Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
SageMaker Amazon-KI-Metriken bei Amazon CloudWatch
Sie können Amazon SageMaker AI mithilfe von Amazon überwachen. Amazon CloudWatch sammelt Rohdaten und verarbeitet sie zu lesbaren, nahezu in Echtzeit verfügbaren Metriken. Diese Statistiken werden für 15 Monate aufbewahrt. Sie können damit auf die Verlaufsdaten zugreifen und sich einen besseren Eindruck von der Leistung Ihrer Webanwendung oder Ihres Service verschaffen. Die CloudWatch Amazon-Konsole beschränkt die Suche jedoch auf Metriken, die in den letzten 2 Wochen aktualisiert wurden. Diese Einschränkung stellt sicher, dass die aktuellen Aufträge in Ihrem Namensraum aufgeführt werden.
Um Kennzahlen ohne Verwendung einer Suche grafisch darzustellen, geben Sie den exakten Namen in der Quellansicht ein. Sie können auch Alarme einrichten, die auf bestimmte Grenzwerte achten und Benachrichtigungen senden oder Aktivitäten auslösen, wenn diese Grenzwerte erreicht werden. Weitere Informationen finden Sie im CloudWatch Amazon-Benutzerhandbuch.
SageMaker KI-Metriken und -Dimensionen
SageMaker KI-Endpunktmetriken
Der /aws/sagemaker/Endpoints Namespace umfasst die folgenden Metriken für Endpunktinstanzen.
Die Kennzahlen sind mit einminütiger Frequenz verfügbar. Sie können die Veröffentlichungsfrequenz auf 10, 30, 60, 120, 180, 240 oder 300 Sekunden konfigurieren, indem Sie die Option MetricPublishFrequencyInSeconds in MetricsConfigeinstellen. Diese Einstellung EnableEnhancedMetrics muss nicht aktiviert sein. Wenn Sie EnableEnhancedMetrics auf einstellenTrue, sind die zusätzlichen Dimensionen InstanceId und AcceleratorId (nur GPU-Metriken) verfügbar. Weitere Informationen finden Sie unter Verbesserte Amazon SageMaker AI-Metriken für Inferenzendpunkte.
Anmerkung
Amazon CloudWatch unterstützt hochauflösende benutzerdefinierte Metriken und die beste Auflösung beträgt 1 Sekunde. Je feiner die Auflösung ist, desto kürzer ist jedoch die Lebensdauer der Messwerte. CloudWatch Für die Frequenzauflösung von 1 Sekunde sind die CloudWatch Metriken 3 Stunden lang verfügbar. Weitere Informationen zur Auflösung und Lebensdauer der CloudWatch Metriken finden Sie GetMetricStatisticsin der Amazon CloudWatch API-Referenz.
| Metrik | Description |
|---|---|
CPUReservation |
Die Summe der CPUs, die von Containern auf einer Instance reserviert wurden. Diese Metrik wird nur für Endpunkte bereitgestellt, die aktive Inferenzkomponenten hosten. Der Wert liegt zwischen 0 und 100 %. In den Einstellungen für eine Inferenzkomponente legen Sie die CPU-Reservierung mit dem |
CPUUtilization |
Die Summe der Auslastung jedes einzelnen CPU-Kerns. Die CPU-Auslastung jedes Kernbereichs liegt zwischen 0 und 100. Sind z. B. vier CPUs vorhanden, kann Bei Endpunktvarianten ist dieser Wert die Summe der CPU-Auslastung von primären und ergänzenden Containern auf der Instance. Einheiten: Prozent |
CPUUtilizationNormalized |
Die normalisierte Summe der Auslastung jedes einzelnen CPU-Kerns. Diese Metrik wird nur für Endpunkte bereitgestellt, die aktive Inferenzkomponenten hosten. Der Wert liegt zwischen 0 und 100 %. Wenn es beispielsweise vier CPUs gibt und der Wert für |
DiskUtilization |
Der Prozentsatz des Speicherplatzes, der von den Containern auf einer Instance verwendet wird. Dieser Wertebereich liegt zwischen 0 und 100%. Bei Endpunktvarianten ist dieser Wert die Summe der Speicherplatzauslastung der primären und ergänzenden Container auf der Instance.Einheiten: Prozent |
GPUMemoryUtilization |
Der Prozentsatz des GPU-Speichers, der von den Containern auf einer Instance belegt wird. Der Wert kann im Bereich zwischen 0 und 100 liegen und wird mit der Anzahl der GPUs multipliziert. Sind z. B. vier GPUs vorhanden, kann Bei Endpunktvarianten ist dieser Wert die Summe der GPU-Speichernutzung der primären und ergänzenden Container auf der Instance. Einheiten: Prozent |
GPUMemoryUtilizationNormalized |
