Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Metriken und Validierung
Dieser Leitfaden zeigt Metriken und Validierungstechniken, mit denen Sie die Leistung von Machine-Learning-Modellen messen können. Amazon SageMaker Autopilot erstellt Metriken, die die prädiktive Qualität von Modellkandidaten für Machine Learning messen. Die für Kandidaten berechneten Metriken werden mithilfe einer Reihe von MetricDatum Typen angegeben.
Autopilot-Metriken
Die folgende Liste enthält die Namen der Metriken, die derzeit zur Messung der Modellleistung in Autopilot verfügbar sind.
Anmerkung
Autopilot unterstützt Stichprobengewichtungen. Weitere Informationen zu Stichprobengewichtungen und den verfügbaren objektiven Messwerten finden Sie unter Gewichtete Metriken mit Autopilot.
Die folgenden Metriken stehen zur Verfügung.
Accuracy-
Das Verhältnis der Anzahl korrekt klassifizierter Artikel zur Gesamtzahl der (richtig und falsch) klassifizierten Artikel. Es wird sowohl für die binäre als auch für die Mehrklassen-Klassifizierung verwendet. Die Genauigkeit gibt an, wie nahe die vorhergesagten Klassenwerte an den tatsächlichen Werten liegen. Die Werte für Genauigkeitsmetriken variieren zwischen Null (0) und Eins (1). Ein Wert von 1 steht für perfekte Genauigkeit, und 0 steht für perfekte Ungenauigkeit.
AUC-
Die AUC-Metrik (Bereich unter der Kurve) wird verwendet, um binäre Klassifikationen mithilfe von Algorithmen zu vergleichen und zu bewerten, die Wahrscheinlichkeiten zurückgeben, wie z. B. logistische Regression. Um den Wahrscheinlichkeiten Klassifizierungen zuzuordnen, werden diese mit einem Schwellenwert verglichen.
Die relevante Kurve ist die Betriebskennlinie des Empfängers. In der Kurve wird die Wirklich-Positiv-Rate (TPR) von Voraussagen (oder Recall) im Vergleich zur Falsch-Positiv-Rate (FPR) als Funktion des Schwellenwerts dargestellt, ab dem eine Voraussage als positiv angesehen wird. Eine Erhöhung des Schwellenwerts führt zu weniger falsch positiven Ergebnissen, dafür aber zu mehr falsch negativen Ergebnissen.
AUC ist die Fläche unter der Betriebskennlinie dieses Empfängers. Daher bietet AUC ein aggregiertes Maß für die Modellleistung über alle möglichen Klassifizierungsschwellen hinweg. Die AUC-Werte variieren zwischen 0 und 1. Ein Wert von 1 steht für perfekte Genauigkeit, und ein Wert von einer Hälfte (0,5) bedeutet, dass die Voraussage nicht besser ist als ein zufälliger Klassifikator.
BalancedAccuracy-
BalancedAccuracyist eine Metrik, die das Verhältnis von genauen Voraussagen zu allen Voraussagen misst. Dieses Verhältnis wird berechnet, nachdem wirklich positive (TP) und True negative Werte (TN) durch die Gesamtzahl der positiven (P) und negativen (N) Werte normalisiert wurden. Es wird sowohl in der binären als auch in der Mehrklassen-Klassifizierung verwendet und ist wie folgt definiert: 0,5* ((TP/P) + (TN/N)) mit Werten im Bereich von 0 bis 1.BalancedAccuracybietet ein besseres Maß für die Genauigkeit, wenn die Anzahl der positiven oder negativen Ergebnisse in einem unausgewogenen Datensatz stark voneinander abweicht, z. B. wenn es sich bei nur 1 % der E-Mails um Spam handelt. F1-
Der
F1Wert ist das harmonische Mittel aus Präzision und Erinnerung, wie folgt definiert: F1 = 2 * (Präzision * Erinnerung)/(Präzision + Erinnerung). Es wird für die binäre Klassifikation in Klassen verwendet, die traditionell als positiv und negativ bezeichnet werden. Voraussagen gelten als wahr, wenn sie ihrer tatsächlichen (richtigen) Klasse entsprechen, und als falsch, wenn dies nicht der Fall ist.Präzision ist das Verhältnis der wirklich positiven Voraussagen zu allen positiven Voraussagen und schließt die falsch positiven Voraussagen in einen Datensatz ein. Mit der Präzision wird die Qualität der Voraussage gemessen, wenn sie die positive Klasse voraussagt.
