Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Ein Amazon SageMaker AI-Modellqualitätsbericht (auch als Leistungsbericht bezeichnet) bietet Einblicke und Qualitätsinformationen für den besten Modellkandidaten, der durch einen AutoML-Job generiert wurde. Dazu gehören Informationen über die Auftragsdetails, den Modellproblemtyp, die Zielfunktion und andere Informationen zum Problemtyp. Diese Anleitung zeigt, wie Sie die Leistungskennzahlen von Amazon SageMaker AI Autopilot grafisch oder als Rohdaten in einer JSON-Datei anzeigen können.
Bei Klassifizierungsproblemen umfasst der Modellqualitätsbericht beispielsweise Folgendes:
-
Verwechslungsmatrix
-
Fläche unter der Betriebskennlinie (AUC) des Empfängers
-
Informationen zum Verständnis falscher positiver und falscher negativer Ergebnisse
-
Kompromisse zwischen echten positiven und falsch positiven Ergebnissen
-
Kompromisse zwischen Präzision und Wiedererkennung
Autopilot bietet auch Leistungskennzahlen für all Ihre Kandidatenmodelle. Diese Metriken werden anhand aller Trainingsdaten berechnet und zur Schätzung der Modellleistung verwendet. Der Hauptarbeitsbereich umfasst diese Metriken standardmäßig. Die Art der Metrik hängt von der Art des Problems ab, das behandelt wird.
Eine Liste der verfügbaren Metriken, die von Autopilot unterstützt werden, finden Sie in der Amazon SageMaker API-Referenzdokumentation.
Sie können Ihre Modellkandidaten nach der entsprechenden Kennzahl sortieren, um Ihnen bei der Auswahl und Implementierung des Modells zu helfen, das Ihren Geschäftsanforderungen entspricht. Definitionen dieser Metriken finden Sie im Thema Autopilot-Kandidatenmetriken.
Gehen Sie wie folgt vor, um einen Leistungsbericht für einen Autopilot-Job anzuzeigen:
-
Wählen Sie im linken Navigationsbereich das Home-Symbol (
 ), um das Amazon SageMaker Studio Classic-Navigationsmenü auf oberster Ebene aufzurufen.
), um das Amazon SageMaker Studio Classic-Navigationsmenü auf oberster Ebene aufzurufen. -
Wählen Sie die AutoML-Karte aus dem Hauptarbeitsbereich aus. Dadurch wird eine neue AutoML-Registerkarte geöffnet.
-
Wählen Sie im Abschnitt Name den Autopilot-Job aus, der die Details enthält, die Sie untersuchen möchten. Dadurch wird eine neue Registerkarte für Autopilot-Jobs geöffnet.
-
Im Fenster Autopilot-Jobs werden die Metrikwerte einschließlich der objektiven Metrik für jedes Modell unter Modellname aufgeführt. Das beste Modell wird oben in der Liste unter Modellname aufgeführt und auf der Registerkarte Modelle hervorgehoben.
-
Um die Modelldetails zu überprüfen, wählen Sie das Modell aus, an dem Sie interessiert sind, und wählen Sie In Modelldetails anzeigen aus. Dadurch wird eine neue Registerkarte mit Modelldetails geöffnet.
-
-
Wählen Sie die Registerkarte Leistung zwischen der Registerkarte Erklärbarkeit und Artefakte.
-
Wählen Sie im oberen rechten Bereich der Registerkarte den Abwärtspfeil auf der Schaltfläche Leistungsberichte herunterladen aus.
-
Der Abwärtspfeil bietet zwei Optionen zum Anzeigen der Leistungskennzahlen des Autopiloten:
-
Sie können eine PDF des Leistungsberichts herunterladen, um die Kennzahlen grafisch anzuzeigen.
-
Sie können Metriken als Rohdaten anzeigen und als JSON-Datei herunterladen.
-
-
Anweisungen zum Erstellen und Ausführen eines AutoML-Jobs in SageMaker Studio Classic finden Sie unterErstellen Sie Regressions- oder Klassifizierungsjobs für Tabellendaten mithilfe der AutoML-API.
Der Leistungsbericht besteht aus zwei Abschnitten. Der erste enthält Einzelheiten über den Autopilot-Job, bei dem das Modell hergestellt wurde. Der zweite Abschnitt enthält einen Bericht zur Modellqualität.
Details zum Autopilot-Job
Dieser erste Abschnitt des Berichts enthält einige allgemeine Informationen über den Autopilot-Job, der das Modell hervorgebracht hat. Der Job enthält die folgenden Informationen:
-
Name des Autopilot-Kandidaten
-
Name des Autopilot-Jobs
-
Problemtypen
-
Zielmetrik
-
Optimierungsrichtung
Bericht zur Modellqualität
Informationen zur Modellqualität werden durch Autopilot-Modelleinsichten generiert. Der generierte Inhalt des Berichts hängt vom Problemtyp ab, mit dem er sich befasst hat: Regression, binäre Klassifikation oder Mehrklassen-Klassifizierung. Der Bericht gibt die Anzahl der Zeilen an, die im Bewertungsdatensatz enthalten waren, und den Zeitpunkt, zu dem die Auswertung stattfand.
Tabellen mit Metriken
Der erste Teil des Modellqualitätsberichts enthält Metriktabellen. Diese sind für die Art des Problems geeignet, das mit dem Modell behoben wurde.
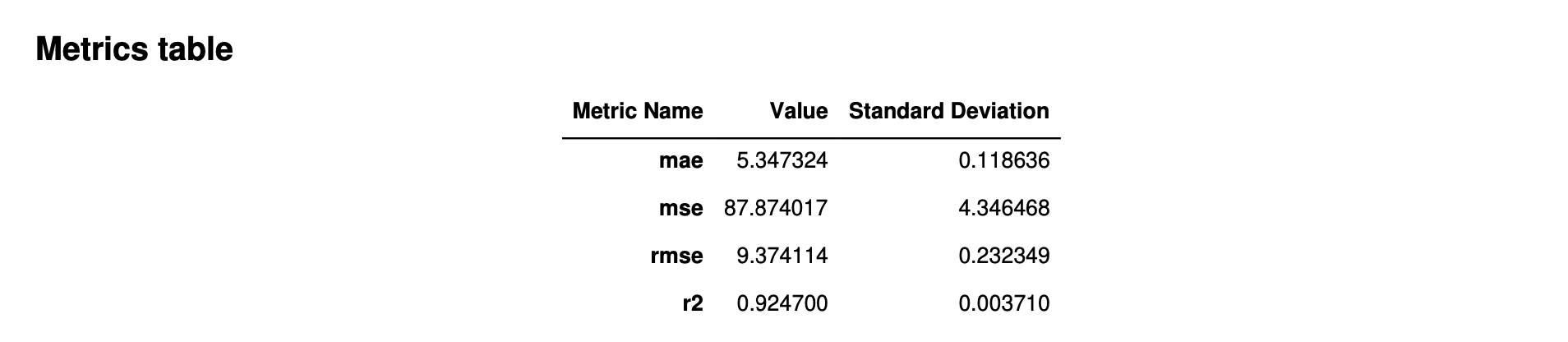
Die folgende Abbildung zeigt ein Beispiel für eine Metriktabelle, die Autopilot für ein Regressionsproblem generiert. Sie zeigt den Namen, den Wert und die Standardabweichung der Metrik.