Der normalisierte Prozentsatz des GPU-Speichers, der von den Containern auf einer Instance belegt wird. Diese Metrik wird nur für Endpunkte bereitgestellt, die aktive Inferenzkomponenten hosten. Der Wert liegt zwischen 0 und 100 %. Wenn es beispielsweise vier GPUs gibt und der Wert für |
GPUReservation |
Die Summe der GPUs, die von Containern auf einer Instance reserviert wurden. Diese Metrik wird nur für Endpunkte bereitgestellt, die aktive Inferenzkomponenten hosten. Der Wert liegt zwischen 0 und 100 %. In den Einstellungen für eine Inferenzkomponente legen Sie die GPU-Reservierung durch |
GPUUtilization |
Der Prozentsatz der GPU-Einheiten, die von den Containern auf einer Instance verwendet werden. Der Wert kann im Bereich zwischen 0 und 100 liegen und wird mit der Anzahl der GPUs multipliziert. Sind z. B. vier GPUs vorhanden, kann Bei Endpunktvarianten ist dieser Wert die Summe der GPU-Auslastung von primären und ergänzenden Containern auf der Instance. Einheiten: Prozent |
GPUUtilizationNormalized |
Der normalisierte Prozentsatz der GPU-Einheiten, die von den Containern auf einer Instance verwendet werden. Diese Metrik wird nur für Endpunkte bereitgestellt, die aktive Inferenzkomponenten hosten. Der Wert liegt zwischen 0 und 100 %. Wenn es beispielsweise vier GPUs gibt und der Wert für |
MemoryReservation |
Die Summe des Speichers, der von Containern auf einer Instance reserviert wurde. Diese Metrik wird nur für Endpunkte bereitgestellt, die aktive Inferenzkomponenten hosten. Der Wert liegt zwischen 0 und 100 %. In den Einstellungen für eine Inferenzkomponente legen Sie die Speicherreservierung mit dem |
MemoryUtilization |
Der Prozentsatz des Speichers, der von den Containern auf einer Instance belegt wird. Dieser Wertebereich liegt zwischen 0 und 100%. Bei Endpunktvarianten ist dieser Wert die Summe der Speichernutzung der primären und ergänzenden Container auf der Instance. Einheiten: Prozent |
| Dimension | Description |
|---|---|
EndpointName, VariantName |
Filtert Endpunktmetriken für einen |
EndpointName, VariantName, InstanceType |
Filtert Endpunktmetriken nach Instanztyp für eine Produktionsvariante, die Instanzpools verwendet. Verwenden Sie diese Dimension, um die Metriken für jeden Instance-Typ innerhalb der Variante separat zu überwachen. |
InstanceId |
Filtert Endpunktmetriken für eine bestimmte Instanz. Verfügbar, wenn auf |
AcceleratorId |
(Nur GPU-Metriken) Filtert Endpunktmetriken für eine bestimmte GPU. Verfügbar, wenn auf |
SageMaker Metriken zum Aufrufen von KI-Endpunkten
Der AWS/SageMaker-Namespace enthält die folgenden Anforderungsmetriken von InvokeEndpoint-Aufrufen.
Die Kennzahlen sind mit einminütiger Frequenz verfügbar. Sie können die Veröffentlichungshäufigkeit auf 10, 30, 60, 120, 180, 240 oder 300 Sekunden konfigurieren, indem Sie die Einstellung MetricPublishFrequencyInSeconds in MetricsConfigeinstellen. Für Aufrufmetriken muss diese Einstellung EnableEnhancedMetrics auf gesetzt seinTrue. Wenn Sie EnableEnhancedMetrics auf einstellenTrue, sind die zusätzlichen Dimensionen InstanceId und ContainerId (nur Inferenzkomponenten) ebenfalls verfügbar. Weitere Informationen finden Sie unter Verbesserte Amazon SageMaker AI-Metriken für Inferenzendpunkte.
Die folgende Abbildung zeigt, wie ein SageMaker KI-Endpunkt mit der Amazon SageMaker Runtime API interagiert. Die Gesamtzeit zwischen dem Absenden einer Anfrage an einen Endpunkt und dem Eingang einer Reaktion hängt von den folgenden drei Komponenten ab.
-
Netzwerklatenz — die Zeit, die zwischen dem Senden einer Anfrage an die Runtime Runtime API und dem Empfang einer Antwort von der SageMaker Runtime API vergeht.
-
Overhead-Latenz — die Zeit, die benötigt wird, um eine Anfrage von der SageMaker Runtime Runtime API an den Modellcontainer zu transportieren und die Antwort zurück zu transportieren.
-
Modelllatenz – die Zeit, die der Modell-Container braucht, um die Anfrage zu verarbeiten und eine Antwort zurückzugeben.
