Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Debugger: erweiterte Demos und Visualisierung
Die folgenden Demos führen Sie durch erweiterte Anwendungsfälle und Visualisierungsskripten mit Debugger.
Themen
Modelle mit Amazon SageMaker Experiments und Debugger trainieren und beschneiden
Dr. Nathalie Rauschmayr, AWS angewandte Wissenschaftlerin | Dauer: 49 Minuten 26 Sekunden
Finden Sie heraus, wie Amazon SageMaker Experiments und Debugger die Verwaltung Ihrer Schulungsjobs vereinfachen können. Amazon SageMaker Debugger bietet einen transparenten Einblick in Trainingsjobs und speichert Trainingsmetriken in Ihrem Amazon S3 S3-Bucket. SageMaker Experiments ermöglicht es Ihnen, die Trainingsinformationen über SageMaker Studio als Tests aufzurufen, und unterstützt die Visualisierung der Trainingsaufgabe. Dies hilft Ihnen, die Modellqualität zu erhalten und gleichzeitig weniger wichtige Parameter basierend auf dem Prioritätsrang zu reduzieren.
In diesem Video wird eine Technik zum Beschneiden von Modellen demonstriert, mit der ResNet bereits trainierte AlexNet Modelle leichter und erschwinglicher werden und gleichzeitig hohe Standards für die Modellgenauigkeit eingehalten werden.
SageMaker AI Estimator trainiert die vom PyTorch Modellzoo bereitgestellten Algorithmen in einem AWS Deep Learning Containers mit PyTorch Framework, und der Debugger extrahiert Trainingsmetriken aus dem Trainingsprozess.