Der Erinnerungswert (oder die Sensibilität) ist das Verhältnis der wirklich positiven Voraussagen zu allen tatsächlich positiven Instances. Mit dem Erinnerungswert wird gemessen, wie vollständig ein Modell die tatsächlichen Klassenmitglieder in einem Datensatz vorhersagt.
Die F1-Werte variieren zwischen 0 und 1. Ein Wert von 1 steht für die bestmögliche Leistung und 0 für die schlechteste.
F1macro-
Die
F1macroPunktzahl wendet die F1-Bewertung auf Mehrklassen-Klassifizierungsprobleme an. Zu diesem Zweck werden die Präzision und der Erinnerungswert berechnet und anschließend anhand ihres harmonischen Mittelwerts der F1-Wert für jede Klasse berechnet. Schließlich werden die Durchschnittswerte der einzelnen Punktzahlen vonF1macrogemittelt, um dieF1macroPunktzahl zu ermitteln.F1macroPunktzahlen variieren zwischen 0 und 1. Ein Wert von 1 steht für die bestmögliche Leistung und 0 für die schlechteste. InferenceLatency-
Die Inferenzlatenz ist die ungefähre Zeitspanne zwischen der Anforderung einer Modellvoraussage und deren Empfang von einem Echtzeit-Endpunkt, auf dem das Modell bereitgestellt wird. Diese Metrik wird in Sekunden gemessen und ist nur im Ensembling-Modus verfügbar.
LogLoss-
Der Protokollverlust, auch bekannt als Kreuz-Entropie-Verlust, ist eine Metrik, die verwendet wird, um die Qualität der Wahrscheinlichkeitsausgaben und nicht die Ergebnisse selbst zu bewerten. Es wird sowohl in der binären als auch für die Mehrklassen-Klassifizierung und in neuronalen Netzen verwendet. Es ist auch die Kostenfunktion für die logistische Regression. Der Protokollverlust ist eine wichtige Kennzahl, die angibt, wann ein Modell mit hoher Wahrscheinlichkeit falsche Voraussagen trifft. Werte liegen zwischen 0 und unendlich. Ein Wert von 0 steht für ein Modell, das die Daten perfekt vorhersagt.
MAE-
Der mittlere absolute Fehler (MAE) ist ein Maß dafür, wie unterschiedlich die vorausgesagten und tatsächlichen Werte sind, wenn sie über alle Werte gemittelt werden. MAE wird häufig in der Regressionsanalyse verwendet, um Fehler bei der Modellvoraussage zu verstehen. Liegt eine lineare Regression vor, stellt MAE die durchschnittliche Entfernung zwischen einer vorausgesagten Linie und dem tatsächlichen Wert dar. MAE ist definiert als die Summe der absoluten Fehler geteilt durch die Anzahl der Beobachtungen. Die Werte reichen von 0 bis unendlich. Dabei weisen kleinere Zahlen auf eine bessere Anpassung des Modells an die Daten hin.
MSE-
Der mittlere quadratische Fehler (MSE) ist der Durchschnitt der quadrierten Differenzen zwischen den vorausgesagten und den tatsächlichen Werten. Er wird für die Regression verwendet. MSE-Werte sind immer positiv. Je besser ein Modell die tatsächlichen Werte vorhersagen kann, desto kleiner ist der MSE-Wert.
Precision-
Mit der Präzision wird gemessen, wie gut ein Algorithmus unter allen von ihm identifizierten positiven Ergebnissen die wirklich positiven Ergebnisse (TP) voraussagt. Sie ist wie folgt definiert: Präzision = TP/ (TP+FP) mit Werten im Bereich von Null (0) bis Eins (1). Sie wird bei der binären Klassifikation verwendet. Präzision ist eine wichtige Kennzahl, wenn die Kosten eines falsch positiven Ergebnisses hoch sind. Die Kosten eines falsch positiven Ergebnisses sind beispielsweise sehr hoch, wenn ein Flugzeugsicherheitssystem fälschlicherweise als flugsicher eingestuft wird. Ein falsch positives Ergebnis (FP) spiegelt eine positive Voraussage wider, die in den Daten tatsächlich negativ ist.
PrecisionMacro-
Das Präzisionsmakro berechnet die Genauigkeit für Mehrklassen-Klassifizierungsprobleme. Zu diesem Zweck wird die Präzision für jede Klasse berechnet und die Ergebnisse werden gemittelt, um die Genauigkeit für mehrere Klassen zu ermitteln.
