Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bericht zur Datenexploration mit Autopilot
Amazon SageMaker Autopilot reinigt und verarbeitet Ihren Datensatz automatisch vor. Hochwertige Daten verbessern die Effizienz des Machine Learning und erzeugen Modelle, die genauere Vorhersagen treffen.
Es gibt Probleme mit vom Kunden bereitgestellten Datensätzen, die nicht automatisch behoben werden können, wenn Sie nicht über ein gewisses Fachwissen verfügen. Große Ausreißerwerte in der Zielspalte für Regressionsprobleme können beispielsweise zu suboptimalen Vorhersagen für die Nicht-Ausreißerwerte führen. Je nach Modellierungsziel müssen Ausreißer möglicherweise entfernt werden. Wenn eine Zielspalte versehentlich als eines der Eingabe-Features aufgenommen wird, ist das endgültige Modell gut validiert, aber für zukünftige Prognosen von geringem Wert.
Um Kunden bei der Entdeckung solcher Probleme zu unterstützen, stellt Autopilot einen Datenexplorationsbericht bereit, der Einblicke in potenzielle Probleme mit ihren Daten enthält. Der Bericht schlägt auch vor, wie mit den Problemen umgegangen werden kann.
Für jeden Autopilot-Auftrag wird ein Notebook zur Datenexploration erstellt, das den Bericht enthält. Der Bericht wird in einem Amazon-S3-Bucket gespeichert und kann von Ihrem Ausgabepfad aus aufgerufen werden. Der Pfad des Datenexplorationsberichts folgt in der Regel dem folgenden Muster.
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMakerAutopilotDataExplorationNotebook.ipynb
Der Standort des Notizbuches zur Datenerkundung kann vom Autopiloten API anhand der DescribeAutoMLJobBetriebsantwort abgerufen werden, die in gespeichert ist. DataExplorationNotebookLocation
Wenn Sie Autopilot von SageMaker Studio Classic aus ausführen, können Sie den Datenexplorationsbericht mithilfe der folgenden Schritte öffnen:
-
Wählen Sie im linken Navigationsbereich das
 Home-Symbol, um das Amazon SageMaker Studio Classic-Navigationsmenü auf oberster Ebene aufzurufen.
Home-Symbol, um das Amazon SageMaker Studio Classic-Navigationsmenü auf oberster Ebene aufzurufen. -
Wählen Sie die AutoML-Karte aus dem Hauptarbeitsbereich aus. Dadurch wird eine neue AutoML-Registerkarte geöffnet.
-
Wählen Sie im Abschnitt Name den Autopilot-Auftrag aus, der das Datenexplorations-Notebook enthält, das Sie untersuchen möchten. Dadurch wird eine neue Registerkarte für Autopilot-Aufträge geöffnet.
-
Wählen Sie oben rechts auf der Registerkarte Autopilot-Auftrag die Option Notebook zur Datenexploration öffnen aus.
Der Datenexplorationsbericht wird aus Ihren Daten generiert, bevor der Trainingsprozess beginnt. Auf diese Weise können Sie Autopilot-Aufträge beenden, die zu bedeutungslosen Ergebnissen führen könnten. Ebenso können Sie alle Probleme oder Verbesserungen mit Ihrem Datensatz beheben, bevor Sie Autopilot erneut ausführen. Auf diese Weise können Sie Ihr Fachwissen nutzen, um die Datenqualität manuell zu verbessern, bevor Sie ein Modell mit einem besser kuratierten Datensatz trainieren.
