Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewerten des Modells
Nachdem Sie nun ein Modell mit Amazon SageMaker AI trainiert und bereitgestellt haben, evaluieren Sie das Modell, um sicherzustellen, dass es genaue Vorhersagen für neue Daten generiert. Verwenden Sie für die Modellbewertung den Testdatensatz, den Sie in Vorbereiten eines Datensatzes erstellt haben.
Evaluieren Sie das für SageMaker AI Hosting Services bereitgestellte Modell
Um das Modell auszuwerten und in der Produktion zu verwenden, rufen Sie den Endpunkt mit dem Testdatensatz auf und überprüfen Sie, ob die erhaltenen Schlussfolgerungen die Zielgenauigkeit ergeben, die Sie erreichen möchten.
So bewerten Sie das Modell
-
Richten Sie die folgende Funktion ein, um jede Zeile des Testsatzes vorherzusagen. Im folgenden Beispielcode besteht das
rowsArgument darin, die Anzahl der Zeilen anzugeben, die gleichzeitig vorhergesagt werden sollen. Sie können den Wert ändern, um eine Batch-Inferenz durchzuführen, die die Hardwareressourcen der Instance voll ausnutzt.import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
Führen Sie den folgenden Code aus, um Vorhersagen für den Testdatensatz zu treffen und ein Histogramm zu zeichnen. Sie müssen nur die Feature-Spalten des Testdatensatzes verwenden, mit Ausnahme der 0-ten Spalte für die tatsächlichen Werte.
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()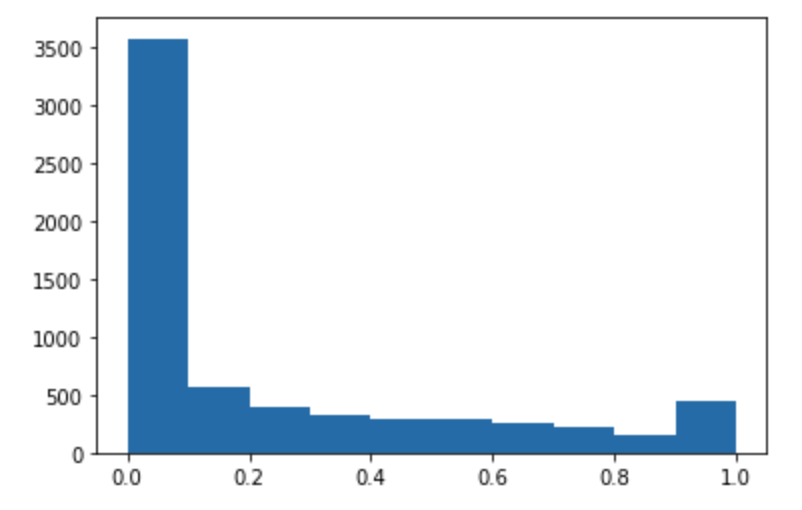
-
Die vorhergesagten Werte sind vom Typ Float. Um
TrueoderFalseauf der Grundlage der Float-Werte zu bestimmen, müssen Sie einen Grenzwert festlegen. Wie im folgenden Beispielcode gezeigt, verwenden Sie die Scikit-learn Bibliothek, um den Output-Confusion Metrics and Classification Report mit einem Cutoff von 0,5 zurückzugeben.import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))Dies sollte die folgende Konfusionsmatrix zurückgeben:
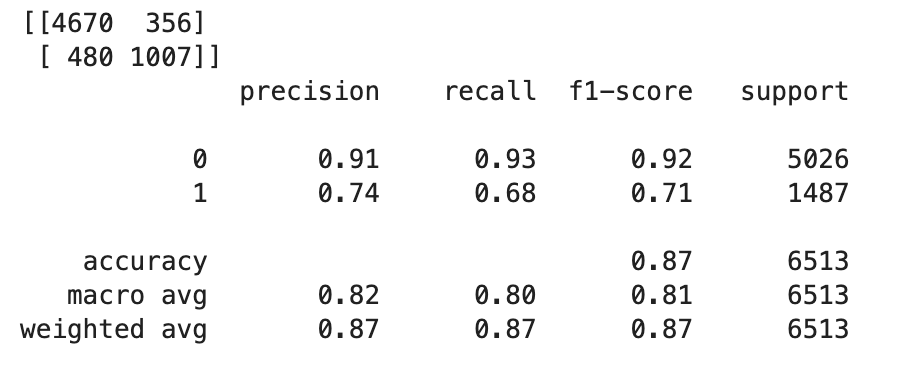
-
Um den besten Grenzwert für den angegebenen Testsatz zu ermitteln, berechnen Sie die Log-Loss-Funktion der logistischen Regression. Die Log-Loss-Funktion ist definiert als die negative Log-Likelihood eines logistischen Modells, das Vorhersagewahrscheinlichkeiten für seine Ground-Truth-Beschriftungen zurückgibt. Im folgenden Beispielcode werden die logarithmischen Verlustwerte (
-(y*log(p)+(1-y)log(1-p)) numerisch und iterativ berechnet. Dabei handelt es sich beiyum die wahre Beschriftung und beipum eine Wahrscheinlichkeitsschätzung der entsprechenden Testprobe. Es wird ein Diagramm mit logarithmischem Verlust im Vergleich zum Grenzwert zurückgegeben.import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()Dies sollte die folgende Log-Verlustkurve zurückgeben.
