Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Zuordnung von Trainingsspeicherpfaden, die von Amazon SageMaker AI verwaltet werden
Diese Seite bietet eine allgemeine Zusammenfassung darüber, wie die SageMaker Schulungsplattform Speicherpfade für Trainingsdatensätze, Modellartefakte, Checkpoints und Ausgaben zwischen AWS Cloud-Speicher und Trainingsjobs in KI verwaltet. SageMaker In diesem Leitfaden erfahren Sie, wie Sie die von der SageMaker KI-Plattform festgelegten Standardpfade identifizieren und erfahren, wie die Datenkanäle mit Ihren Datenquellen in Amazon Simple Storage Service (Amazon S3), FSx for Lustre und Amazon EFS optimiert werden können. Weitere Informationen zu verschiedenen Datenkanal-Eingabemodi und Speicherungsoptionen finden Sie unter Einrichtung von Trainingsjobs für den Zugriff auf Datensätze.
Überblick darüber, wie SageMaker KI Speicherpfade abbildet
Das folgende Diagramm zeigt ein Beispiel dafür, wie SageMaker KI Eingabe- und Ausgabepfade zuordnet, wenn Sie einen Trainingsjob mit der SageMaker Python SDK Estimator-Klasse
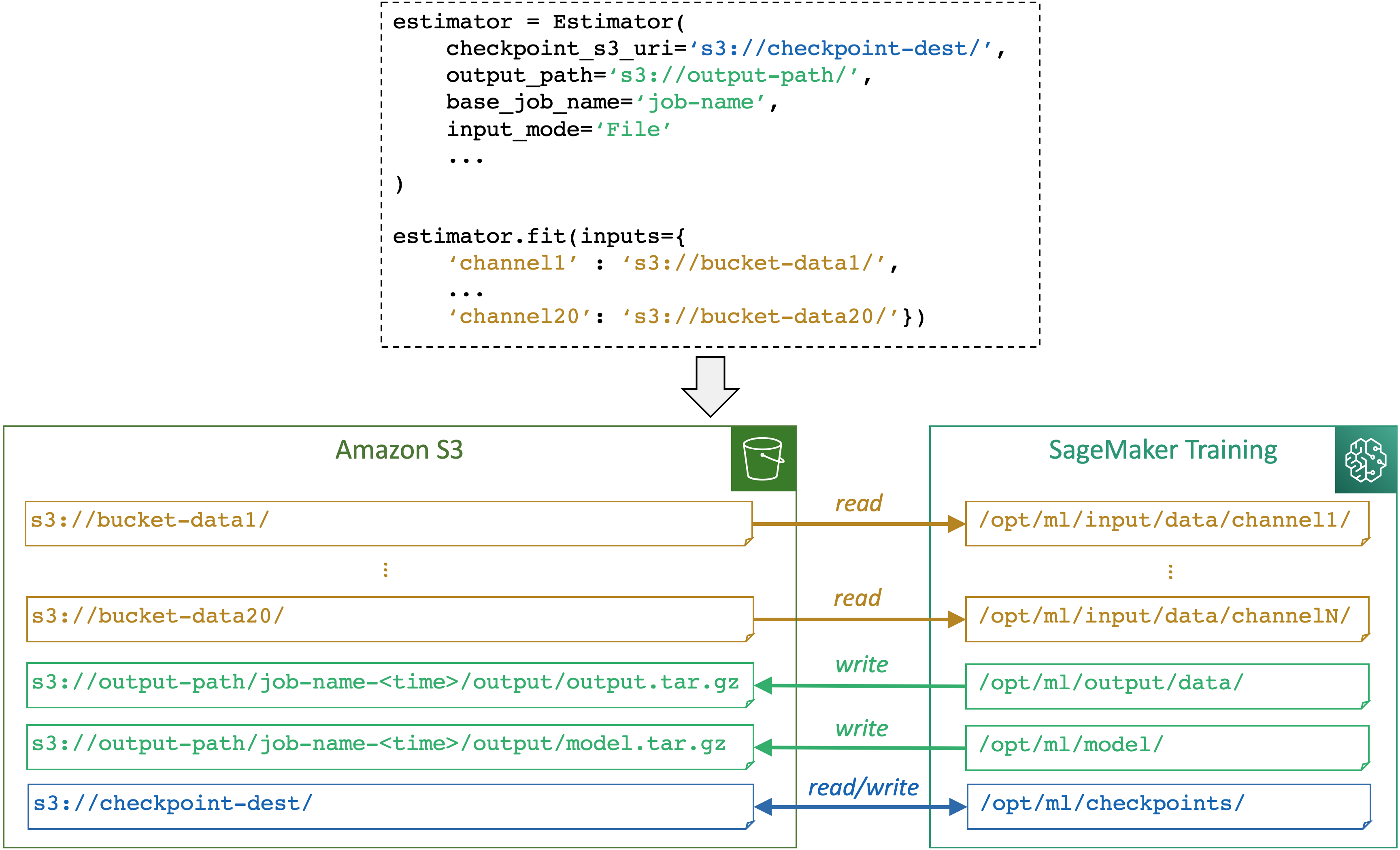
SageMaker KI ordnet Speicherpfade zwischen einem Speicher (wie Amazon S3, Amazon FSx und Amazon EFS) und dem SageMaker Trainingscontainer auf der Grundlage der Pfade und des Eingabemodus zu, die durch ein SageMaker AI-Estimator-Objekt angegeben wurden. Weitere Informationen darüber, wie SageMaker KI aus den Pfaden liest oder in sie schreibt und welchen Zweck die Pfade haben, finden Sie unter. SageMaker KI-Umgebungsvariablen und die Standardpfade für Trainingsspeicherorte
Sie können die CreateTrainingJobAPI verwenden, um die Ergebnisse des Modelltrainings OutputDataConfig in einem S3-Bucket zu speichern. Verwenden Sie die ModelArtifactsAPI, um den S3-Bucket zu finden, der Ihre Modellartefakte enthält. Ein Beispiel für Ausgabepfade und deren Verwendung in API-Aufrufen finden Sie im Notebook abalone_build_train_deploy
Weitere Informationen und Beispiele dafür, wie SageMaker KI die Datenquelle, Eingabemodi und lokale Pfade in SageMaker Trainingsinstanzen verwaltet, finden Sie unter Zugriff auf Trainingsdaten.
Themen
