Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Exemplarische Vorgehensweise für den XGBoost Debugger-Schulungsbericht
In diesem Abschnitt werden Sie durch den XGBoost Debugger-Schulungsbericht geführt. Der Bericht wird je nach Ausgabetensor-Regex automatisch aggregiert, wobei erkannt wird, um welche Art von Trainingsauftrag es sich bei der binären Klassifikation, der Mehrklassen-Klassifizierung und der Regression handelt.
Wichtig
Der Bericht enthält Diagramme und Empfehlungen zu Informationszwecken und sind nicht endgültig. Es liegt in Ihrer Verantwortung, die Informationen eigenständig zu bewerten.
Themen
- Verteilung der wahren Bezeichnungen des Datensatzes
- Diagramm zwischen Verlust und Schritt
- Bedeutung des Merkmals
- Verwechslungsmatrix
- Bewertung der Konfusionsmatrix
- Genauigkeitsrate jedes diagonalen Elements im Laufe der Iteration
- Betriebskennlinie des Empfängers
- Verteilung der Residuen im letzten gespeicherten Schritt
- Absoluter Validierungsfehler pro Label-Bin während der Iteration
Verteilung der wahren Bezeichnungen des Datensatzes
Dieses Histogramm zeigt die Verteilung der beschrifteten Klassen (zur Klassifizierung) oder Werte (für die Regression) in Ihrem ursprünglichen Datensatz. Schiefe Werte in Ihrem Datensatz können zu Ungenauigkeiten führen. Diese Visualisierung ist für die folgenden Modelltypen verfügbar: binäre Klassifikation, Multiklassifikation und Regression.
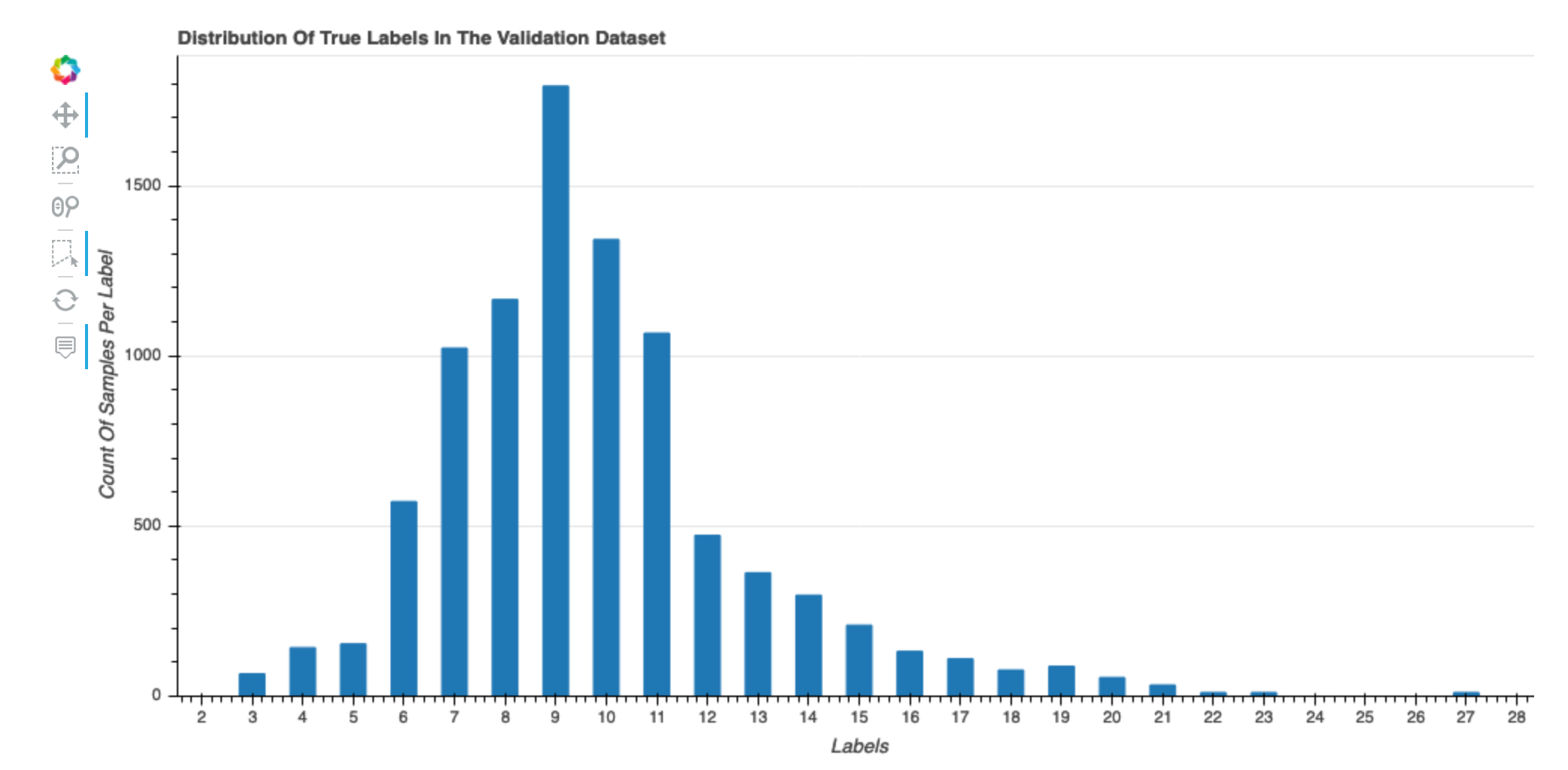
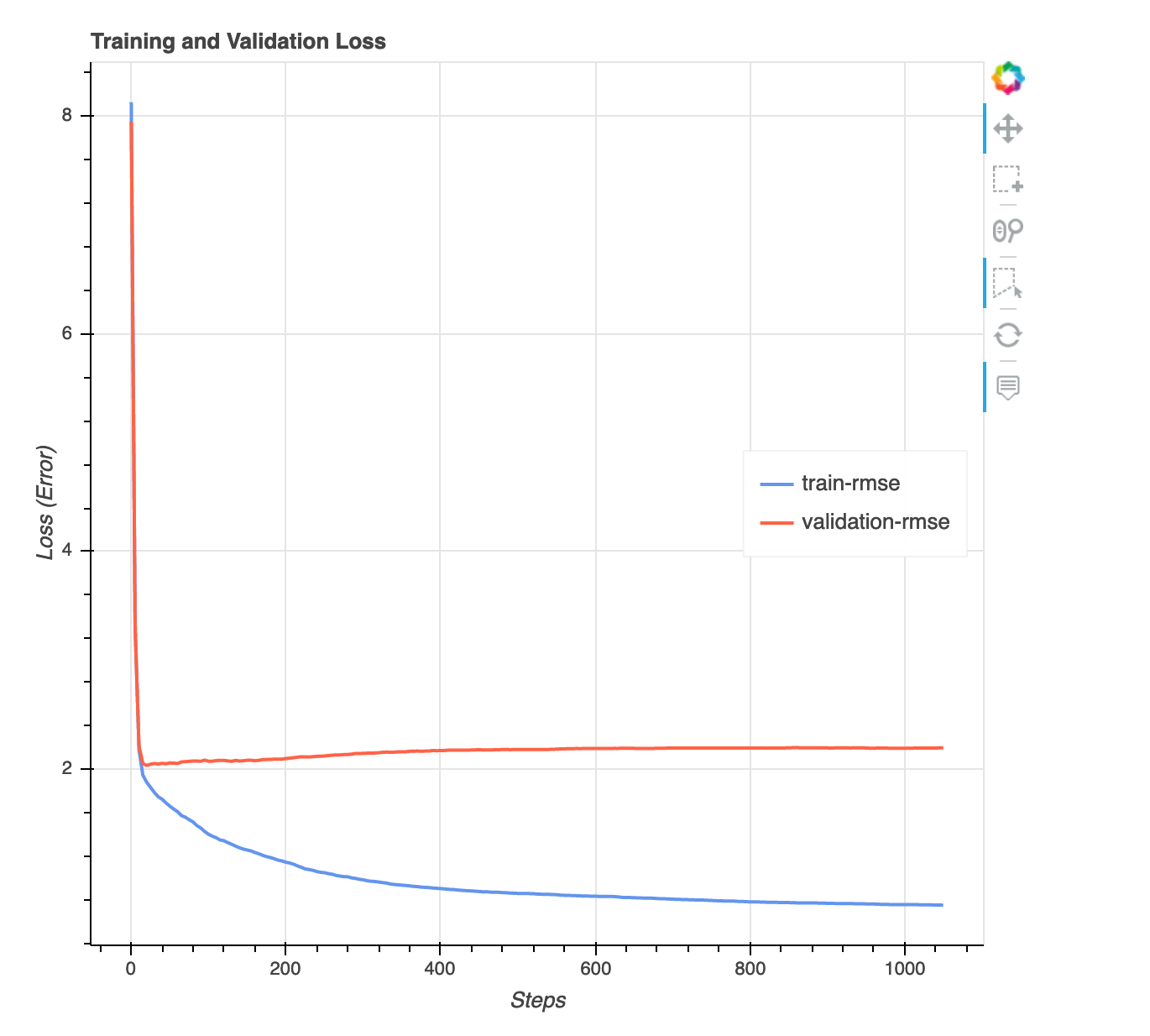
Diagramm zwischen Verlust und Schritt
Dies ist ein Liniendiagramm, das den Verlauf des Verlusts von Trainingsdaten und Validierungsdaten während der Trainingsschritte zeigt. Der Verlust entspricht dem, was Sie in Ihrer Zielfunktion definiert haben, z. B. den quadratischen Mittelwert des Fehlers. Anhand dieses Diagramms können Sie abschätzen, ob das Modell über- oder unterangepasst ist. In diesem Abschnitt wird auch das Problem der Überanpassung und Unterausstattung beschrieben. Diese Visualisierung ist für die folgenden Modelltypen verfügbar: binäre Klassifikation, Multiklassifizierung und Regression.
