Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Parallelität fragmentierter Daten
Sharded Data Parallelism ist eine speichersparende verteilte Trainingstechnik, die den Status eines Modells (Modellparameter, Gradienten und Optimiererzustände) in einer datenparallelen Gruppe aufteilt. GPUs
Anmerkung
Sharded Data Parallelism ist in der Modellparallelismus-Bibliothek v1.11.0 und höher verfügbar. PyTorch SageMaker
Wenn Sie Ihren Trainingsjob auf einen großen GPU-Cluster skalieren, können Sie den Speicherbedarf des Modells pro GPU reduzieren, indem Sie den Trainingsstatus des Modells auf mehrere verteilen. GPUs Dies hat zwei Vorteile: Sie können größere Modelle einsetzen, denen sonst bei standardmäßiger Datenparallelität der Speicher ausgehen würde, oder Sie können mithilfe des freigewordenen GPU-Speichers die Batch-Größe erhöhen.
Die Standardtechnik für Datenparallelität repliziert die Trainingszustände GPUs in der Gruppe der Datenparallelen und führt auf der Grundlage der Operation eine Gradientenaggregation durch. AllReduce Die Parallelität fragmentierter Daten modifiziert das Standard-Trainingsverfahren mit verteilten, parallelen Daten, um der fragmentierten Natur der Optimierer-Zustände Rechnung zu tragen. Eine Gruppe von Rängen, über die die Zustände des Modells und des Optimierers fragmentiert werden, wird als Fragmentierungsgruppe bezeichnet. Bei der Technik der Datenparallelität werden die trainierbaren Parameter eines Modells und die entsprechenden Gradienten und Optimierungszustände in der Sharding-Gruppe aufgeteilt. GPUs
SageMaker KI erreicht Sharded Data Parallelität durch die Implementierung von MICs, was im Blogbeitrag Near-linear scaling of gigantic-model training on behandelt wird. AWSAWSAllGather Nach dem Vorwärts- oder Rückwärtsdurchlauf jeder Layer fragmentiert MICs die Parameter erneut, um GPU-Speicher zu sparen. Während des Rückwärtsdurchlaufs reduziert MICs die Gradienten und verteilt sie gleichzeitig während des gesamten Vorgangs. GPUs ReduceScatter Schließlich wendet MICs die lokalen reduzierten und fragmentierten Steigungen auf die entsprechenden lokalen Parameter-Fragmente an und verwendet dabei die lokalen Fragmente der Optimierer-Zustände. Um den Kommunikationsaufwand zu verringern, ruft die SageMaker Modellparallelitätsbibliothek die nächsten Schichten im Vorwärts- oder Rückwärtsgang vorab ab und überlagert die Netzwerkkommunikation mit der Berechnung.
Der Trainingszustand des Modells wird über alle Fragmentierungsgruppen repliziert. Das heißt, bevor auf die Parameter Steigungen angewendet werden, muss zusätzlich zu der ReduceScatter Operation, die innerhalb der Fragmentierungsgruppe stattfindet, in allen Fragmentierungsgruppen die AllReduce Operation erfolgen.
Tatsächlich führt die Parallelität fragmentierter Daten zu einem Kompromiss zwischen dem Kommunikationsaufwand und der GPU-Speichereffizienz. Die Verwendung paralleler fragmentierter Daten erhöht zwar die Kommunikationskosten, der Speicherbedarf je GPU (ohne die Speichernutzung aufgrund von Aktivierungen) wird aber durch den Grad der Parallelität der fragmentierten Daten fragmentiert, so dass größere Modelle in den GPU-Cluster passen.
Wahl des Parallelitätsgrades fragmentierter Daten
Wenn Sie einen Wert für den Daten-Parallelitätsgrad der fragmentierten Daten wählen, muss dieser Wert den Daten-Parallelitätsgrad gleichmäßig verteilen. Wählen Sie z. B. für einen Auftrag mit 8-Wege-Datenparallelität 2, 4 oder 8 als Parallelitätsgrad für die fragmentierten Daten aus. Wir empfehlen, bei der Auswahl des Parallelitätsgrades für die fragmentierten Daten mit einer kleinen Zahl zu beginnen und diese schrittweise zu erhöhen, bis das Modell zusammen mit der gewünschten Batch-Größe in den Speicher passt.
Wahl der Batch-Größe
Achten Sie nach der Einrichtung der Parallelität der fragmentierten Daten darauf, dass Sie die optimale Trainingskonfiguration finden, die auf dem GPU-Cluster erfolgreich laufen kann. Um Large Language Models (LLM) zu trainieren, beginnen Sie mit der Batchgröße 1 und erhöhen Sie diese schrittweise, bis Sie den Punkt erreichen, an dem der Fehler (OOM) angezeigt wird. out-of-memory Wenn der OOM-Fehler auch bei der kleinsten Batch-Größe auftritt, wenden Sie einen höheren Parallelitätsgrad der fragmentierten Daten oder eine Kombination aus der Parallelität der fragmentierten Daten und Tensor-Parallelität an.