Der Datenbericht enthält nur statischen Markdown und kann in jeder Jupyter-Umgebung geöffnet werden. Das Notizbuch, das den Bericht enthält, kann in andere Formate konvertiert werden, z. B. PDF oderHTML. Weitere Informationen zu Konvertierungen finden Sie unter Verwenden des nbconvert-Skripts zum Konvertieren von Jupyter Notebooks in andere Formate
Themen
Datensatzzusammenfassung
Diese Datensatzzusammenfassung enthält wichtige Statistiken, die Ihren Datensatz charakterisieren, einschließlich der Anzahl der Zeilen, Spalten, prozentualer Anzahl doppelter Zeilen und fehlender Zielwerte. Es soll Sie schnell benachrichtigen, wenn es Probleme mit Ihrem Datensatz gibt, die Amazon SageMaker Autopilot erkannt hat und die wahrscheinlich Ihr Eingreifen erfordern. Die Erkenntnisse werden in Form von Warnungen angezeigt, die entweder als „hoch“ oder „niedrig“ eingestuft werden. Die Klassifizierung hängt davon ab, wie sicher das Problem ist, dass sich das Problem negativ auf die Leistung des Modells auswirkt.
Die Erkenntnisse mit hohem und niedrigem Schweregrad werden in der Zusammenfassung als Pop-ups angezeigt. Bei den meisten Erkenntnissen werden Empfehlungen angeboten, wie Sie überprüfen können, ob ein Problem mit dem Datensatz vorliegt, das Ihre Aufmerksamkeit erfordert. Es werden auch Vorschläge zur Lösung der Probleme gemacht.
Der Autopilot bietet zusätzliche Statistiken über fehlende oder ungültige Zielwerte in unserem Datensatz, damit Sie andere Probleme erkennen können, die möglicherweise nicht durch Erkenntnisse mit hohem Schweregrad erfasst werden können. Eine unerwartete Anzahl von Spalten eines bestimmten Typs kann darauf hindeuten, dass einige Spalten, die Sie verwenden möchten, möglicherweise im Datensatz fehlen. Dies könnte auch darauf hinweisen, dass ein Problem mit der Aufbereitung oder Speicherung der Daten aufgetreten ist. Die Behebung dieser Datenprobleme, auf die Sie durch Autopilot aufmerksam gemacht wurden, kann die Leistung der anhand Ihrer Daten trainierten Modelle für Machine Learning verbessern.
Erkenntnisse mit hohem Schweregrad finden Sie in der Zusammenfassung und in anderen relevanten Abschnitten des Berichts. Beispiele für Erkenntnisse mit hohem und niedrigem Schweregrad werden in der Regel je nach Abschnitt des Datenberichts angegeben.
Zielanalyse
In diesem Abschnitt werden verschiedene Erkenntnisse mit hohem und niedrigem Schweregrad gezeigt, die sich auf die Verteilung der Werte in der Zielspalte beziehen. Überprüfen Sie, ob die Zielspalte die richtigen Werte enthält. Falsche Werte in der Zielspalte führen wahrscheinlich zu einem Machine-Learning-Modell, das nicht dem beabsichtigten Geschäftszweck dient. In diesem Abschnitt finden Sie mehrere Erkenntnisse aus Daten mit hohem und niedrigem Schweregrad. Im Folgenden finden Sie einige Beispiele.
-
Zielwerte für Ausreißer – Schiefe oder ungewöhnliche Zielverteilung für Regressionszwecke, z. B. stark schwankende Ziele.
-
Hohe oder niedrige Zielkardinalität – Seltene Anzahl von Klassenbezeichnungen oder eine große Anzahl von eindeutigen Klassen für die Klassifizierung.
Sowohl bei Regressions- als auch bei Klassifikationsproblemen werden ungültige Werte wie numerische Unendlichkeit, NaN oder Leerzeichen in der Zielspalte angezeigt. Je nach Problemtyp werden unterschiedliche Datensatzstatistiken dargestellt. Anhand einer Verteilung der Zielspaltenwerte für ein Regressionsproblem können Sie überprüfen, ob die Verteilung Ihren Erwartungen entspricht.
