Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Beginnen Sie mit den grundlegenden Lebenszyklusskripten von HyperPod
In diesem Abschnitt werden Sie von oben nach unten durch alle Komponenten des grundlegenden Ablaufs der Einrichtung von Slurm geführt. HyperPod Es beginnt mit der Vorbereitung einer Anfrage zur HyperPod Clustererstellung zur Ausführung des und taucht tief in die hierarchische Struktur ein CreateClusterAPI, bis hin zu Lebenszyklusskripten. Verwenden Sie die Beispiel-Lebenszyklusskripte, die im Awsome Distributed Training GitHub
git clone https://github.com/aws-samples/awsome-distributed-training/
Die grundlegenden Lebenszyklus-Skripte für die Einrichtung eines Slurm-Clusters SageMaker HyperPod finden Sie unter 1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
cd awsome-distributed-training/1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
Das folgende Flussdiagramm zeigt einen detaillierten Überblick darüber, wie Sie die grundlegenden Lebenszyklus-Skripte entwerfen sollten. In den Beschreibungen unter dem Diagramm und dem Verfahrensleitfaden wird erklärt, wie sie während des HyperPod CreateCluster API Anrufs funktionieren.
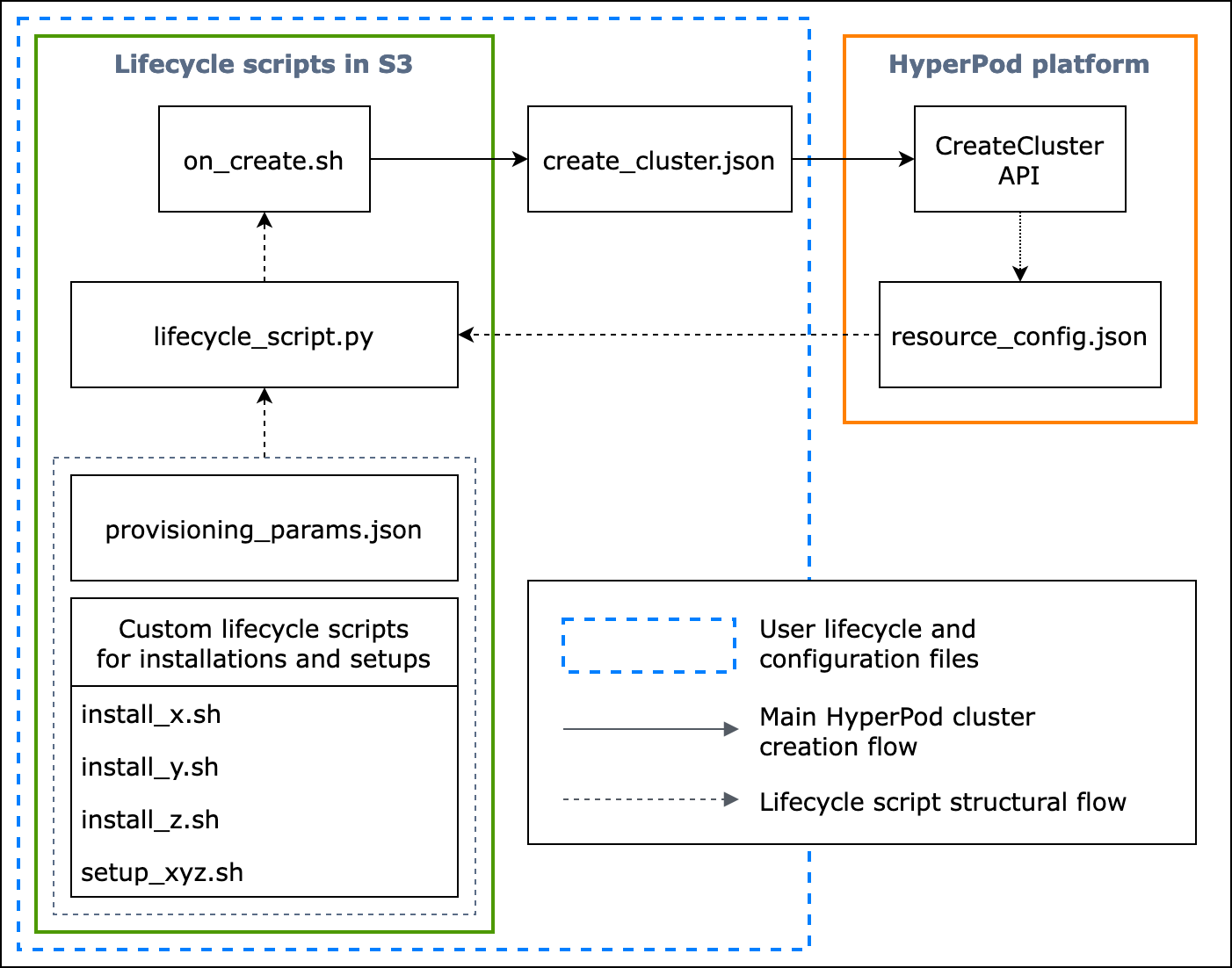
Abbildung: Ein detailliertes Flussdiagramm der HyperPod Clustererstellung und der Struktur von Lebenszyklusskripten. (1) Die gestrichelten Pfeile weisen darauf hin, wo die Boxen „aufgerufen“ werden, und zeigen den Ablauf der Vorbereitung von Konfigurationsdateien und Lebenszyklusskripten. Es beginnt mit der Vorbereitung provisioning_parameters.json und den Lebenszyklusskripten. Diese werden dann der Reihe lifecycle_script.py nach für eine gemeinsame Ausführung codiert. Und die Ausführung des lifecycle_script.py Skripts erfolgt durch das on_create.sh Shell-Skript, das im HyperPod Instanzterminal ausgeführt werden soll. (2) Die durchgezogenen Pfeile zeigen den Hauptablauf bei der HyperPod Clustererstellung und wie die Boxen „aufgerufen“ oder „eingereicht“ werden. on_create.shist für die Anfrage zur Clustererstellung erforderlich, entweder im Formular create_cluster.json oder im Formular Clusteranforderung