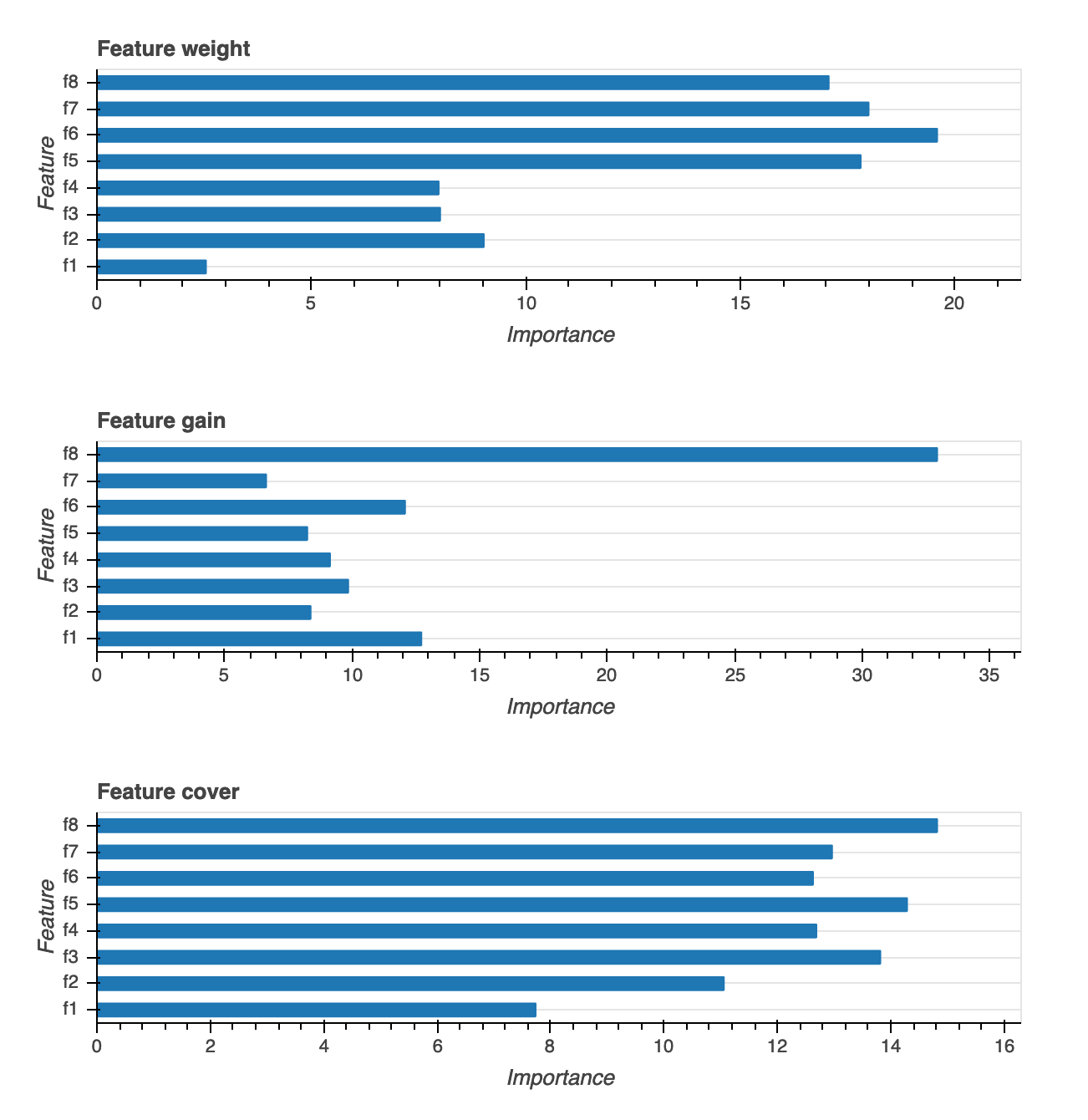
Bedeutung des Merkmals
Es stehen drei verschiedene Arten von Visualisierungen der Feature-Wichtigkeit zur Verfügung: Gewicht, Zuwachs und Reichweite. Wir stellen detaillierte Definitionen für jede der drei im Bericht bereit. Visualisierungen der Wichtigkeit von Features helfen Ihnen zu erfahren, welche Features in Ihrem Trainingsdatensatz zu den Vorhersagen beitragen. Visualisierungen der Wichtigkeit von Features sind für die folgenden Modelltypen verfügbar: Binäre Klassifikation, Multiklassifikation und Regression.
Verwechslungsmatrix
Diese Visualisierung ist nur für binäre und Mehrklassen-Klassifikationsmodelle anwendbar. Genauigkeit allein reicht möglicherweise nicht aus, um die Leistung des Modells zu bewerten. Für einige Anwendungsfälle, z. B. im Gesundheitswesen und bei der Betrugserkennung, ist es auch wichtig, die Falsch-Positiv-Rate und die Falsch-Negativ-Rate zu kennen. Eine Konfusionsmatrix bietet Ihnen zusätzliche Dimensionen für die Bewertung der Leistung Ihres Modells.

Bewertung der Konfusionsmatrix
In diesem Abschnitt erhalten Sie weitere Einblicke in die Mikro-, Makro- und gewichteten Messwerte für Präzision, Erinnerungsvermögen und F1-Score für Ihr Modell.
