Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Um Ihnen den Einstieg in SageMaker KI Inference zu erleichtern, lesen Sie die folgenden Abschnitte, in denen Ihre Optionen für die Implementierung Ihres Modells in SageMaker KI und das Abrufen von Schlussfolgerungen erläutert werden. Inferenzoptionen in Amazon AI SageMaker In diesem Abschnitt können Sie herausfinden, welche Funktion am besten zu Ihrem Anwendungsfall für Inferenz passt.
RessourcenIn diesem Abschnitt finden Sie weitere Informationen zur Problembehandlung und Referenzinformationen, Blogs und Beispiele, die Ihnen den Einstieg erleichtern, sowie allgemeine FAQs Informationen.
Themen
Bevor Sie beginnen
In diesen Themen wird davon ausgegangen, dass Sie ein oder mehrere Machine-Learning-Modelle erstellt und trainiert haben und bereit sind, sie bereitzustellen. Sie müssen Ihr Modell nicht in SageMaker KI trainieren, um Ihr Modell in SageMaker KI einzusetzen und daraus Schlüsse zu ziehen. Wenn Sie kein eigenes Modell haben, können Sie auch die integrierten Algorithmen der SageMaker KI oder vortrainierte Modelle verwenden.
Wenn Sie mit SageMaker KI noch nicht vertraut sind und noch kein Modell für die Implementierung ausgewählt haben, gehen Sie die Schritte im Tutorial Erste Schritte mit Amazon SageMaker AI durch. Machen Sie sich anhand des Tutorials damit vertraut, wie SageMaker KI den datenwissenschaftlichen Prozess verwaltet und wie sie mit der Modellbereitstellung umgeht. Weitere Informationen zum Trainieren eines Modells finden Sie unter Modelle trainieren.
Weitere Informationen, Referenzen und Beispiele finden Sie in der Ressourcen.
Schritte beim Modelleinsatz
Der allgemeine Arbeitsablauf für Inference-Endpunkte besteht aus den folgenden Schritten:
Erstellen Sie ein Modell in SageMaker AI Inference, indem Sie auf in Amazon S3 gespeicherte Modellartefakte und ein Container-Image verweisen.
Wählen Sie eine Inference-Option aus. Weitere Informationen finden Sie unter Inferenzoptionen in Amazon AI SageMaker .
Erstellen Sie eine SageMaker AI Inference-Endpunktkonfiguration, indem Sie den Instance-Typ und die Anzahl der Instances auswählen, die Sie hinter dem Endpunkt benötigen. Sie können Amazon SageMaker Inference Recommender verwenden, um Empfehlungen für Instance-Typen zu erhalten. Für Serverless Inference brauchen Sie nur die Speicherkonfiguration anzugeben, die Sie bei Ihrer Modellgröße brauchen.
Erstellen Sie einen SageMaker AI Inference-Endpunkt.
Rufen Sie Ihren Endpunkt auf, um als Antwort eine Inference zu erhalten.
Das folgende Diagramm zeigt den vorangehenden Arbeitsablauf.
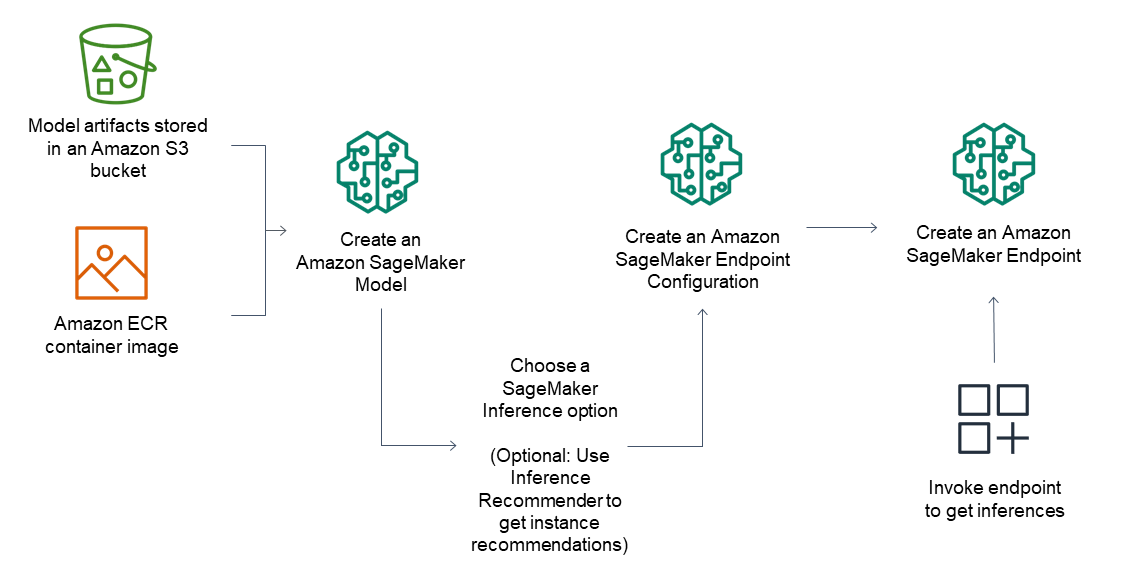
Sie können diese Aktionen mit der AWS Konsole, dem AWS SDKs, dem SageMaker Python-SDK AWS CloudFormation oder dem ausführen AWS CLI.
Für Batch-Inference mit Stapel-Transformation verweisen Sie auf Ihre Modellartefakte und Eingabedaten und erstellen Sie einen Batch-Inference-Auftrag. Anstatt einen Endpunkt für Inferenzen zu hosten, gibt SageMaker KI Ihre Schlussfolgerungen an einen Amazon S3 S3-Standort Ihrer Wahl aus.
