Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Einführung in die SageMaker KI-Bibliothek für verteilte Datenparallelität
Die SageMaker AI Distributed Data Parallelism (SMDDP) -Bibliothek ist eine kollektive Kommunikationsbibliothek, die die Rechenleistung des parallel Trainings mit verteilten Daten verbessert. Die SMDDP-Bibliothek trägt dem Kommunikationsaufwand der wichtigsten kollektiven Kommunikationsoperationen Rechnung, indem sie Folgendes bietet.
-
Die Bibliothek bietet optimierte Angebote für.
AllReduceAWSAllReduceist eine wichtige Operation, mit der Gradienten zwischen GPUs am Ende jeder Trainingsiteration während eines verteilten Datentrainings synchronisiert werden. -
Die Bibliothek bietet optimierte Angebote für.
AllGatherAWSAllGatherist eine weitere wichtige Operation, die beim Sharded Data Parallel Training verwendet wird. Dabei handelt es sich um eine speichereffiziente Datenparallelitätstechnik, die von beliebten Bibliotheken wie der SageMaker AI Model Parallelism (SMP) -Bibliothek, dem DeepSpeed Zero Redundancy Optimizer (ZerO) und Fully Sharded Data Parallelism (FSDP) angeboten wird. PyTorch -
Die Bibliothek ermöglicht eine optimierte Kommunikation von Knoten zu Knoten, indem sie die AWS Netzwerkinfrastruktur und die Amazon EC2 EC2-Instance-Topologie vollständig nutzt.
Die SMDDP-Bibliothek kann die Trainingsgeschwindigkeit erhöhen, indem sie bei der Skalierung Ihres Trainingsclusters eine Leistungsverbesserung mit nahezu linearer Skalierungseffizienz bietet.
Anmerkung
Die über SageMaker KI verteilten Schulungsbibliotheken sind über die AWS Deep-Learning-Container für PyTorch und Hugging Face auf der SageMaker Trainingsplattform verfügbar. Um die Bibliotheken verwenden zu können, müssen Sie das SageMaker Python-SDK oder die SageMaker APIs über das SDK für Python (Boto3) oder verwenden. AWS Command Line Interface In der gesamten Dokumentation konzentrieren sich Anweisungen und Beispiele auf die Verwendung der verteilten Trainingsbibliotheken mit dem SageMaker Python-SDK.
SMDDP-Operationen für die kollektive Kommunikation, optimiert für AWS Rechenressourcen und Netzwerkinfrastruktur
Die SMDDP-Bibliothek bietet Implementierungen AllReduce und AllGather kollektive Operationen, die für AWS Rechenressourcen und Netzwerkinfrastruktur optimiert sind.
Kollektive AllReduce-Operation mit SMDDP
Die SMDDP-Bibliothek sorgt für eine optimale Überlappung der AllReduce-Operation mit dem Rückwärtsdurchlauf, wodurch die GPU-Auslastung erheblich verbessert wird. Durch die Optimierung der Kerneloperationen zwischen CPUs und GPUs werden eine nahezu lineare Skalierungseffizienz und eine schnellere Trainingsgeschwindigkeit erreicht. Die Bibliothek führt AllReduce parallel aus, während die GPU Gradienten berechnet, ohne zusätzliche GPU-Zyklen in Anspruch zu nehmen, wodurch die Bibliothek ein schnelleres Training erzielt.
-
Nutzt CPUs: Die Bibliothek verwendet CPUs für
AllReduce-Gradienten, wodurch diese Aufgabe von den GPUs ausgelagert wird. -
Verbesserte GPU-Nutzung: Die GPUs des Clusters konzentrieren sich auf die Berechnung von Gradienten und verbessern so ihre Auslastung während des gesamten Trainings.