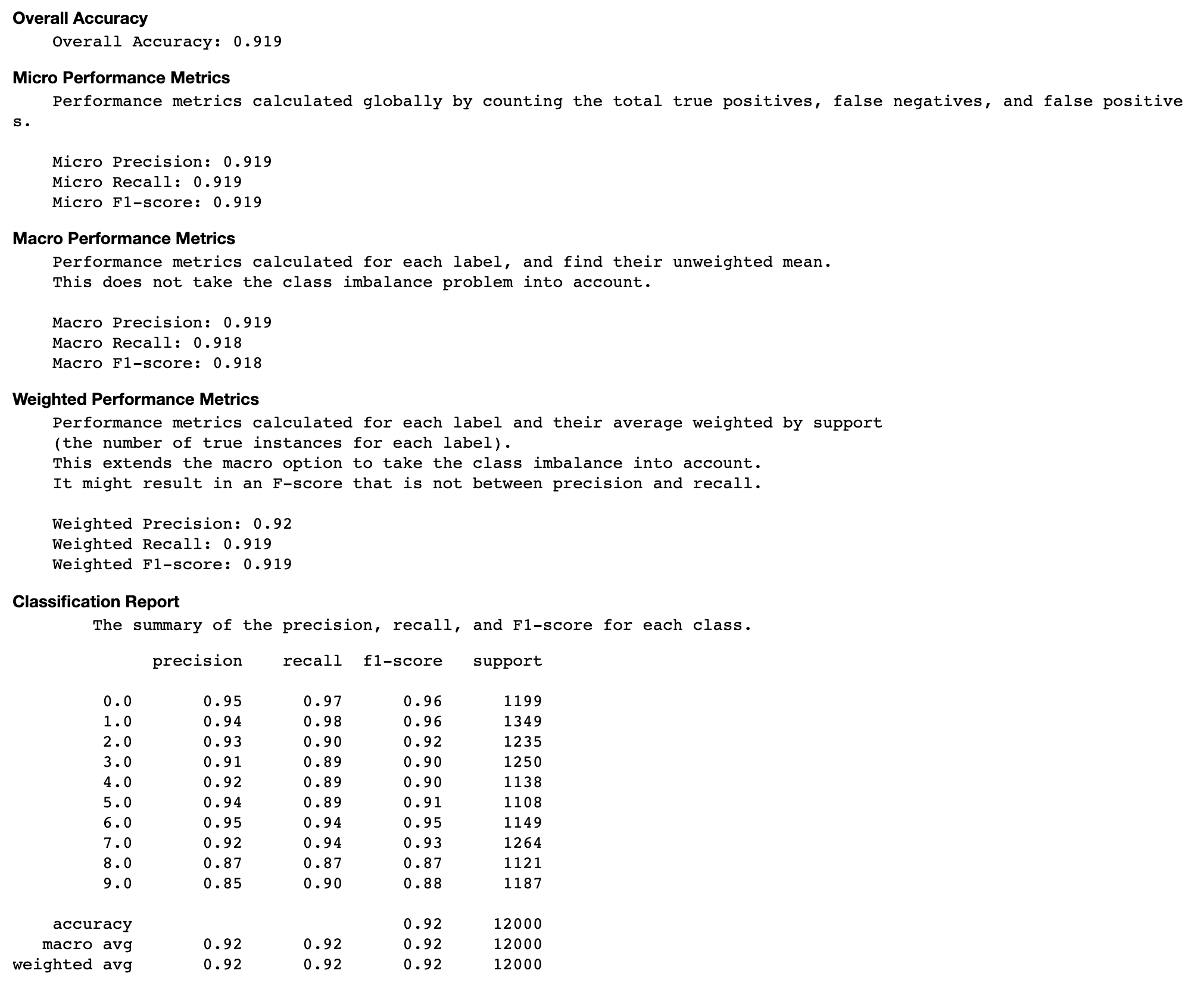
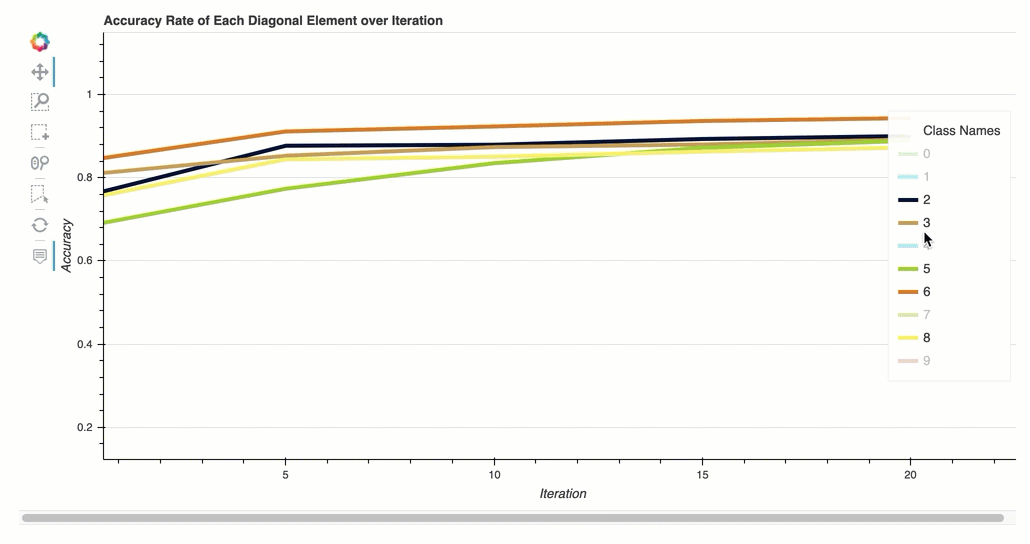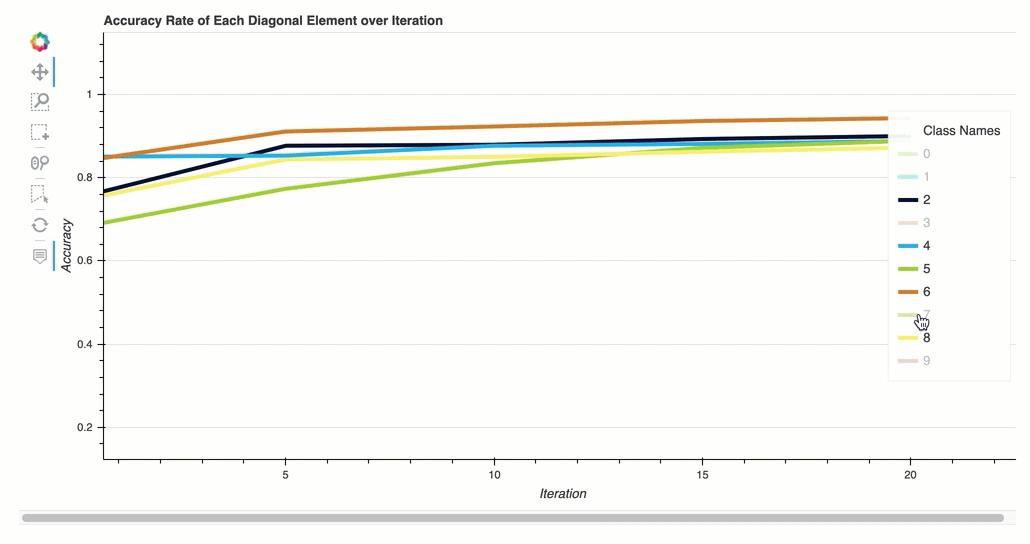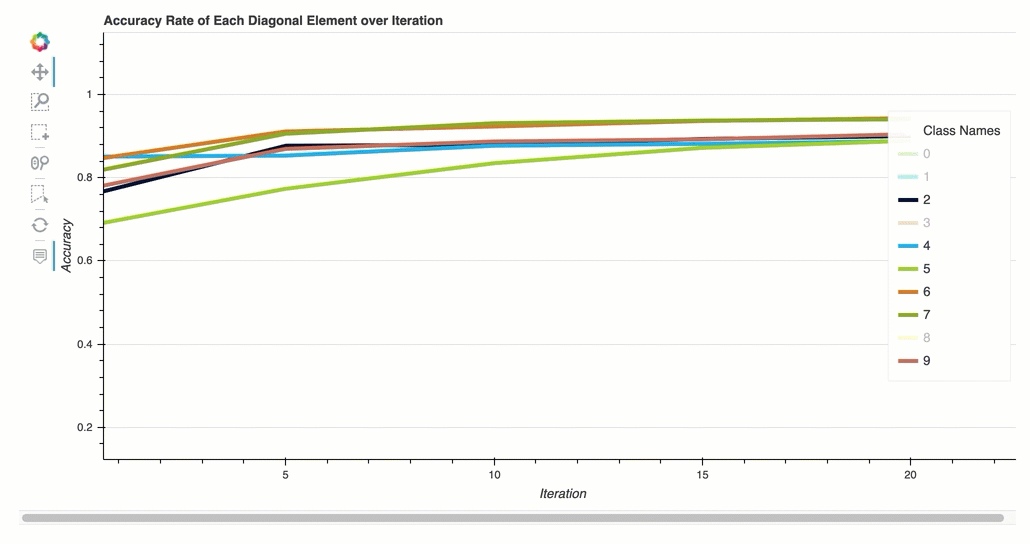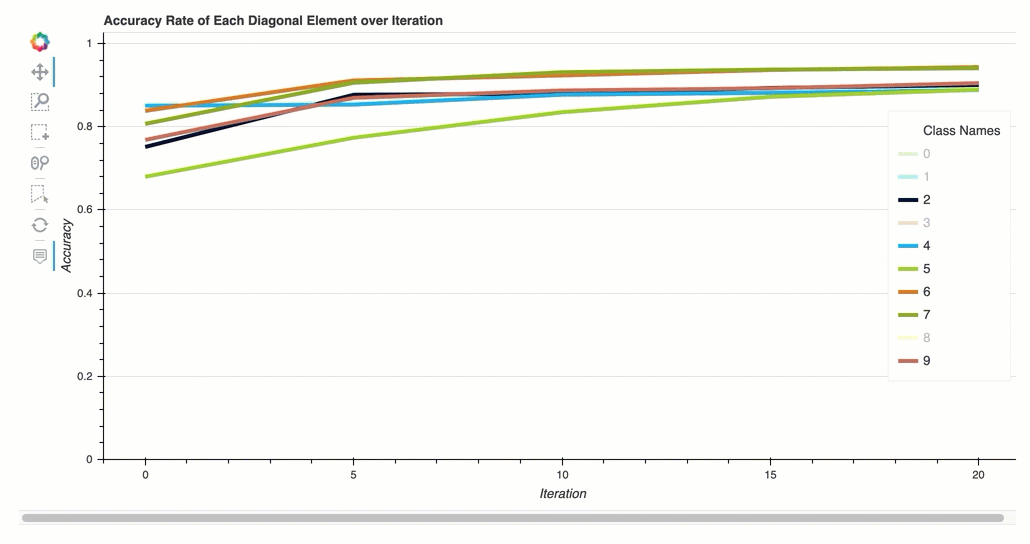
Genauigkeitsrate jedes diagonalen Elements im Laufe der Iteration
Diese Visualisierung ist nur für binäre Klassifikations- und Mehrklassen-Klassifizierungsmodelle anwendbar. Dies ist ein Liniendiagramm, in dem die diagonalen Werte in der Konfusionsmatrix während der Trainingsschritte für jede Klasse dargestellt werden. Dieses