Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Skalierung des Trainings
In den folgenden Abschnitten werden Szenarien behandelt, in denen Sie das Training möglicherweise erweitern möchten, und wie Sie dies mithilfe von AWS Ressourcen tun können. Möglicherweise möchten Sie das Training in einer der folgenden Situationen skalieren:
-
Skalierung von einem einzelnen GPU auf viele GPUs
-
Skalieren von einer einzelnen Instance auf mehrere Instances
-
Verwenden von benutzerdefinierten Trainingsskripten
Skalierung von einem einzelnen GPU auf viele GPUs
Die Datenmenge oder die Größe des Modells, das beim Machine Learning verwendet wird, können zu Situationen führen, in denen das Training eines Modells länger dauert als Sie warten möchten. Manchmal funktioniert das Training überhaupt nicht, weil das Modell oder die Trainingsdaten zu groß sind. Eine Lösung besteht darin, die Anzahl der Geräte zu erhöhen, die GPUs Sie für das Training verwenden. Bei einer Instanz mit mehrerenGPUs, z. B. einer p3.16xlarge Instanz mit achtGPUs, werden die Daten und die Verarbeitung auf die acht aufgeteiltGPUs. Wenn Sie verteilte Trainingsbibliotheken verwenden, kann dies zu einer nahezu linearen Beschleunigung der Zeit führen, die für das Trainieren Ihres Modells benötigt wird. Es dauert etwas mehr als 1/8 der Zeit, die es p3.2xlarge mit einer einzigen GPU Person gedauert hätte.
| Instance-Typ | GPUs |
|---|---|
| p3.2xgroß | 1 |
| p3.8xgroß | 4 |
| p3.16xgroß | 8 |
| p3dn.24xgroß | 8 |
Anmerkung
Die beim SageMaker Training verwendeten ML-Instanztypen haben dieselbe Anzahl GPUs wie die entsprechenden p3-Instanztypen. ml.p3.8xlargeHat zum Beispiel dieselbe Anzahl von GPUs wie p3.8xlarge - 4.
Skalieren von einer einzelnen Instance auf mehrere Instances
Wenn Sie Ihr Training noch weiter skalieren möchten, können Sie mehr Instances verwenden. Sie sollten jedoch einen größeren Instance-Typ wählen, bevor Sie weitere Instances hinzufügen. Sehen Sie sich die vorherige Tabelle an, um zu sehen, wie GPUs viele es in jedem p3-Instance-Typ gibt.
Wenn Sie den Sprung von einer auf eine GPU GPUs auf vier bei a p3.2xlarge geschafft habenp3.8xlarge, aber entscheiden, dass Sie mehr Rechenleistung benötigen, können Sie eine bessere Leistung und geringere Kosten erzielen, wenn Sie a wählen, p3.16xlarge bevor Sie versuchen, die Anzahl der Instanzen zu erhöhen. Je nachdem, welche Bibliotheken Sie verwenden, sind die Leistung besser und die Kosten niedriger als bei einem Szenario, in dem Sie mehrere Instances verwenden, wenn Sie das Training auf einer einzelnen Instance fortsetzen.
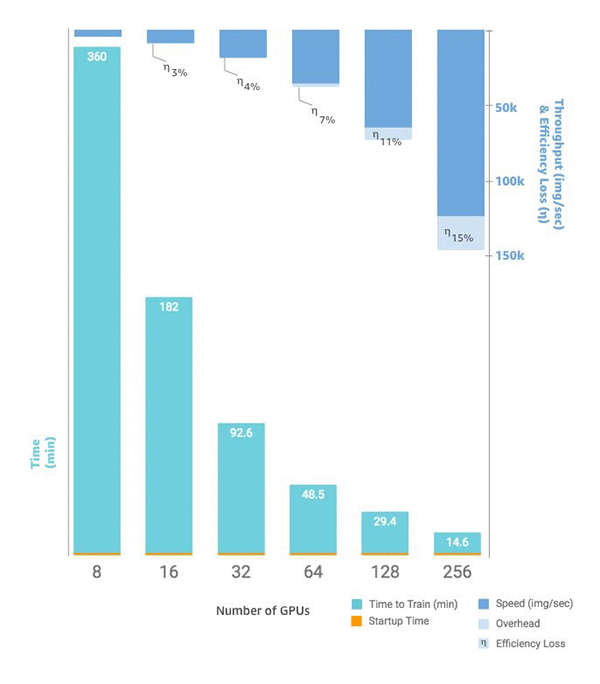
Wenn Sie bereit sind, die Anzahl der Instanzen zu skalieren, können Sie dies mit der SageMaker SDK estimator AI-Python-Funktion tun, indem Sie Ihre einstelleninstance_count. Sie können beispielsweise instance_type = p3.16xlarge und instance_count =
2 festlegen. Statt der acht GPUs bei einer einzigen stehen p3.16xlarge Ihnen 16 GPUs für zwei identische Instanzen zur Verfügung. Das folgende Diagramm zeigt Skalierung und Durchsatz, angefangen bei acht GPUs
Benutzerdefinierte Trainingsskripte
SageMaker KI macht es zwar einfach, die Anzahl der Instanzen bereitzustellen und zu skalierenGPUs, und je nach Framework Ihrer Wahl kann die Verwaltung der Daten und Ergebnisse sehr schwierig sein, weshalb häufig externe unterstützende Bibliotheken verwendet werden. Diese einfachste Form des verteilten Trainings erfordert eine Änderung Ihres Trainingsskripts, um die Datenverteilung zu verwalten.
SageMaker KI unterstützt auch Horovod und Implementierungen von verteiltem Training, die für jedes wichtige Deep-Learning-Framework systemspezifisch sind. Wenn Sie sich dafür entscheiden, Beispiele aus diesen Frameworks zu verwenden, können Sie dem Container-Leitfaden von SageMaker AI für Deep Learning Containers und verschiedenen Beispielnotizbüchern