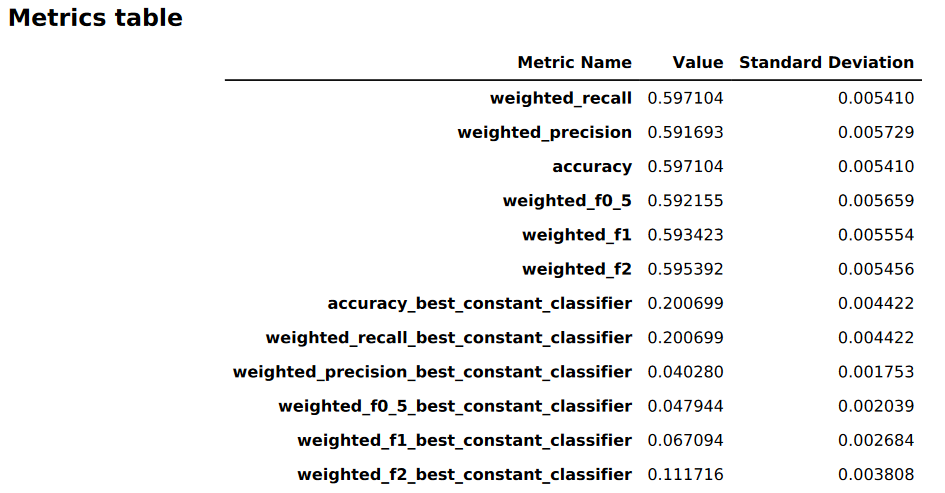
Die folgende Abbildung zeigt ein Beispiel für eine Metriktabelle, die Autopilot für eine Mehrklassen-Klassifizierung generiert. Sie zeigt den Namen, den Wert und die Standardabweichung der Metrik.
Informationen zur Leistung grafischer Modelle
Der zweite Teil des Modellqualitätsberichts enthält grafische Informationen, die Ihnen bei der Bewertung der Modellleistung helfen. Der Inhalt dieses Abschnitts hängt vom Problemtyp ab, der bei der Modellierung verwendet wird.
Die Fläche unter der Betriebskennlinie des Empfängers
Die Fläche unter der Betriebskennlinie des Empfängers stellt den Kompromiss zwischen echten positiven und falsch positiven Werten dar. Es handelt sich um eine branchenübliche Genauigkeitsmetrik, die für binäre Klassifikationsmodelle verwendet wird. AUC (Fläche unter der Kurve) misst die Fähigkeit des Modells, eine höhere Bewertung für positive Beispiele im Vergleich zu negativen Beispielen vorherzusagen. Die AUC-Metrik bietet ein aggregiertes Maß für die Modellleistung über alle möglichen Klassifizierungsschwellen hinweg.
Die AUC-Metrik gibt einen Dezimalwert zwischen 0 und 1 zurück. AUC-Werte nahe 1 weisen auf ein sehr genaues Machine-Learning-Modell hin. Werte um 0,5 weisen darauf hin, dass das Modell, nicht besser funktioniert als das Raten nach dem Zufallsprinzip. AUC-Werte nahe 0 deuten darauf hin, dass das Modell zwar die richtigen Muster gelernt hat, aber Vorhersagen trifft, die so ungenau wie möglich sind. Werte nahe Null können auf ein Problem mit den Daten hinweisen. Weitere Informationen zur AUC-Metrik finden Sie auf der Seite Receiver Operating Characteristic
Im Folgenden finden Sie ein Beispiel für einen Bereich unter der Grenzwertoptimierungskurve zur Bewertung von Vorhersagen, die anhand eines binären Klassifikationsmodells getroffen wurden. Die gestrichelte dünne Linie stellt den Bereich unter der Betriebskennlinie des Empfängers dar, den ein Modell, das no-better-than-random Erraten klassifiziert, mit einem AUC-Wert von 0,5 erreichen würde. Die Kurven genauerer Klassifikationsmodelle liegen über dieser zufälligen Ausgangsbasis, bei der die Rate der echten positiven Ergebnisse die Rate der falsch positiven Ergebnisse übersteigt. Der Bereich unter der Grenzwertoptimierungskurve, der die Leistung des binären Klassifikationsmodells darstellt, ist die dickere durchgezogene Linie.
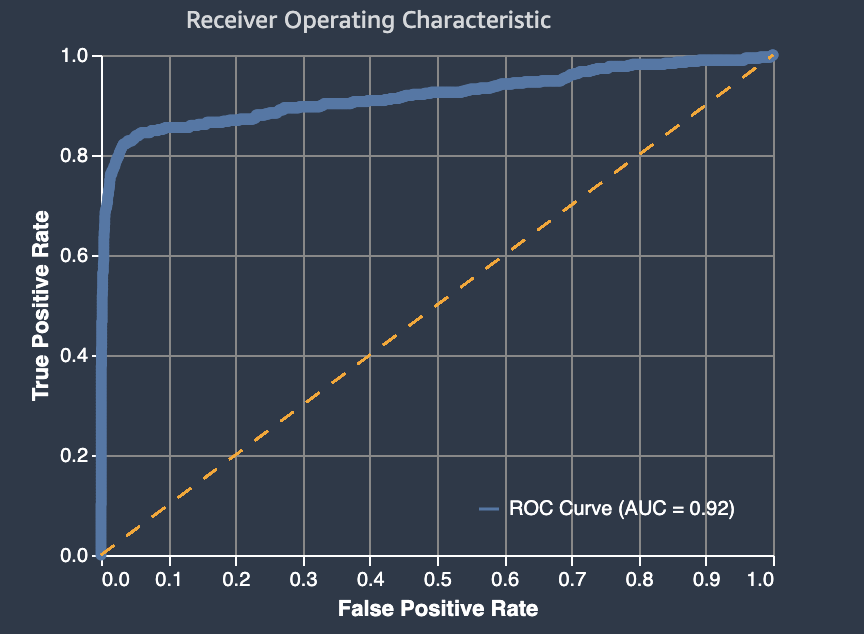
Eine Zusammenfassung der in der Grafik enthaltenen Komponenten Falsch-Positiv-Rate (FPR) und True-Positiv-Rate (TPR) ist wie folgt definiert.
-
Richtige Voraussagen
-
Richtig positiv (TP): Der vorhergesagte Wert ist 1, und der wahre Wert ist 1.
-
Richtig negativ (TN): Der vorhergesagte Wert ist 0 und der wahre Wert ist 0.
-
-
Falsche Voraussagen
-
Falsch positiv (FP): Der vorhergesagte Wert ist 1, aber der wahre Wert ist 0.
-
Falsch negativ (FN): Der vorhergesagte Wert ist 0, aber der wahre Wert ist 1.
-
Mit der Falsch-Positiv-Rate (FPR) wird der Anteil der richtig negativen Ergebnisse (TN), die fälschlicherweise als positiv (FP) vorhergesagt wurden, an der Summe von FP und TN gemessen. Der Bereich liegt zwischen 0 und 1. Ein kleinerer Wert gibt eine bessere Genauigkeit der Prognosen an.
-
FR = FP/(FP+TN)
Mit der Richtig-Positiv-Rate (TPR) wird der Anteil der richtig positiven Ergebnisse, die richtigerweise als positiv (TP) vorhergesagt wurden, an der Summe von TP und falsch negativen Ergebnissen (FN) gemessen. Der Bereich liegt zwischen 0 und 1. Ein größerer Wert gibt eine bessere prädiktive Richtigkeit an:
-
TPR = TP/(TP+FN)
Verwechslungsmatrix
Eine Verwechslungsmatrix bietet eine Möglichkeit, die Genauigkeit der Vorhersagen zu visualisieren, die von einem Modell für die binäre und die Mehrklassen-Klassifizierung für verschiedene Probleme getroffen wurden. Die Verwechslungsmatrix im Modellqualitätsbericht enthält Folgendes.
-
Die Anzahl und der Prozentsatz der richtigen und falschen Vorhersagen für die tatsächlichen Labels
-
Die Anzahl und der Prozentsatz der genauen Vorhersagen auf der Diagonale von der oberen linken zur unteren rechten Ecke
-
Die Anzahl und der Prozentsatz der ungenauen Vorhersagen auf der Diagonale von der oberen rechten zur unteren linken Ecke
Die falschen Vorhersagen in einer Verwechslungsmatrix sind die Verwechslungswerte.
