Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden Sie fortlaufende Bereitstellungen
Wenn Sie Ihren Endpunkt aktualisieren, können Sie einen fortlaufenden Einsatz angeben, um den Verkehr schrittweise von Ihrer alten Flotte auf eine neue Flotte zu verlagern. Sie können die Größe der Schritte zur Verkehrsverlagerung steuern und einen Testzeitraum festlegen, in dem die neuen Instances auf Probleme hin überwacht werden, bevor Instances aus der alten Flotte beendet werden. Bei fortlaufenden Bereitstellungen werden die Instances auf der alten Flotte nach jeder Verlagerung des Datenverkehrs auf die neue Flotte bereinigt, wodurch die Anzahl der zusätzlichen Instances, die für die Aktualisierung Ihres Endpunkts erforderlich sind, reduziert wird. Dies ist insbesondere für beschleunigte Instances nützlich, die stark nachgefragt werden.
Bei fortlaufenden Bereitstellungen wird die vorherige Bereitstellung Ihrer Modellversion schrittweise durch die neue Version ersetzt, indem Ihr Endpunkt in konfigurierbaren Batchgrößen aktualisiert wird. Das Verhalten rollierender Bereitstellungen zur Verkehrsverlagerung ähnelt dem linearen Modus zur Verkehrsverlagerung bei der blue/green deployments, but rolling deployments provide you with the benefit of reduced capacity requirements when compared to blue/green deployments. With rolling deployments, fewer instances are active at a time, and you have more granular control over how many instances you want to update in the new fleet. You should consider using a rolling deployment instead of a blue/green Bereitstellung, wenn Sie über große Modelle oder einen großen Endpunkt mit vielen Instanzen verfügen.
In der folgenden Liste werden die wichtigsten Funktionen von fortlaufenden Bereitstellungen in Amazon SageMaker AI beschrieben:
-
Backzeit.Die Backphase ist ein festgelegter Zeitraum, um die neue Flotte zu überwachen, bevor mit der nächsten Einsatzphase begonnen wird. Wenn einer der vordefinierten Alarme während einer Back-Phase ausgelöst wird, wird der gesamte Endpunktverkehr auf die alte Flotte zurückgesetzt. Die Backphase hilft Ihnen dabei, Vertrauen in Ihr Update aufzubauen, bevor Sie den Traffic dauerhaft verlagern.
-
Größe der rollenden Charge. Sie haben die genaue Kontrolle über die Größe jedes Batches für die Verkehrsverlagerung oder über die Anzahl der Instances, die Sie in jedem Batch aktualisieren möchten. Diese Zahl kann zwischen 5 und 50% der Größe Ihrer Flotte liegen. Sie können die Batchgröße als Anzahl von Instances oder als Gesamtanteil Ihrer Flotte angeben.
-
Automatisches Zurücksetzen.Sie können CloudWatch Amazon-Alarme angeben, die SageMaker KI zur Überwachung der neuen Flotte verwendet. Wenn ein Problem mit dem aktualisierten Code einen der Alarme auslöst, leitet SageMaker KI ein automatisches Rollback zur alten Flotte ein, um die Verfügbarkeit aufrechtzuerhalten und so das Risiko zu minimieren.
Anmerkung
Wenn Ihr Endgerät eine der auf der Seite Ausnahmen aufgeführten Funktionen verwendet, können Sie keine fortlaufenden Bereitstellungen verwenden.
Funktionsweise
Während einer fortlaufenden Bereitstellung stellt SageMaker KI die Infrastruktur bereit, um den Verkehr von der alten Flotte auf die neue Flotte zu verlagern, ohne dass alle neuen Instanzen gleichzeitig bereitgestellt werden müssen. SageMaker KI verwendet die folgenden Schritte, um den Verkehr zu verlagern:
-
SageMaker KI stellt die erste Gruppe von Instances in der neuen Flotte bereit.
-
Ein Teil des Datenverkehrs wird von den alten Instances auf den ersten Batch neuer Instances verlagert.
-
Wenn nach der Backphase keine CloudWatch Amazon-Alarme ausgelöst werden, bereinigt SageMaker KI einen Stapel alter Instances.