Diagramm zeigt dir, wie sich die Genauigkeit der einzelnen Klassen im Laufe der Trainingsschritte entwickelt. Anhand dieses Diagramms können Sie die Klassen identifizieren, die schlechter abschneiden.
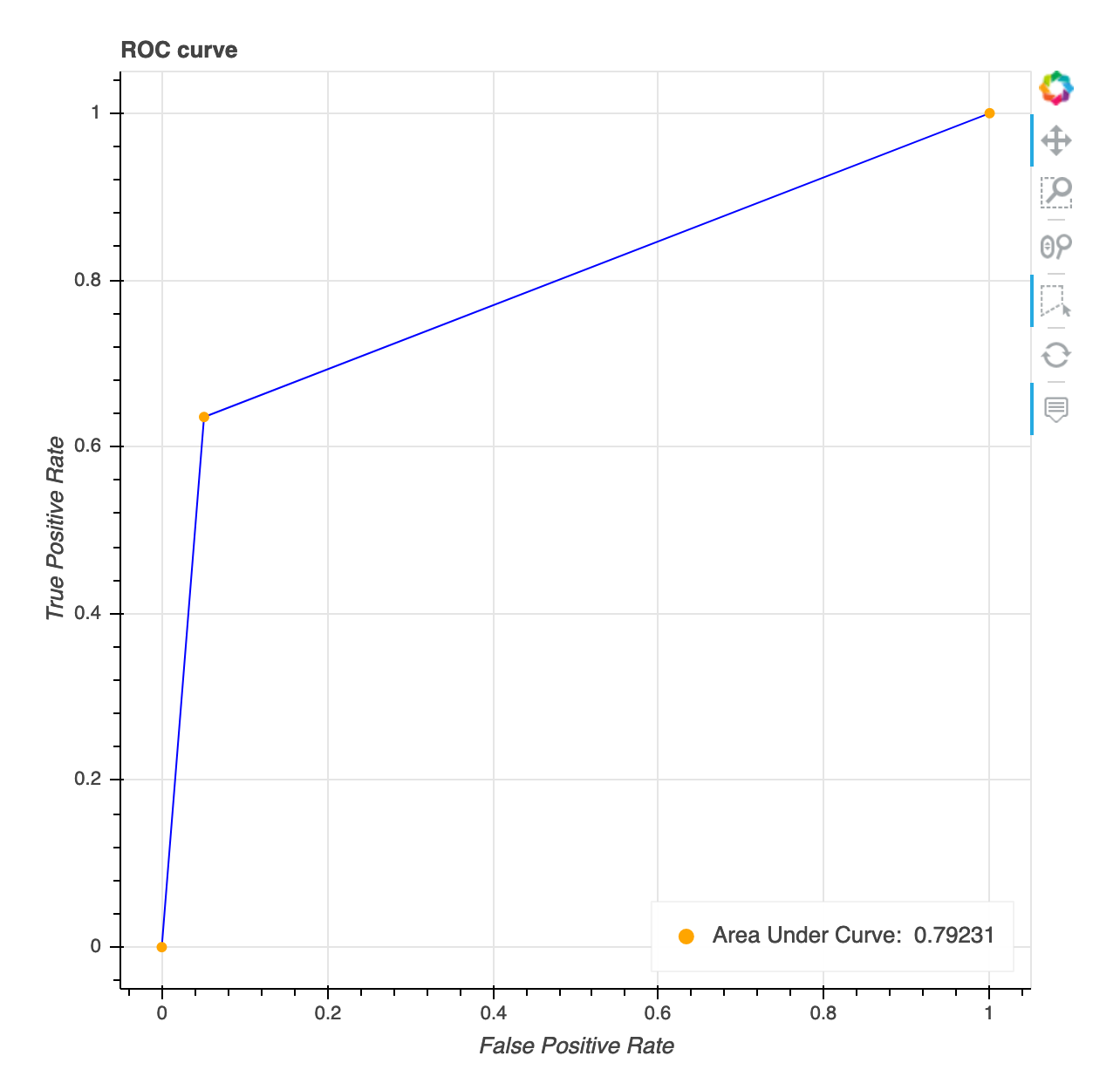
Betriebskennlinie des Empfängers
Diese Visualisierung ist nur auf binäre Klassifikationsmodelle anwendbar. Die Betriebskennlinie des Empfängers wird häufig zur Bewertung der Leistung von binären Klassifikationsmodellen verwendet. Die Y-Achse der Kurve ist True Positive Rate (TPF) und die X-Achse ist Falsch-Positiv-Rate (FPR). Das Diagramm zeigt auch den Wert für die Fläche unter der Kurve ()AUC. Je höher der AUC Wert, desto prädiktiver ist Ihr Klassifikator. Sie können die ROC Kurve auch verwenden, um den Kompromiss zwischen TPR und zu verstehen FPR und den optimalen Klassifizierungsschwellenwert für Ihren Anwendungsfall zu ermitteln. Der Klassifizierungsschwellenwert kann angepasst werden, um das Verhalten des Modells so zu optimieren, dass mehr Fehler der einen oder anderen Art (FP/FN) reduziert werden.