Themen
So können Sie die Parallelität fragmentierter Daten auf Ihren Trainingsauftrag anwenden
Um mit Sharded Data Parallelism zu beginnen, nehmen Sie die erforderlichen Änderungen an Ihrem Trainingsskript vor und richten Sie den SageMaker PyTorch Schätzer mit den Parametern ein. sharded-data-parallelism-specific Erwägen Sie auch, Referenzwerte und Beispiel-Notebooks als Ausgangspunkt zu verwenden.
Passen Sie Ihr Trainingsskript an PyTorch
Folgen Sie den Anweisungen unter Schritt 1: Ein PyTorch Trainingsskript ändern, um die Modell- und Optimizer-Objekte mit den smdistributed.modelparallel.torch Wrappern der torch.nn.parallel Module und zu verbinden. torch.distributed
(Optional) Zusätzliche Änderung zur Registrierung externer Modellparameter
Wenn Ihr Modell mit torch.nn.Module erstellt wurde und Parameter verwendet, die innerhalb der Modulklasse nicht definiert sind, sollten Sie sie manuell im Modul registrieren, damit SMP die vollständigen Parameter erfassen kann, während . Verwenden Sie smp.register_parameter(module,
parameter), um Parameter für ein Modul zu registrieren.
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
Richten Sie den Schätzer ein SageMaker PyTorch
Fügen Sie bei der Konfiguration eines SageMaker PyTorch Schätzers die Parameter für die Parallelität von Sharded Data hinzu. Schritt 2: Starten Sie einen Trainingsjob mit dem SageMaker Python-SDK
Um die Sharded-Datenparallelität zu aktivieren, fügen Sie den Parameter zum Estimator hinzu. sharded_data_parallel_degree SageMaker PyTorch Dieser Parameter gibt die Zahl an, GPUs über die der Trainingsstatus aufgeteilt wird. Der Wert für sharded_data_parallel_degree muss eine Ganzzahl zwischen eins und dem Daten-Parallelitätsgrad sein und muss den Daten-Parallelitätsgrad gleichmäßig verteilen. Beachten Sie, dass die Bibliothek automatisch die Anzahl und GPUs somit den Grad der Datenparallelität erkennt. Für die Konfiguration der Parallelität der fragmentierten Daten stehen die folgenden zusätzlichen Parameter zur Verfügung.
-
"sdp_reduce_bucket_size"(int, Standard: 5e8) — Gibt die Größe von PyTorch DDP-Gradienten-Bucketsals Anzahl von Elementen mit dem Standard-Dtype an. -
"sdp_param_persistence_threshold"(int, Standard: 1e6) – Gibt die Größe eines Parametertensors als Anzahl von Elementen an, die auf jeder GPU bestehen bleiben können. Sharded Data Parallelism teilt jeden Parametertensor auf eine Datenparallelgruppe auf GPUs . Wenn die Anzahl der Elemente im Parametertensor kleiner als dieser Schwellenwert ist, wird der Parametertensor nicht aufgeteilt. Dies trägt dazu bei, den Kommunikationsaufwand zu reduzieren, da der Parametertensor datenparallel repliziert wird. GPUs -
"sdp_max_live_parameters"(int, Standard: 1e9) – Gibt die maximale Anzahl von Parametern an, die sich während des Vorwärts- und Rückwärtsdurchlaufs gleichzeitig in einem neu kombinierten Trainingszustand befinden können. Das Abrufen von Parametern mit demAllGatherVorgang wird unterbrochen, wenn die Anzahl der aktiven Parameter den angegebenen Schwellenwert erreicht. Beachten Sie, dass eine Erhöhung dieses Parameters den Speicherbedarf erhöht. -
"sdp_hierarchical_allgather"(bool, Standard: True) – Wenn dieser aufTruegesetzt wird, wird derAllGatherVorgang hierarchisch ausgeführt: Er wird zuerst innerhalb jedes Knotens und dann knotenübergreifend ausgeführt. Bei verteilten Trainingsaufträgen mit mehreren Knoten wird die hierarchischeAllGatherOperation automatisch aktiviert. -
"sdp_gradient_clipping"(Gleitkomma, Standard: 1.0) – Gibt einen Schwellenwert für die Gradientenbeschneidung der L2-Norm der Steigungen an, bevor sie durch die Modellparameter rückwärts verteilt werden. Wenn die Parallelität fragmentierter Daten aktiviert ist, ist auch die Gradientenbeschneidung aktiviert. Der Standardschwellenwert ist1.0. Passen Sie diesen Parameter an, wenn das Problem mit explodierenden Steigungen auftritt.