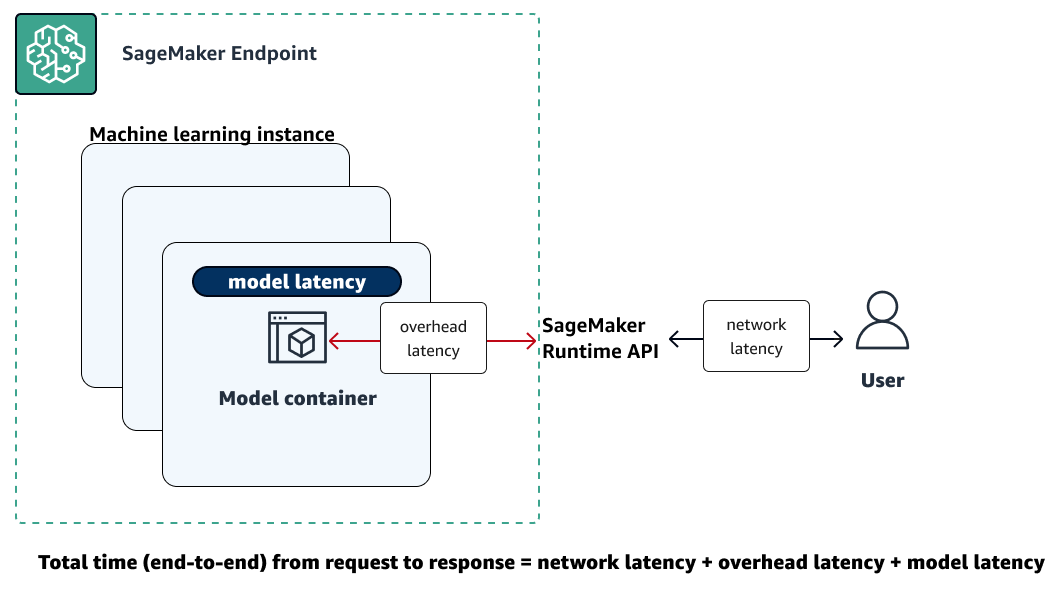
Weitere Informationen zur Gesamtlatenz finden Sie unter Bewährte Methoden für das Auslastungstesten von Amazon SageMaker AI-Inferenzendpunkten in Echtzeit
| Metrik | Description |
|---|---|
ConcurrentRequestsPerCopy |
Die Anzahl der gleichzeitigen Anforderungen, die von der Inferenzkomponente empfangen wurden, normalisiert durch jede Kopie einer Inferenzkomponente. Gültige Statistiken: Min, Max |
ConcurrentRequestsPerModel |
Die Anzahl der gleichzeitigen Anforderungen, die vom Modell empfangen wurden. Gültige Statistiken: Min, Max |
Invocation4XXErrors |
Die Anzahl der Einheiten: keine Gültige Statistiken: Durchschnitt, Summe |
Invocation5XXErrors |
Die Anzahl der Einheiten: keine Gültige Statistiken: Durchschnitt, Summe |
InvocationModelErrors |
Die Anzahl der Modellaufrufanforderungen, die nicht zu einer 2XX-HTTP-Antwort geführt haben. Dazu gehören 4XX/5XX Statuscodes, Socket-Fehler auf niedriger Ebene, falsch formatierte HTTP-Antworten und Timeouts für Anfragen. Für jede Antwort auf Fehler wird der Wert 1 gesendet, andernfalls 0. Einheiten: keine Gültige Statistiken: Durchschnitt, Summe |
Invocations |
Die Anzahl Mit der Summenstatistik (Sum) können Sie die Gesamtanzahl der an einen Modellendpunkt gesendeten Anforderungen abrufen. Einheiten: keine Gültige Statistiken: Summe |
InvocationsPerCopy |
die Anzahl der Aufrufe, normalisiert durch jede Kopie einer Inferenzkomponente Gültige Statistiken: Summe |
InvocationsPerInstance |
Die Anzahl der Aufrufe, die an ein Modell gesendet wurden, normalisiert durch Einheiten: keine Gültige Statistiken: Summe |
ModelLatency |
Das Zeitintervall, das ein Modell benötigt, um auf eine SageMaker Runtime-API-Anfrage zu antworten. Dieses Intervall enthält die Zeitspanne für die lokale Kommunikation zum Senden der Anfrage und zum Abrufen der Antwort vom Modell-Container. Es beinhaltet auch die benötigte Zeit, um die Inferenz im Container abzuschließen. Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Summe, Minimum, Maximum, Stichprobenzahl, Perzentile |
ModelSetupTime |
Die zum Starten neuer Ressourcen zur Datenverarbeitung für einen Serverless-Endpunkt erforderliche Zeit. Die Zeit kann je nach Modellgröße, Dauer zum Herunterladen des Modells und Startzeit des Containers variieren. Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenzahl, Perzentile |
OverheadLatency |
Das Zeitintervall, das zu der Zeit addiert wird, die SageMaker KI-Overheads für die Beantwortung einer Kundenanfrage benötigen. Dieses Intervall wird von der Zeit an gemessen, in der SageMaker KI die Anfrage empfängt, bis sie eine Antwort an den Client zurücksendet, abzüglich der Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenanzahl |
MidStreamErrors
|
Die Anzahl der Fehler, die beim Streaming von Antworten auftreten, nachdem die erste Antwort an den Kunden gesendet wurde. Einheiten: keine Gültige Statistiken: Durchschnitt, Summe |
FirstChunkLatency
|
Die Zeit, die vom Eintreffen der Anfrage am SageMaker KI-Endpunkt bis zum Versand des ersten Teils der Antwort an den Kunden verstrichen ist. Diese Metrik gilt für bidirektionale Streaming-Inferenzanfragen. Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Summe, Minimum, Maximum, Stichprobenzahl, Perzentile |
FirstChunkModelLatency
|
Die Zeit, die der Modellcontainer benötigt, um die Anfrage zu verarbeiten und den ersten Teil der Antwort zurückzugeben. Dies wird vom Senden der Anfrage an den Modellcontainer bis zum Empfang des ersten Bytes vom Modell gemessen. Diese Metrik gilt für bidirektionale Streaming-Inferenzanfragen. Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Summe, Minimum, Maximum, Stichprobenzahl, Perzentile |
FirstChunkOverheadLatency
|
Die Overhead-Latenz für den ersten Abschnitt, ohne die Verarbeitungszeit des Modells. Dies wird als Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Summe, Min., Max., Anzahl der Stichproben, Perzentil |
| Dimension | Description |
|---|---|
EndpointName, VariantName |
Filtert die Kennzahlen für den Endpunktaufruf einer |