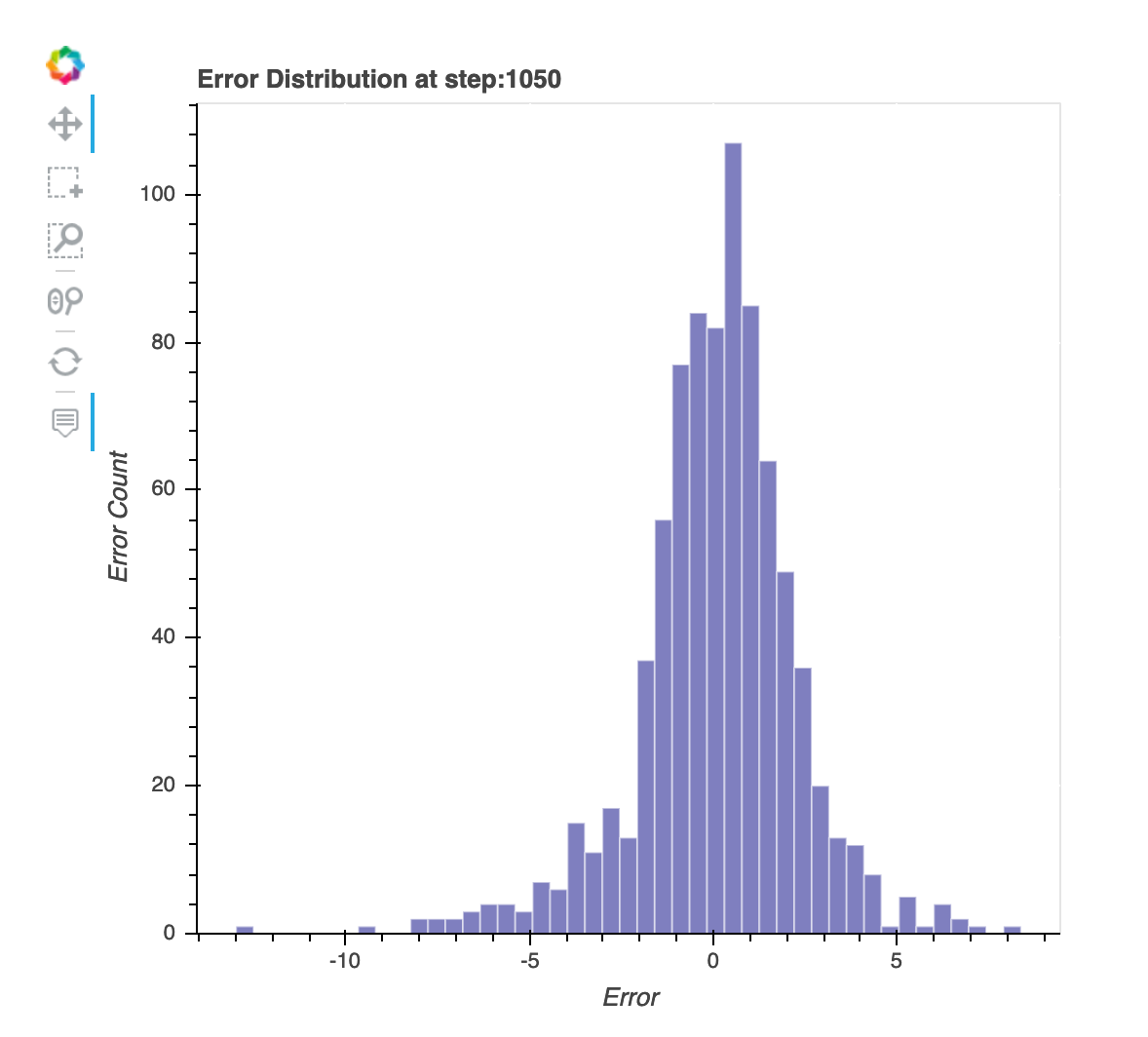
Verteilung der Residuen im letzten gespeicherten Schritt
Bei dieser Visualisierung handelt es sich um ein Säulendiagramm, das die Restverteilungen im letzten Schritt zeigt, den der Debugger erfasst. In dieser Visualisierung können Sie überprüfen, ob die Residuenverteilung der Normalverteilung nahe kommt, deren Mittelpunkt bei Null liegt. Wenn die Residuen schief sind, reichen Ihre Features möglicherweise nicht aus, um die Beschriftungen vorherzusagen.