Der folgende Code zeigt ein Beispiel für die Konfiguration der Parallelität fragmentierter Daten.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
Referenzkonfigurationen
Das SageMaker verteilte Schulungsteam stellt die folgenden Referenzkonfigurationen zur Verfügung, die Sie als Ausgangspunkt verwenden können. Sie können von den folgenden Konfigurationen extrapolieren, um zu experimentieren und die GPU-Speichernutzung für Ihre Modellkonfiguration abzuschätzen.
Parallelität fragmentierter Daten mit SMDDP-Kollektiven
| Modell/die Anzahl der Parameter | Num. Instances | Instance-Typ | Länge der Reihenfolge | Globale Batch-Größe | Mini-Batch-Größe | Parallelitätsgrad der fragmentierten Daten |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
Wenn Sie z. B. die Länge der Reihenfolge für ein Modell mit 20 Milliarden Parametern oder die Größe des Modells auf 65 Milliarden Parameter erhöhen, müssen Sie zunächst versuchen, die Batch-Größe zu reduzieren. Wenn das Modell dann immer noch nicht in die kleinste Batch-Größe (die Batch-Größe 1) passt, versuchen Sie, den Parallelitätsgrad des Modell zu erhöhen.
Parallelität fragmentierter Daten mit Tensor-Parallelität und NCCL-Kollektiven
| Modell/die Anzahl der Parameter | Num. Instances | Instance-Typ | Länge der Reihenfolge | Globale Batch-Größe | Mini-Batch-Größe | Parallelitätsgrad der fragmentierten Daten | Tensor-Parallelgrad | Aktivierung, Entladung |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | Y |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | Y |
Die kombinierte Verwendung von Datenparallelität und Tensorparallelität ist nützlich, wenn Sie ein großes Sprachmodell (LLM) in einen großen Cluster einpassen und gleichzeitig Textdaten mit einer längeren Sequenzlänge verwenden möchten, was zu einer geringeren Batchgröße führt, und folglich die GPU-Speicherauslastung für das Training mit längeren Textsequenzen bewältigen möchten. LLMs Weitere Informationen hierzu finden Sie unter Parallelität fragmentierter Daten mit Tensor-Parallelität.
Fallstudien, Benchmarks und weitere Konfigurationsbeispiele finden Sie im Blogbeitrag Neue Leistungsverbesserungen in der Amazon SageMaker AI-Modellparallelbibliothek
Parallelität fragmentierter Daten mit SMDDP-Kollektiven
Die SageMaker Datenparallelitätsbibliothek bietet kollektive Kommunikationsprimitive (SMDDP-Kollektive), die für die Infrastruktur optimiert sind. AWS Die Optimierung wird durch die Annahme eines all-to-all-type Kommunikationsmusters mithilfe des Elastic Fabric Adapter (EFA) erreicht, was zu einem
Anmerkung
Sharded Data Parallelism mit SMDDP Collectives ist in der SageMaker Modellparallelismus-Bibliothek v1.13.0 und höher sowie in der Datenparallelismus-Bibliothek v1.6.0 und höher verfügbar. SageMaker Weitere Informationen finden Sie unter So verwenden Sie Sharded Data Supported configurations Parallelism mit SMDDP Kollektive.
Bei der Parallelität fragmentierter Daten, einer häufig verwendeten Technik für groß angelegtes verteiltes Training, wird das AllGather Kollektiv verwendet, um die Sharded-Layer-Parameter für Vorwärts- und Rückwärtspassberechnungen parallel zur GPU-Berechnung zu rekonstruieren. Bei großen Modellen ist eine effiziente Ausführung des AllGather Vorgangs entscheidend, um GPU-Engpässe und eine Verlangsamung der Trainingsgeschwindigkeit zu vermeiden. Wenn die Parallelität fragmentierter Daten aktiviert ist, wird SMDDP Kollektive in diese leistungskritischen AllGather-Kollektive fragmentiert, wodurch der Trainingsdurchsatz verbessert wird.
Trainieren Sie mit SMDDP Kollektive
Wenn in Ihrem Trainingsauftrag die Parallelität fragmentierter Daten aktiviert ist und die Anfrageen erfüllt sindSupported configurations, werden SMDDP Kollektive automatisch aktiviert. Intern optimieren SMDDP Collectives das Kollektiv so, dass es in der Infrastruktur performant ist, und greifen für alle anderen AllGather Kollektive auf NCCL zurück. AWS Darüber hinaus verwenden bei nicht unterstützten Konfigurationen alle Kollektive, einschließlich AllGather, automatisch das NCCL-Backend.
Seit der Version SageMaker 1.13.0 der Modellparallelismus-Bibliothek wird der Parameter zu den Optionen hinzugefügt. "ddp_dist_backend" modelparallel Der Standardwert für diesen Konfigurationsparameter ist "auto". Wann immer möglich verwendet dieser SMDDP-Kollektive. Andernfalls wird auf NCCL zurückgegriffen. Um zu erzwingen, dass die Bibliothek immer NCCL verwendet, geben Sie "nccl" im "ddp_dist_backend" Konfigurationsparameter an.
