Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Feature Store-Konzepte
Wir listen häufig verwendete Begriffe im Amazon SageMaker Feature Store auf, gefolgt von Beispieldiagrammen zur Veranschaulichung einiger Konzepte:
-
Feature Store: Speicher- und Datenmanagementebene für Funktionen des maschinellen Lernens (ML). Dient als zentrale Informationsquelle zum Speichern, Abrufen, Entfernen, Nachverfolgen, Teilen, Entdecken und Steuern des Zugriffs auf Funktionen. Im folgenden Beispieldiagramm ist der Feature Store ein Speicher für Ihre Feature-Gruppen, der Ihre ML-Daten enthält und zusätzliche Dienste bereitstellt.
-
Online-Speicher: Speicher mit niedriger Latenz und hoher Verfügbarkeit für eine Feature-Gruppe, der die Suche nach Datensätzen in Echtzeit ermöglicht. Der Online-Speicher ermöglicht über die
GetRecordAPI einen schnellen Zugriff auf den neuesten Datensatz. -
Offline-Speicher: Speichert historische Daten in Ihrem Amazon-S3-Bucket. Der Offline-Speicher wird verwendet, wenn Lesevorgänge mit niedriger Latenz (unter einer Sekunde) nicht erforderlich sind. Der Offline-Speicher kann beispielsweise verwendet werden, wenn Sie Funktionen für die Erkundung, das Modelltraining und die Batch-Inferenz speichern und bereitstellen möchten.
-
Feature-Gruppe: Die Hauptressource von Feature Store, die die Daten und Metadaten enthält, die für das Training oder die Vorhersage mit einem ML-Modell verwendet werden. Eine Feature-Gruppe ist eine logische Gruppierung von Features, die zur Beschreibung von Datensätzen verwendet werden. Im folgenden Beispieldiagramm enthält eine Feature-Gruppe Ihre ML-Daten.
-
Merkmal: Eine Eigenschaft, die als eine der Eingaben für das Training oder die Vorhersage anhand Ihres ML-Modells verwendet wird. In der Feature Store API ist ein Feature ein Attribut eines Datensatzes. Im folgenden Beispieldiagramm beschreibt ein Feature eine Spalte in Ihrer ML-Datentabelle.
-
Feature-Definition: Bestehtaus einem Namen und einem der Datentypen: Ganzzahl, Zeichenfolge oder Bruchzahl. Eine Feature-Gruppe enthält eine Liste von Feature-Definitionen. Weitere Informationen zu Feature Store-Datentypen finden Sie unter Datentypen.
-
Datensatz: Sammlung von Werten für Features für eine einzelne Datensatz-ID. Eine Kombination aus Datensatz-ID und Ereigniszeitwerten identifiziert einen Datensatz innerhalb einer Feature-Gruppe eindeutig. Im folgenden Beispieldiagramm ist ein Datensatz eine Zeile in Ihrer ML-Datentabelle.
-
Name der Datensatz-ID: Die Datensatz-ID ist der Name der Funktion, die die Datensätze identifiziert. Er muss sich auf einen der Namen eines Features beziehen, die in den Feature-Definitionen der Feature-Gruppe definiert sind. Jede Feature-Gruppe ist mit einem Datensatz-Identifikationsnamen definiert.
-
Zeitpunkt des Ereignisses: Von Ihnen eingegebener Zeitstempel, der dem Zeitpunkt entspricht, zu dem das Datensatzereignis eingetreten ist. Alle Datensätze in einer Feature-Gruppe müssen eine entsprechende Ereigniszeit haben. Der Online-Speicher enthält nur den Datensatz, der der letzten Ereigniszeit entspricht, wohingegen der Offline-Speicher alle historischen Datensätze enthält. Weitere Informationen zu Ereigniszeitformaten finden Sie unter Datentypen.
-
Ingestion: Hinzufügen neuer Datensätze zu einer Feature-Gruppe. Die Aufnahme erfolgt in der Regel über die
PutRecordAPI.
Diagramm mit Übersicht über Konzepte
Im folgenden Beispieldiagramm werden einige Feature Store-Konzepte konzeptualisiert:

Der Feature Store enthält Ihre Feature-Gruppen und eine Feature-Gruppe enthält Ihre ML-Daten. Im Beispieldiagramm enthält die ursprüngliche Feature-Gruppe eine Datentabelle mit drei Features (die jeweils eine Spalte beschreiben) und zwei Datensätzen (Zeilen).
-
Die Definition eines Features beschreibt den Feature-Namen und den Datentyp der Feature-Werte, die mit Datensätzen verknüpft sind.
-
Ein Datensatz enthält die Feature-Werte und wird anhand seiner Datensatz-ID eindeutig identifiziert. Er muss die Uhrzeit des Ereignisses enthalten.