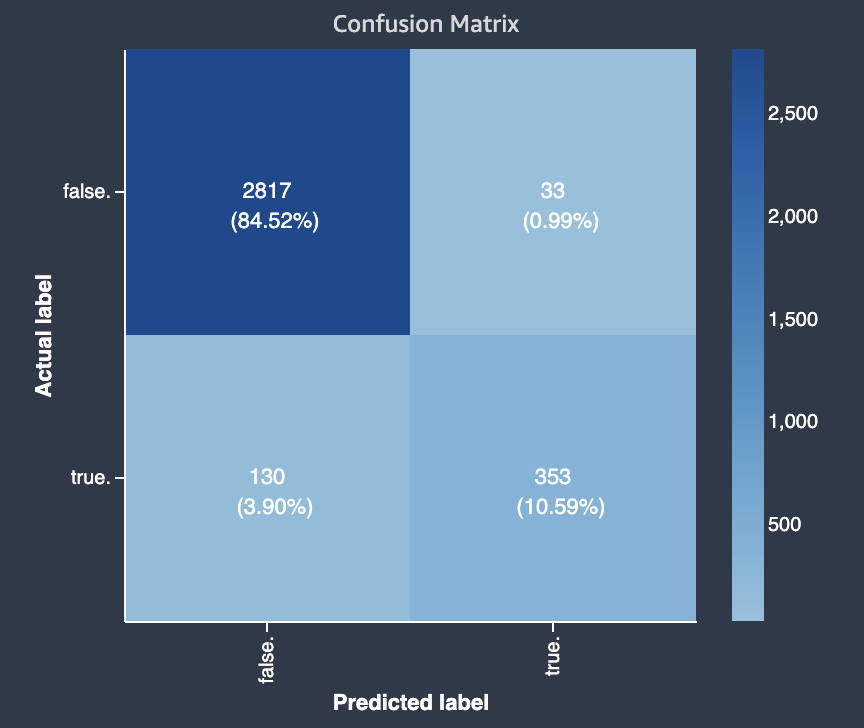
Das folgende Diagramm ist ein Beispiel für eine Verwechslungsmatrix für ein binäres Klassifikationsproblem. Sie umfasst die folgenden Informationen:
-
Die vertikale Achse ist in zwei Zeilen unterteilt, die echte und falsche tatsächliche Bezeichnungen enthalten.
-
Die horizontale Achse ist in zwei Spalten unterteilt, die wahre und falsche Bezeichnungen enthalten, die vom Modell vorhergesagt wurden.
-
Der Farbbalken weist einer größeren Anzahl von Stichproben einen dunkleren Farbton zu, um die Anzahl der Werte, die in jeder Kategorie klassifiziert wurden, visuell darzustellen.
In diesem Beispiel hat das Modell die tatsächlichen 2817 falschen Werte korrekt und 353 tatsächliche wahre Werte korrekt vorhergesagt. Das Modell prognostizierte fälschlicherweise 130 tatsächliche wahre Werte als falsch und 33 tatsächliche falsche Werte als wahr. Der Unterschied im Ton weist darauf hin, dass der Datensatz nicht ausgewogen ist. Das Ungleichgewicht ist darauf zurückzuführen, dass es viel mehr tatsächliche falsche Bezeichnungen als tatsächliche wahre Bezeichnungen gibt.
Das folgende Diagramm ist ein Beispiel für eine Konfusionsmatrix für ein Mehrklassen-Klassifizierungsproblem. Die Verwechslungsmatrix im Modellqualitätsbericht enthält Folgendes.
-
Die vertikale Achse ist in drei Zeilen unterteilt, die drei unterschiedliche tatsächliche Bezeichnungen enthalten.
-
Die horizontale Achse ist in drei Spalten unterteilt, die Bezeichnungen enthalten, die vom Modell vorhergesagt wurden.
-
Der Farbbalken weist einer größeren Anzahl von Stichproben einen dunkleren Farbton zu, um die Anzahl der Werte, die in jeder Kategorie klassifiziert wurden, visuell darzustellen.
Im folgenden Beispiel hat das Modell die tatsächlichen 354 Werte für Bezeichnung f, 1094 Werte für Bezeichnung i und 852 Werte für Bezeichnung m korrekt vorhergesagt. Der Unterschied im Ton weist darauf hin, dass der Datensatz nicht ausgewogen ist, da es für den Wert i viel mehr Bezeichnungen gibt als für f oder m.
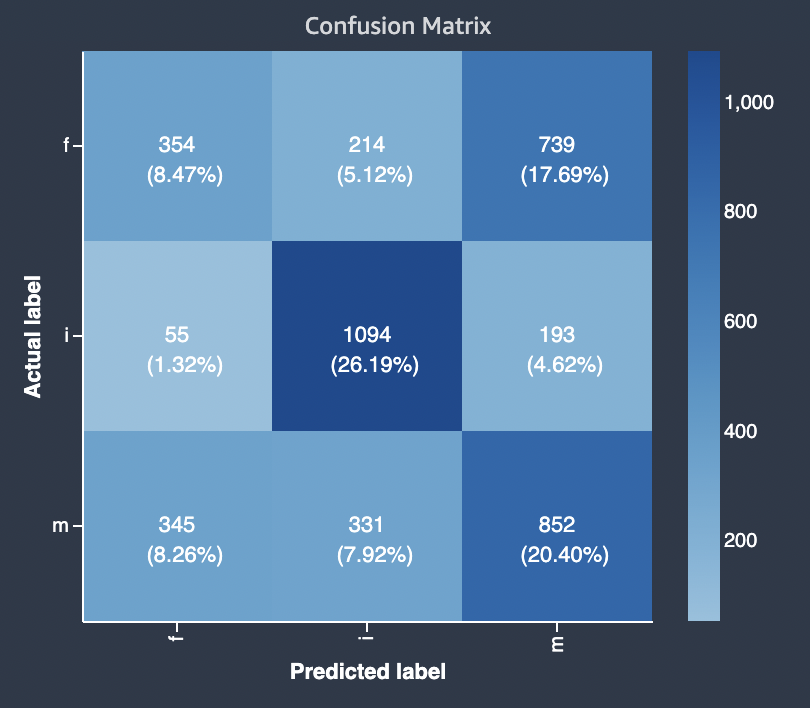
Die Verwechslungsmatrix im bereitgestellten Modellqualitätsbericht bietet Platz für maximal 15 Bezeichnungen für Problemtypen bei der Mehrklassen-Klassifizierung. Wenn eine Zeile, die einer Bezeichnung entspricht, einen Nan-Wert enthält, bedeutet dies, dass der Validierungsdatensatz, der zur Überprüfung der Modellvorhersagen verwendet wurde, keine Daten mit dieser Bezeichnung enthält.