PrecisionMacroDie Werte reichen von Null (0) bis Eins (1). Höhere Werte spiegeln die Fähigkeit des Modells wider, wirklich positive Ergebnisse (TP) aus allen identifizierten positiven Ergebnissen vorauszusagen, wobei der Durchschnitt über mehrere Klassen hinweg berechnet wird. R2-
R 2, auch Bestimmtheitskoeffizient genannt, wird in der Regression verwendet, um zu quantifizieren, inwieweit ein Modell die Varianz einer abhängigen Variablen erklären kann. Die Werte reichen von Eins (1) bis negativ Eins (-1). Höhere Werte bedeuten einen höheren Anteil der erklärten Variabilität.
R2-Werte nahe Null (0) deuten darauf hin, dass nur ein sehr geringer Teil der abhängigen Variablen durch das Modell erklärt werden kann. Negative Werte deuten auf eine schlechte Anpassung hin und darauf, dass das Modell durch eine konstante Funktion übertroffen wird. Bei linearer Regression ist dies eine horizontale Linie. Recall-
Der Erinnerungswert misst, wie gut ein Algorithmus alle wirklich positiven Ergebnisse (TP) in einem Datensatz korrekt voraussagt. Ein wirklich positives Ergebnis ist eine positive Voraussage, die auch einen tatsächlich positiver Wert in den Daten darstellt. Der Erinnerungswert ist wie folgt definiert: Erinnerungswert = TP/ (TP+FN) mit Werten im Bereich von 0 bis 1. Höhere Werte spiegeln die bessere Fähigkeit des Modells wider, wirklich positive Ergebnisse (TP) in den Daten vorauszusagen. Er wird in der binären Klassifikation verwendet.
Beim Testen auf Krebs ist der Erinnerungswert wichtig, da er verwendet wird, um alle wirklich positiven Ergebnisse zu ermitteln. Ein falsch positives Ergebnis (FP) spiegelt eine positive Voraussage wider, die in den Daten tatsächlich negativ ist. Oft reicht es nicht aus, nur den Erinnerungswert zu messen, da die Voraussage jeder Ausgabe als wirklich positiv zu einem perfekten Erinnerungswert führt.
RecallMacro-
Bei Mehrklassen-Klassifizierungsproblemen berechnet der
RecallMacroden Erinnerungswert, indem dieser für jede Klasse berechnet und die Ergebnisse gemittelt werden, um den Erinnerungswert für mehrere Klassen zu ermitteln.RecallMacroDie Werte reichen von 0 bis 1. Höhere Werte spiegeln die Fähigkeit des Modells wider, wirklich positive Ergebnisse (TP) in einem Datensatz vorauszusagen, wohingegen ein wirklich positives Ergebnis eine positive Voraussage widerspiegelt, die auch ein tatsächlich positiver Wert in den Daten ist. Oft reicht es nicht aus, nur den Erinnerungswert zu messen, da die Voraussage jeder Ausgabe als wirklich positiv zu einem perfekten Erinnerungswert führen wird. RMSE-
Der quadratische Mittelwert (Root Mean Squared Error, RMSE) misst die Quadratwurzel der quadrierten Differenz zwischen vorausgesagten und tatsächlichen Werten und wird über alle Werte gemittelt. Er wird häufig in der Regressionsanalyse verwendet, um Fehler bei der Modellvoraussage zu verstehen. Er ist eine wichtige Kennzahl, die auf das Vorhandensein großer Fehler und Ausreißer im Modell hinweist. Die Werte reichen von Null (0) bis unendlich. Dabei weisen kleinere Zahlen auf eine bessere Anpassung des Modells an die Daten hin. RMSE hängt von der Größenordnung ab und sollte nicht zum Vergleich von Datensätzen unterschiedlicher Größe verwendet werden.
Metriken, die automatisch für einen Modellkandidaten berechnet werden, hängen von der Art des zu lösenden Problems ab.
Eine Liste der verfügbaren Metriken, die von Autopilot unterstützt werden, finden Sie in der Amazon SageMaker -API-Referenzdokumentation.