Das Video zeigt auch, wie Sie eine benutzerdefinierte Debugger-Regel einrichten, um die Genauigkeit eines bereinigten Modells zu überwachen, ein CloudWatch Amazon-Ereignis und eine AWS Lambda Funktion auszulösen, wenn die Genauigkeit einen Schwellenwert erreicht, und den Bereinigungsprozess automatisch zu stoppen, um redundante Iterationen zu vermeiden.
Die Lernziele sind wie folgt:
-
Erfahren Sie, wie Sie mithilfe von SageMaker KI das Training von ML-Modellen beschleunigen und die Modellqualität verbessern können.
-
Erfahren Sie, wie Sie Trainingsiterationen mit SageMaker Experimenten verwalten können, indem Sie Eingabeparameter, Konfigurationen und Ergebnisse automatisch erfassen.
-
Erfahren Sie, wie Debugger den Trainingsprozess transparent macht, indem automatisch Echtzeit-Tensordaten von Metriken wie Gewichten, Gradienten und Aktivierungsausgaben von Convolutional Neural Networks erfasst werden.
-
Wird verwendet CloudWatch , um Lambda auszulösen, wenn der Debugger Probleme erkennt.
-
Meistern Sie den SageMaker Trainingsprozess mithilfe von SageMaker Experimenten und Debugger.
Die in diesem Video verwendeten Notizbücher und Schulungsskripte finden Sie unter SageMaker Debugger PyTorch Iterative