Das folgende Codebeispiel zeigt, wie ein PyTorch Schätzer unter Verwendung der Sharded-Datenparallelität mit dem "ddp_dist_backend" Parameter eingerichtet wird, der "auto" standardmäßig auf gesetzt ist und daher optional hinzugefügt werden kann.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Unterstützte Konfigurationen
Der AllGather Vorgang mit SMDDP-Kollektiven wird in Trainingsaufträgen aktiviert, wenn alle der folgenden Konfigurationsanforderungen erfüllt sind.
-
Der Parallelitätsgrad fragmentierter Daten ist größer als 1
-
Instance_countgrößer als 1 -
Instance_typegleichml.p4d.24xlarge -
SageMaker Trainingscontainer für v1.12.1 oder höher PyTorch
-
Die SageMaker Datenparallelitätsbibliothek v1.6.0 oder höher
-
Die SageMaker Modellparallelismus-Bibliothek v1.13.0 oder höher
Leistungs- und Speicheroptimierung
SMDDP-Kollektive nutzen zusätzlichen GPU-Speicher. Es gibt zwei Umgebungsvariablen zur Konfiguration der GPU-Speichernutzung in Abhängigkeit von verschiedenen Anwendungsfällen für das Modelltraining.
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES– Während des SMDDPAllGather-Vorgangs wird derAllGatherEingabepuffer für die Kommunikation zwischen den Knoten in einen temporären Puffer kopiert. DieSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESVariable steuert die Größe dieses temporären Puffers (in Byte). Wenn die Größe des temporären Puffers kleiner ist als die Größe desAllGatherEingabepuffers, greift dasAllGatherKollektiv auf NCCL zurück.-
Standardwert: 16 * 1024 * 1024 (16 MB)
-
Zulässige Werte: alle Vielfachen von 8192
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTES– DieSMDDP_AG_SORT_BUFFER_SIZE_BYTESVariable dient zur Anpassung der Größe des temporären Puffers (in Byte) für Daten, die bei der Kommunikation zwischen Knoten gesammelt wurden. Wenn die Größe dieses temporären Puffers kleiner ist als1/8 * sharded_data_parallel_degree * AllGather input size, greift dasAllGatherKollektiv auf NCCL zurück.-
Standardwert: 128 * 1024 * 1024 (128 MB)
-
Zulässige Werte: alle Vielfachen von 8192
-
Optimierungsleitlinien zu den Variablen der Puffergröße
Die Standardwerte für die Umgebungsvariablen sollten für die meisten Anwendungsfälle gut funktionieren. Wir empfehlen, diese Variablen nur zu optimieren, wenn beim Training der Fehler out-of-memory (OOM) auftritt.
In der folgenden Liste werden Tipps für die Optimierung beschrieben, um den GPU-Speicherbedarf von SMDDP-Kollektiven zu reduzieren und dabei den daraus resultierenden Leistungsgewinn beizubehalten.
-
Optimierung von
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES-
Die Größe des
AllGatherEingabepuffers ist bei kleineren Modellen kleiner. Daher kann die erforderliche Größe fürSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESfür Modelle mit weniger Parametern geringer sein. -
Die Größe des
AllGatherEingabepuffers nimmt mitsharded_data_parallel_degreezunehmender Größe ab, da das Modell stärker GPUs fragmentiert wird. Daher kann die erforderliche Größe fürSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESbei Trainingsaufträgen mit großen Werten fürsharded_data_parallel_degreekleiner sein.
-
-
Optimierung von
SMDDP_AG_SORT_BUFFER_SIZE_BYTES-
Bei Modellen mit weniger Parametern ist die Datenmenge, die bei der Kommunikation zwischen den Knoten gesammelt wird, geringer. Daher kann die erforderliche Größe für
SMDDP_AG_SORT_BUFFER_SIZE_BYTESfür solche Modelle mit weniger Parametern geringer sein.
-
Manche Kollektive greifen ggf. auf NCCL zurück. Daher erzielen Sie durch die optimierten SMDDP-Kollektive ggf. nicht die erwartete Leistungssteigerung. Wenn zusätzlicher GPU-Speicher zur Verfügung steht, können Sie erwägen, die Werte von SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES und SMDDP_AG_SORT_BUFFER_SIZE_BYTES zu erhöhen, um von der Leistungssteigerung zu profitieren.