Gewichtete Metriken mit Autopilot
Anmerkung
Der Autopilot unterstützt Stichprobengewichtungen im Ensembling-Modus nur für alle verfügbaren Metriken mit Ausnahme von Balanced Accuracy und InferenceLatency. BalanceAccuracy verfügt über ein eigenes Gewichtungsschema für unausgewogene Datensätze, für das keine Stichprobengewichtungen erforderlich sind. InferenceLatency unterstützt keine Stichprobengewichtungen. Sowohl objektive Balanced Accuracy als auch InferenceLatency Metriken werden von allen vorhandenen Stichprobengewichtungen ignoriert, wenn ein Modell trainiert und bewertet wird.
Benutzer können ihren Daten eine Spalte mit den Stichprobengewichtungen hinzufügen, um sicherzustellen, dass jeder Beobachtung, die zum Trainieren eines Machine Learning-Modells verwendet wird, eine Gewichtung zugewiesen wird, die ihrer wahrgenommenen Bedeutung für das Modell entspricht. Dies ist besonders nützlich in Szenarien, in denen die Beobachtungen im Datensatz unterschiedlich wichtig sind oder in denen ein Datensatz eine unverhältnismäßige Anzahl von Stichproben aus einer Klasse im Vergleich zu anderen enthält. Die Gewichtung jeder Beobachtung auf der Grundlage ihrer Bedeutung oder ihrer größeren Bedeutung für eine Minderheitenklasse kann die Gesamtleistung eines Modells verbessern oder sicherstellen, dass ein Modell nicht auf die Mehrheitsklasse ausgerichtet ist.
Informationen zum Übergeben von Beispielgewichtungen beim Erstellen eines Experiments in der Studio Classic-Benutzeroberfläche finden Sie unter Schritt 7 unter Erstellen eines Autopilot-Experiments mit Studio Classic.
Informationen zum programmgesteuerten Übergeben von Probengewichten bei der Erstellung eines Autopilot-Experiments mithilfe der API finden Sie unter So fügen Sie Stichprobengewichtungen zu einem AutoML-Job hinzu in Programmgesteuert ein Autopilot-Experiment erstellen.
Kreuzvalidierung im Autopilot
Die Kreuzvalidierung wird verwendet, um Überanpassungen und Verzerrungen bei der Modellauswahl zu reduzieren. Sie wird auch verwendet, um zu beurteilen, wie gut ein Modell die Werte eines unbekannten Validierungsdatensatzes voraussagen kann, wenn der Validierungsdatensatz aus derselben Grundgesamtheit stammt. Diese Methode ist besonders wichtig, wenn mit Datensätzen trainiert wird, die über eine begrenzte Anzahl von Schulungs-Instances verfügen.
Autopilot verwendet Kreuzvalidierung, um Modelle im Hyperparameter-Optimierungsmodus (HPO) und im Ensemble-Trainingsmodus zu erstellen. Der erste Schritt im Autopilot-Kreuzvalidierungsprozess besteht darin, die Daten in k-Bereichen aufzuteilen.
k-Bereichsaufteilung
Die k-Bereichsaufteilung ist eine Methode, bei der ein Eingabe-Trainingsdatensatz in mehrere Trainings- und Validierungsdatensätze aufgeteilt wird. Der Datensatz wird in k gleich große Teilstichproben aufgeteilt, die als Bereiche bezeichnet werden. Anschließend werden die Modelle anhand von k-1 Bereichen trainiert und anhand des verbleibenden k-ten Bereiche dem Validierungsdatensatz getestet. Der Vorgang wird k-mal wiederholt, wobei zur Validierung ein anderer Datensatz verwendet wird.
Das folgende Bild zeigt die k-fache Aufteilung mit k = 4 Bereiche an. Jeder Bereich wird als eine Reihe dargestellt. Die dunkel getönten Felder stellen die Teile der Daten dar, die im Training verwendet wurden. Die verbleibenden hell getönten Felder kennzeichnen die Validierungsdatensätze.

Autopilot verwendet die k-fache Kreuzvalidierung sowohl für den Hyperparameter-Optimierungsmodus (HPO) als auch für den Ensemble-Modus.
Sie können Autopilot-Modelle bereitstellen, die mit Kreuzvalidierung erstellt wurden, wie Sie es bei jedem anderen Autopiloten oder SageMaker Modell tun würden.
HPO-Modus
Bei der f-fachen Kreuzvalidierung wird die Methode der k-fachen Aufteilung für die Kreuzvalidierung verwendet. Im HPO-Modus implementiert Autopilot automatisch die k-fache Kreuzvalidierung für kleine Datensätze mit 50.000 oder weniger Schulungs-Instances. Die Durchführung einer Kreuzvalidierung ist besonders wichtig, wenn mit kleinen Datensätzen trainiert wird, da sie vor Überanpassung und Selektionsverzerrungen schützt.
