Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen Sie einen Multi-Model Endpunkt
Sie können die SageMaker AI-Konsole oder die verwenden, AWS SDK für Python (Boto) um einen Endpunkt mit mehreren Modellen zu erstellen. Informationen dazu, wie ein CPU- oder GPU-gestützter Endpunkt über die Konsole erstellt wird, finden Sie im Konsolenverfahren in den folgenden Abschnitten. Wenn Sie mit dem einen Endpunkt mit mehreren Modellen erstellen möchten AWS SDK für Python (Boto), verwenden Sie entweder das CPU- oder GPU-Verfahren in den folgenden Abschnitten. Die CPU- und GPU-Workflows sind ähnlich, weisen jedoch mehrere Unterschiede auf, z. B. die Container-Anforderungen.
Themen
Erstellen eines Multimodell-Endpunkts (Konsole)
Über die Konsole können Sie CPU- und GPU-gestützte Multimodell-Endpunkte erstellen. Gehen Sie wie folgt vor, um über die SageMaker AI-Konsole einen Endpunkt mit mehreren Modellen zu erstellen.
So erstellen Sie einen Multimodell-Endpunkt (Konsole)
-
Öffnen Sie die Amazon SageMaker AI-Konsole unter https://console.aws.amazon.com/sagemaker/
. -
Wählen Sie Model (Modell) und wählen Sie dann aus der Gruppe Inference (Inferenz) die Option Create model (Modell erstellen) aus.
-
Geben Sie für Model name (Modellname) einen Namen ein.
-
Wählen Sie für IAM-Rolle eine IAM-Rolle bzw. erstellen Sie eine, die mit der
AmazonSageMakerFullAccessIAM-Richtlinie verknüpft ist. -
Wählen Sie im Abschnitt Containerdefinition für Modellartefakte und Optionen für Inference-Bilder bereitstellen die Option Mehrere Modelle verwenden aus.
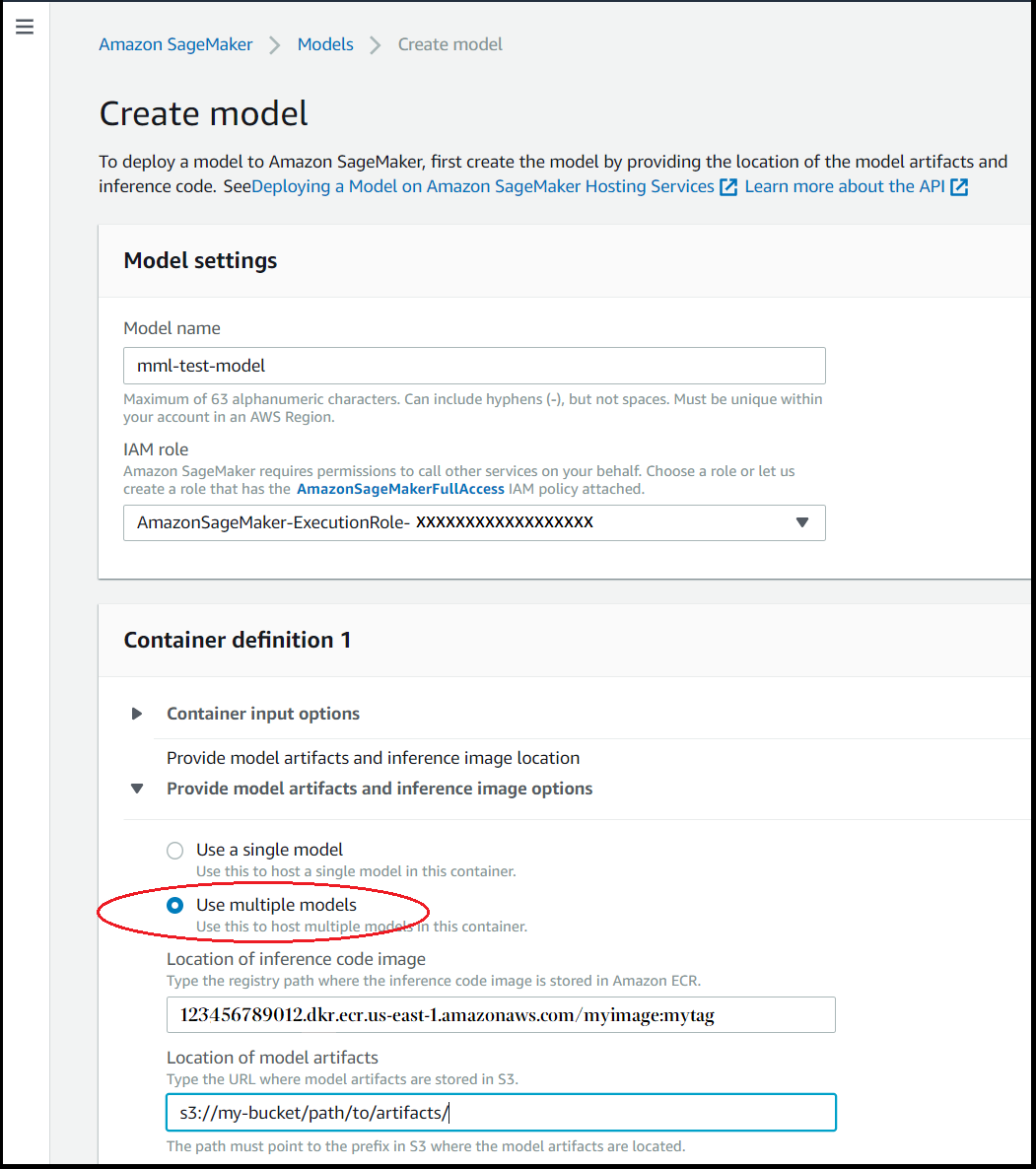
-
Geben Sie für das Inference-Container-Image den Amazon ECR-Pfad für Ihr gewünschtes Container-Image ein.