Der folgende Code zeigt, wie Sie die Umgebungsvariablen konfigurieren können, indem Sie sie an mpi_options den Verteilungsparameter für den PyTorch Schätzer anhängen.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Gemischtes Präzisionstraining mit Parallelität fragmentierter Daten
Um GPU-Speicher mit halbpräzisen Fließkommazahlen und Datenparallelität weiter zu sparen, können Sie das 16-Bit-Fließkommaformat (FP16) oder das Brain-Fließkommaformat
Anmerkung
Das Training mit gemischter Präzision und Sharded-Datenparallelität ist in der Modellparallelismus-Bibliothek v1.11.0 und höher verfügbar. SageMaker
Für FP16 das Training mit Sharded Data Parallelism
Um ein FP16 Training mit Sharded Data Parallelism durchzuführen, fügen Sie es dem Konfigurationswörterbuch hinzu. "fp16": True" smp_options In Ihrem Trainingsskript können Sie mit Hilfe des smp.DistributedOptimizer Moduls zwischen den statischen und dynamischen Verlustskalierungsoptionen wählen. Weitere Informationen finden Sie unter FP16 Training mit Modellparallelität.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
Für das BF16 Training mit Sharded Data Parallelism
Die SageMaker KI-Funktion zur Parallelität von Sharded Data unterstützt das Training nach Datentypen. BF16 Der BF16 Datentyp verwendet 8 Bit, um den Exponenten einer Fließkommazahl darzustellen, während der FP16 Datentyp 5 Bit verwendet. Wenn die 8 Bit für den Exponenten beibehalten werden, kann dieselbe Darstellung des Exponenten einer 32-Bit-Gleitkommazahl () FP32 mit einfacher Genauigkeit beibehalten werden. Dadurch wird die Konvertierung zwischen FP32 und BF16 einfacher und es ist deutlich weniger anfällig für Überlauf- und Unterlaufprobleme, die häufig beim Training auftreten, insbesondere beim FP16 Training größerer Modelle. Beide Datentypen verwenden zwar insgesamt 16 Bit, aber dieser vergrößerte Darstellungsbereich für den Exponenten im BF16 Format geht zu Lasten einer geringeren Genauigkeit. Beim Training großer Modelle wird diese geringere Genauigkeit oft als akzeptabler Kompromiss für den Bereich und die Stabilität des Trainings angesehen.
Anmerkung
Derzeit funktioniert das BF16 Training nur, wenn die Shard-Datenparallelität aktiviert ist.
Um ein BF16 Training mit Sharded-Datenparallelität durchzuführen, fügen Sie es dem Konfigurationswörterbuch hinzu. "bf16": True smp_options
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
Parallelität fragmentierter Daten mit Tensor-Parallelität
Wenn Sie die Parallelität fragmentierter Daten nutzen und außerdem die globale Batch-Größe reduzieren müssen, sollten Sie die Verwendung von Tensor-Parallelität mit der Parallelität fragmentierter Daten in Betracht ziehen. Wenn Sie ein großes Modell mit Parallelität fragmentierter Daten auf einem sehr großen Datenverarbeitungscluster (typischerweise 128 Knoten oder mehr) trainieren, führt selbst eine kleine Batch-Größe pro GPU zu einer sehr großen globalen Batch-Größe. Dies kann zu Konvergenzproblemen oder Problemen mit geringer Datenverarbeitungsleistung führen. Die Batch-Größe pro GPU kann manchmal mit der Parallelität fragmentierter Daten allein nicht reduziert werden, wenn ein einzelnes Batch bereits sehr umfangreich ist und nicht weiter reduziert werden kann. In solchen Fällen trägt die Verwendung der Parallelität fragmentierter Daten in Kombination mit Tensor-Parallelität dazu bei, die globale Batch-Größe zu reduzieren.
Die Wahl des optimalen Grades für die Parallelität fragmentierter Daten und die Tensor-Parallelität hängt von der Größe des Modells, dem Instance-Typ und von der globalen Batch-Größe ab, die angemessen ist, damit das Modell konvergieren kann. Wir empfehlen, dass Sie mit einem niedrigen Tensorparallelgrad beginnen, um die globale Batchgröße an den Rechencluster anzupassen, um out-of-memory CUDA-Fehler zu beheben und die beste Leistung zu erzielen. In den folgenden beiden Beispielfällen erfahren Sie, wie die Kombination aus Tensorparallelität und Sharded-Datenparallelität Ihnen hilft, die globale Batchgröße durch Gruppierung GPUs nach Modellparallelität anzupassen, was zu einer geringeren Anzahl von Modellreplikaten und einer kleineren globalen Batchgröße führt.