EndpointName, VariantName, InstanceType |
Filtert Metriken für Endpunktaufrufe nach Instanztyp für eine Produktionsvariante, die Instanzpools verwendet. Verwenden Sie diese Dimension, um die Aufrufmuster für jeden Instanztyp innerhalb der Variante anzuzeigen. |
InferenceComponentName |
Filtert Metriken zum Aufrufen von Inferenzkomponenten. |
InstanceId |
Filtert Aufrufmetriken für eine bestimmte Instance. Verfügbar, wenn auf |
ContainerId |
(Nur Inferenzkomponenten) Filtert Aufrufmetriken für einen bestimmten Container. Verfügbar, wenn auf In gesetzt |
SageMaker Metriken für KI-Inferenzkomponenten
Der /aws/sagemaker/InferenceComponents Namespace umfasst die folgenden Metriken von Aufrufen an Endpunkte, InvokeEndpointdie Inferenzkomponenten hosten. Container-level Granularität ist EnableEnhancedMetrics=True in den Endpunktkonfigurationen erforderlich. MetricsConfig
Die Kennzahlen sind mit einminütiger Frequenz verfügbar. Sie können die Veröffentlichungshäufigkeit auf 10, 30, 60, 120, 180, 240 oder 300 Sekunden konfigurieren, indem Sie sie einstellenMetricPublishFrequencyInSeconds. MetricsConfig Diese Einstellung EnableEnhancedMetrics muss nicht aktiviert sein. Wenn Sie EnableEnhancedMetrics auf einstellenTrue, sind die zusätzlichen Dimensionen InstanceIdContainerId, und AcceleratorId (nur GPU-Metriken) verfügbar. Weitere Informationen finden Sie unter Verbesserte Amazon SageMaker AI-Metriken für Inferenzendpunkte.
| Metrik | Description |
|---|---|
CPUUtilizationNormalized |
Der Wert der |
GPUMemoryUtilizationNormalized |
Der Wert der |
GPUUtilizationNormalized |
Der Wert der |
MemoryUtilizationNormalized |
Der von jeder Kopie der Inferenzkomponente gemeldete |
| Dimension | Description |
|---|---|
InferenceComponentName |
Filtert Metriken für Inferenzkomponenten |
InferenceComponentName, InstanceType |
Filtert Metriken für Inferenzkomponenten nach Instanztyp. Verwenden Sie diese Dimension, wenn die Inferenzkomponente in einer Produktionsvariante mit Instanzpools bereitgestellt wird, um Metriken für jeden Instanztyp separat anzuzeigen. |
InstanceId |
Filtert Metriken von Inferenzkomponenten für eine bestimmte Instanz. Verfügbar, wenn auf |
ContainerId |
Filtert Metriken von Inferenzkomponenten für einen bestimmten Container. Verfügbar, wenn auf |
AcceleratorId |
(Nur GPU-Metriken) Filtert Metriken für Inferenzkomponenten für eine bestimmte GPU. Verfügbar, wenn die Einstellung auf |
SageMaker KI-Endpunktmetriken für mehrere Modelle
Der AWS/SageMaker Namespace umfasst das folgende Modell zum Laden von Metriken aus Aufrufen von. InvokeEndpoint
Die Kennzahlen sind mit einminütiger Frequenz verfügbar.
Informationen darüber, wie lange CloudWatch Metriken aufbewahrt werden, finden Sie GetMetricStatisticsin der Amazon CloudWatch API-Referenz.
| Metrik | Description |
|---|---|
ModelLoadingWaitTime |
Der Zeitraum, über den eine Aufrufanforderung darauf gewartet hat, dass das Zielmodell heruntergeladen oder geladen wird, oder beides, um Interferenzen auszuführen. Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenanzahl |
ModelUnloadingTime |
Der Zeitraum , das zum Entladen des Modells über den Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenanzahl |
ModelDownloadingTime |
Die Dauer, die es brauchte, das Modell von Amazon Simple Storage Service (Amazon S3) herunterzuladen. Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenanzahl |
ModelLoadingTime |
Der Zeitraum , das zum Laden des Modells über den Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenanzahl |
ModelCacheHit |
Die Anzahl der Die Durchschnittsstatistik zeigt das Verhältnis der Anforderungen an, für die das Modell bereits geladen wurde. Einheiten: keine Gültige Statistiken: Durchschnitt, Datenstichprobe |
| Dimension | Description |
|---|---|
EndpointName, VariantName |
Filtert die Kennzahlen für den Endpunktaufruf einer |
Die /aws/sagemaker/Endpoints-Namespaces enthalten die folgenden Instance-Metriken aus Aufrufen an InvokeEndpoint.
Die Kennzahlen sind mit einminütiger Frequenz verfügbar.