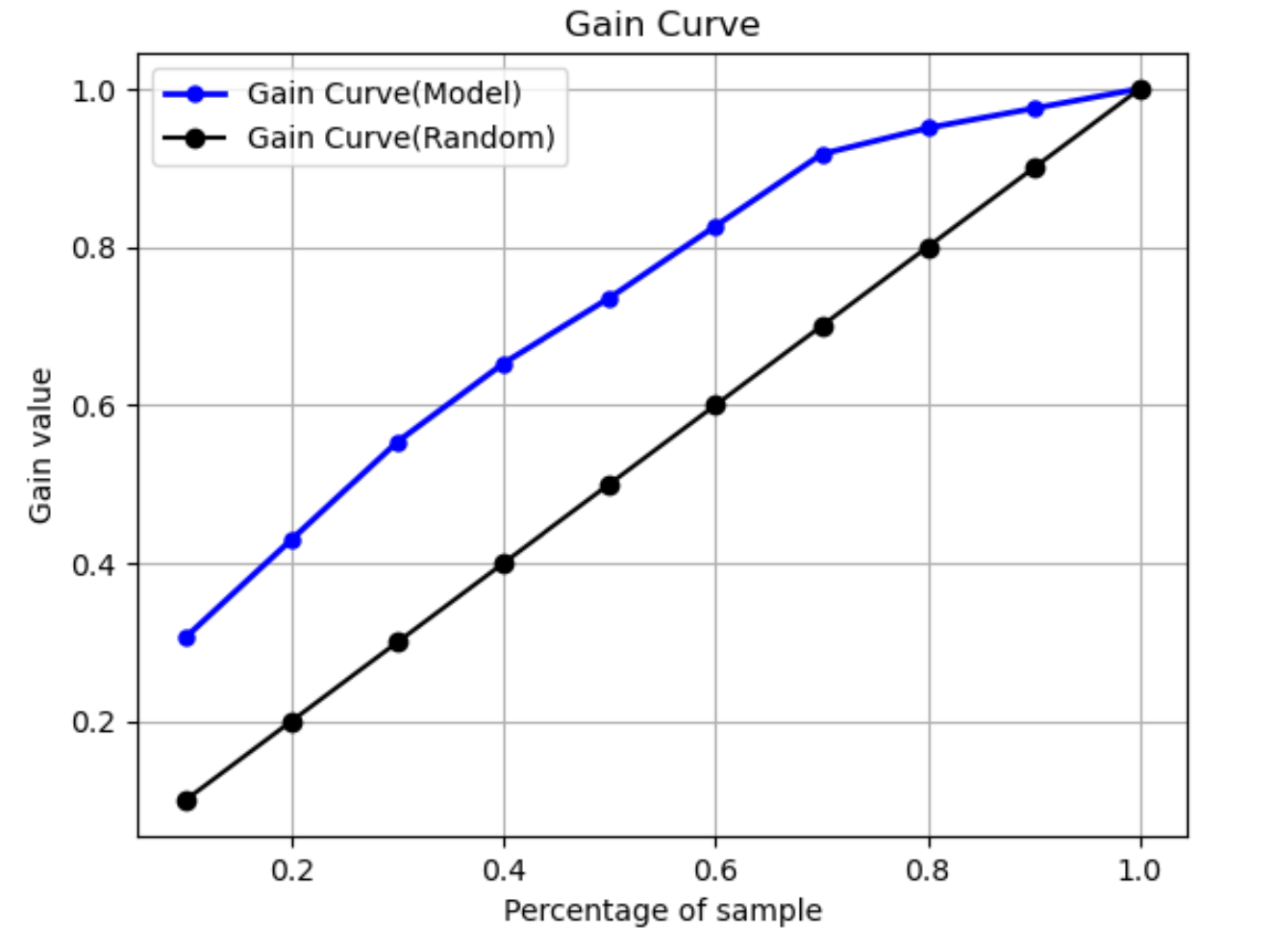
Gewinnkurve
Bei der binären Klassifikation sagt eine Gewinnkurve den kumulativen Nutzen voraus, der sich ergibt, wenn ein Prozentsatz des Datensatzes verwendet wird, um eine positive Bezeichnung zu finden. Der Gewinnwert wird während des Trainings berechnet, indem die kumulierte Anzahl positiver Beobachtungen durch die Gesamtzahl der positiven Beobachtungen in den Daten pro Dezil dividiert wird. Wenn das während des Trainings erstellte Klassifikationsmodell repräsentativ für die unsichtbaren Daten ist, können Sie anhand der Gewinnkurve den Prozentsatz der Daten vorhersagen, den Sie als Ziel angeben müssen, um einen Prozentsatz positiver Bezeichnungen zu erhalten. Je höher der Prozentsatz des verwendeten Datensatzes ist, desto höher ist der Prozentsatz der gefundenen positiven Bezeichnungen.
In der folgenden Beispielgrafik ist die Gewinnkurve die Linie mit sich ändernder Steigung. Die gerade Linie ist der Prozentsatz der positiven Bezeichnungen, die durch zufällige Auswahl eines Prozentsatzes der Daten aus dem Datensatz gefunden wurden. Wenn Sie 20 % des Datensatzes als Ziel auswählen, würden Sie erwarten, mehr als 40 % der positiven Bezeichnungen zu finden. Als Beispiel könnten Sie erwägen, eine Gewinnkurve zu verwenden, um Ihre Bemühungen im Rahmen einer Marketingkampagne zu ermitteln. Wenn wir unser Beispiel für eine Gewinnkurve verwenden, würden Sie, wenn 83 % der Menschen in einer Nachbarschaft Cookies kaufen, eine Werbung an etwa 60 % der Nachbarschaft senden.
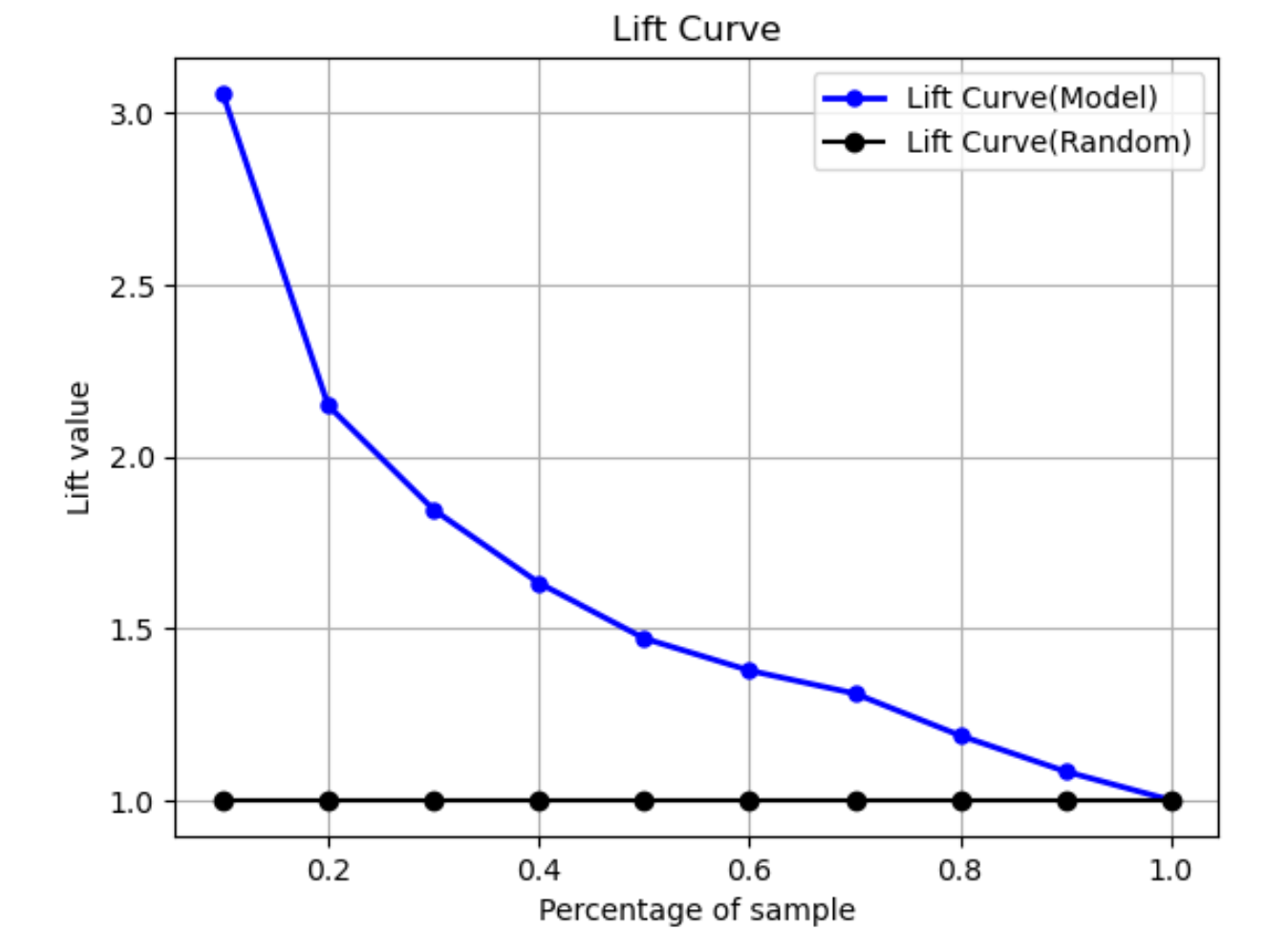
Auftriebskurve
Bei der binären Klassifikation veranschaulicht die Auftriebskurve den Anstieg, den die Verwendung eines trainierten Modells zur Vorhersage der Wahrscheinlichkeit, eine positive Bezeichnung zu finden, im Vergleich zu einer zufälligen Schätzung ergibt. Der Auftriebswert wird während des Trainings anhand des Verhältnisses der prozentualen Zunahme zum Verhältnis der positiven Bezeichnungen bei jedem Dezil berechnet. Wenn das während des Trainings erstellte Modell repräsentativ für die bisher unbekannten Daten ist, können Sie anhand der Auftriebskurve vorhersagen, welchen Nutzen die Verwendung des Modells gegenüber zufälligen Schätzungen bietet.