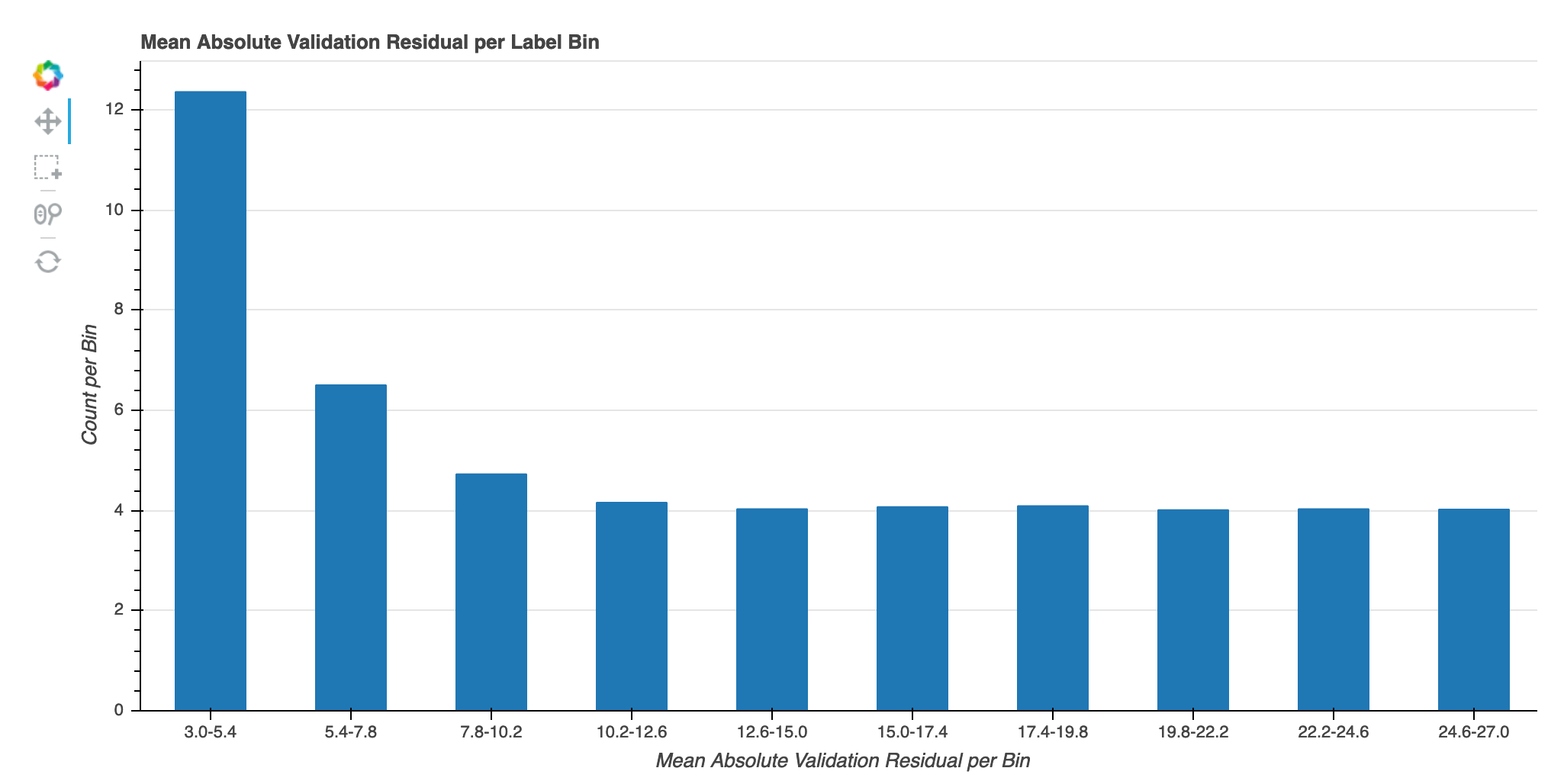
Absoluter Validierungsfehler pro Label-Bin während der Iteration
Diese Visualisierung gilt nur für Regressionsmodelle. Die tatsächlichen Zielwerte sind in 10 Intervalle aufgeteilt. Diese Visualisierung zeigt in Liniendiagrammen, wie sich die Validierungsfehler für jedes Intervall während der Trainingsschritte entwickeln. Der absolute Validierungsfehler ist der absolute Wert der Differenz zwischen Prognose und Istwert während der Validierung. Anhand dieser Visualisierung können Sie erkennen, welche Intervalle schlechter abschneiden.