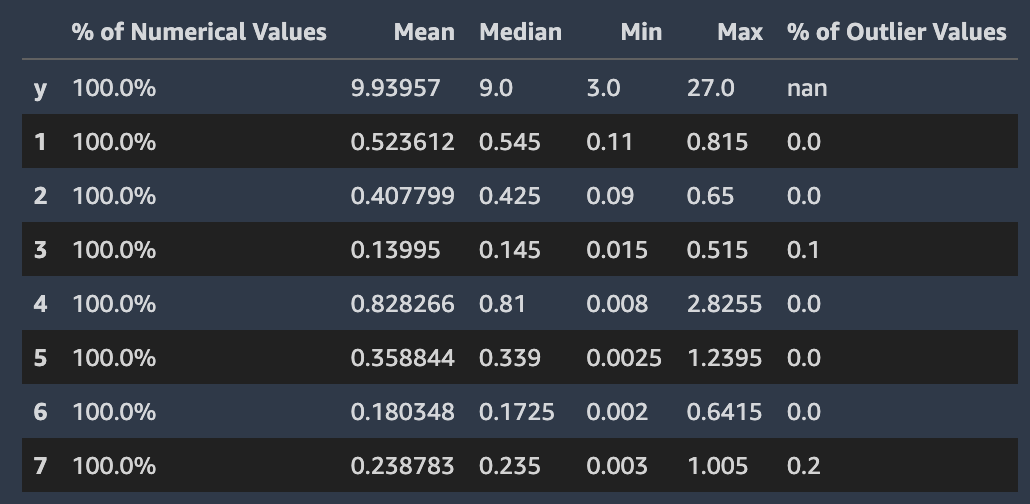
Der folgende Screenshot zeigt einen Autopilot-Datenbericht, der Statistiken wie Mittelwert, Median, Minimum, Maximum und Prozentsatz der Ausreißer in Ihrem Datensatz enthält. Der Screenshot enthält auch ein Histogramm, das die Verteilung der Beschriftungen in der Zielspalte zeigt. Das Histogramm zeigt Zielspaltenwerte auf der horizontalen Achse und Count auf der vertikalen Achse. Der Abschnitt Prozentsatz der Ausreißer auf dem Screenshot wird durch ein Feld hervorgehoben, um anzugeben, wo diese Statistik angezeigt wird.
Es werden mehrere Statistiken zu Zielwerten und ihrer Verteilung angezeigt. Wenn einer der Ausreißer, ungültigen Werte oder fehlenden Prozentsätze größer als Null ist, werden diese Werte angezeigt, sodass Sie untersuchen können, warum Ihre Daten unbrauchbare Zielwerte enthalten. Einige unbrauchbare Zielwerte werden als Warnung mit geringem Schweregrad gekennzeichnet.
Im folgenden Screenshot wurde der Zielspalte versehentlich ein `-Symbol hinzugefügt, wodurch der numerische Wert des Ziels nicht analysiert werden konnte. Eine Niedriges Schweregrad: „Ungültige Zielwerte“-Warnung wird angezeigt. Die Warnung in diesem Beispiel besagt, dass "0,14% der Beschriftungen in der Zielspalte nicht in