Die folgende Abbildung zeigt, wie der iterative Modellbereinigungsprozess die Größe von reduziert, AlexNet indem die 100 Filter mit der geringsten Signifikanz auf der Grundlage ihrer Rangfolge, bewertet anhand von Aktivierungsausgaben und Gradienten, herausgeschnitten werden.
Der Beschneidungsprozess reduzierte die anfänglichen 50 Millionen Parameter auf 18 Millionen. Außerdem wurde die geschätzte Modellgröße von 201 MB auf 73 MB reduziert.
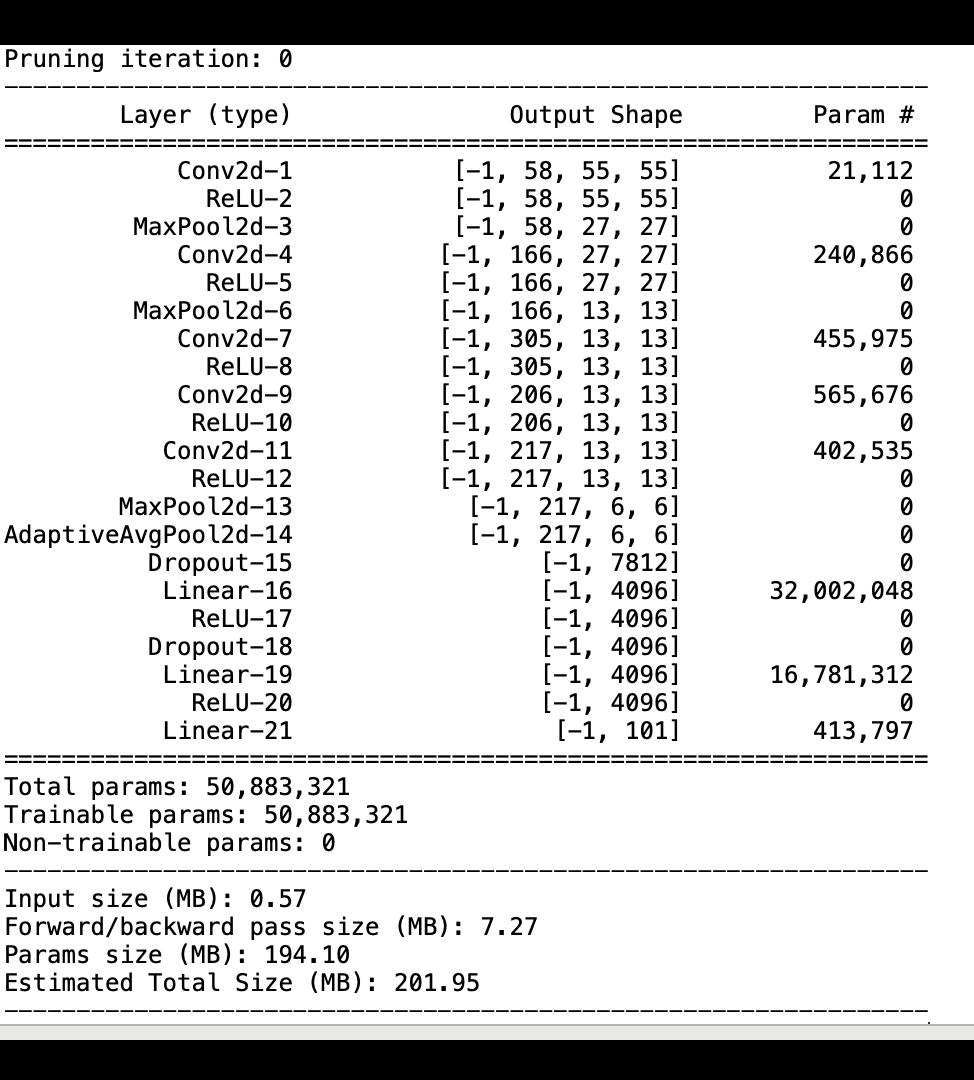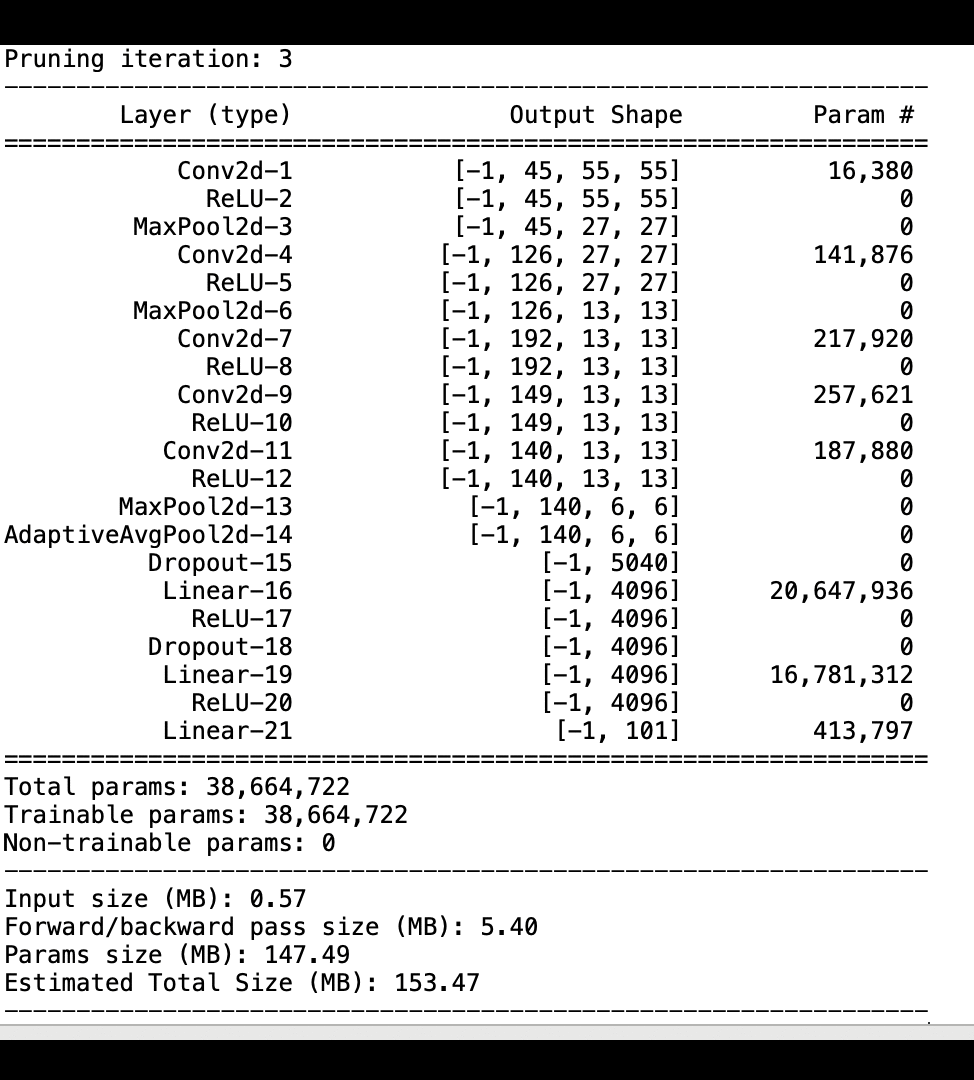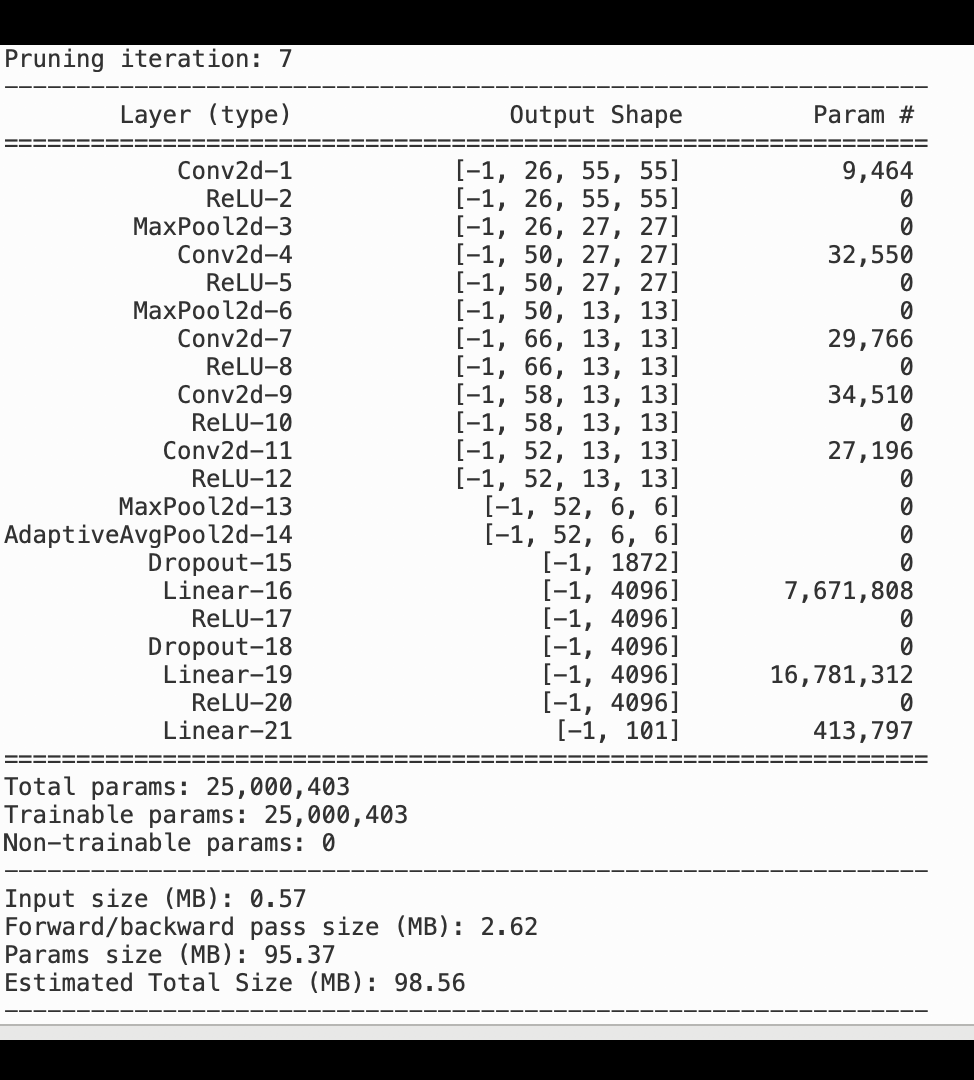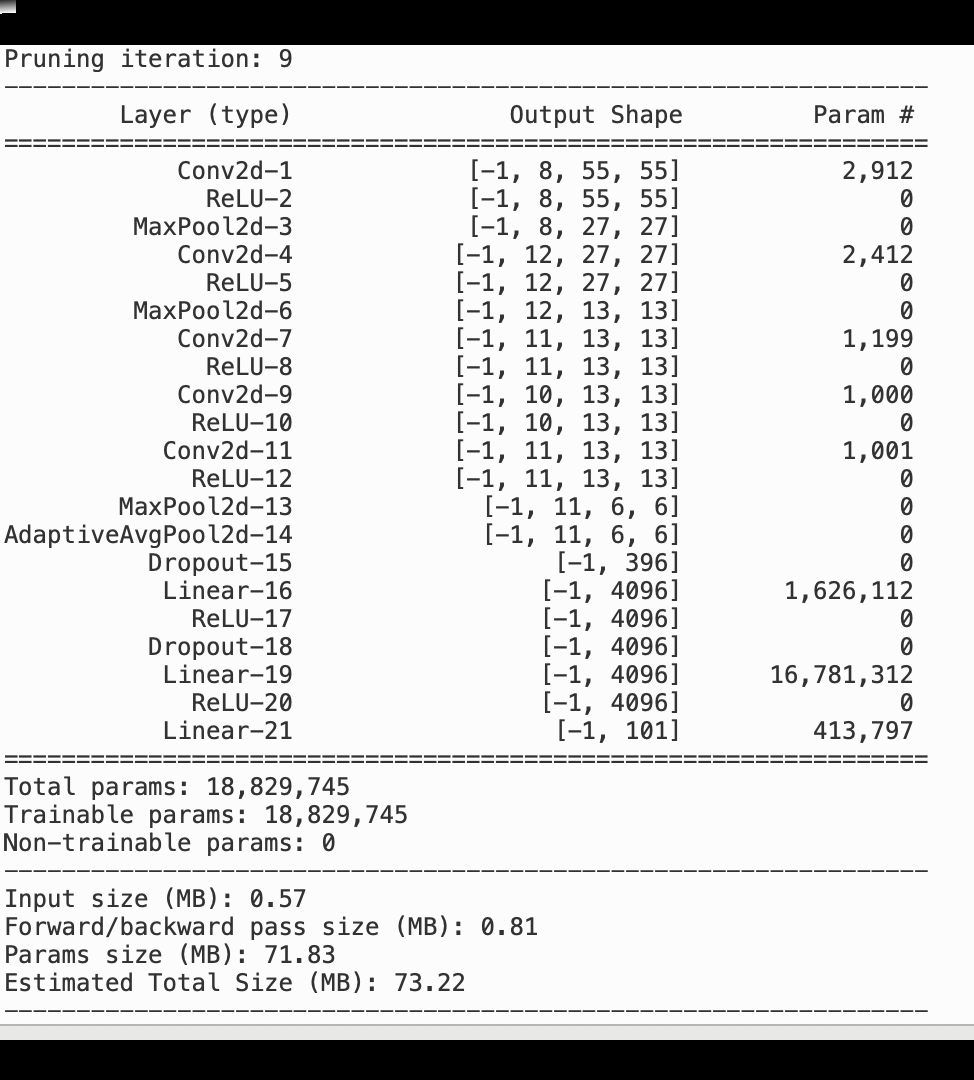
Sie müssen auch die Modellgenauigkeit verfolgen. Die folgende Abbildung zeigt, wie Sie den Modellbereinigungsprozess grafisch darstellen können, um Änderungen der Modellgenauigkeit anhand der Anzahl der Parameter in SageMaker Studio zu visualisieren.
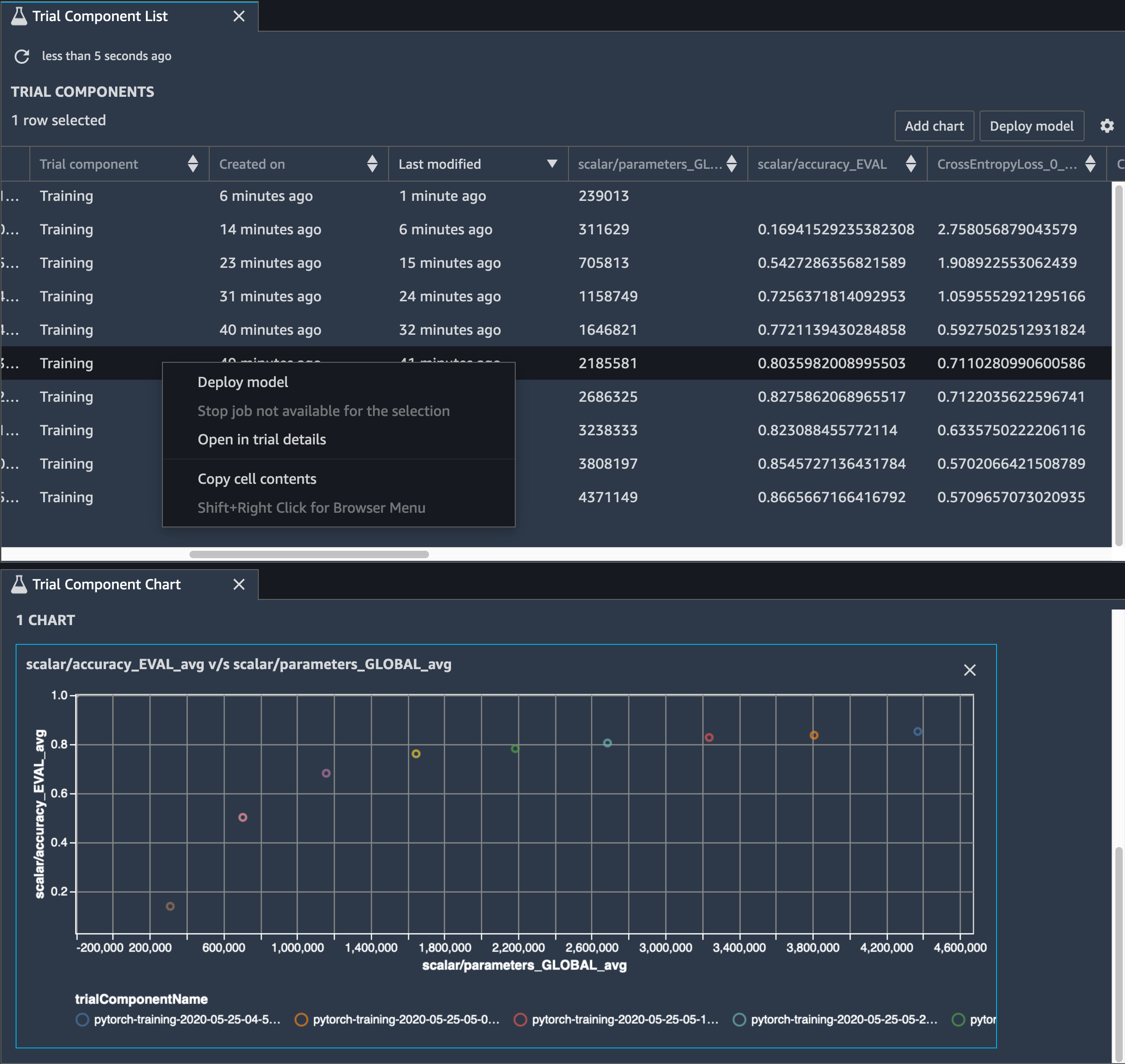
Wählen Sie in SageMaker Studio die Registerkarte Experimente aus, wählen Sie eine Liste von Tensoren aus, die vom Debugger während des Bereinigungsvorgangs gespeichert wurden, und erstellen Sie dann einen Bereich mit der Liste der Testkomponenten. Wählen Sie alle zehn Iterationen aus, und wählen Sie Diagramm hinzufügen, um ein Testkomponenten-Diagramm zu erstellen. Nachdem Sie sich für ein Modell für die Bereitstellung entschieden haben, wählen Sie die Testkomponente aus und wählen Sie ein Menü, um eine Aktion auszuführen, oder wählen Sie Modell bereitstellen.