In der folgenden Beispielgrafik ist die Auftriebskurve die Linie mit sich ändernder Steigung. Die gerade Linie ist die Auftriebskurve, die mit der zufälligen Auswahl des entsprechenden Prozentsatzes aus dem Datensatz verknüpft ist. Wenn Sie 40 % des Datensatzes mit den Klassifikationsbezeichnungen Ihres Modells als Ziel angeben, würden Sie erwarten, dass Sie etwa das 1,7-fache der positiven Bezeichnungen finden würden, die Sie bei einer zufälligen Auswahl von 40 % der unsichtbaren Daten gefunden hätten.
Präzisions-Wiedererkennungs-Kurve
Die Präzisions-Wiedererkennungs-Kurve stellt den Kompromiss zwischen Präzision und Wiedererkennung bei binären Klassifikationsproblemen dar.
Mit der Präzision wird der Anteil der tatsächlich als positiv prognostizierten positiven Ergebnisse (TP) an allen positiven Prognosen (TP und falsch positiv) gemessen. Der Bereich liegt zwischen 0 und 1. Ein größerer Wert gibt eine bessere Genauigkeit in den vorhergesagten Werten an.
-
Präzision = TP/(TP+FP)
Mit Recall wird der Anteil der tatsächlich positiven Ergebnisse, die als positiv (TP) prognostiziert wurden, an allen tatsächlich positiven Prognosen (TP und falsch negativ) gemessen. Dieser Wert wird auch als Sensitivität oder als True-Positiv-Rate bezeichnet. Der Bereich liegt zwischen 0 und 1. Ein größerer Wert bedeutet, dass positive Werte aus der Probe besser erkannt werden können.
-
Wiedererkennung = TP/(TP+FN)
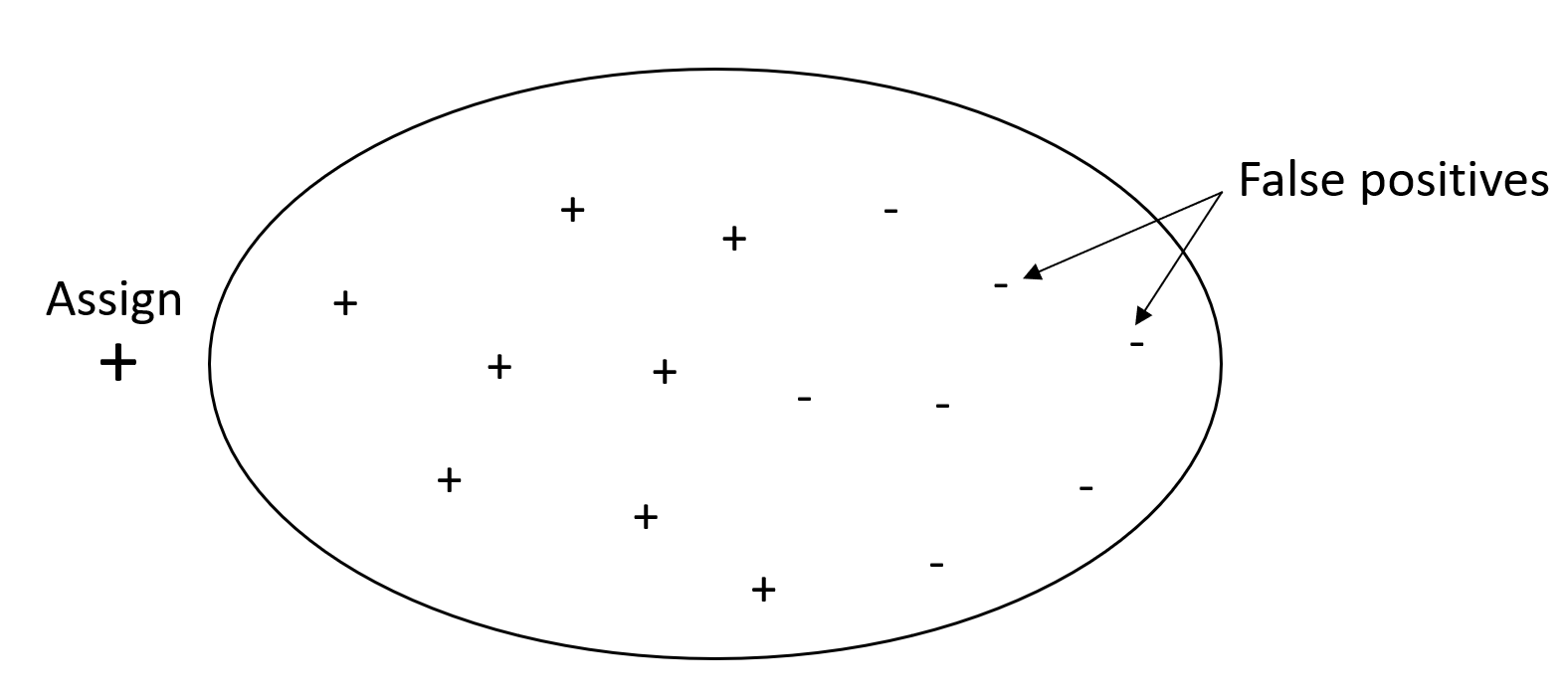
Das Ziel eines Klassifikationsproblems besteht darin, so viele Elemente wie möglich korrekt zu kennzeichnen. Ein System mit hohem Wiedererkennungsvermögen, aber geringer Präzision gibt einen hohen Prozentsatz falsch positiver Ergebnisse zurück.
Die folgende Grafik zeigt einen Spamfilter, der jede E-Mail als Spam markiert. Er hat einen hohen Wiedererkennungsvermögen, aber eine geringe Präzision, da beim Abrufen keine falsch positiven Ergebnisse gemessen werden.
Geben Sie der Wiedererkennung mehr Gewicht als der Präzision, wenn bei Ihrem Problem eine niedrige Strafe für falsch positive Werte, aber eine hohe Strafe für das Fehlen eines richtig positiven Ergebnisses gilt. Zum Beispiel die Erkennung einer drohenden Kollision in einem selbstfahrenden Fahrzeug.