numerische Werte umgewandelt werden konnten. Die häufigsten nicht numerischen Werte sind: ["-3.8e-05","-9-05","-4.7e-05","-1.4999999999999999e-05","-4.3e-05"]. Das deutet normalerweise darauf hin, dass es Probleme bei der Datenerfassung oder -verarbeitung gibt. Amazon SageMaker Autopilot ignoriert alle Beobachtungen mit ungültiger Zielbezeichnung.“

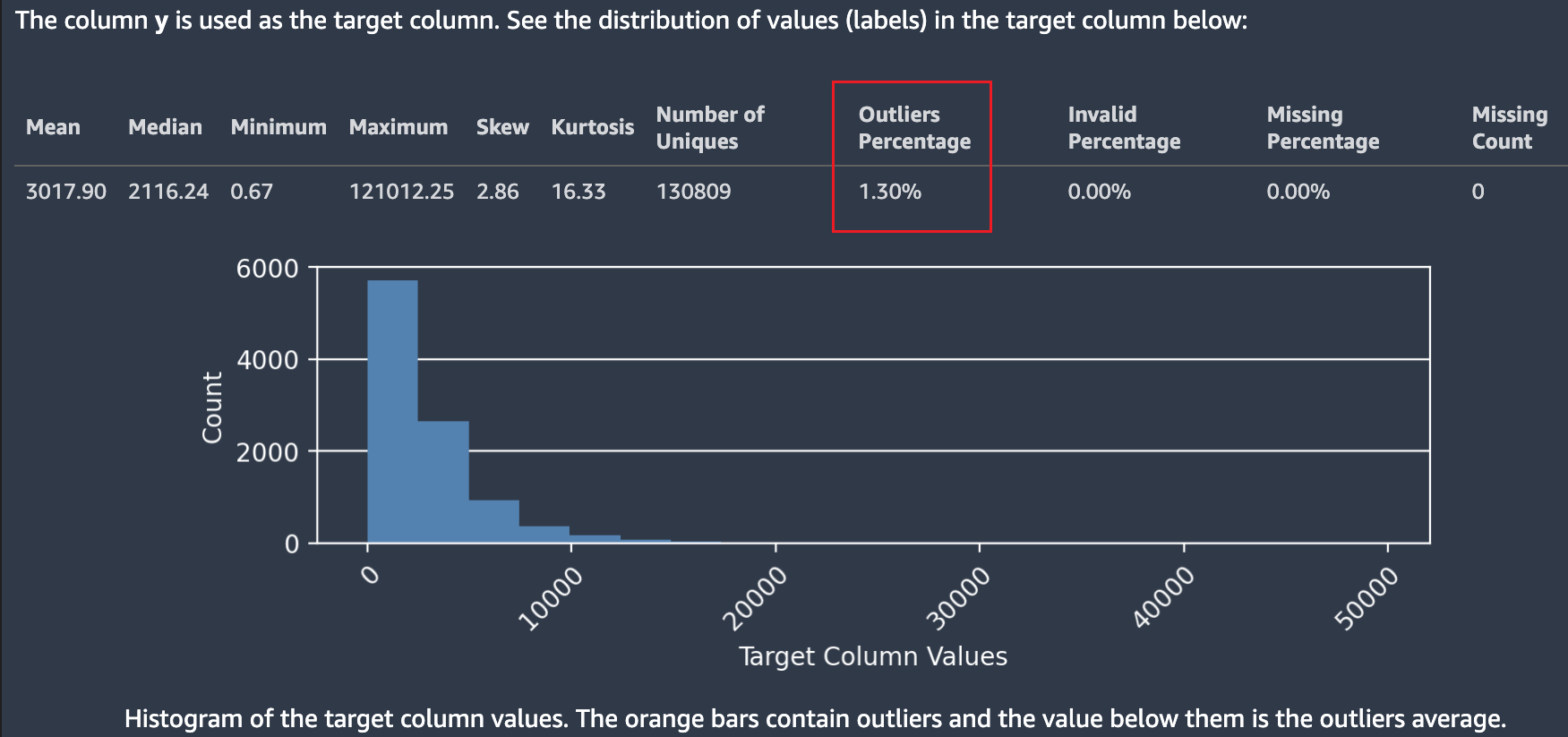
Der Autopilot bietet auch ein Histogramm, das die Verteilung der Beschriftungen für die Klassifizierung zeigt.
Der folgende Screenshot zeigt ein Beispiel für Statistiken für Ihre Zielspalte, einschließlich der Anzahl der Klassen, fehlender oder ungültiger Werte. Ein Histogramm mit Zielbeschrifung auf der horizontalen Achse und Frequenz auf der vertikalen Achse zeigt die Verteilung der einzelnen Beschriftungskategorien.
Anmerkung
Definitionen aller in diesem und anderen Abschnitten vorgestellten Begriffe finden Sie im Abschnitt Definitionen am Ende des Berichts-Notebooks.
Beispieldaten
Der Autopilot zeigt eine aktuelle Stichprobe Ihrer Daten, damit Sie Probleme mit Ihrem Datensatz leichter erkennen können. Die Beispieltabelle scrollt horizontal. Überprüfen Sie die Beispieldaten, um sicherzustellen, dass alle erforderlichen Spalten im Datensatz vorhanden sind.