Anmerkung
Um ein Modell mithilfe des folgenden Notebook-Beispiels über SageMaker Studio bereitzustellen, fügen Sie am Ende der train Funktion im train.py Skript eine Zeile hinzu.
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
Verwenden des SageMaker Debuggers zur Überwachung des Modelltrainings mit Convolutional Autoencoder
Dieses Notizbuch zeigt, wie SageMaker Debugger Tensoren aus einem unbeaufsichtigten (oder selbstüberwachten) Lernprozess anhand eines MNIST-Bilddatensatzes mit handgeschriebenen Zahlen visualisiert.
Das Trainingsmodell in diesem Notebook ist ein Convolutional-Autoencoder mit dem MXNet-Framework. Der Convolutional Autoencoder verfügt über ein flaschenhalsförmiges Convolutional Neural Network, das aus einem Encoder-Teil und einem Decoder-Teil besteht.
Der Encoder in diesem Beispiel verfügt über zwei Convolution-Ebenen, um eine komprimierte Darstellung (latente Variablen) der Eingabebilder zu erzeugen. In diesem Fall erzeugt der Encoder eine latente Variable der Größe (1, 20) aus einem Originaleingabebild der Größe (28, 28) und reduziert die Größe der Daten für das Training um das 40fache.
Der Decoder verfügt über zwei Deconvolutional-Schichten und stellt sicher, dass die latenten Variablen wichtige Informationen beibehalten, indem Ausgabebilder rekonstruiert werden.
Der Convolutional Encoder betreibt Clustering-Algorithmen mit kleinerer Eingabedatengröße und sowie die Leistung von Clustering-Algorithmen wie k-Means, k-NN und t-Distributed Stochastic Neighbor Embedding (t-SNE).