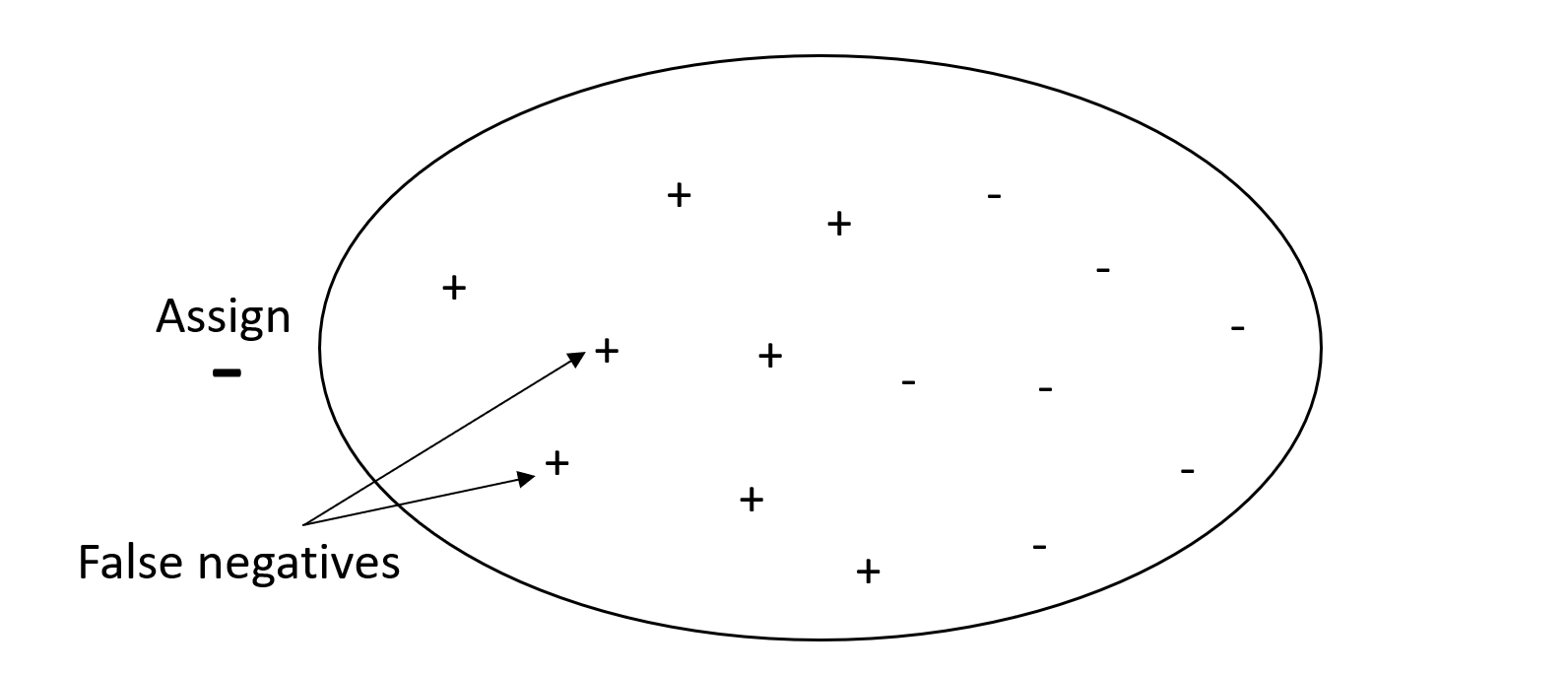
Im Gegensatz dazu gibt ein System mit hohem Wiedererkennungsvermögen, aber geringer Präzision einen hohen Prozentsatz falsch positiver Ergebnisse zurück. Ein Spamfilter, der jede E-Mail als wünschenswert (nicht als Spam) markiert, hat eine hohe Präzision, erinnert sich aber kaum daran, weil mit Präzision keine falsch negativen Nachrichten gemessen werden.
Wenn bei Ihrem Problem eine niedrige Strafe für falsch negative Werte, aber eine hohe Strafe für das Fehlen eines richtig negativen Ergebnisses gilt, geben Sie der Präzision mehr Gewicht als der Wiedererkennung. Zum Beispiel das Kennzeichnen eines verdächtigen Filters für eine Steuerprüfung.
Die folgende Grafik zeigt einen Spamfilter mit hoher Präzision, aber geringem Wiedererkennungsvermögen, da Falschmeldungen mit Präzision nicht gemessen werden können.
Ein Modell, das Vorhersagen sowohl mit hoher Präzision als auch mit hohem Wiedererkennungsvermögen trifft, führt zu einer großen Anzahl korrekt beschrifteter Ergebnisse. Weitere Informationen finden Sie unter Präzision und Wiedererkennung
Fläche unter der Präzisions-Wiedererkennungs-Kurve (AUPRC)
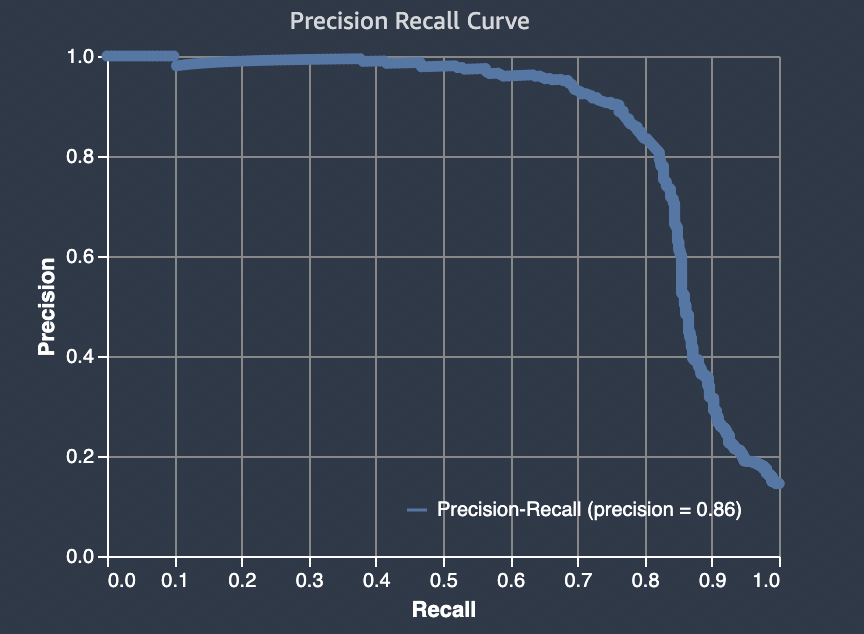
Bei binären Klassifizierungsproblemen enthält Amazon SageMaker Autopilot ein Diagramm der Fläche unter der Precision-Recall-Kurve (AUPRC). Die AUPRC-Metrik bietet eine aggregierte Messung der Modellleistung über alle möglichen Klassifizierungsschwellen hinweg und verwendet sowohl Präzision als auch Wiedererkennung. AUPRC berücksichtigt nicht die Anzahl der echten Negativwerte. Daher kann es nützlich sein, die Modellleistung in Fällen zu bewerten, in denen die Daten eine große Anzahl von echten negativen Ergebnissen enthalten. Zum Beispiel, um ein Gen zu modellieren, das eine seltene Mutation enthält.
Die folgende Grafik ist ein Beispiel für ein AUPRC-Diagramm. Der höchste Wert für die Präzision ist 1 und der Wert für die Wiedererkennung ist 0. In der unteren rechten Ecke des Diagramms steht für Wiedererkennung der höchste Wert (1) und für Präzision der Wert 0. Zwischen diesen beiden Punkten veranschaulicht die AUPRC-Kurve den Kompromiss zwischen Präzision und Wiedererkennung bei unterschiedlichen Schwellenwerten.