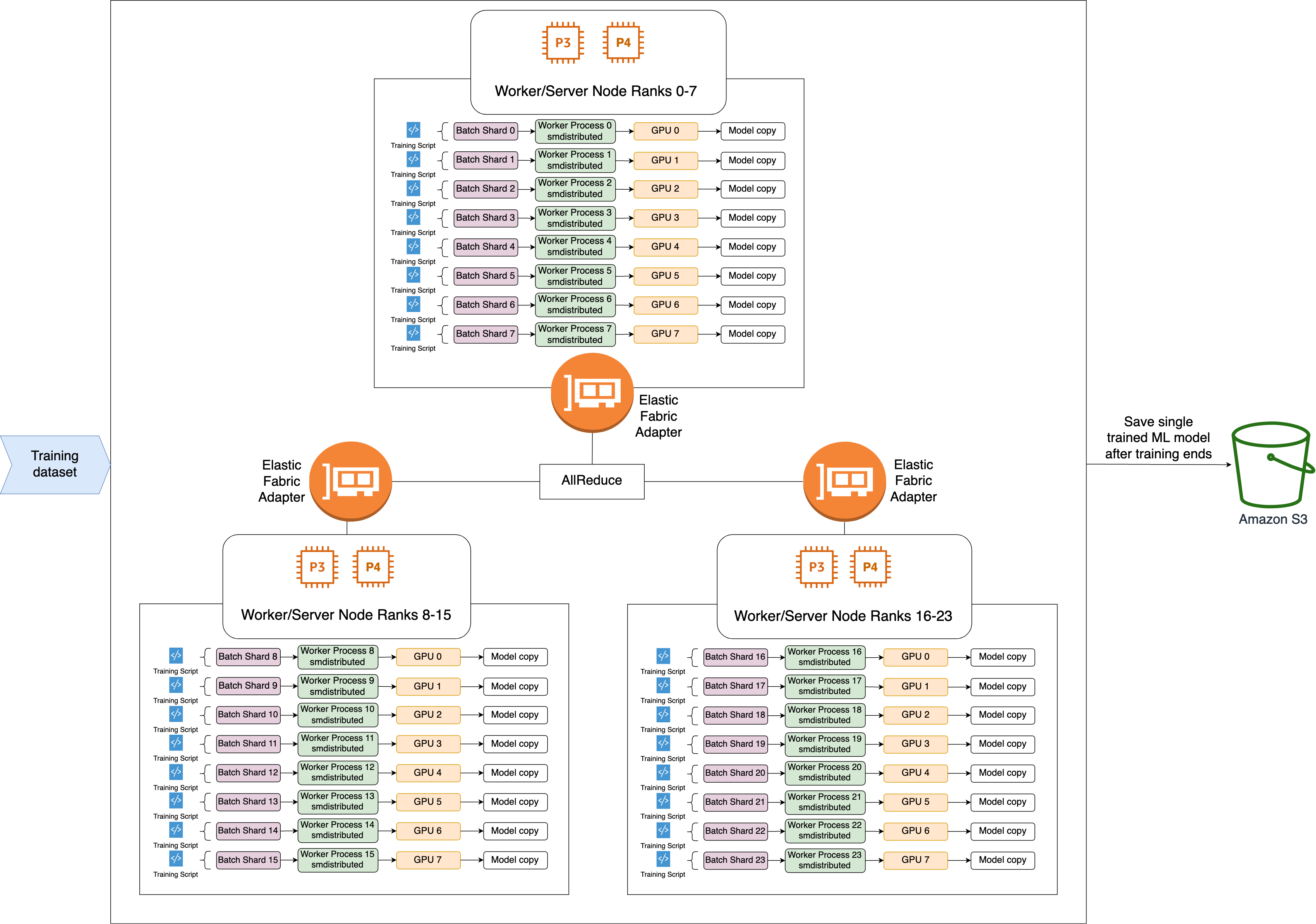
Im Folgenden wird der allgemeine Arbeitsablauf der SMDDP-AllReduce-Operation beschrieben.
-
Die Bibliothek weist GPUs (Workern) Ränge zu.
-
Bei jeder Iteration teilt die Bibliothek jeden globalen Stapel durch die Gesamtzahl der Arbeiter (Weltgröße) und weist den Arbeitern kleine Chargen (Batch-Shards) zu.
-
Die Größe des globalen Batches ist
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard). -
Ein Batch-Shard (kleiner Batch) ist eine Teilmenge von Datensätzen, die jeder GPU (Worker) pro Iteration zugewiesen wird.
-
-
Die Bibliothek startet für jeden Worker ein Trainingsskript.
-
In der Bibliothek werden am Ende jeder Iteration Kopien der Modellgewichte und -verläufe von den Workern verwaltet.
-
Die Bibliothek synchronisiert die Gewichte und Farbverläufe der Modelle der einzelnen Worker, um ein einziges trainiertes Modell zu aggregieren.
Das folgende Architekturdiagramm zeigt ein Beispiel dafür, wie die Bibliothek Datenparallelität für einen Cluster von 3 Knoten einrichtet.