Anmerkung
Diese Funktion ist in der Modellparallelismus-Bibliothek v1.15 verfügbar und unterstützt Version 1.13.1. SageMaker PyTorch
Anmerkung
Diese Funktion steht für die durch die Tensor-Parallelitätsfunktionalität der Bibliothek unterstützten Modelle zur Verfügung. Eine Liste der unterstützten Modelle finden Sie unter Support für Hugging Face Transformator-Modelle. Beachten Sie auch, dass Sie bei der Änderung Ihres Trainingsskripts tensor_parallelism=True an das smp.model_creation Argument übergehen müssen. Weitere Informationen finden Sie im Trainingsskript train_gpt_simple.py
Beispiel 1
Nehmen wir an, wir möchten ein Modell über einen Cluster von 1536 GPUs (192 Knoten mit jeweils 8) trainieren und GPUs dabei den Grad der Sharded-Datenparallelität auf 32 (sharded_data_parallel_degree=32) und die Batchgröße pro GPU auf 1 setzen, wobei jeder Stapel eine Sequenzlänge von 4096 Token hat. In diesem Fall gibt es 1536 Modellrepliken, die globale Batch-Größe beträgt 1536 und jedes globale Batch enthält etwa 6 Millionen Token.
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
Durch Hinzufügen von Tensor-Parallelität kann die globale Batch-Größe verringert werden. Ein Konfigurationsbeispiel kann darin bestehen, den Grad der Tensor-Parallelität auf 8 und die Batch-Größe pro GPU auf 4 festzulegen. Dies bildet 192 parallel Tensorgruppen oder 192 Modellreplikate, wobei jedes Modellreplikat auf 8 verteilt ist. GPUs Die Batch-Größe von 4 ist die Menge an Trainingsdaten je Iteration und Tensorparallelgruppe, d. h. jede Modellreplik verbraucht 4 Batches pro Iteration. In diesem Fall beträgt die globale Batch-Größe 768, und jedes globale Batch enthält etwa 3 Millionen Token. Daher wird die globale Batch-Größe im Vergleich zum vorangehenden Fall um die Hälfte reduziert, wo nur die Parallelität fragmentierter Daten verwendet wurde.
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
Beispiel 2
Wenn sowohl die Parallelität fragmentierter Daten als auch die Tensor-Parallelität aktiviert sind, wendet die Bibliothek zunächst die Tensor-Parallelität an und fragmentiert das Modell über diese Dimension. Für jeden Tensorparallelrang wird die Datenparallelität gem. sharded_data_parallel_degree angewendet.
Nehmen wir zum Beispiel an, dass wir 32 GPUs mit einem Tensorparallelgrad von 4 setzen möchten (wobei Gruppen von 4 gebildet werden GPUs), einem parallel Grad für zerteilte Daten von 4, was zu einem Replikationsgrad von 2 führt. Durch die Zuweisung werden anhand des Grades der Tensor-Parallelität acht GPU-Gruppen wie folgt erstellt: (0,1,2,3), (4,5,6,7), (8,9,10,11), (12,13,14,15), (16,17,18,19), (20,21,22,23), (24,25,26,27), (28,29,30,31). Das heißt, vier GPUs bilden eine tensorparallele Gruppe. In diesem Fall wäre die reduzierte Datenparallelgruppe für den 0. Rang GPUs der tensorparallelen Gruppen. (0,4,8,12,16,20,24,28) Die reduzierte Datenparallelgruppe wird auf der Grundlage des Parallelgrads von 4 aufgeteilt, was zu zwei Replikationsgruppen für Datenparallelität führt. GPUs(0,4,8,12)bilden eine Sharding-Gruppe, die zusammen eine vollständige Kopie aller Parameter für den 0ten tensorparallelen Rang enthält, und GPUs (16,20,24,28) bilden eine weitere solche Gruppe. Auch andere Tensorparallelränge haben ähnliche Fragmentierungs- und Replikationsgruppen.