-
SageMaker KI stellt Instances weiterhin stapelweise bereit, verschiebt und bereinigt, bis die Bereitstellung abgeschlossen ist.
Wenn während einer der Back-Phasen ein Alarm ausgelöst wird, wird der Traffic in Batches einer von Ihnen angegebenen Größe auf die alte Flotte zurückgeführt. Alternativ können Sie den fortlaufenden Einsatz so festlegen, dass 100% des Verkehrs wieder auf die alte Flotte umgeleitet werden, wenn ein Alarm ausgelöst wird.
Das folgende Diagramm zeigt den Verlauf eines erfolgreichen rollierenden Einsatzes, wie in den vorherigen Schritten beschrieben.
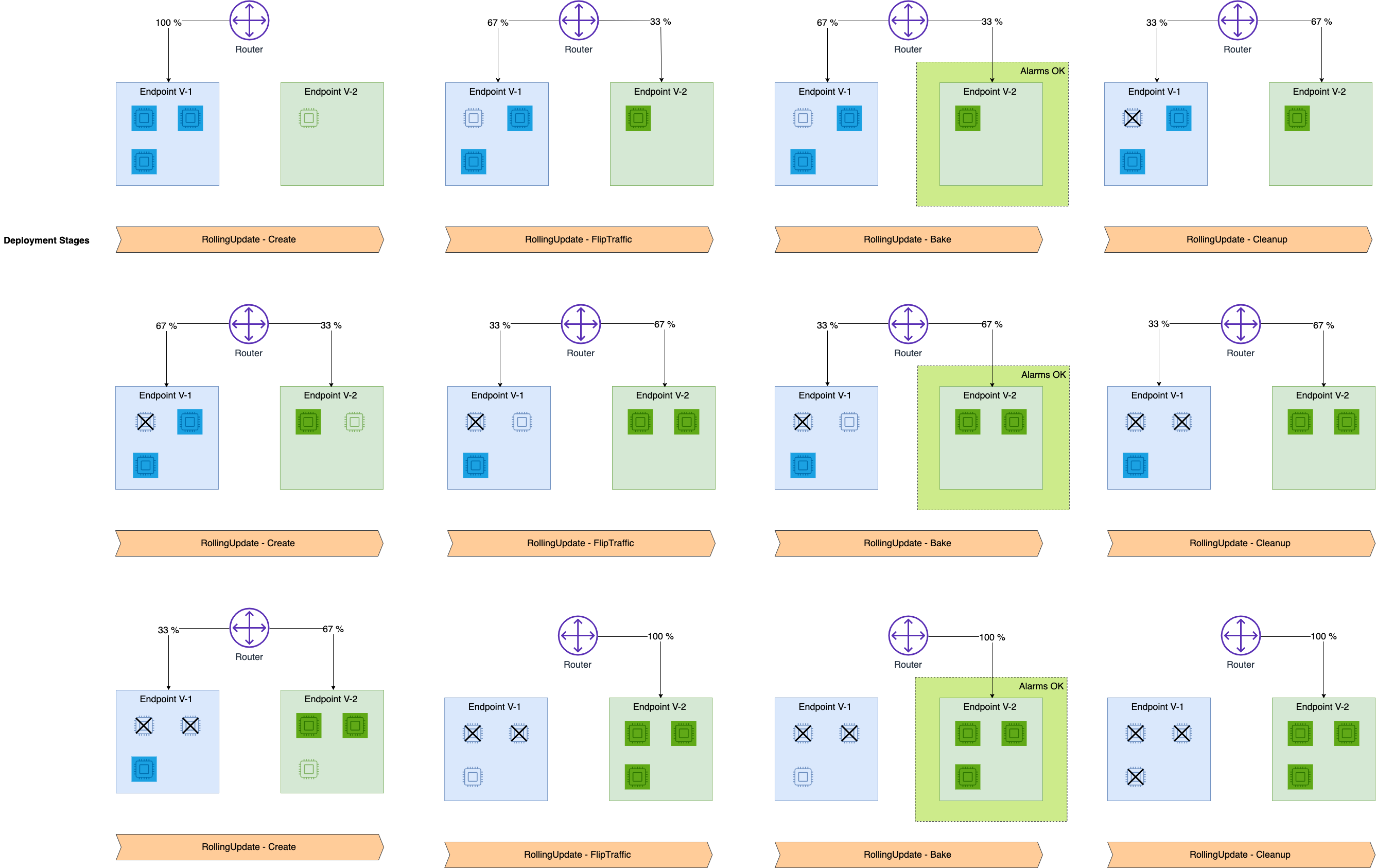
Um eine fortlaufende Bereitstellung zu erstellen, müssen Sie nur Ihre gewünschte Bereitstellungskonfiguration angeben. Dann kümmert sich SageMaker KI für Sie um die Bereitstellung neuer Instances, die Terminierung alter Instances und die Verlagerung des Traffics. Sie können Ihre Bereitstellung mithilfe der vorhandenen Befehle und und erstellen UpdateEndpointCreateEndpoint SageMaker APIund AWS Command Line Interface verwalten.