Für GPU-Modelle müssen Sie einen Container verwenden, der vom NVIDIA Triton Inference Server unterstützt wird. Eine Liste der Container-Images, die mit GPU-gestützten Endpunkten funktionieren, finden Sie in den NVIDIA Triton Inference Containers (nur SM-Unterstützung)
. Weitere Informationen zum NVIDIA Triton Inference Server finden Sie unter Verwenden von Triton Inference Server mit KI. SageMaker -
Wählen Sie Modell erstellen aus.
-
Stellen Sie Ihren Multimodell-Endpunkt genauso wie einen Einzelmodell-Endpunkt bereit. Detaillierte Anweisungen finden Sie unter Stellen Sie das Modell für SageMaker AI Hosting Services bereit.
Erstellen Sie einen Endpunkt mit mehreren Modellen mithilfe von CPUs mit AWS SDK für Python (Boto3)
Erstellen Sie mit Hilfe des folgenden Abschnitts einen durch CPU-Instances unterstützten Multimodell-Endpunkt. Sie erstellen einen Endpunkt mit mehreren Modellen mithilfe der Amazon SageMaker AI create_modelcreate_endpointcreate_endpoint_configMode-Parameterwert übergeben, MultiModel. Sie müssen auch das Feld ModelDataUrl übergeben, das das Präfix in Amazon S3 angibt, in dem sich die Modellartefakte befinden, anstatt den Pfad zu einem Artefakt mit nur einem Modell, wie beim Bereitstellen eines einzelnen Modells.
Ein Beispiel-Notebook, das SageMaker KI verwendet, um mehrere XGBoost-Modelle auf einem Endpunkt bereitzustellen, finden Sie unter Multi-Model Endpoint XGBoost
Im folgenden Verfahren werden die wichtigsten Schritte beschrieben, die in diesem Beispiel zum Erstellen eines Multimodell-Endpunkts mit CPU-Unterstützung verwendet werden.
Um das Modell bereitzustellen (AWS SDK für Python (Boot 3)
-
Besorgen Sie sich einen Container mit einem Image, das die Bereitstellung von Multimodell-Endpunkten unterstützt. Eine Liste der integrierten Algorithmen und Framework-Container, die Multimodell-Endpunkte unterstützen, finden Sie unter Unterstützte Algorithmen, Frameworks und Instances für Multimodell-Endpunkte. In diesem Beispiel verwenden wir den integrierten Algorithmus K-Nearest Algorithmus für Nachbarn (k-NN). Wir rufen die SageMaker Python-SDK-Utility-Funktion
image_uris.retrieve()auf, um die Adresse für das integrierte K-Nearest Neighbors-Algorithmus-Image abzurufen.import sagemaker region = sagemaker_session.boto_region_name image = sagemaker.image_uris.retrieve("knn",region=region) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } -
Holen Sie sich einen AWS SDK für Python (Boto3) SageMaker AI-Client und erstellen Sie das Modell, das diesen Container verwendet.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Optional) Wenn Sie eine serielle Inferenz-Pipeline verwenden, rufen Sie die zusätzlichen Container ab, die in der Pipeline enthalten sein sollen, und fügen sie in das Argument
ContainersvonCreateModelein:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )Anmerkung
Sie können in einer seriellen Inferenz-Pipeline jeweils nur einen Multimodell-fähigen Endpunkt verwenden.