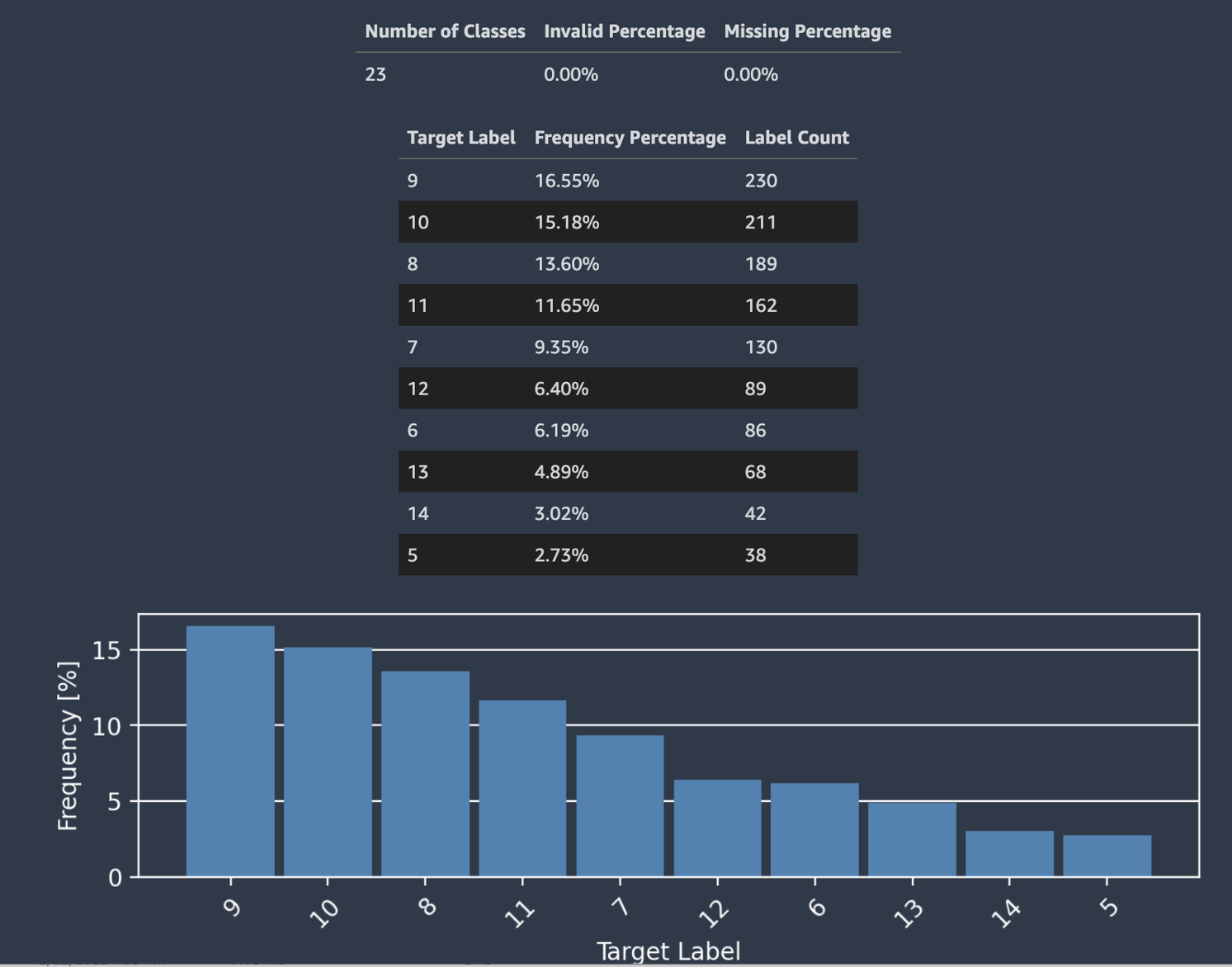
Der Autopilot berechnet außerdem ein Maß für die Vorhersagekraft, anhand dessen eine lineare oder nichtlineare Beziehung zwischen einem Feature und der Zielvariablen identifiziert werden kann. Der Wert von 0 gibt an, dass das Feature keinen prädiktiven Wert für die Vorhersage der Zielvariablen hat. Der Wert von 1 gibt die höchste Vorhersagekraft für die Zielvariable an. Weitere Informationen zur Vorhersagekraft finden Sie im Abschnitt Definitionen.