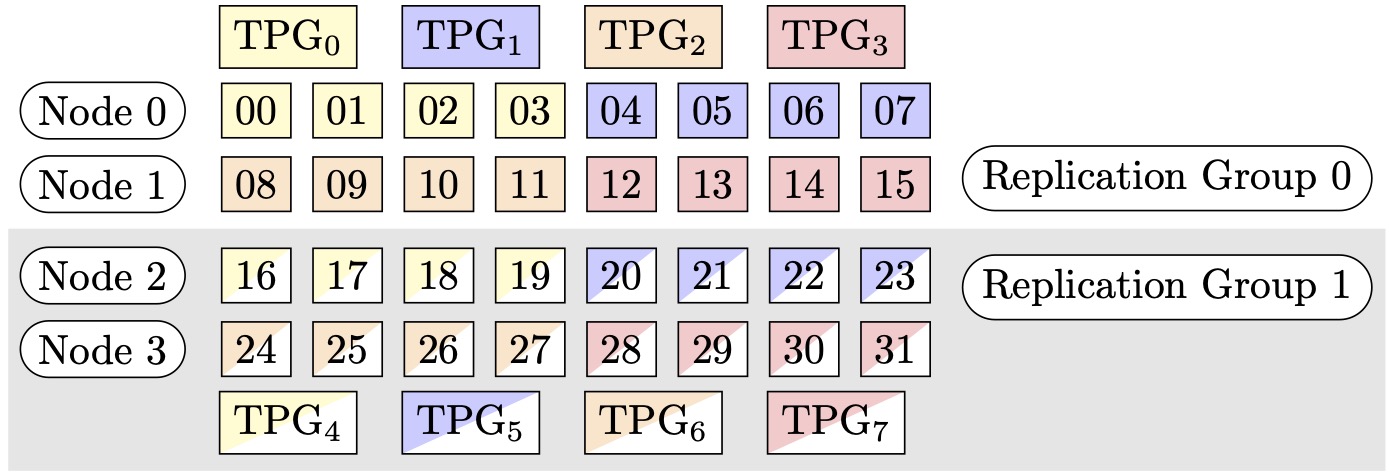
Abbildung 1: Tensorparallelitätsgruppen für (Knoten, parallel Grad der Sharded Data, Tensorparallelgrad) = (4, 4, 4), wobei jedes Rechteck eine GPU mit Indizes von 0 bis 31 darstellt. Sie GPUs bilden Tensorparallelitätsgruppen von TPG zu TPG. 0 7 Replikationsgruppen sind ({TPG0, TPG4}, {TPG, TPG}, {TPG1, TPG5} und {TPG2, TPG 67}); jedes Replikationsgruppenpaar hat dieselbe 3 Farbe, ist aber unterschiedlich gefüllt.
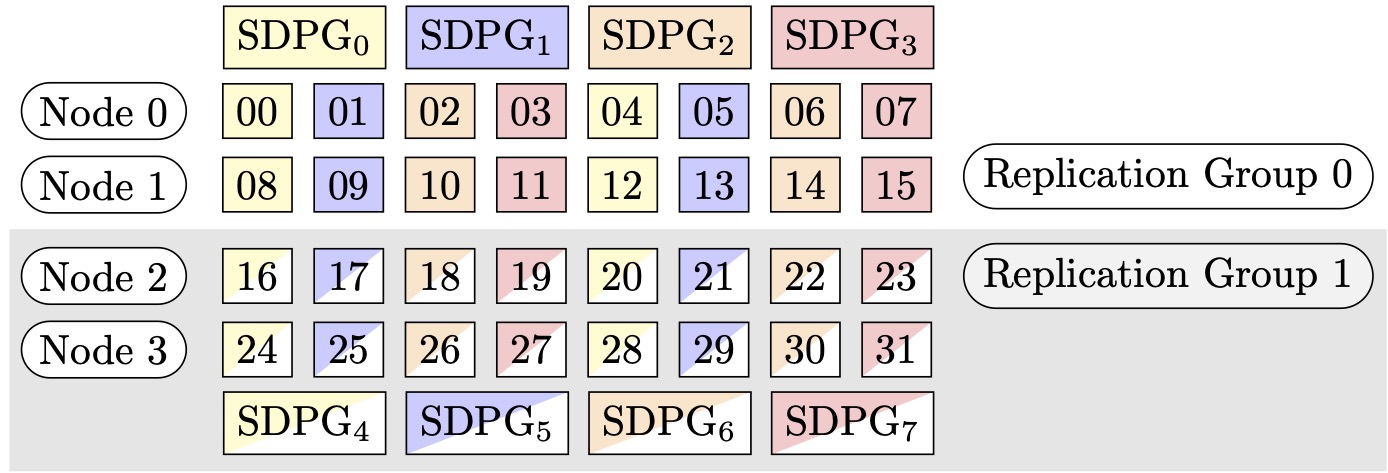
Abbildung 2: Sharded Data Parallelism Groups für (Nodes, Sharded Data Parallel Degree, Tensor Parallel Degree) = (4, 4, 4), wobei jedes Rechteck eine GPU mit Indizes von 0 bis 31 darstellt. Die GPUs Form Sharded Data Parallelism gruppiert von SDPG bis SDPG. 0 7 Replikationsgruppen sind ({SDPG0, SDPG4}, {SDPG, SDPG}1, {SDPG, SDPG5} und {SDPG2, SDPG 67}). Jedes Replikationsgruppenpaar hat 3 dieselbe Farbe, ist aber unterschiedlich gefüllt.