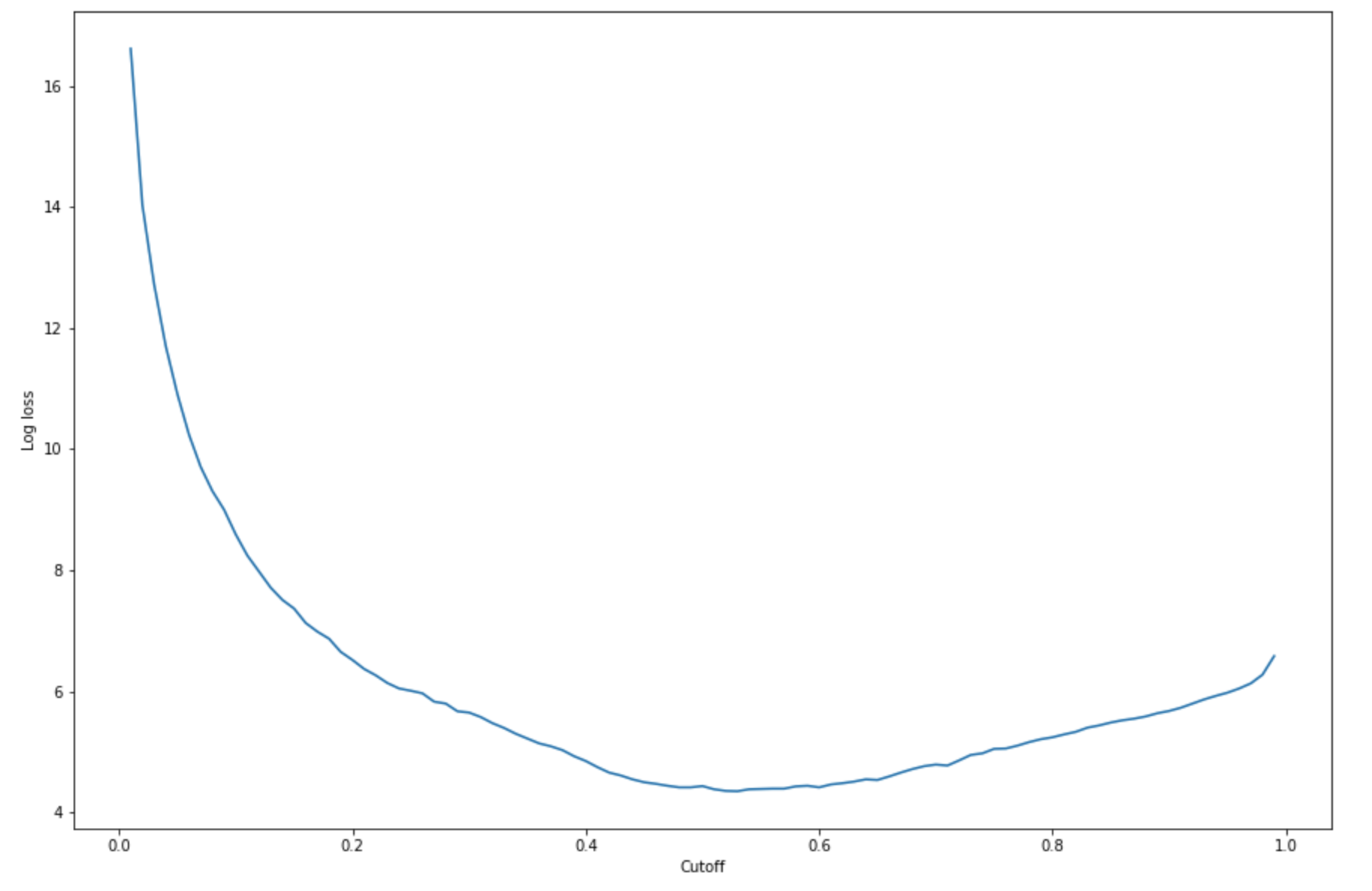
-
Ermitteln Sie die Mindestpunkte der Fehlerkurve mithilfe der
minFunktionen NumPyargminund:print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )Das sollte folgendes zurückgeben:
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897.Anstatt die Log-Loss-Funktion zu berechnen und zu minimieren, können Sie als Alternative eine Kostenfunktion schätzen. Wenn Sie beispielsweise ein Modell darauf trainieren möchten, eine binäre Klassifikation für ein Geschäftsproblem durchzuführen, z. B. ein Problem mit der Vorhersage der Kundenabwanderung, können Sie Gewichtungen für die Konfusionsmatrix festlegen und die Kostenfunktion entsprechend berechnen.
Sie haben jetzt Ihr erstes SageMaker KI-Modell trainiert, eingesetzt und evaluiert.
Tipp
Verwenden Sie Amazon Model Monitor und SageMaker AI Clarify, um SageMaker Modellqualität, Datenqualität und Verzerrungen zu überwachen. Weitere Informationen finden Sie unter Amazon SageMaker Model Monitor, Datenqualität überwachen, Modellqualität überwachen, Verzerrungsdrift überwachen und Funktionszuordnungsabweichung überwachen.
Tipp
Verwenden Sie Amazon Augmented AI-Workflows zur mesnchlichen Überprüfung, um ML-Vorhersagen mit geringer Zuverlässigkeit oder eine Zufallsstichprobe von Vorhersagen von Menschen überprüfen zu lassen. Weitere Informationen finden Sie unter Amazon Augmented AI for Human Review verwenden.