Anmerkung
Es wird nicht empfohlen, die Vorhersagekraft als Ersatz für die Bedeutung von Features zu verwenden. Verwenden Sie sie nur, wenn Sie sicher sind, dass die Vorhersagekraft ein geeignetes Maß für Ihren Anwendungsfall ist.
Im folgenden Screenshot wird Beispieldaten gezeigt. Die oberste Zeile enthält die Vorhersagestärke jeder Spalte in Ihrem Datensatz. Die zweite Zeile enthält den Datentyp der Spalte. Nachfolgende Zeilen enthalten die Beschriftungen. Die Spalten enthalten die Zielspalte, gefolgt von jeder Feature-Spalte. Jeder Feature-Spalte ist eine Vorhersagekraft zugeordnet, die in diesem Screenshot durch ein Kästchen hervorgehoben wird. In diesem Beispiel hat die Spalte, die das Feature enthält x51, eine Vorhersagekraft von 0.68 für die Zielvariable y. Das Feature x55 ist mit einer Vorhersagekraft von etwas weniger prädiktiv 0.59.
Doppelte Zeilen
Wenn der Datensatz doppelte Zeilen enthält, zeigt Amazon SageMaker Autopilot eine Stichprobe davon an.
Anmerkung
Es wird nicht empfohlen, einen Datensatz durch Upsampling auszubalancieren, bevor er dem Autopilot zur Verfügung gestellt wird. Dies kann zu ungenauen Validierungsergebnissen für die mit Autopilot trainierten Modelle führen, und die erstellten Modelle können unbrauchbar sein.
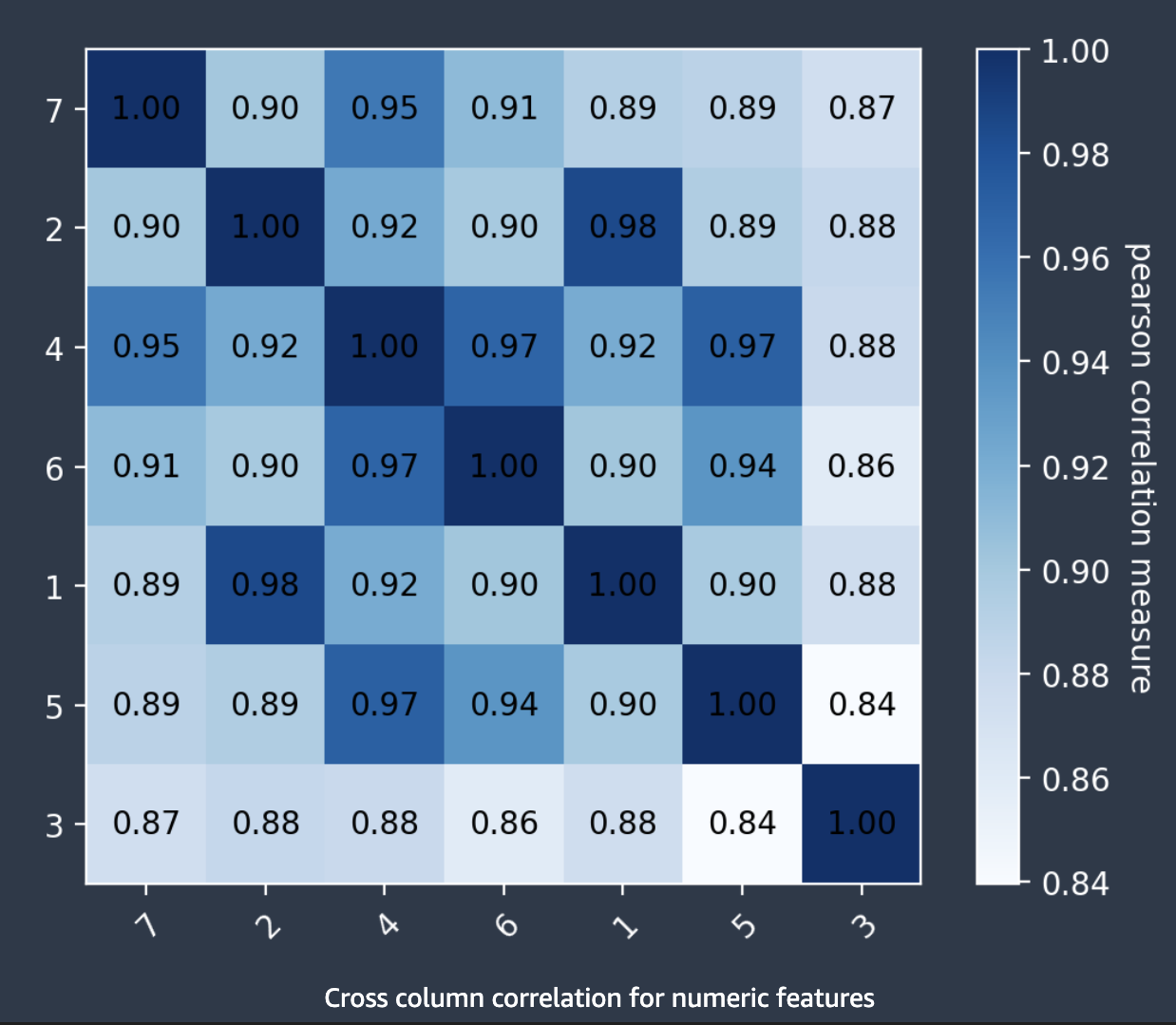
Spaltenübergreifende Korrelationen