Der HPO-Modus verwendet einen k-Wert von 5 für jeden der Kandidatenalgorithmen, die zur Modellierung des Datensatzes verwendet werden. Mehrere Modelle werden auf unterschiedlichen Splits trainiert, und die Modelle werden separat gespeichert. Wenn das Training abgeschlossen ist, werden die Validierungsmetriken für jedes der Modelle gemittelt, sodass eine einzige Schätzungsmetrik entsteht. Zum Schluss kombiniert Autopilot die Modelle aus der Testversion mit der besten Validierungsmetrik zu einem Ensemble-Modell. Autopilot verwendet dieses Ensemble-Modell, um Voraussagen zu treffen.
Die Validierungsmetrik für die mit Autopilot trainierten Modelle wird in der Modell-Bestenliste als objektive Metrik dargestellt. Autopilot verwendet für jeden von ihm behandelten Problemtyp die Standard-Validierungsmetrik, sofern Sie nichts anderes angeben. Eine Liste aller Metriken, die von Autopilot verwendet werden, finden Sie unter Autopilot-Metriken.
Beispielsweise enthält der Datensatz Boston Housing
Durch eine Kreuzvalidierung kann die Trainingszeit um durchschnittlich 20 % verlängert werden. Die Trainingszeiten können sich auch bei komplexen Datensätzen erheblich verlängern.
Anmerkung
Im HPO-Modus können Sie die Trainings- und Validierungsmetriken aus jedem Bereich in Ihren -/aws/sagemaker/TrainingJobs CloudWatch Protokollen sehen. Weitere Informationen zu - CloudWatch Protokollen finden Sie unter Protokollgruppen und Streams, die Amazon SageMaker an Amazon CloudWatch Logs sendet.
Ensembling-Modus
Anmerkung
Der Autopilot unterstützt Probengewichtungen im Ensembling-Modus. Eine Liste der verfügbaren Metriken, die Stichprobengewichtungen unterstützen, finden Sie unter Autopilot-Metriken.
Im Ensembling-Modus wird die Kreuzvalidierung unabhängig von der Datensatzgröße durchgeführt. Kunden können entweder ihren eigenen Validierungsdatensatz und ein benutzerdefiniertes Datenteilungsverhältnis angeben oder den Datensatz von Autopilot automatisch in einem Teilungsverhältnis von 80–20 % teilen lassen. Die Trainingsdaten werden dann für die Kreuzvalidierung in k-Bereiche aufgeteilt, wobei der Wert von von der AutoGluon Engine bestimmt k wird. Ein Ensemble besteht aus mehreren Machine Learning-Modellen, wobei jedes Modell als Basismodell bezeichnet wird. Ein einzelnes Basismodell wird anhand von (k-1)-Falten trainiert und trifft out-of-fold Vorhersagen für den verbleibenden Bereich. Dieser Prozess wird für alle k Bereiche wiederholt, und die out-of-fold (OOF)-Vorhersagen werden zu einem einzigen Satz von Vorhersagen verkettet. Alle Basismodelle im Ensemble folgen demselben Prozess der Generierung von OOF-Voraussagen.
Das folgende Bild zeigt die k-Bereichsvalidierung mit k = 4 Bereiche an. Jeder Bereich wird als eine Reihe dargestellt. Die dunkel getönten Felder stellen die Teile der Daten dar, die im Training verwendet wurden. Die verbleibenden hell getönten Felder kennzeichnen die Validierungsdatensätze.
Im oberen Teil des Bildes, in jedem Bereich, trifft das erste Basismodell nach dem Training mit den Trainingsdatensätzen Voraussagen für den Validierungsdatensatz. Bei jeder weiteren Bereich wechseln die Datensätze ihre Rollen. Ein Datensatz, der zuvor für die Schulung verwendet wurde, wird jetzt zur Validierung verwendet, und das gilt auch umgekehrt. Am Ende des k Bereichs werden alle Vorhersagen zu einem einzigen Satz von Vorhersagen verkettet, die als out-of-fold (OOF)-Vorhersage bezeichnet werden. Dieser Vorgang wird für jedes n Basismodell wiederholt.