Dieses Notebook-Beispiel veranschaulicht, wie die latenten Variablen mithilfe von visualisiert werden, wie in der folgenden Animation gezeigt. Es zeigt auch, wie der t-SNE-Algorithmus die latenten Variablen in zehn Cluster klassifiziert und in einen zweidimensionalen Raum projiziert. Das Streudiagramm-Farbschema auf der rechten Seite des Bildes spiegelt die wahren Werte wider, um zu zeigen, wie gut das BERT-Modell und der T-SNE-Algorithmus die latenten Variablen in die Cluster organisieren.
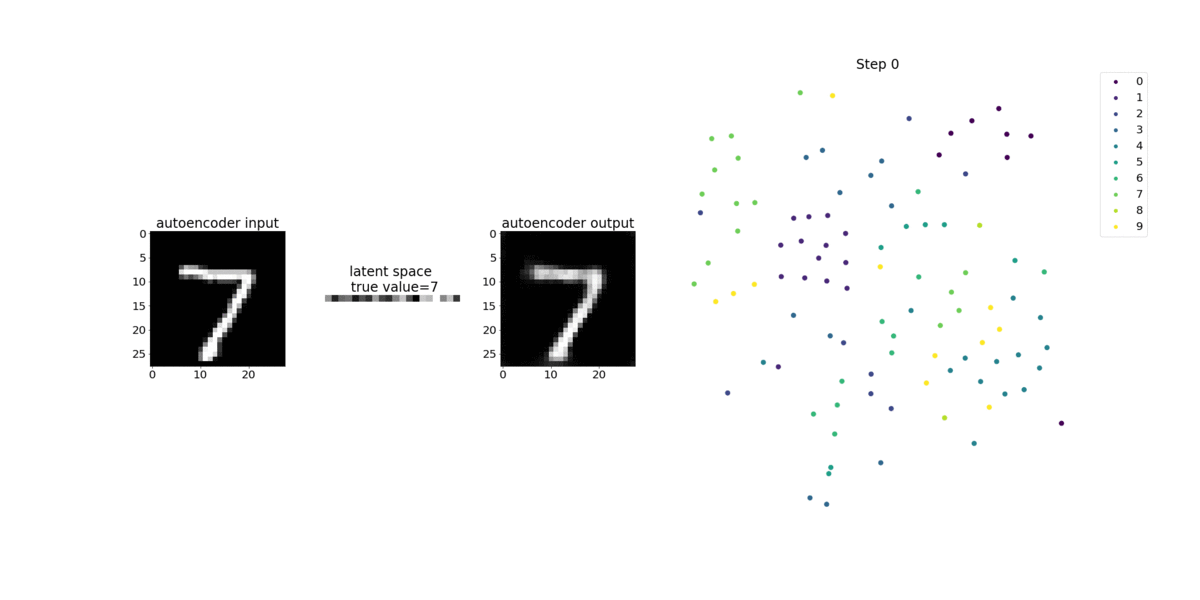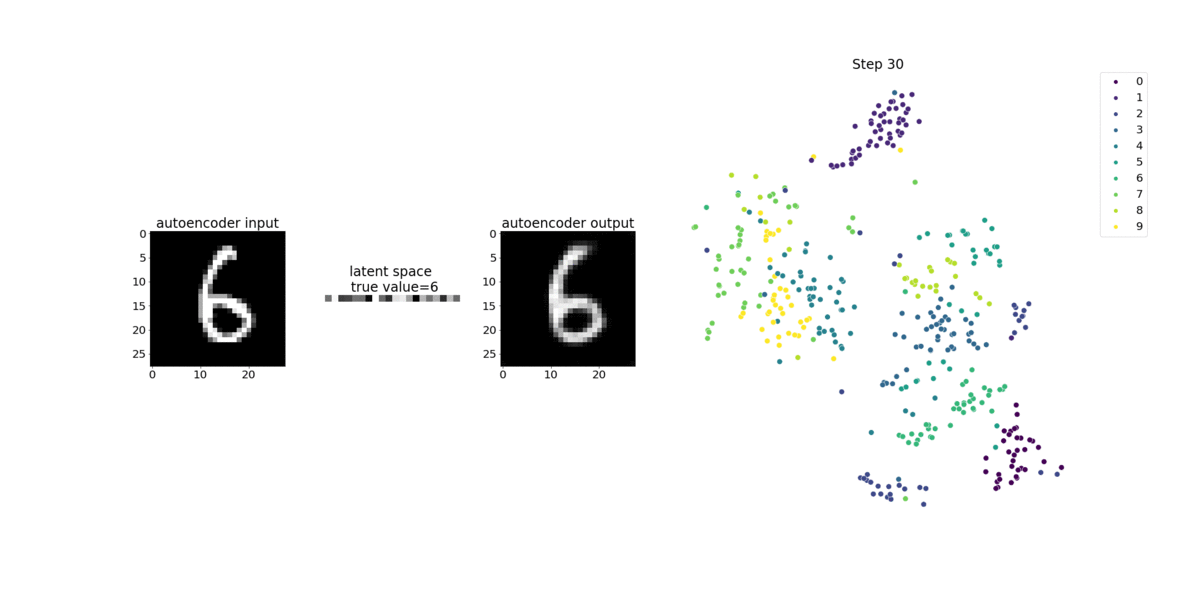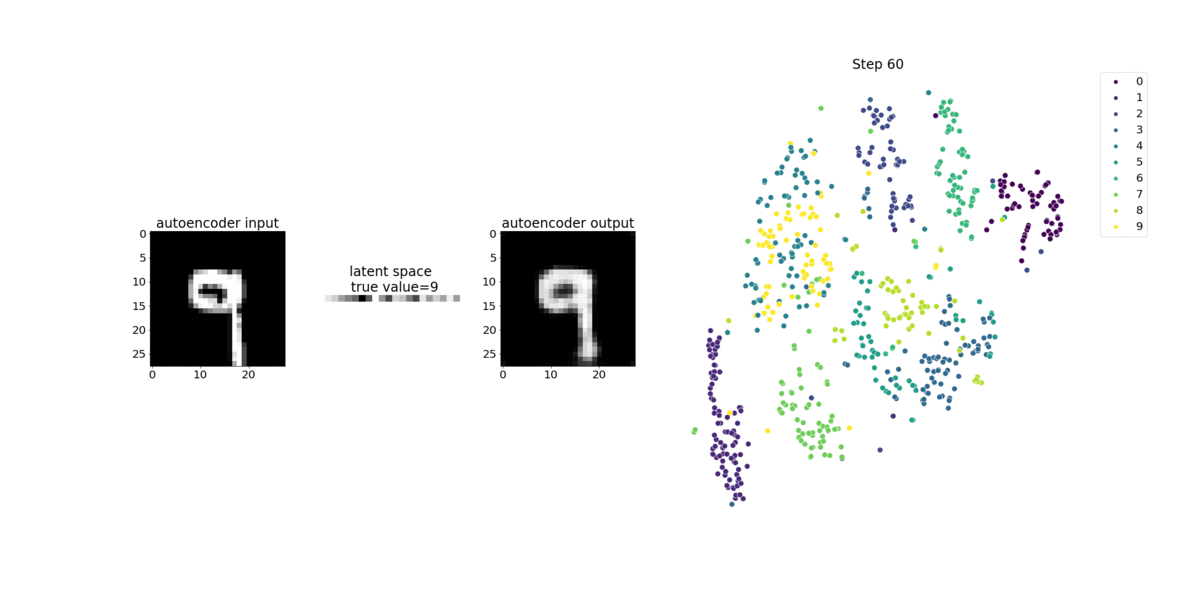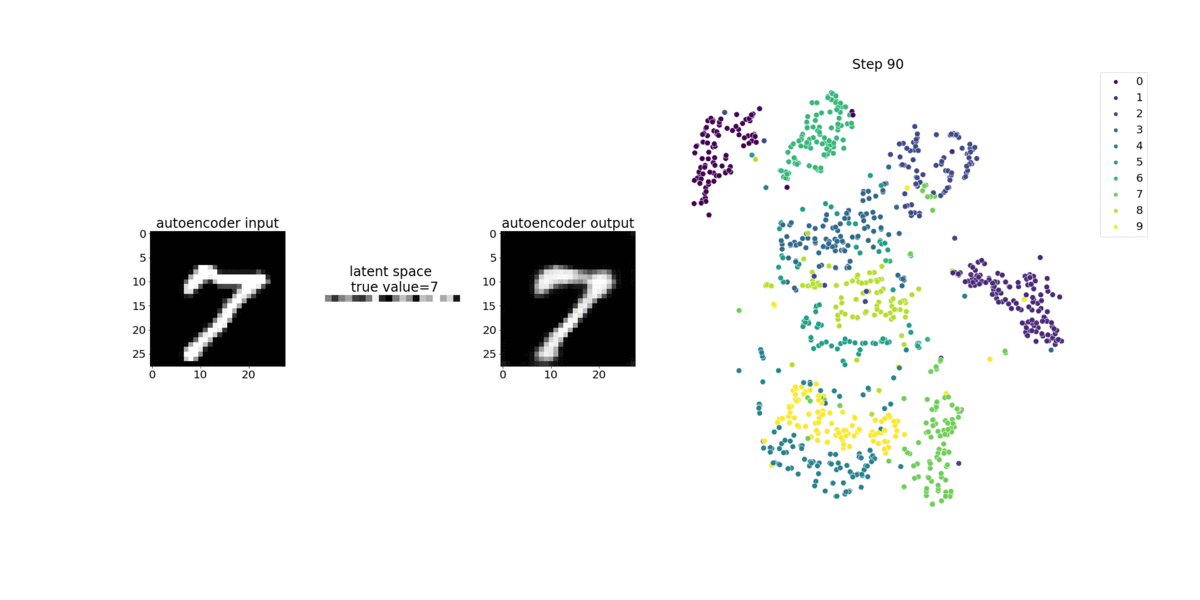
Verwendung des SageMaker Debuggers zur Überwachung der Aufmerksamkeit beim BERT-Modelltraining
Bidirectional Encode Representations from Transformers (BERT) ist ein Sprachrepräsentationsmodell. Wie der Name des Modells widerspiegelt, baut das BERT-Modell auf Transferlernen und dem Transformer-Modell für die Verarbeitung natürlicher Sprache (NLP) auf.
Das BERT-Modell ist vortrainiert für unbeaufsichtigte Aufgaben wie die Vorhersage fehlender Wörter in einem Satz oder die Vorhersage des nächsten Satzes, der natürlich einem vorherigen Satz folgt. Die Trainingsdaten enthalten 3,3 Milliarden Wörter (Tokens) englischen Textes, wie Wikipedia und elektronische Bücher. Als einfaches Beispiel kann das BERT-Modell den entsprechenden Verb-Tokens oder Pronomen-Tokens eines Subjekt-Tokens große Aufmerksamkeit schenken.
Das vortrainierte BERT-Modell kann mit einer zusätzlichen Ausgabeschicht optimiert werden, um eine hochmoderne Modelltraining in NLP-Aufgaben zu erreichen, wie z. B. automatisierte Beantwortung von Fragen, Textklassifizierung und vieles mehr.