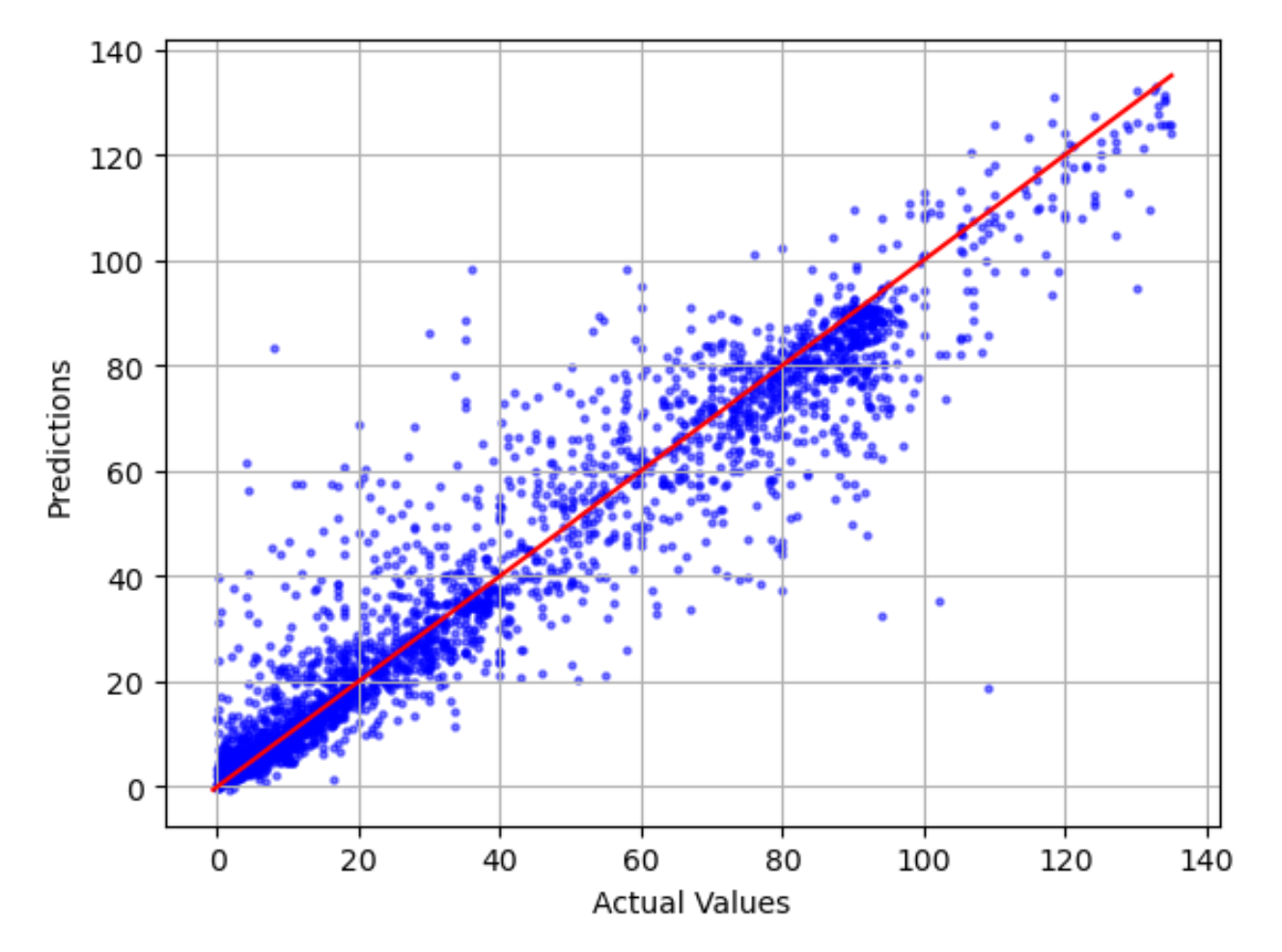
Das tatsächliche Diagramm im Vergleich zum prognostizierten Diagramm
Das Diagramm zwischen tatsächlichen und prognostizierten Modellwerten zeigt die Differenz zwischen den tatsächlichen und den vorhergesagten Modellwerten. In der folgenden Beispielgrafik ist die durchgezogene Linie eine lineare Linie mit der besten Anpassung. Wenn das Modell zu 100 % genau wäre, würde jeder vorhergesagte Punkt seinem entsprechenden tatsächlichen Punkt entsprechen und auf dieser Linie mit der besten Anpassung liegen. Die Entfernung von der Linie mit der besten Anpassung ist ein optischer Hinweis auf einen Modellfehler. Je größer der Abstand von der Linie mit der besten Anpassung ist, desto größer ist der Modellfehler.
Standardisiertes Residuendiagramm
Ein standardisiertes Residuendiagramm beinhaltet die folgenden statistischen Begriffe:
residual-
Ein (rohes) Residuum zeigt die Differenz zwischen den tatsächlichen Werten und den von Ihrem Modell vorhergesagten Werten. Je größer die Differenz, desto größer der Restwert.
standard deviation-
Die Standardabweichung ist ein Maß dafür, wie Werte von einem Durchschnittswert abweichen. Eine hohe Standardabweichung weist darauf hin, dass sich viele Werte stark von ihrem Durchschnittswert unterscheiden. Eine geringe Standardabweichung weist darauf hin, dass viele Werte nahe an ihrem Durchschnittswert liegen.
standardized residual-
Ein standardisiertes Residuum dividiert die Rohresiduen durch ihre Standardabweichung. Standardisierte Residuen haben Einheiten der Standardabweichung und sind nützlich, um Ausreißer in Daten zu identifizieren, unabhängig vom Skalenunterschied der Rohresiduen. Wenn ein standardisiertes Residuum viel kleiner oder größer als die anderen standardisierten Residuen ist, deutet dies darauf hin, dass das Modell nicht gut zu diesen Beobachtungen passt.
Das standardisierte Residuendiagramm misst die Stärke der Differenz zwischen beobachteten und erwarteten Werten. Der tatsächlich vorhergesagte Wert wird auf der X-Achse angezeigt. Ein Punkt mit einem Wert, der größer als der absolute Wert 3 ist, wird üblicherweise als Ausreißer angesehen.
Die folgende Beispielgrafik zeigt, dass eine große Anzahl standardisierter Residuen auf der horizontalen Achse um 0 gruppiert ist. Die Werte nahe Null deuten darauf hin, dass das Modell gut an diese Punkte angepasst ist. Die Punkte am oberen und unteren Rand des Diagramms werden vom Modell nicht gut vorhergesagt.