Informationen darüber, wie lange CloudWatch Metriken aufbewahrt werden, finden Sie GetMetricStatisticsin der Amazon CloudWatch API-Referenz.
| Metrik | Description |
|---|---|
LoadedModelCount |
Die Anzahl der Modelle, die in die Container des Multimodell-Endpunkts geladen werden. Diese Metrik wird pro Instance ausgegeben. Die Durchschnittsstatistik mit einem Zeitraum von 1 Minute gibt Ihnen die durchschnittliche Anzahl der pro Instance geladenen Modelle an. Die Summenstatistik gibt Ihnen die Gesamtzahl der Modelle an, die über alle Instances im Endpunkt geladen wurden. Die Modelle, die von dieser Metrik verfolgt werden, sind nicht unbedingt eindeutig, da ein Modell möglicherweise in mehrere Container am Endpunkt geladen wird. Einheiten: keine Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenanzahl |
| Dimension | Description |
|---|---|
EndpointName, VariantName |
Filtert die Kennzahlen für den Endpunktaufruf einer |
SageMaker KI-Jobmetriken
Die /aws/sagemaker/TransformJobs Namespaces /aws/sagemaker/ProcessingJobs/aws/sagemaker/TrainingJobs, und beinhalten die folgenden Metriken für die Verarbeitung von Jobs, Trainingsjobs und Batch-Transformationsjobs.
Die Kennzahlen sind mit einminütiger Frequenz verfügbar.
Anmerkung
Amazon CloudWatch unterstützt hochauflösende benutzerdefinierte Metriken und die beste Auflösung beträgt 1 Sekunde. Je feiner die Auflösung ist, desto kürzer ist jedoch die Lebensdauer der Messwerte. CloudWatch Für die Frequenzauflösung von 1 Sekunde sind die CloudWatch Metriken 3 Stunden lang verfügbar. Weitere Informationen zur Auflösung und Lebensdauer der CloudWatch Metriken finden Sie GetMetricStatisticsin der Amazon CloudWatch API-Referenz.
Tipp
Erwägen Sie die Verwendung von Amazon Debugger, um Ihr Trainingsjob mit einer feineren Auflösung von bis zu 100 Millisekunden (0,1 Sekunden) zu profilieren und die Trainingsmetriken unbegrenzt in Amazon S3 zu speichern, um jederzeit benutzerdefinierte Analysen durchführen zu können. SageMaker SageMaker Der Debugger bietet integrierte Regeln zur automatischen Erkennung häufiger Trainingsprobleme. Er erkennt Probleme mit der Nutzung von Hardwareressourcen (wie CPU, GPU und I/O Engpässe). Er erkennt auch Probleme mit nicht konvergierenden Modellen (wie Überanpassung, verschwindende Gradienten und explodierende Tensoren). SageMaker Der Debugger bietet auch Visualisierungen über Studio Classic und seinen Profilerstellungsbericht. Weitere Informationen zu den Debugger-Visualisierungen finden Sie unter Exemplarische Vorgehensweise zum SageMaker Debugger Insights-Dashboard, Exemplarische Vorgehensweise zum Debugger-Profilerstellungsbericht und Analysieren von Daten mithilfeder SMDebug-Clientbibliothek.
| Metrik | Description |
|---|---|
CPUUtilization |
Die Summe der Auslastung jedes einzelnen CPU-Kerns. Die CPU-Auslastung jedes Kernbereichs liegt zwischen 0 und 100. Sind z. B. vier CPUs vorhanden, kann CPUUtilization im Bereich zwischen 0% und 400% liegen. Bei der Verarbeitung von Aufträgen ist der Wert die CPU-Auslastung des Verarbeitungscontainers auf der Instance.Bei Trainingsaufträgen bildet dieser Wert die CPU-Auslastung des Algorithmus-Containers auf der Instance ab. Bei Stapeltransformationsaufträgen bildet dieser Wert die CPU-Auslastung des Umwandlungs-Containers auf der Instance ab. AnmerkungFür Multi-Instance-Jobs meldet jede Instance Kennzahlen zur CPU-Auslastung. In der Standardansicht in wird jedoch die durchschnittliche CPU-Auslastung aller Instanzen CloudWatch angezeigt. Einheiten: Prozent |
DiskUtilization |
Der Prozentsatz des Speicherplatzes, der von den Containern auf einer Instance verwendet wird. Dieser Wertebereich liegt zwischen 0% und 100%. Diese Metrik wird für Stapeltransformationsaufträge nicht unterstützt. Bei Verarbeitungsaufträgen ist der Wert die Festplattenspeichernutzung des Verarbeitungscontainers auf der Instance.Bei Trainingsaufträgen bildet dieser Wert die Speicherplatzauslastung des Algorithmus-Containers auf der Instance ab. Einheiten: Prozent AnmerkungFür Multi-Instance-Jobs meldet jede Instance Kennzahlen für die Festplattennutzung. In der Standardansicht in wird jedoch die durchschnittliche Festplattenauslastung aller Instanzen CloudWatch angezeigt. |
GPUMemoryUtilization |