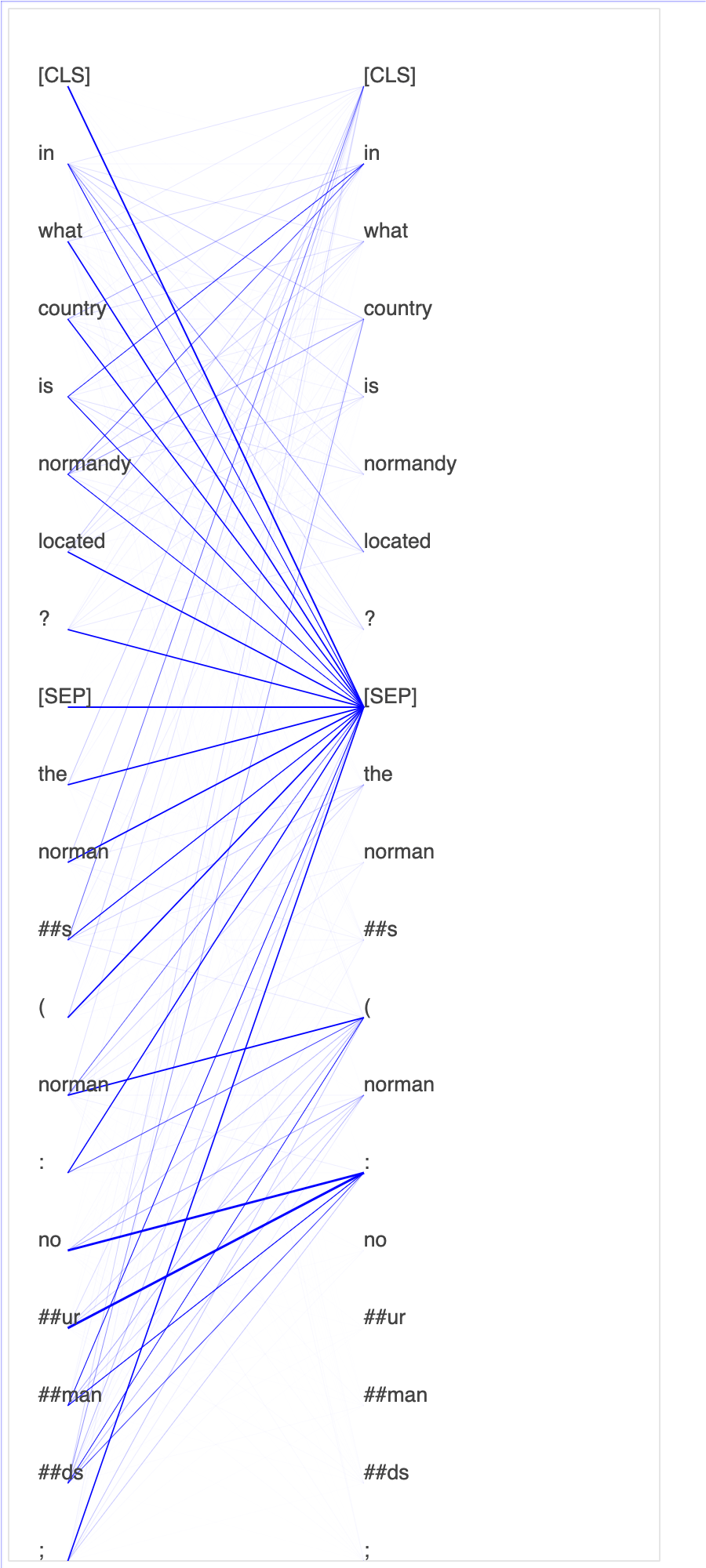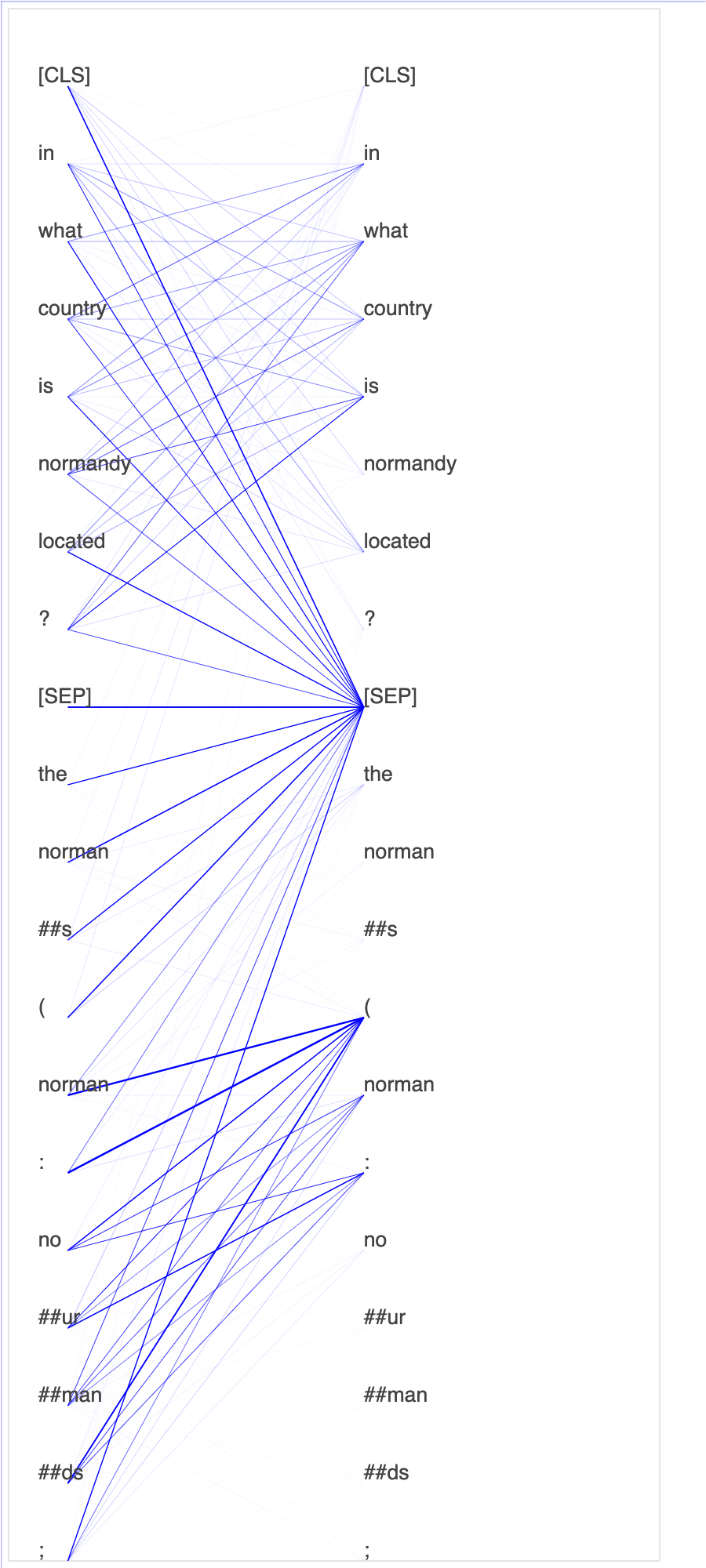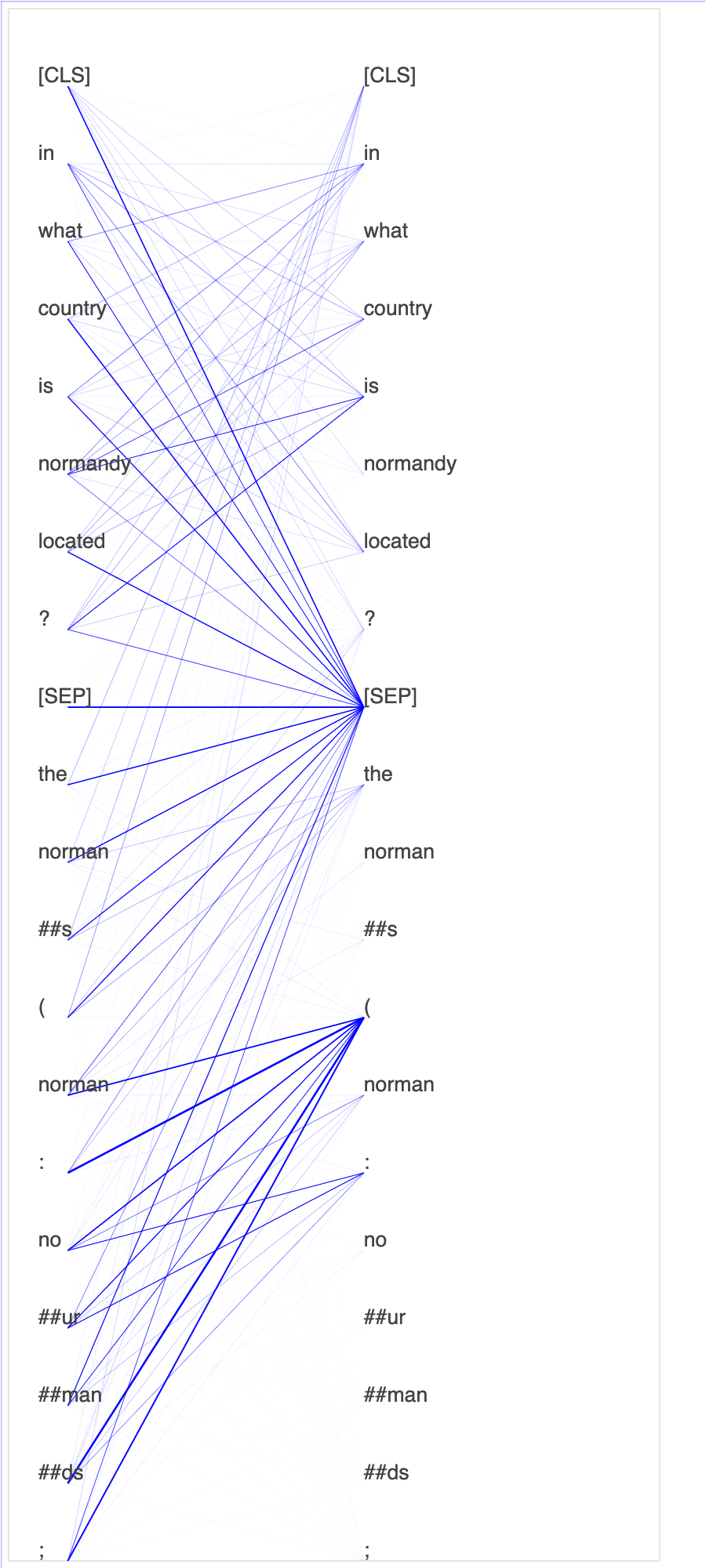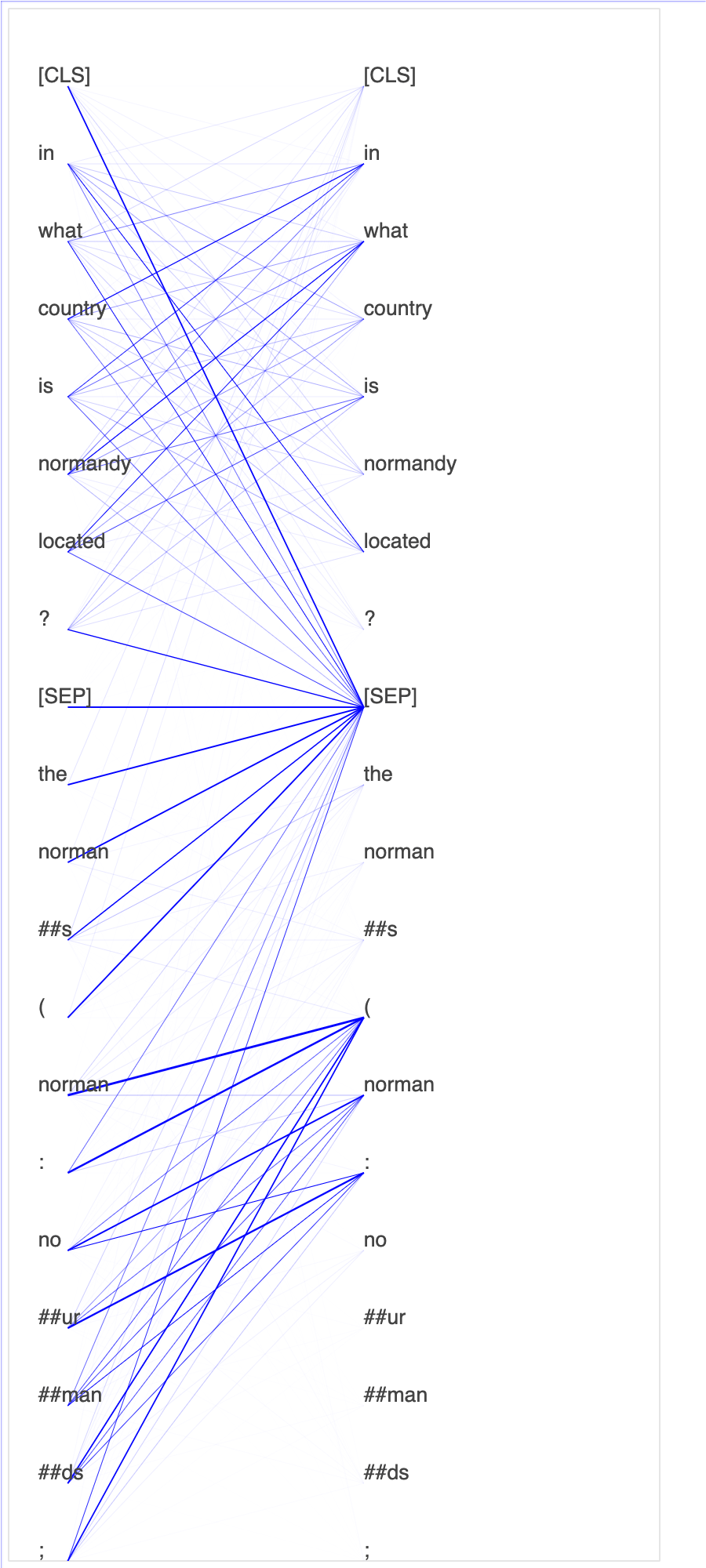
Der Debugger sammelt Tensoren aus dem Feinabstimmungsprozess. Im Kontext von NLP wird das Gewicht von Neuronen als Aufmerksamkeit bezeichnet.
