Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Wählen Sie einen Eingabemodus und eine Speichereinheit
Die beste Datenquelle für Ihren Trainingsauftrag hängt von Arbeitslastmerkmalen wie der Größe des Datensatzes, dem Dateiformat, der durchschnittlichen Dateigröße, der Trainingsdauer, einem sequentiellen oder zufälligen Lesemuster des Datenladers und der Geschwindigkeit ab, mit der Ihr Modell die Trainingsdaten verarbeiten kann. Die folgenden bewährten Methoden bieten Richtlinien für den Einstieg in den für Ihren Anwendungsfall am besten geeigneten Eingabemodus und Datenspeicherdienst.
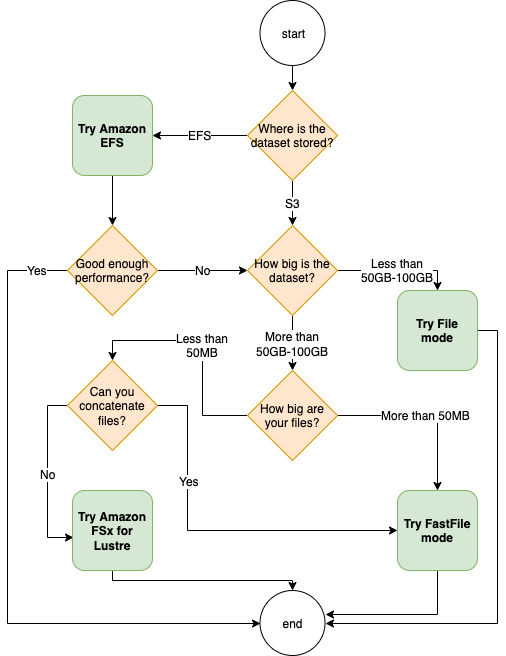
Wann sollte man Amazon verwenden EFS
Wenn Ihr Datensatz in Amazon Elastic File System gespeichert ist, verfügen Sie möglicherweise über eine Vorverarbeitungs- oder Annotationsanwendung, die Amazon EFS zur Speicherung verwendet. Sie können einen Trainingsjob ausführen, der mit einem Datenkanal konfiguriert ist, der auf das EFS Amazon-Dateisystem verweist. Weitere Informationen finden Sie unter Beschleunigen Sie das Training auf Amazon SageMaker mithilfe von Amazon FSx for Lustre und EFS Amazon-Dateisystemen
Verwenden Sie den Dateimodus für kleine Datensätze
Wenn der Datensatz in Amazon Simple Storage Service gespeichert ist und sein Gesamtvolumen relativ klein ist (z. B. weniger als 50-100 GB), sollten Sie den Dateimodus verwenden. Der Aufwand für das Herunterladen eines 50-GB-Datensatzes kann je nach Gesamtzahl der Dateien variieren. Beispielsweise dauert es etwa 5 Minuten, wenn ein Datensatz in 100-MB-Shards aufgeteilt wird. Ob dieser Startaufwand akzeptabel ist, hängt in erster Linie von der Gesamtdauer Ihres Trainingsauftrags ab, denn eine längere Trainingsphase bedeutet eine verhältnismäßig kleinere Downloadphase.
Serialisierung vieler kleiner Dateien
Wenn Ihr Datensatz klein ist (weniger als 50-100 GB), aber aus vielen kleinen Dateien besteht (weniger als 50 MB pro Datei), steigt der Download-Overhead im Dateimodus, da jede Datei einzeln vom Amazon Simple Storage Service auf das Volume der Trainings-Instance heruntergeladen werden muss. Um diesen Overhead und die Datendurchlaufzeit im Allgemeinen zu reduzieren, sollten Sie erwägen, Gruppen solcher kleiner Dateien in weniger größere Dateicontainer (z. B. 150 MB pro Datei) zu serialisieren, indem Sie Dateiformate wie TFRecord
Wann sollte der schnelle Dateimodus verwendet werden
Bei größeren Datensätzen mit größeren Dateien (mehr als 50 MB pro Datei) besteht die erste Option darin, den schnellen Dateimodus auszuprobieren, der einfacher zu verwenden ist als FSx für Lustre, da kein Dateisystem erstellt oder eine Verbindung zu einem hergestellt werden mussVPC. Der schnelle Dateimodus ist ideal für große Dateicontainer (mehr als 150 MB) und eignet sich möglicherweise auch für Dateien mit mehr als 50 MB. Da der schnelle Dateimodus eine POSIX Schnittstelle bietet, unterstützt er zufällige Lesevorgänge (Lesen von nicht sequentiellen Bytebereichen). Dies ist jedoch nicht der ideale Anwendungsfall, und der Durchsatz ist möglicherweise geringer als bei sequenziellen Lesevorgängen. Wenn Sie jedoch ein relativ großes und rechenintensives ML-Modell haben, kann der schnelle Dateimodus die effektive Bandbreite der Trainingspipeline sättigen und nicht zu einem IO-Engpass führen. Sie müssen experimentieren und sehen. Um vom Dateimodus in den schnellen Dateimodus (und zurück) zu wechseln, fügen Sie einfach den input_mode='FastFile' Parameter hinzu (oder entfernen) Sie ihn, während Sie Ihren Eingabekanal mit SageMaker Python definierenSDK:
sagemaker.inputs.TrainingInput(S3_INPUT_FOLDER, input_mode = 'FastFile')
Wann sollten Sie Amazon FSx for Lustre verwenden
Wenn Ihr Datensatz für den Dateimodus zu groß ist, viele kleine Dateien enthält, die Sie nicht einfach serialisieren können, oder ein zufälliges Lesezugriffsmuster verwendet, ist Lustre eine gute Option, FSx die Sie in Betracht ziehen sollten. Das Dateisystem lässt sich auf einen Durchsatz von Hunderten von Gigabyte pro Sekunde (GB/s) und Millionen von Gigabytes pro Sekunde (GB/s) skalieren. Das ist idealIOPS, wenn Sie viele kleine Dateien haben. Beachten Sie jedoch, dass das Kaltstartproblem möglicherweise auf verzögertes Laden und den Aufwand beim Einrichten und Initialisieren des FSx for Lustre-Dateisystems zurückzuführen ist.
Tipp
Weitere Informationen finden Sie unter Wählen Sie die beste Datenquelle für Ihren SageMaker Amazon-Schulungsjob