Voraussetzungen
Bevor Sie eine fortlaufende Bereitstellung einrichten, müssen Sie CloudWatch Amazon-Alarme erstellen, um Metriken von Ihrem Endpunkt aus zu überwachen. Wenn einer der Alarme während der Backphase ausgelöst wird, wird der Traffic wieder auf Ihre alte Flotte übertragen. Informationen zum Einrichten von CloudWatch Alarmen auf einem Endpunkt finden Sie auf der Seite mit den Voraussetzungen für die automatische Rollback-Konfiguration und Überwachung. Weitere Informationen zu CloudWatch Alarmen finden Sie unter Verwenden von CloudWatch Amazon-Alarmen im CloudWatch Amazon-Benutzerhandbuch.
Sehen Sie sich auch die Seite mit den Ausnahmen an, um sicherzustellen, dass Ihr Endpunkt die Anforderungen für eine fortlaufende Bereitstellung erfüllt.
Ermitteln Sie die Größe der fortlaufenden Charge
Bevor Sie Ihren Endpunkt aktualisieren, bestimmen Sie die Batchgröße, die Sie für die schrittweise Verlagerung des Datenverkehrs auf die neue Flotte verwenden möchten.
Für fortlaufende Bereitstellungen können Sie eine Chargengröße angeben, die 5-50% der Kapazität Ihrer Flotte entspricht. Wenn Sie sich für eine große Batchgröße entscheiden, wird die Bereitstellung schneller abgeschlossen. Beachten Sie jedoch, dass der Endpunkt bei der Aktualisierung mehr Kapazität benötigt, was in etwa dem Mehraufwand für die Batchgröße entspricht. Wenn Sie eine kleinere Batchgröße wählen, dauert die Bereitstellung länger, aber Sie verbrauchen während der Bereitstellung weniger Kapazität.
Eine laufende Bereitstellung konfigurieren
Sobald Sie für Ihre Bereitstellung bereit sind und CloudWatch Alarme für Ihren Endpunkt eingerichtet haben, können Sie die Bereitstellung mithilfe der SageMaker KI UpdateEndpointAPIoder des Befehls update-endpoint in der AWS Command Line Interface starten.