Verschluckungsdiagramme
Bei der Aufnahme handelt es sich um das Hinzufügen eines oder mehrerer Datensätze zu einer vorhandenen Feature-Gruppe. Die Online- und Offline-Speichers werden für verschiedene Speicheranwendungsfälle unterschiedlich aktualisiert.
Aufnahme in das Beispiel des Online-Speichers
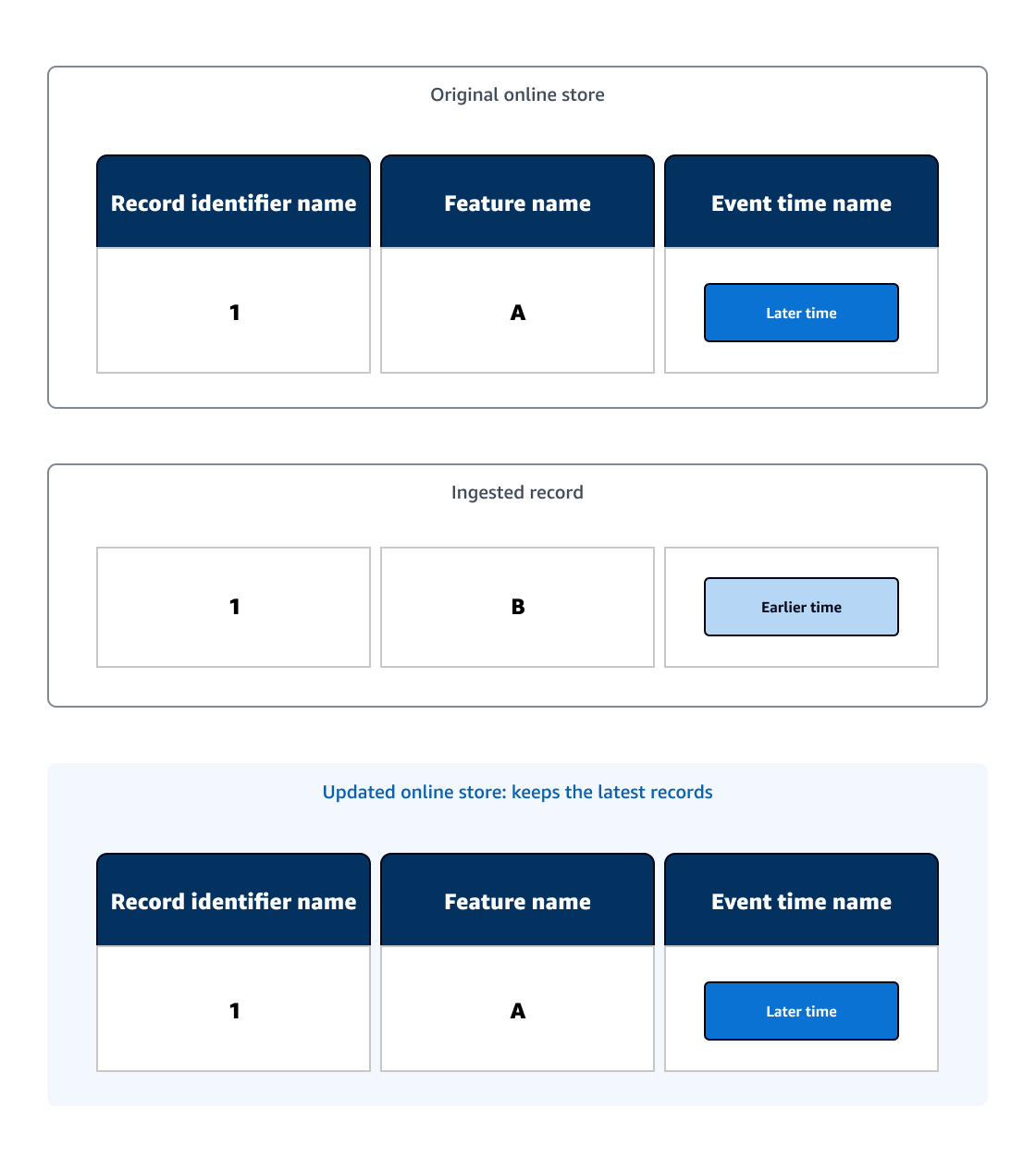
Der Online-Speicher dient als Echtzeit-Suchfunktion für Datensätze und speichert nur die aktuellsten Datensätze. Nachdem ein Datensatz in einen bestehenden Online-Speicher aufgenommen wurde, speichert der aktualisierte Online-Speicher nur den Datensatz mit der letzten Eventzeit.
Im folgenden Beispieldiagramm enthält der ursprüngliche Online-Speicher eine ML-Datentabelle mit einem Datensatz. Ein Datensatz wird mit dem gleichen Datensatzkennungsnamen wie der ursprüngliche Datensatz erfasst und der erfasste Datensatz hat einen früheren Ereigniszeitpunkt als der ursprüngliche Datensatz. Da der aktualisierte Online-Speicher nur den Datensatz mit der letzten Ereigniszeit führt, enthält der aktualisierte Online-Speicher den ursprünglichen Datensatz.