Der Autopilot verwendet den Korrelationskoeffizienten von Pearson, ein Maß für die lineare Korrelation zwischen zwei Features, um eine Korrelationsmatrix zu füllen. In der Korrelationsmatrix werden numerische Features sowohl auf der horizontalen als auch auf der vertikalen Achse dargestellt, wobei der Korrelationskoeffizient nach Pearson an ihren Schnittpunkten dargestellt wird. Je höher die Korrelation zwischen zwei Features ist, desto höher ist der Koeffizient mit einem Höchstwert von |1|.
-
Ein Wert von
-1gibt an, dass die Features perfekt negativ korreliert sind. -
Ein Wert von
1, der auftritt, wenn ein Feature mit sich selbst korreliert, weist auf eine perfekte positive Korrelation hin.
Sie können die Informationen in der Korrelationsmatrix verwenden, um stark korrelierte Features zu entfernen. Eine geringere Anzahl von Features verringert die Wahrscheinlichkeit einer Überanpassung eines Modells und kann die Produktionskosten auf zweierlei Weise senken. Dies verringert die benötigte Laufzeit des Autopiloten und kann bei einigen Anwendungen die Datenerfassungsverfahren billiger machen.
Im folgenden Screenshot wird ein Beispiel einer Korrelationsmatrix zwischen 7 Features gezeigt. Jedes Feature wird in einer Matrix sowohl auf der horizontalen als auch auf der vertikalen Achse angezeigt. Der Korrelationskoeffizient nach Pearson wird am Schnittpunkt zwischen zwei Features angezeigt. Jedem Schnittpunkt eines Features ist ein Farbton zugeordnet. Je höher die Korrelation, desto dunkler der Ton. Die dunkelsten Töne nehmen die Diagonale der Matrix ein, wo jedes Feature mit sich selbst korreliert, was eine perfekte Korrelation darstellt.