Wie aktualisiert man einen Endpunkt
Das folgende Beispiel zeigt, wie Sie Ihren Endpunkt mit einer fortlaufenden Bereitstellung aktualisieren können, indem Sie die Methode update_endpoint des Boto3 AI-Clients
Verwenden Sie das folgende Beispiel und die folgenden Felder, um eine fortlaufende Bereitstellung zu konfigurieren:
-
Verwenden Sie für
EndpointNameden Namen des vorhandenen Endpunkts, den Sie aktualisieren möchten. -
Verwenden Sie für
EndpointConfigNameden Namen der Endpunkt-Konfiguration, die Sie verwenden möchten. -
Im
AutoRollbackConfigurationObjekt, innerhalb desAlarmsFeldes, können Sie Ihre CloudWatch Alarme nach Namen hinzufügen. Erstellen Sie einenAlarmName: <your-cw-alarm>Eintrag für jeden Alarm, den Sie verwenden möchten. -
Geben Sie unter
DeploymentConfigfür dasRollingUpdatePolicyObjekt die folgenden Felder an:-
MaximumExecutionTimeoutInSeconds– Das Zeitlimit für die gesamte Bereitstellung. Eine Überschreitung dieses Limits führt zu einem Timeout. Der Höchstwert, den Sie für dieses Feld angeben können, ist 28800 Sekunden oder 8 Stunden. -
WaitIntervalInSeconds— Die Dauer der Backphase, in der die SageMaker KI die Alarme für jede Charge der neuen Flotte überwacht. -
MaximumBatchSize– Geben Sie dieTypeCharge an, die Sie verwenden möchten (entweder die Anzahl der Instances oder der Gesamtanteil Ihrer Flotte) und dieValueoder die Größe jeder Charge. -
RollbackMaximumBatchSize– Verwenden Sie dieses Objekt, um die Rollback-Strategie für den Fall festzulegen, dass ein Alarm ausgelöst wird. Geben Sie dieTypeAnzahl der Chargen an, die Sie verwenden möchten (entweder die Anzahl der Instances oder der Gesamtanteil Ihrer Flotte) und dieValueoder die Größe der einzelnen Chargen. Wenn Sie diese Felder nicht angeben oder den Wert auf 100% Ihres Endpunkts setzen, verwendet SageMaker KI eine blaue/grüne Rollback-Strategie und rollt den gesamten Verkehr auf die alte Flotte zurück, wenn ein Alarm ausgelöst wird.
-
import boto3 client = boto3.client("sagemaker") response = client.update_endpoint( EndpointName="<your-endpoint-name>", EndpointConfigName="<your-config-name>", DeploymentConfig={ "AutoRollbackConfiguration": { "Alarms": [ { "AlarmName": "<your-cw-alarm>" }, ] }, "RollingUpdatePolicy": { "MaximumExecutionTimeoutInSeconds": number, "WaitIntervalInSeconds": number, "MaximumBatchSize": { "Type": "INSTANCE_COUNT" | "CAPACITY_PERCENTAGE" (default), "Value": number }, "RollbackMaximumBatchSize": { "Type": "INSTANCE_COUNT" | "CAPACITY_PERCENTAGE" (default), "Value": number }, } } )
Nach der Aktualisierung Ihres Endpunkts möchten Sie möglicherweise den Status Ihrer fortlaufenden Bereitstellung und den Zustand Ihres Endpunkts überprüfen. Sie können den Status Ihres Endpunkts in der SageMaker KI-Konsole überprüfen, oder Sie können den Status Ihres Endpunkts mit der überprüfen. DescribeEndpointAPI
In dem von der zurückgegebenen VariantStatus Objekt gibt das Status Feld Auskunft über den aktuellen Bereitstellungs- oder Betriebsstatus Ihres Endpunkts. DescribeEndpoint API Weitere Informationen zu den möglichen Status und ihrer Bedeutung finden Sie unter ProductionVariantStatus.
Wenn Sie versucht haben, eine fortlaufende Bereitstellung durchzuführen und der Status Ihres Endpunkts lautet UpdateRollbackFailed, finden Sie im folgenden Abschnitt Hilfe zur Fehlerbehebung.
Fehlerbehandlung
Wenn Ihre rollenden Bereitstellungen fehlschlagen und auch das automatische Rollback fehlschlägt, kann Ihr Endpunkt den Status von UpdateRollbackFailed behalten. Dieser Status bedeutet, dass für die Instances hinter Ihrem Endpunkt unterschiedliche Endpunktkonfigurationen bereitgestellt werden und Ihr Endpunkt mit einer Mischung aus alten und neuen Endpunktkonfigurationen in Betrieb ist.
Sie können den UpdateEndpointAPIerneut aufrufen, um Ihren Endpunkt wieder in einen fehlerfreien Zustand zu versetzen. Geben Sie Ihre gewünschte Endpunktkonfiguration und Bereitstellungskonfiguration an (entweder als fortlaufende Bereitstellung, als blaue/grüne Bereitstellung oder beides), um Ihren Endpunkt zu aktualisieren.
Sie können den aufrufen DescribeEndpointAPI, um den Zustand Ihres Endpunkts erneut zu überprüfen, der im VariantStatus Objekt als Status Feld zurückgegeben wird. Wenn Ihr Update erfolgreich ist, kehrt Ihr Endpunkt Status zu InService zurück.