Beispiel für die Aufnahme in den Offline-Speicher
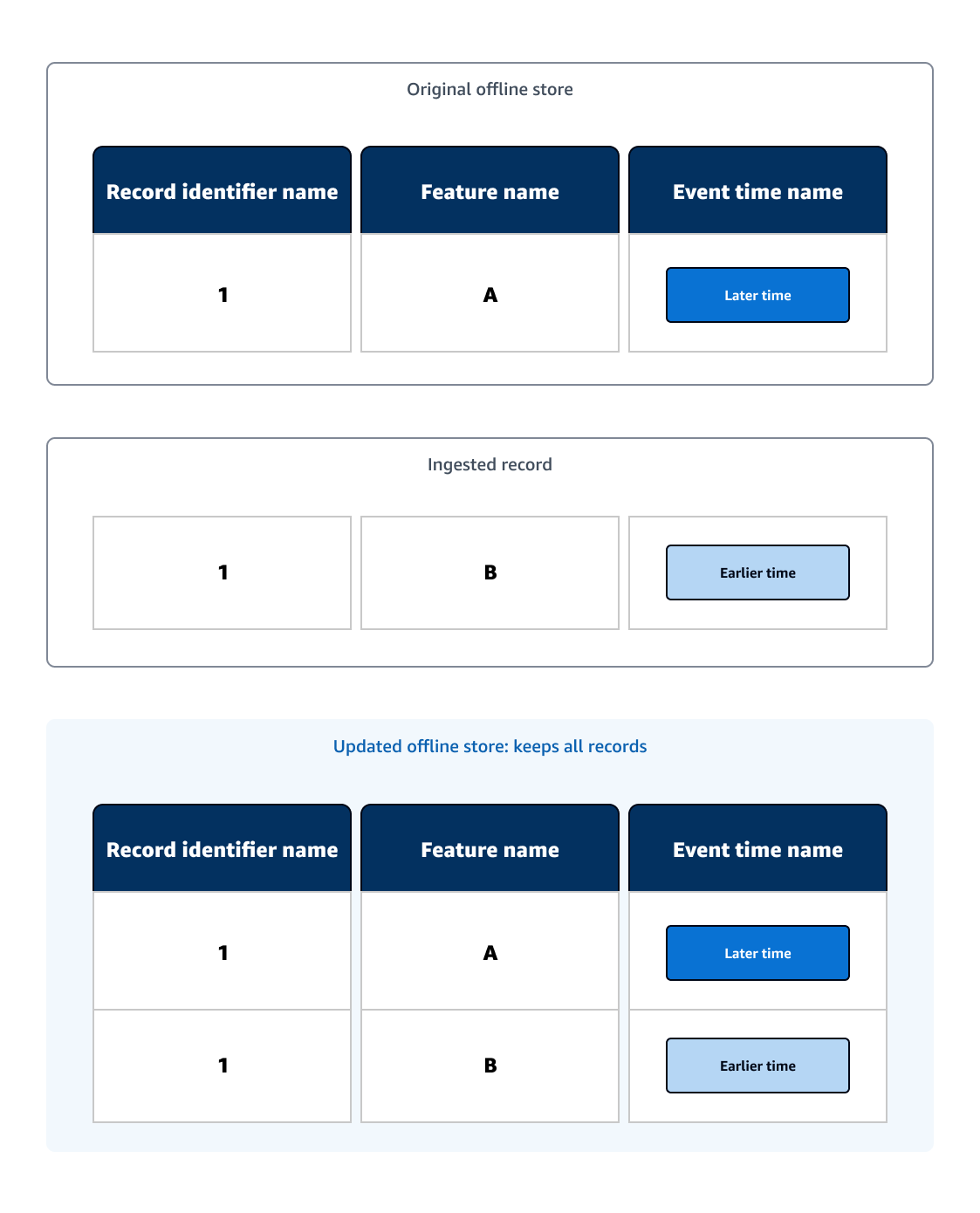
Der Offline-Speicher dient als historische Suche nach Datensätzen und speichert alle Datensätze. Nachdem ein neuer Datensatz in einen vorhandenen Offline-Speicher aufgenommen wurde, behält der aktualisierte Offline-Speicher den neuen Datensatz bei.
Im folgenden Beispieldiagramm enthält der ursprüngliche Offline-Speicher eine ML-Datentabelle mit einem Datensatz. Ein Datensatz wird mit dem gleichen Datensatzkennungsnamen wie der ursprüngliche Datensatz erfasst und der erfasste Datensatz hat einen früheren Ereigniszeitpunkt als der ursprüngliche Datensatz. Da der aktualisierte Offline-Store alle Datensätze enthält, enthält der aktualisierte Offline-Store beide Datensätze.