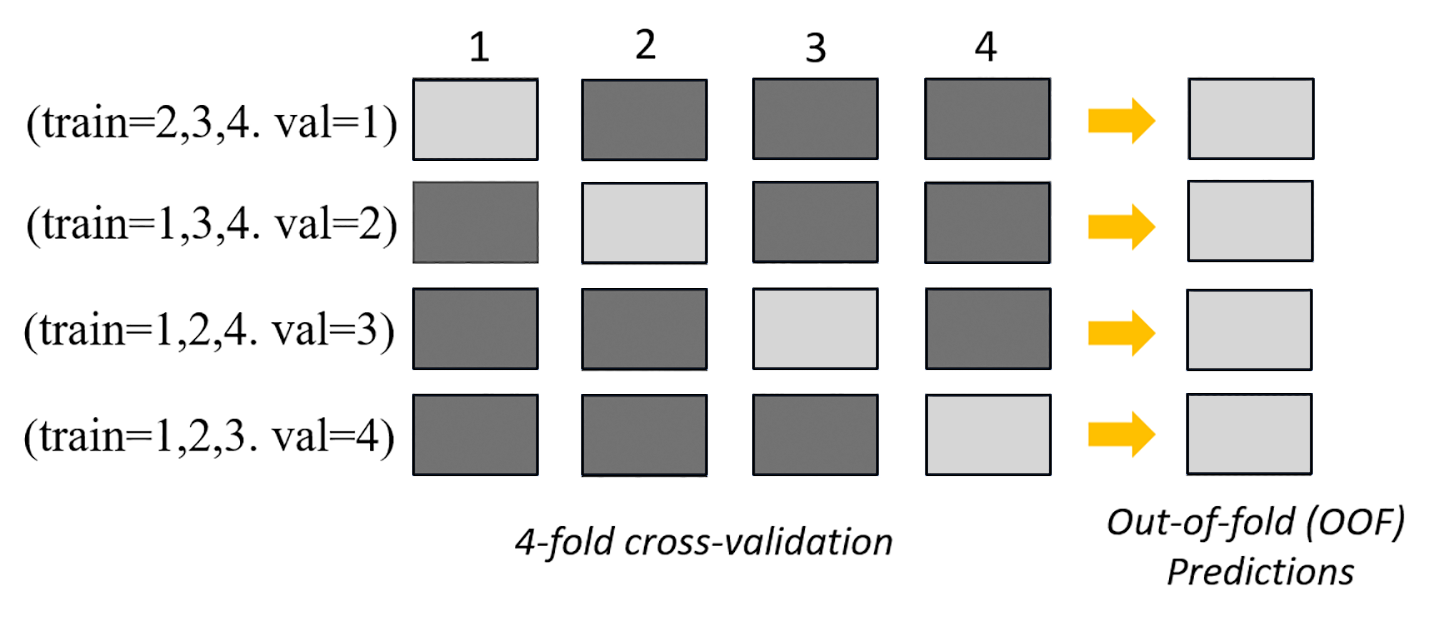
Die OOF-Voraussagen für jedes Basismodell werden dann als Merkmale zum Trainieren eines Stapelmodells verwendet. Das Stapelmodell lernt die Wichtigkeitsgewichtungen für jedes Basismodell kennen. Diese Gewichtungen werden verwendet, um die OOF-Voraussagen zu kombinieren, um die endgültige Voraussage zu bilden. Die Leistung des Validierungsdatensatzes bestimmt, welches Basis- oder Stapelmodell das beste ist, und dieses Modell wird als endgültiges Modell zurückgegeben.
Im Ensemble-Modus können Sie entweder Ihren eigenen Validierungsdatensatz bereitstellen oder Autopilot den Eingabedatensatz automatisch in 80 % Trainingsdatensätze und 20 % Validierungsdatensätze aufteilen lassen. Die Trainingsdaten werden dann für die Kreuzvalidierung in k-Bereiche aufgeteilt, sodass für jeden Bereich eine OOF-Voraussage und ein Basismodell erstellt werden.
Diese OOF-Voraussagen werden als Merkmale verwendet, um ein Stapelmodell zu trainieren, das gleichzeitig Gewichtungen für jedes Basismodell lernt. Diese Gewichtungen werden verwendet, um die OOF-Voraussagen zu kombinieren, um die endgültige Voraussage zu bilden. Die Validierungsdatensätze für jeden Bereich werden für die Hyperparameteroptimierung aller Basismodelle und des Stapelmodells verwendet. Die Leistung der Validierungsdatensätze bestimmt, welches Basis- oder Stapelmodell das beste Modell ist, und dieses Modell wird als endgültiges Modell zurückgegeben.