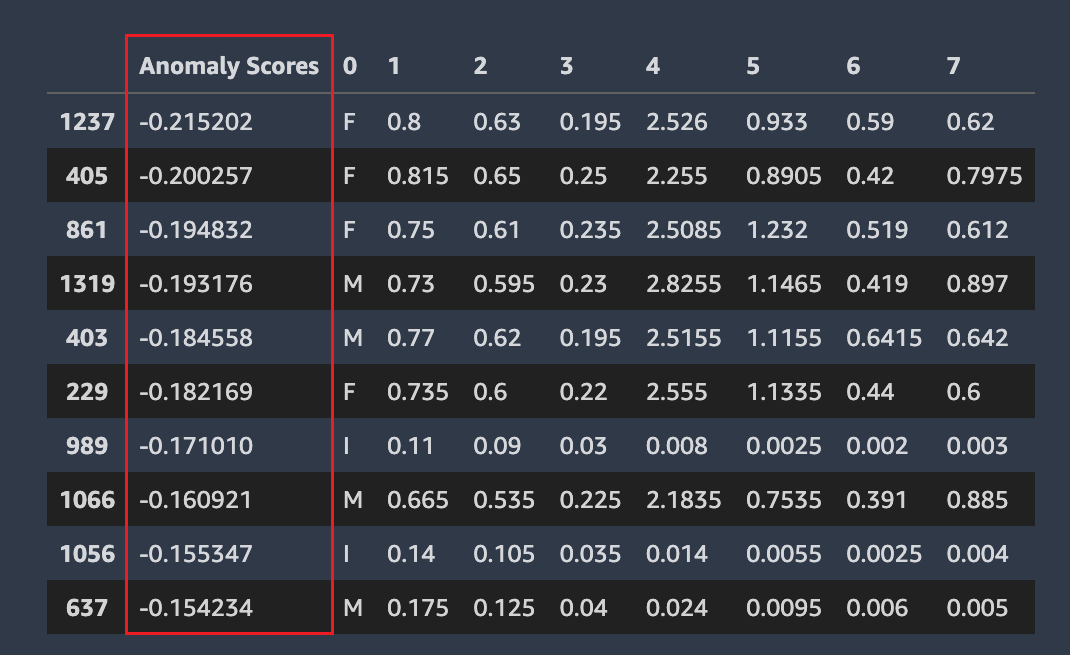
Anomale Zeilen
Amazon SageMaker Autopilot erkennt, welche Zeilen in Ihrem Datensatz möglicherweise anomal sind. Anschließend wird jeder Zeile ein Anomaliewert zugewiesen. Zeilen mit negativen Anomaliewerten werden als anomal betrachtet.
Der folgende Screenshot zeigt die Ausgabe einer Autopilot-Analyse für Zeilen mit Anomalien. Eine Spalte mit einer anomalen Punktzahl wird neben den Datensatzspalten für jede Zeile angezeigt.
Fehlende Werte, Kardinalität und deskriptive Statistiken
Amazon SageMaker Autopilot untersucht die Eigenschaften der einzelnen Spalten Ihres Datensatzes und erstellt Berichte darüber. In jedem Abschnitt des Datenberichts, der diese Analyse präsentiert, ist der Inhalt der Reihe nach angeordnet. Auf diese Weise können Sie die „verdächtigsten“ Werte zuerst überprüfen. Mithilfe dieser Statistiken können Sie den Inhalt einzelner Spalten und die Qualität des von Autopilot erstellten Modells verbessern.
Autopilot berechnet mehrere Statistiken zu den kategorialen Werten in den Spalten, die sie enthalten. Dazu gehören die Anzahl der eindeutigen Einträge und bei Text die Anzahl der eindeutigen Wörter.
Autopilot berechnet mehrere Standardstatistiken anhand der numerischen Werte in den Spalten, die sie enthalten. Die folgende Abbildung zeigt diese Statistiken, einschließlich der Mittel-, Median-, Minimal- und Maximalwerte sowie der Prozentsätze numerischer Typen und Ausreißerwerte.