Dieses Notizbuch zeigt, wie das vortrainierte BERT-Modell aus dem GluonNLP-Modellzoo für den
Das Plotten von Aufmerksamkeitswerten und einzelnen Neuronen in der Abfrage und Schlüsselvektoren kann helfen, Ursachen für falsche Modellvorhersagen zu identifizieren. Mit dem SageMaker KI-Debugger können Sie die Tensoren abrufen und die Aufmerksamkeitskopf-Ansicht während des Trainingsfortschritts in Echtzeit grafisch darstellen. So können Sie nachvollziehen, was das Modell gerade lernt.
Die folgende Animation zeigt die Aufmerksamkeitswerte der ersten 20 Eingabetokens für zehn Iterationen im Trainingsauftrag, der im Notebook-Beispiel bereitgestellt wird.
Verwendung von SageMaker Debugger zur Visualisierung von Klassenaktivierungskarten in Convolutional Neural Networks (CNNs)
Dieses Notizbuch zeigt, wie SageMaker Debugger verwendet werden kann, um Klassenaktivierungskarten für die Bilderkennung und Klassifizierung in Convolutional Neural Networks (CNNs) zu zeichnen. Beim Deep Learning ist ein Convolutional Neural Network (CNN oder ConvNet) eine Klasse von tiefen neuronalen Netzwerken, die am häufigsten zur Analyse visueller Bilder eingesetzt werden. Eine der Anwendungen, die die Klassenaktivierungskarten übernimmt, sind selbstfahrende Autos, die die sofortige Erkennung und Klassifizierung von Bildern wie Verkehrszeichen, Straßen und Hindernisse erfordern.
In diesem Notizbuch wird das PyTorch ResNet Modell anhand des deutschen Verkehrszeichendatensatzes
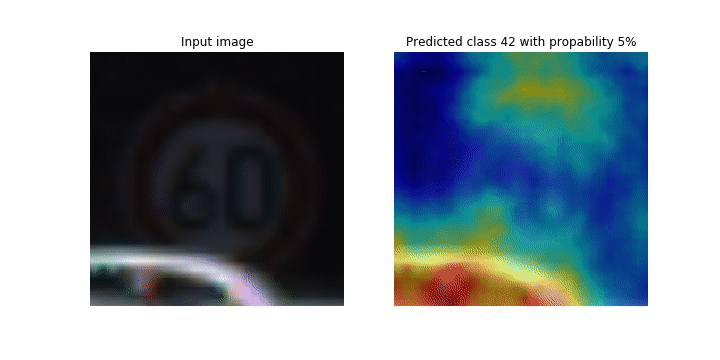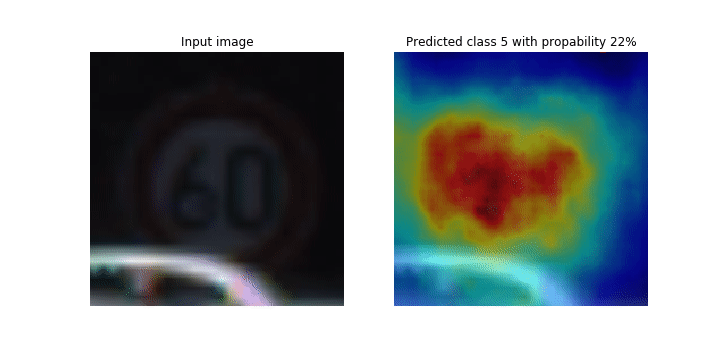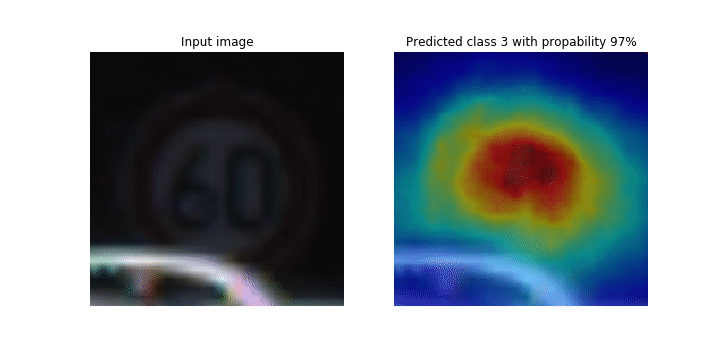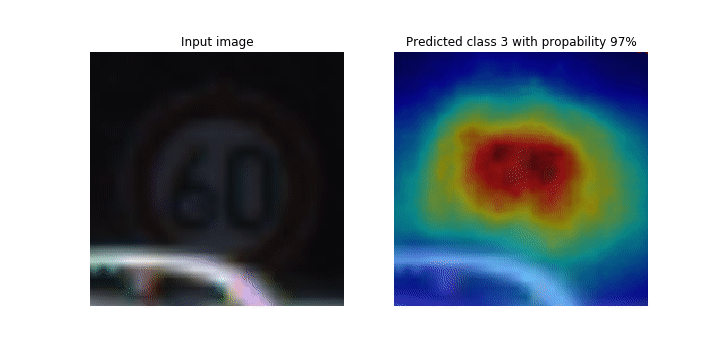
Während des Trainingsprozesses sammelt der SageMaker Debugger Tensoren, um die Klassenaktivierungskarten in Echtzeit darzustellen. Wie im animierten Bild gezeigt, hebt die Klassenaktivierungskarte (auch als Saliency Map bezeichnet) Regionen mit hoher Aktivierung in roter Farbe hervor.
Mithilfe von Tensoren, die von Debugger erfasst werden, können Sie visualisieren, wie sich die Aktivierungskarte während der Modelltraining entwickelt. Das Modell beginnt mit der Erkennung der Kante in der linken unteren Ecke zu Beginn des Trainingsauftrags. Im Verlauf des Trainings verlagert sich der Fokus auf die Mitte und erkennt das Tempolimitschild. Das Modell prognostiziert das Eingabebild erfolgreich als Klasse 3, also eine Klasse von 60km/h Geschwindigkeitsbegrenzungsschildern, mit einem Konfidenzniveau von 97%.