Der Prozentsatz des GPU-Speichers, der von den Containern auf einer Instance belegt wird. Der Wert kann im Bereich zwischen 0 und 100 liegen und wird mit der Anzahl der GPUs multipliziert. Sind z. B. vier GPUs vorhanden, kann Bei Trainingsaufträgen bildet dieser Wert die GPU-Speichernutzung des Algorithmus-Containers auf der Instance ab. Bei Stapeltransformationsaufträgen bildet dieser Wert die GPU-Speicherauslastung des Umwandlungs-Containers auf der Instance ab. AnmerkungFür Multi-Instance-Jobs meldet jede Instance Kennzahlen zur GPU-Speicherauslastung. In der Standardansicht in wird jedoch die durchschnittliche GPU-Speicherauslastung aller Instanzen CloudWatch angezeigt. Einheiten: Prozent |
GPUUtilization |
Der Prozentsatz der GPU-Einheiten, die von den Containern auf einer Instance verwendet werden. Der Wert kann im Bereich zwischen 0 und 100 liegen und wird mit der Anzahl der GPUs multipliziert. Sind z. B. vier GPUs vorhanden, kann Bei Trainingsaufträgen bildet dieser Wert die GPU-Auslastung des Algorithmus-Containers auf der Instance ab. Bei Stapeltransformationsaufträgen bildet dieser Wert die GPU-Auslastung des Umwandlungs-Containers auf der Instance ab. AnmerkungFür Multi-Instance-Jobs meldet jede Instance Kennzahlen zur GPU-Auslastung. In der Standardansicht in wird jedoch die durchschnittliche GPU-Auslastung aller Instanzen CloudWatch angezeigt. Einheiten: Prozent |
MemoryUtilization |
Der Prozentsatz des Speichers, der von den Containern auf einer Instance belegt wird. Dieser Wertebereich liegt zwischen 0% und 100%. Bei der Verarbeitung von Aufträgen ist der Wert die Speichernutzung des Verarbeitungscontainers auf der Instance.Bei Trainingsaufträgen bildet dieser Wert die Speichernutzung des Algorithmus-Containers auf der Instance ab. Bei Stapeltransformationsaufträgen bildet dieser Wert die Speichernutzung des Umwandlungs-Containers auf der Instance ab. Einheiten: Prozent AnmerkungFür Multi-Instance-Jobs meldet jede Instance Kennzahlen zur Speicherauslastung. In der Standardansicht in wird jedoch die durchschnittliche Speicherauslastung aller Instanzen CloudWatch angezeigt. |
| Dimension | Description |
|---|---|
Host |
Bei Verarbeitungsaufträgen wird der Wert für diese Dimension im Format Bei Trainingsaufträgen wird der Wert für diese Dimension im Format Bei Stapeltransformationsaufträgen wird der Wert für diese Dimension im Format |
SageMaker Kennzahlen zu Stellenangeboten von Inference Recommender
Der /aws/sagemaker/InferenceRecommendationsJobs-Namensraum enthält die folgenden Kennzahlen für Inference-Empfehlungs-Jobs.
| Metrik | Description |
|---|---|
ClientInvocations |
Die vom Inference Recommender beobachtete Anzahl der an einen Modell-Endpunkt gesendeten Einheiten: keine Gültige Statistiken: Summe |
ClientInvocationErrors |
Die vom Inference Recommender beobachtete Anzahl der fehlgeschlagenen Einheiten: keine Gültige Statistiken: Summe |
ClientLatency |
Das vom Inference Recommender beobachtete Zeitintervall zwischen dem Absenden eines Einheiten: Millisekunden Gültige Statistiken: Durchschnitt, Summe, Minimum, Maximum, Stichprobenzahl, Perzentile |
NumberOfUsers |
Die Anzahl der gleichzeitigen Benutzer, die Einheiten: keine Gültige Statistiken: Maximum, Minimum, Durchschnitt |
| Dimension | Description |
|---|---|
JobName |
Filtert die Kennzahlen für den Inference-Recommender-Job für den angegebenen Inference-Recommender-Job. |
EndpointName |
Filtert die Kennzahlen für Inference-Recommender-Jobs für den angegebenen Endpunkt. |
SageMaker Ground Truth Truth-Metriken
| Metrik | Description |
|---|---|
ActiveWorkers |
Nur ein einziger aktiver Mitarbeiter in einem privaten Arbeitsteam hat eine Aufgabe eingereicht, freigegeben oder abgelehnt. Verwenden Sie die Summenstatistik, um die Gesamtzahl der aktiven Arbeiter zu erhalten. Ground Truth versucht, jedes einzelne Einheiten: keine Gültige Statistiken: Summe, Stichprobenanzahl |
DatasetObjectsAutoAnnotated |
Die Anzahl der Datensatz-Objekte, die in einem Etikettierungsauftrag automatisch mit Anmerkungen versehen werden. Diese Metrik wird nur ausgegeben, wenn die automatisierte Etikettierung aktiviert ist. Um den Fortschritt des Etikettierungsauftrags anzuzeigen, verwenden Sie die Max-Metrik. Einheiten: keine Gültige Statistiken: Max |
DatasetObjectsHumanAnnotated |
Die Anzahl der Datensatz-Objekte, die in einem Etikettierungsauftrag durch eine Person mit Anmerkungen versehen werden. Um den Fortschritt des Etikettierungsauftrags anzuzeigen, verwenden Sie die Max-Metrik. Einheiten: keine Gültige Statistiken: Max |