-
(Optional) Wenn Ihr Anwendungsfall vom Modell-Caching nicht profitiert, setzen Sie den Wert des Feldes
ModelCacheSettingdes ParametersMultiModelConfigaufDisabledund nehmen Sie ihn in das ArgumentContainerdes Aufrufs voncreate_modelauf. Der Wert für das FeldModelCacheSettingist standardmäßigEnabled.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Konfigurieren Sie den Multimodell-Endpunkt für das Modell. Wir empfehlen, Ihre Endpunkte mit mindestens zwei Instances zu konfigurieren. Auf diese Weise kann SageMaker KI einen hochverfügbaren Satz von Vorhersagen für mehrere Availability Zones für die Modelle bereitstellen.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.m4.xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] )Anmerkung
Sie können in einer seriellen Inferenz-Pipeline jeweils nur einen Multimodell-fähigen Endpunkt verwenden.
-
Erstellen Sie den Multimodell-Endpunkt mit den Parametern
EndpointNameundEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
Erstellen Sie einen Endpunkt mit mehreren Modellen mithilfe von GPUs mit AWS SDK für Python (Boto3)
Erstellen Sie mit Hilfe des folgenden Abschnitts einen durch GPU unterstützten Multimodell-Endpunkt. Sie erstellen einen Endpunkt mit mehreren Modellen mithilfe von Amazon SageMaker AI und create_endpointcreate_modelcreate_endpoint_configMode-Parameterwert übergeben, MultiModel. Sie müssen auch das Feld ModelDataUrl übergeben, das das Präfix in Amazon S3 angibt, in dem sich die Modellartefakte befinden, anstatt den Pfad zu einem Artefakt mit nur einem Modell, wie beim Bereitstellen eines einzelnen Modells. Für GPU-gestützte Multimodell-Endpunkte müssen Sie außerdem einen Container mit dem NVIDIA Triton Inference Server verwenden, der für die Ausführung auf GPU-Instances optimiert ist. Eine Liste der Container-Images, die mit GPU-gestützten Endpunkten funktionieren, finden Sie in den NVIDIA Triton Inference Containers (nur SM-Unterstützung)
Ein Beispiel-Notizbuch, das demonstriert, wie ein von GPUs unterstützter Multimodell-Endpoint erstellt wird, finden Sie unter Ausführen mehrerer Deep-Learning-Modelle auf GPUs mit Amazon SageMaker Multi-model AI-Endpunkten
Das folgende Verfahren beschreibt die wichtigsten Schritte zur Erstellung eines GPU-gestützten Multimodell-Endpunkts.
Um das Modell bereitzustellen (AWS SDK für Python (Boot 3)
-
Definieren Sie das Container-Image. Um einen Endpunkt mit mehreren Modellen mit GPU-Unterstützung für ResNet Modelle zu erstellen, definieren Sie den Container so, dass er das NVIDIA Triton Server-Image verwendet. Dieser Container unterstützt Multimodell-Endpunkte und ist für die Ausführung auf GPU-Instances optimiert. Wir rufen die SageMaker AI-Python-SDK-Utility-Funktion
image_uris.retrieve()auf, um die Adresse für das Bild abzurufen. Beispiel:import sagemaker region = sagemaker_session.boto_region_name // Find the sagemaker-tritonserver image at // https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-triton/resnet50/triton_resnet50.ipynb // Find available tags at https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only image = "<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/sagemaker-tritonserver:<TAG>".format( account_id=account_id_map[region], region=region ) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel', "Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "resnet"}, } -
Holen Sie sich einen AWS SDK für Python (Boto3) SageMaker AI-Client und erstellen Sie das Modell, das diesen Container verwendet.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Optional) Wenn Sie eine serielle Inferenz-Pipeline verwenden, rufen Sie die zusätzlichen Container ab, die in der Pipeline enthalten sein sollen, und fügen sie in das Argument
ContainersvonCreateModelein:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )Anmerkung
Sie können in einer seriellen Inferenz-Pipeline jeweils nur einen Multimodell-fähigen Endpunkt verwenden.
-
(Optional) Wenn Ihr Anwendungsfall vom Modell-Caching nicht profitiert, setzen Sie den Wert des Feldes
ModelCacheSettingdes ParametersMultiModelConfigaufDisabledund nehmen Sie ihn in das ArgumentContainerdes Aufrufs voncreate_modelauf. Der Wert für das FeldModelCacheSettingist standardmäßigEnabled.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Konfigurieren Sie den Multimodell-Endpunkt mit GPU-gestützten Instances für das Modell. Wir empfehlen, Ihre Endpunkte mit mehr als einer Instance zu konfigurieren, um eine hohe Verfügbarkeit und höhere Cache-Zugriffe zu gewährleisten.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.g4dn.4xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] ) -
Erstellen Sie den Multimodell-Endpunkt mit den Parametern
EndpointNameundEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