So aktivieren Sie die Parallelität fragmentierter Daten mit Tensor-Parallelität
Um Sharded-Datenparallelität mit Tensorparallelität zu verwenden, müssen Sie beide sharded_data_parallel_degree Werte und in der Konfiguration für festlegen, während Sie ein Objekt der Estimator-Klasse erstellen. tensor_parallel_degree distribution SageMaker PyTorch
Und Sie müssen auch prescaled_batch aktivieren. Das bedeutet, dass nicht jede GPU ihren eigenen Daten-Batch liest, sondern jede parallel Tensorparallelgruppe gemeinsam ein kombiniertes Batch der ausgewählten Batch-Größe liest. Anstatt den Datensatz in Teile zu unterteilen, die der Anzahl von GPUs (oder der parallel Datengrößesmp.dp_size()) entsprechen, wird er in Teile aufgeteilt, die der Anzahl von GPUs geteilt durch tensor_parallel_degree (auch als reduzierte Datenparallelgröße bezeichnetsmp.rdp_size()) entsprechen. Weitere Informationen zu Prescaled Batch finden Sie unter Prescaled Batchtrain_gpt_simple.py
Der folgende Codeausschnitt zeigt ein Beispiel für die Erstellung eines PyTorch Schätzobjekts auf der Grundlage des oben genannten Szenarios in. Beispiel 2
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
Tipps und Überlegungen zur Verwendung der Parallelität fragmentierter Daten
Beachten Sie Folgendes, wenn Sie die Sharded-Datenparallelität der SageMaker Modellparallelismus-Bibliothek verwenden.
-
Die Parallelität von Sharded Data ist mit Training kompatibel. FP16 Informationen zur Durchführung von FP16 Schulungen finden Sie im Abschnitt. FP16 Training mit Modellparallelität
-
Die Parallelität fragmentierter Daten ist mit der Tensor-Parallelität kompatibel. Sie müssen ggf. die folgenden Punkte berücksichtigen, wenn Sie die Parallelität fragmentierter Daten mit Tensor-Parallelität verwenden möchten.
-
Bei Verwendung der Parallelität fragmentierter Daten mit der Tensor-Parallelität werden auch die Einbettungs-Layers automatisch über die Tensorparallelgruppe verteilt. Mit anderen Worten, der
distribute_embeddingParameter wird automatisch aufTruegesetzt. Weitere Informationen zur Tensor-Parallelität finden Sie unter Tensor-Parallelität. -
Beachten Sie, dass die Parallelität fragmentierter Daten und die Tensor-Parallelität derzeit die NCCL-Kollektive als Backend der verteilten Trainingsstrategie verwendet.
Weitere Informationen finden Sie im Parallelität fragmentierter Daten mit Tensor-Parallelität Abschnitt.
-
-
Die Parallelität fragmentierter Daten ist derzeit nicht mit der Pipeline-Parallelität oder der Optimierer-Zustands-Fragmentierung kompatibel. Um die Parallelität fragmentierter Daten zu aktivieren, deaktivieren Sie die Optimierer-Zustands-Fragmentierung und setzen Sie den Grad der Pipeline-Parallelität auf 1.
-
Die Funktionen zur Aktivierung von Prüfpunkten und zum Entladen der Aktivierung sind mit der Parallelität fragmentierter Daten kompatibel.
-
Um die Parallelität fragmentierter Daten mit der Steigungsakkumulation zu verwenden, setzen Sie das
backward_passes_per_stepArgument auf die Anzahl der Akkumulationsschritte und wickeln Sie dabei Ihr Modell in dassmdistributed.modelparallel.torch.DistributedModelModul. Dadurch wird sichergestellt, dass die AllReduceSteigungsoperation zwischen den Modellreplikationsgruppen (Fragmentierungsgruppen) an der Grenze der Steigungsakkumulation stattfindet. -
Sie können Ihre mit Sharded Data Parallelism trainierten Modelle überprüfen, indem Sie die Checkpoint-Funktion der Bibliothek verwenden, und. APIs
smp.save_checkpointsmp.resume_from_checkpointWeitere Informationen finden Sie unter Checkpointing für ein verteiltes PyTorch Modell (für die SageMaker Modellparallelismus-Bibliothek v1.10.0 und höher). -
Das Verhalten des
delayed_parameter_initializationKonfigurationsparameters ändert sich bei Parallelität fragmentierter Daten. Wenn diese beiden Funktionen gleichzeitig aktiviert sind, werden die Parameter sofort nach der Modellerstellung fragmentiert initialisiert, anstatt die Parameterinitialisierung zu verzögern, damit jeder Rang seine eigenen fragmentierten Parameter initialisiert und speichert. -
Wenn die Parallelität fragmentierter Daten aktiviert ist, beschneidet die Bibliothek bei der Ausführung des
optimizer.step()Aufrufs intern die Steigungen. Sie müssen kein Hilfsprogramm APIs für Gradientenausschnitte verwenden, wie z.torch.nn.utils.clip_grad_norm_()Um den Schwellenwert für das Beschneiden von Farbverläufen anzupassen, können Sie ihn über den sdp_gradient_clippingParameter für die Konfiguration der Verteilungsparameter festlegen, wenn Sie den SageMaker PyTorch Schätzer erstellen, wie im Abschnitt gezeigt. So können Sie die Parallelität fragmentierter Daten auf Ihren Trainingsauftrag anwenden