DatasetObjectsLabelingFailed |
Die Anzahl der Datensatz-Objekte, deren Etikettierung in einem Etikettierungsauftrag fehlgeschlagen ist. Um den Fortschritt des Etikettierungsauftrags anzuzeigen, verwenden Sie die Max-Metrik. Einheiten: keine Gültige Statistiken: Max |
JobsFailed |
Nur ein einziger Etikettierungsauftrag ist fehlgeschlagen. Um die Gesamtzahl der fehlgeschlagenen Etikettierungsaufträge zu erhalten, verwenden Sie die Summenstatistik. Einheiten: keine Gültige Statistiken: Summe, Stichprobenanzahl |
JobsSucceeded |
Nur ein einziger Etikettierungsauftrag war erfolgreich. Um die Gesamtzahl der erfolgreich durchgeführten Etikettierungsaufträge zu erhalten, verwenden Sie die Summenstatistik. Einheiten: keine Gültige Statistiken: Summe, Stichprobenanzahl |
JobsStopped |
Nut ein einziger Etikettierungsauftrag wurde gestoppt. Um die Gesamtzahl der angehaltenen Etikettierungsaufträge zu erhalten, verwenden Sie die Summenstatistik. Einheiten: keine Gültige Statistiken: Summe, Stichprobenanzahl |
TasksAccepted |
Von einem Mitarbeiter wurde eine einzige Aufgabe akzeptiert. Verwenden Sie die Summenstatistik, um die Gesamtzahl der von Mitarbeitern akzeptierten Aufgaben zu erhalten. Ground Truth versucht, jedes einzelne Einheiten: keine Gültige Statistiken: Summe, Stichprobenanzahl |
TasksDeclined |
Von einem Mitarbeiter wurde eine einzige Aufgabe abgelehnt. Verwenden Sie die Summenstatistik, um die Gesamtzahl der von Mitarbeitern abgelehnten Aufgaben zu erhalten. Ground Truth versucht, jedes einzelne Einheiten: keine Gültige Statistiken: Summe, Stichprobenanzahl |
TasksReturned |
Eine einzige Aufgabe wurde zurückgegeben. Verwenden Sie die Summenstatistik, um die Gesamtzahl der zurückgegebenen Aufgaben zu erhalten. Ground Truth versucht, jedes einzelne Einheiten: keine Gültige Statistiken: Summe, Stichprobenanzahl |
TasksSubmitted |
Eine einzelne Aufgabe wurde submitted/completed von einem Privatangestellten übernommen. Verwenden Sie die Summenstatistik, um die Gesamtzahl der von Mitarbeitern zurückgegebenen Aufgaben zu erhalten. Ground Truth versucht, jedes einzelne Einheiten: keine Gültige Statistiken: Summe, Stichprobenanzahl |
TimeSpent |
Die für eine Aufgabe aufgewendete Zeit, die von einem privaten Arbeiter abgeschlossen wurde. Diese Kennzahl beinhaltet nicht die Zeit, in der ein Mitarbeiter eine Pause einlegte. Ground Truth versucht, jedes Einheiten: Sekunden Gültige Statistiken: Summe, Stichprobenanzahl |
TotalDatasetObjectsLabeled |
Die Anzahl der Datensatz-Objekte, deren Etikettierung in einem Etikettierungsauftrag erfolgreich war. Um den Fortschritt des Etikettierungsauftrags anzuzeigen, verwenden Sie die Max-Metrik. Einheiten: keine Gültige Statistiken: Max |
| Dimension | Description |
|---|---|
LabelingJobName |
Filtert die Kennzahlen für die Datensatz-Objektanzahl eines Etikettierungsauftrags. |
Amazon SageMaker Feature Store-Metriken
| Metrik | Description |
|---|---|
ConsumedReadRequestsUnits |
Die Anzahl über den angegebenen Zeitraum verbrauchten Leseeinheiten. Sie können die verbrauchten Leseeinheiten für einen Laufzeitvorgang des Feature-Stores und die dazugehörige Feature-Gruppe abrufen. Einheiten: keine Gültige Statistiken: Alle |
ConsumedWriteRequestsUnits |
Die Anzahl der über den angegebenen Zeitraum verbrauchten Schreibeinheiten. Sie können die verbrauchten Schreibeinheiten für einen Laufzeitvorgang des Feature-Stores und die dazugehörige Feature-Gruppe abrufen. Einheiten: keine Gültige Statistiken: Alle |
ConsumedReadCapacityUnits |
Die Anzahl der bereitgestellten Lesekapazitätseinheiten, die über den angegebenen Zeitraum verbraucht wurden. Sie können die verbrauchten Lesekapazitätseinheiten für einen Laufzeitvorgang des Feature Store und die dazugehörige Feature-Gruppe abrufen. Einheiten: keine Gültige Statistiken: Alle |
ConsumedWriteCapacityUnits |
Die Anzahl der bereitgestellten Schreibkapazitätseinheiten, die über den angegebenen Zeitraum verbraucht wurden. Sie können die verbrauchten Schreibkapazitätseinheiten für einen Laufzeitvorgang des Feature Store und die dazugehörige Feature-Gruppe abrufen. Einheiten: keine Gültige Statistiken: Alle |
| Dimension | Description |
|---|---|
FeatureGroupName, OperationName |
