Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Beispiel-Notebooks und Codebeispiele zur Konfiguration des Debugger-Hooks
Die folgenden Abschnitte enthalten Notebooks und Codebeispiele zur Verwendung des Debugger-Hooks zum Speichern, Zugreifen und Visualisieren von Ausgabetensoren.
Themen
Beispiel-Notebooks für Tensorvisualisierungen
Die folgenden beiden Notebook-Beispiele zeigen die erweiterte Verwendung von Amazon SageMaker Debugger zur Visualisierung von Tensoren. Der Debugger bietet einen transparenten Einblick in das Training von Deep-Learning-Modellen.
-
Interaktive Tensoranalyse in SageMaker Studio Notebook mit MXNet
Dieses Notebook-Beispiel zeigt, wie gespeicherte Tensoren mit Amazon SageMaker Debugger visualisiert werden. Durch die Visualisierung der Tensoren können Sie leicht sehen, wie sich die Tensorwerte ändern, während Sie Deep-Learning-Algorithmen trainieren. Dieses Notizbuch beinhaltet eine Trainingsaufgabe mit einem schlecht konfigurierten neuronalen Netzwerk und verwendet Amazon SageMaker Debugger, um Tensoren, einschließlich Gradienten, Aktivierungsausgaben und Gewichtungen, zu aggregieren und zu analysieren. Das folgende Diagramm zeigt beispielsweise die Verteilung der Gradienten eines Convolutional Layers (faltenden Layers), bei dem ein Problem in Zusammenhang mit dem Verschwinden des Gradienten vorliegt.
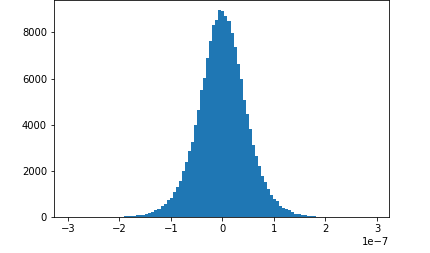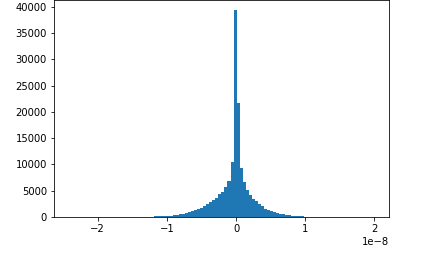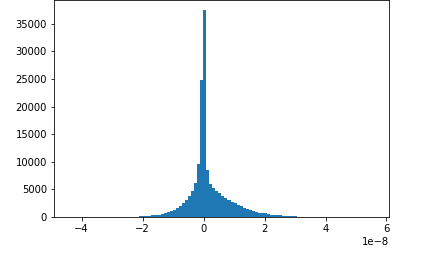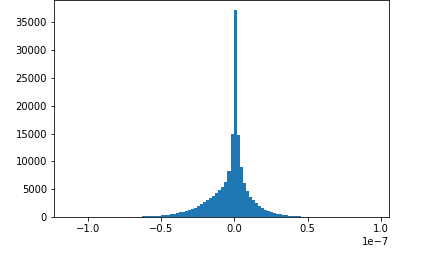
Dieses Notebooks veranschaulicht auch, wie eine gute anfängliche Hyperparametereinstellung den Trainingsprozess verbessert, indem die gleichen Tensorverteilungsdiagramme generiert werden.
-
Visualisieren und Debuggen von Tensoren aus dem MXNet-Modelltraining
Dieses Notebook-Beispiel zeigt, wie Tensoren aus einem MXNet-Gluon-Modell-Trainingsjob mit Amazon Debugger gespeichert und visualisiert werden. SageMaker Es zeigt, dass der Debugger so eingestellt ist, dass er alle Tensoren in einem Amazon S3 S3-Bucket speichert und ReLu Aktivierungsausgaben für die Visualisierung abruft. Die folgende Abbildung zeigt eine dreidimensionale Visualisierung der ReLu Aktivierungsausgaben. Im Hinblick auf das Farbschema bedeutet Blau, dass es sich um Werte nahe 0 handelt, und Gelb, dass die Werte nahe 1 sind.