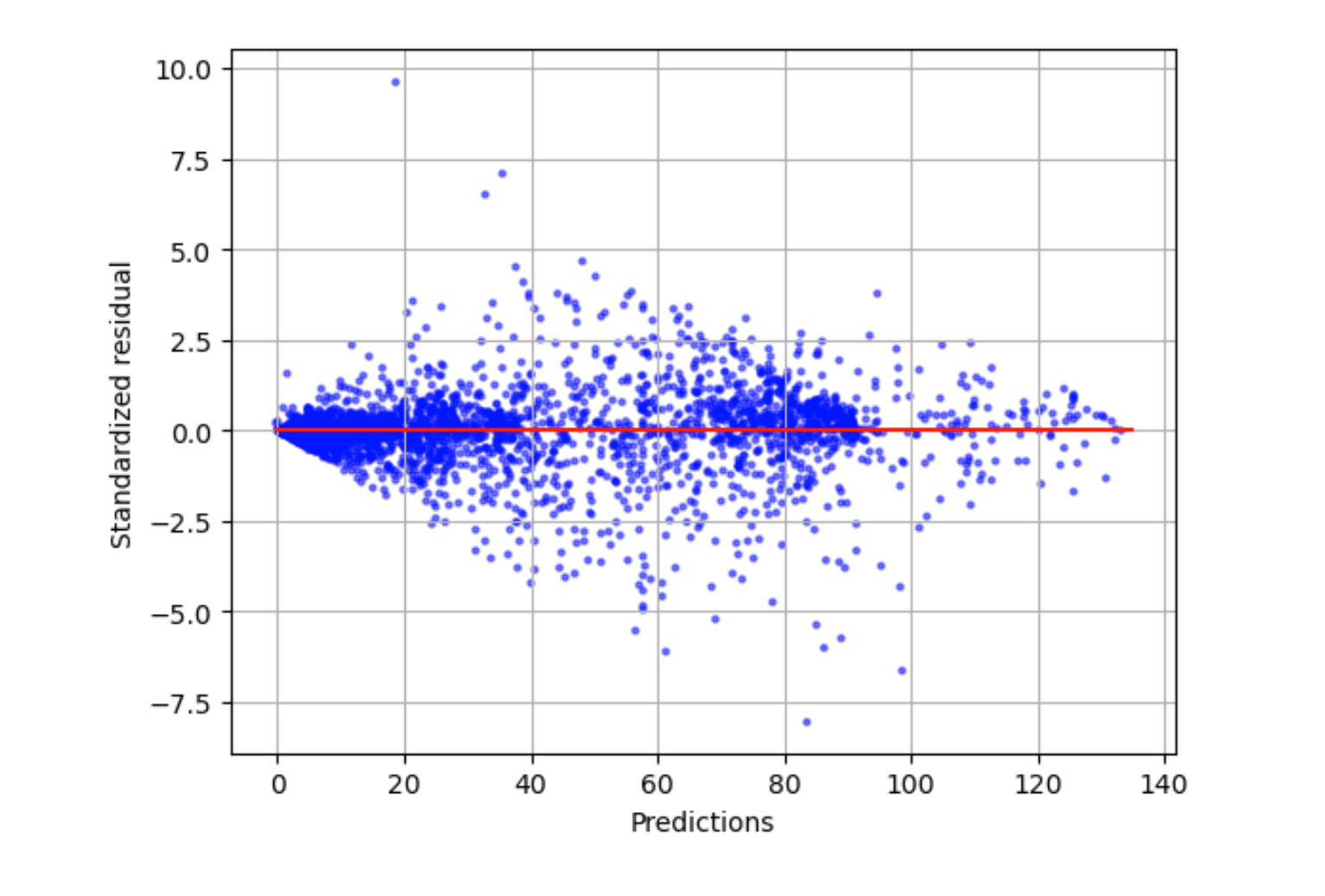
Residuenhistogramm
Ein standardisiertes Residuenhistogramm beinhaltet die folgenden statistischen Begriffe:
residual-
Ein (rohes) Residuum zeigt die Differenz zwischen den tatsächlichen Werten und den von Ihrem Modell vorhergesagten Werten. Je größer die Differenz, desto größer der Restwert.
standard deviation-
Die Standardabweichung ist ein Maß dafür, wie stark Werte von einem Durchschnittswert abweichen. Eine hohe Standardabweichung weist darauf hin, dass sich viele Werte stark von ihrem Durchschnittswert unterscheiden. Eine geringe Standardabweichung weist darauf hin, dass viele Werte nahe an ihrem Durchschnittswert liegen.
standardized residual-
Ein standardisiertes Residuum dividiert die Rohresiduen durch ihre Standardabweichung. Standardisierte Residuen haben Einheiten der Standardabweichung. Diese sind nützlich, um Ausreißer in Daten zu identifizieren, unabhängig vom Skalenunterschied der Rohresiduen. Wenn ein standardisiertes Residuum viel kleiner oder größer als die anderen standardisierten Residuen ist, würde dies darauf hindeuten, dass das Modell nicht gut zu diesen Beobachtungen passt.
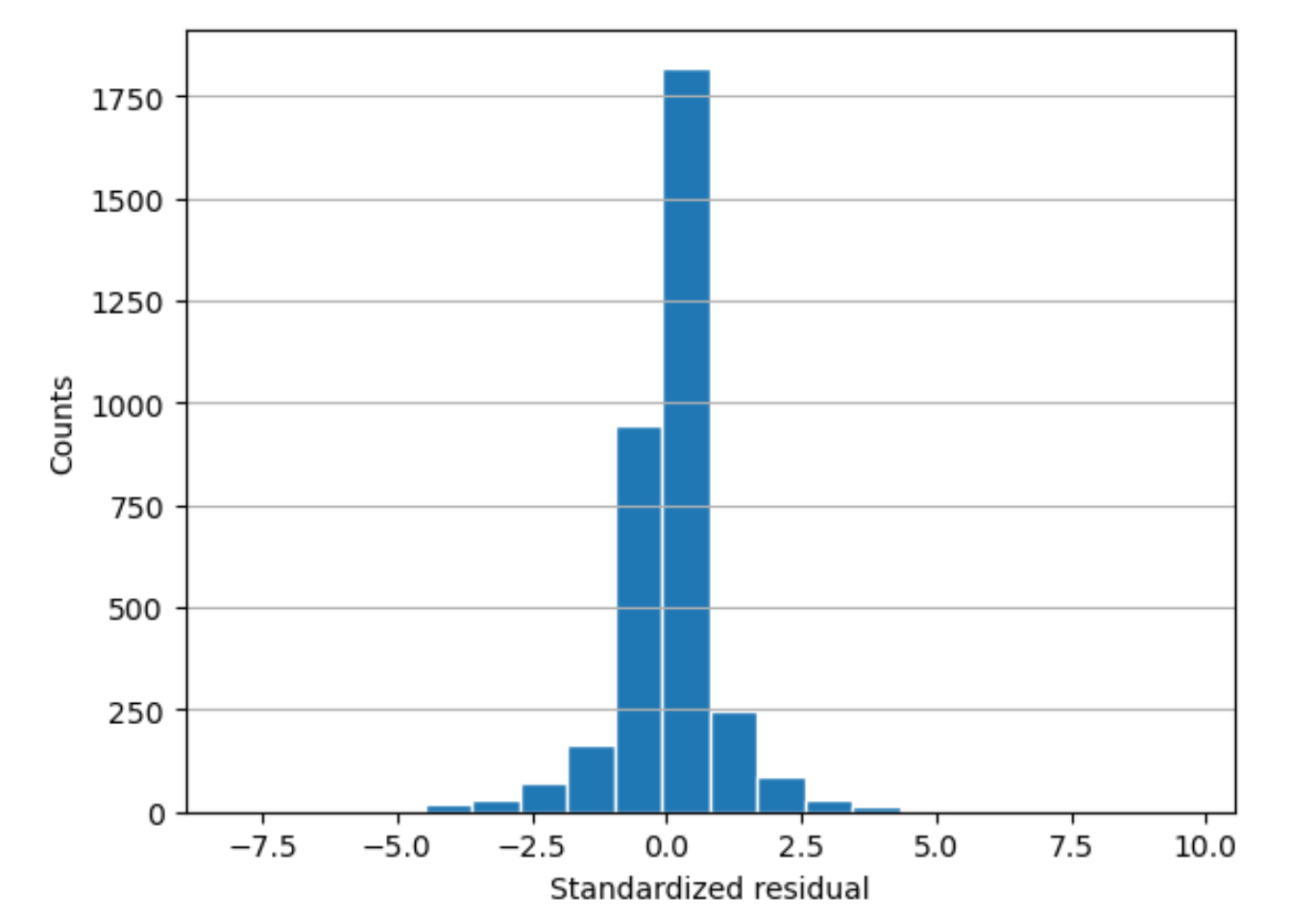
histogram-
Ein Histogramm ist ein Diagramm, das zeigt, wie oft ein Wert aufgetreten ist.
Das Residuenhistogramm zeigt die Verteilung der standardisierten Restwerte. Ein Histogramm, das glockenförmig angeordnet und auf Null zentriert ist, deutet darauf hin, dass das Modell keinen spezifischen Zielwertbereich systematisch über- oder unterschätzt.
In der folgenden Grafik deuten die standardisierten Restwerte darauf hin, dass das Modell gut an die Daten angepasst ist. Wenn in der Grafik Werte angezeigt würden, die weit vom Mittelwert entfernt sind, würde dies darauf hindeuten, dass diese Werte nicht gut zum Modell passen.