Kollektive SMDDP-AllGather-Operation
AllGather ist eine kollektive Operation, bei der jeder Worker mit einem Eingabepuffer beginnt und dann die Eingabepuffer aller anderen Worker zu einem Ausgabepuffer verkettet oder zusammenfasst.
Anmerkung
Der AllGather gemeinsame SMDDP-Vorgang ist in smdistributed-dataparallel>=2.0.1 und AWS Deep Learning Containers (DLC) für Version 2.0.1 und höher verfügbar PyTorch .
AllGather wird häufig für verteilte Trainingstechniken wie die Parallelität fragmentierter Daten verwendet, bei der jeder einzelne Worker einen Bruchteil eines Modells oder eine fragmentierte Ebene besitzt. Die Worker rufen AllGather vor Vorwärts- und Rückwärtsdurchläufen auf, um die fragmentierten Ebenen zu rekonstruieren. Die Vorwärts- und Rückwärtsdurchläufe setzen sich fort, nachdem alle Parameter erfasst wurden. Während des Rückwärtsdurchlaufs ruft jeder Worker außerdem ReduceScatter auf, um Gradienten zu sammeln (zu reduzieren) und sie in Gradientenfragmente zu zerlegen (zu zerteilen), um die entsprechende fragmentierte Ebene zu aktualisieren. Weitere Informationen zur Rolle dieser kollektiven Operationen beim Sharded Data Parallelism finden Sie in der Dokumentation zur Implementierung von Sharded Data Parallelism in der SMP-Bibliothek, ZerO
Da kollektive Operationen wie in jeder Iteration aufgerufen AllGather werden, sind sie der Hauptverursacher des GPU-Kommunikationsaufwands. Eine schnellere Berechnung dieser kollektiven Operationen führt direkt zu einer kürzeren Trainingszeit ohne negative Auswirkungen auf die Konvergenz. Um dies zu erreichen, bietet die SMDDP-Bibliothek AllGather, optimiert für P4-Instances an.
SMDDP AllGather verwendet die folgenden Techniken, um die Rechenleistung auf P4d-Instances zu verbessern.
-
Es überträgt Daten zwischen Instances (zwischen Knoten) über das Elastic Fabric Adapter (EFA)
-Netzwerk mit einer Mesh-Topologie. EFA ist die Netzwerklösung AWS mit niedriger Latenz und hohem Durchsatz. Eine Mesh-Topologie für die Netzwerkkommunikation zwischen Knoten ist stärker auf die Eigenschaften von EFA und Netzwerkinfrastruktur zugeschnitten. AWS Im Vergleich zur NCCL-Ring- oder Baumtopologie, die mehrere Paket-Hops umfasst, vermeidet SMDDP die Akkumulation von Latenz aufgrund mehrerer Hops, da nur ein Hop benötigt wird. SMDDP implementiert einen Algorithmus zur Steuerung der Netzwerkrate, der die Workload auf jeden Kommunikationspartner in einer Mesh-Topologie verteilt und so einen höheren globalen Netzwerkdurchsatz erzielt. -
Es verwendet eine GPU-Speicherkopierbibliothek mit niedriger Latenz, die auf der Technologie NVIDIA GPUDirect RDMA (GDRCopy) basiert
, um den lokalen NVLink- und EFA-Netzwerkverkehr zu koordinieren. GDRCopy, eine von NVIDIA angebotene Bibliothek für GPU-Speicherkopien mit niedriger Latenz, ermöglicht eine Kommunikation mit niedriger Latenz zwischen CPU-Prozessen und GPU-CUDA-Kerneln. Mit dieser Technologie ist die SMDDP-Bibliothek in der Lage, die Datenbewegung innerhalb und zwischen den Knoten zu leiten. -
Sie reduziert den Einsatz von GPU-Streaming-Multiprozessoren, um die Rechenleistung für die Ausführung von Modellkerneln zu erhöhen. P4d- und P4de-Instances sind mit NVIDIA-A100-GPUs ausgestattet, die jeweils über 108 Streaming-Multiprozessoren verfügen. Während NCCL bis zu 24 Streaming-Multiprozessoren benötigt, um kollektive Operationen auszuführen, verwendet SMDDP weniger als 9 Streaming-Multiprozessoren. Modell-Compute-Kernel greifen für schnellere Berechnungen auf die gespeicherten Streaming-Multiprozessoren zurück.