In diesem Notebook ist die aus
tensor_plot.pyimportierteTensorPlot-Klasse so konzipiert, dass sie Convolutional Neural Networks (CNNs) mit zweidimensionalen Bildern als Eingabe plottet. Das mit dem Notebook geliefertetensor_plot.pySkript ruft mit Debugger Tensoren ab und visualisiert das CNN. Sie können dieses Notizbuch auf SageMaker Studio ausführen, um die Tensorvisualisierung zu reproduzieren und Ihr eigenes neuronales Faltungsnetzmodell zu implementieren. -
Real-time Tensoranalyse in einem SageMaker Notebook mit MXNet
Dieses Beispiel führt Sie durch die Installation der erforderlichen Komponenten für die Ausgabe von Tensoren in einem SageMaker Amazon-Schulungsjob und die Verwendung der Debugger-API-Operationen, um während des Trainings auf diese Tensoren zuzugreifen. Ein Gluon-CNN-Modell wird mit dem Fashion MNIST-Datensatz trainiert. Während der Auftrag ausgeführt wird, werden Sie sehen, wie der Debugger die Aktivierungsausgaben der ersten Faltungsschicht aus jedem der 100 Batches abruft und sie visualisiert. Außerdem erfahren Sie, wie Sie Gewichte nach Abschluss der Arbeit visualisieren.
Speichern von Tensoren mit integrierten Debugger-Sammlungen
Sie können integrierte Sammlungen von Tensoren mithilfe der CollectionConfig API verwenden und sie mithilfe der DebuggerHookConfig API speichern. Das folgende Beispiel zeigt, wie Sie die Standardeinstellungen der Debugger-Hook-Konfigurationen verwenden, um einen KI-Schätzer zu erstellen. SageMaker TensorFlow Sie können dies auch für MXNet- und PyTorch XGBoost-Schätzer verwenden.
Anmerkung
Im folgenden Beispielcode ist der s3_output_path Parameter für DebuggerHookConfig optional. Wenn Sie es nicht angeben, speichert Debugger die Tensoren unters3://<output_path>/debug-output/, wo dies der Standardausgabepfad für <output_path> Trainingsjobs ist. SageMaker Beispiel:
"s3://sagemaker-us-east-1-111122223333/sagemaker-debugger-training-YYYY-MM-DD-HH-MM-SS-123/debug-output"
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to call built-in collections collection_configs=[ CollectionConfig(name="weights"), CollectionConfig(name="gradients"), CollectionConfig(name="losses"), CollectionConfig(name="biases") ] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-built-in-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
Eine Liste der integrierten Debugger-Sammlungen finden Sie unter Debugger-Sammlungen. Built-in
Speichern von Tensoren mit integrierten Debugger-Sammlungen
Sie können die integrierten Debugger-Sammlungen mithilfe der CollectionConfig API-Operation ändern. Das folgende Beispiel zeigt, wie Sie die integrierte losses Sammlung optimieren und einen SageMaker KI-Schätzer erstellen können. TensorFlow Sie können dies auch für MXNet- und PyTorch XGBoost-Schätzer verwenden.
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to call and modify built-in collections collection_configs=[ CollectionConfig( name="losses", parameters={"save_interval": "50"})] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-modified-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
Speichern von reduzierten Tensoren mit benutzerdefinierten Debugger-Sammlungen
Sie können auch eine reduzierte Anzahl an Tensoren anstelle des vollständigen Satzes von Tensoren speichern, um beispielsweise die in Ihrem Amazon-S3-Bucket gespeicherte Datenmenge zu verringern. Das folgende Beispiel zeigt, wie Sie die Debugger-Hook-Konfiguration ändern, um Zieltensoren zum Speichern anzugeben. Sie können dies für MXNet TensorFlow - und PyTorch XGBoost-Schätzer verwenden.
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to create a custom collection collection_configs=[ CollectionConfig( name="custom_activations_collection", parameters={ "include_regex": "relu|tanh", # Required "reductions": "mean,variance,max,abs_mean,abs_variance,abs_max" }) ] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-custom-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
Eine vollständige Liste der CollectionConfig Parameter finden Sie unter Debugger. CollectionConfig