Filtert Laufzeitverbrauchskennzahlen zum Feature-Store der Feature-Gruppe und des von Ihnen angegebenen Vorgangs. |
| Metrik | Description |
|---|---|
Invocations |
Die Anzahl der im angegebenen Zeitraum an den Feature-Store-Laufzeitbetrieb gestellten Anfragen. Einheiten: keine Gültige Statistiken: Summe |
Operation4XXErrors |
Die Anzahl der an den Feature-Store-Laufzeitbetrieb gestellten Anfragen, bei denen der Vorgang einen Antwortcode 4xx HTTP zurückgegeben hat. Für jede 4xx-Antwort wird der Wert 1 gesendet, andernfalls 0. Einheiten: keine Gültige Statistiken: Durchschnitt, Summe |
Operation5XXErrors |
Die Anzahl der an den Feature-Store-Laufzeitbetrieb gestellten Anfragen, bei denen der Vorgang einen Antwortcode 5xx HTTP zurückgegeben hat. Für jede 5xx-Antwort wird der Wert 1 gesendet, andernfalls 0. Einheiten: keine Gültige Statistiken: Durchschnitt, Summe |
ThrottledRequests |
Die Anzahl der an den Feature-Store-Laufzeitbetrieb gestellten Anfragen, bei denen die Anfrage gedrosselt wurde. Für jede gedrosselte Anfrage wird 1 gesendet, andernfalls 0. Einheiten: keine Gültige Statistiken: Durchschnitt, Summe |
Latency |
Der Zeitraum für die Verarbeitung von Anfragen an den Feature-Store-Laufzeitbetrieb. Dieses Intervall wird vom Empfang der Anfrage durch SageMaker KI bis zur Rückgabe einer Antwort an den Client gemessen. Einheiten: Mikrosekunden Gültige Statistiken: Durchschnitt, Summe, Minimum, Maximum, Stichprobenzahl, Perzentile |
| Dimension | Description |
|---|---|
|
|
Filtert die Betriebskennzahlen der Feature-Store-Laufzeit der Feature-Gruppe und des von Ihnen angegebenen Vorgangs. Sie können diese Dimensionen für Operationen verwenden, die keine Batch-Operationen sind GetRecord, wie PutRecord, und DeleteRecord. |
OperationName |
Filtert die Betriebskennzahlen der Feature-Store-Laufzeit für den von Ihnen angegebenen Vorgang. Sie können diese Dimension für Batch-Operationen wie verwenden BatchGetRecord. |
SageMaker Metriken für Pipelines
Der Namensraum AWS/Sagemaker/ModelBuildingPipeline enthält die folgenden Kennzahlen für die Ausführung von Pipelines.
Es sind zwei Kategorien von Metriken zur Pipeline-Ausführung verfügbar:
-
Ausführungskennzahlen für alle Pipelines – Kennzahlen zur Pipeline-Ausführung auf Kontoebene (für alle Pipelines im aktuellen Konto)
-
Ausführungskennzahlen nach Pipeline – Kennzahlen zur Pipeline-Ausführung je Pipeline
Die Kennzahlen sind mit einminütiger Frequenz verfügbar.
| Metrik | Description |
|---|---|
ExecutionStarted |
Die Anzahl der Pipeline-Ausführungen, die begonnen haben. Einheiten: Anzahl Gültige Statistiken: Durchschnitt, Summe |
ExecutionFailed |
Die Anzahl der Pipeline-Ausführungen, die fehlgeschlagen sind. Einheiten: Anzahl Gültige Statistiken: Durchschnitt, Summe |
ExecutionSucceeded |
Die Anzahl der Pipeline-Ausführungen, die erfolgreich waren. Einheiten: Anzahl Gültige Statistiken: Durchschnitt, Summe |
ExecutionStopped |
Die Anzahl der Pipeline-Ausführungen, die abgebrochen wurden. Einheiten: Anzahl Gültige Statistiken: Durchschnitt, Summe |
ExecutionDuration |
Die Dauer in Millisekunden, für die die Pipeline-Ausführung lief. Einheiten: Millisekunden Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenanzahl |
| Dimension | Description |
|---|---|
PipelineName |
Filtert Kennzahlen zur Pipeline-Ausführung für eine angegebene Pipeline. |
Der Namensraum AWS/Sagemaker/ModelBuildingPipeline enthält die folgenden Kennzahlen für Pipeline-Schritte.
Die Kennzahlen sind mit einminütiger Frequenz verfügbar.
| Metrik | Description |
|---|---|
StepStarted |
Die Anzahl der Schritte, die begonnen haben. Einheiten: Anzahl Gültige Statistiken: Durchschnitt, Summe |
StepFailed |
Die Anzahl der Schritte, die fehlgeschlagen sind. Einheiten: Anzahl Gültige Statistiken: Durchschnitt, Summe |
StepSucceeded |
Die Anzahl der Schritte, die erfolgreich waren. Einheiten: Anzahl Gültige Statistiken: Durchschnitt, Summe |
StepStopped |
Die Anzahl der Schritte, die abgebrochen wurden. Einheiten: Anzahl Gültige Statistiken: Durchschnitt, Summe |
StepDuration |
Die Dauer in Millisekunden, für die der Schritt lief. Einheiten: Millisekunden Gültige Statistiken: Durchschnitt, Minimum, Maximum, Stichprobenanzahl |
| Dimension | Description |
|---|---|
PipelineName, StepName |
Filtert Schrittkennzahlen für eine angegebene Pipeline und den jeweiligen Schritt. |