erstellen in der Benutzeroberfläche der Konsole. Nachdem Sie die Anfrage eingereicht haben, HyperPod wird das auf der CreateCluster API Grundlage der angegebenen Konfigurationsinformationen aus der Anfrage und den Lebenszyklusskripten ausgeführt. (3) Der gepunktete Pfeil weist darauf hin, dass die HyperPod Plattform während der Bereitstellung von Clusterressourcen Instances resource_config.json in den Clustern erstellt. resource_config.jsonenthält HyperPod Clusterressourceninformationen wie den ClusterARN, Instanztypen und IP-Adressen. Es ist wichtig zu beachten, dass Sie die Lebenszyklusskripts so vorbereiten sollten, dass die resource_config.json Datei bei der Clustererstellung erwartet wird. Weitere Informationen finden Sie im nachfolgenden Verfahrensleitfaden.
In der folgenden Anleitung wird erklärt, was bei der HyperPod Clustererstellung passiert und wie die grundlegenden Lebenszyklusskripts entworfen werden.
-
create_cluster.json— Um eine Anfrage zur HyperPod Clustererstellung einzureichen, bereiten Sie eineCreateClusterAnforderungsdatei im JSON Format vor. In diesem Best-Practice-Beispiel gehen wir davon aus, dass die Anforderungsdatei benannt istcreate_cluster.json. Schreiben Siecreate_cluster.json, um einen HyperPod Cluster mit Instanzgruppen bereitzustellen. Es hat sich bewährt, die gleiche Anzahl von Instanzgruppen hinzuzufügen wie die Anzahl der Slurm-Knoten, die Sie auf dem HyperPod Cluster konfigurieren möchten. Stellen Sie sicher, dass Sie den Instanzgruppen, die Sie den Slurm-Knoten zuweisen, die Sie einrichten möchten, eindeutige Namen geben.Außerdem müssen Sie einen S3-Bucket-Pfad angeben, um Ihren gesamten Satz von Konfigurationsdateien und Lebenszyklusskripten unter dem Feldnamen
InstanceGroups.LifeCycleConfig.SourceS3UriimCreateClusterAnforderungsformular zu speichern, und den Dateinamen eines Einstiegspunkt-Shell-Skripts (davon ausgehen, dass es benannton_create.shist) angeben.InstanceGroups.LifeCycleConfig.OnCreateAnmerkung
Wenn Sie das Formular zum Erstellen eines Clusters in der Benutzeroberfläche der HyperPod Konsole verwenden, verwaltet die Konsole das Ausfüllen und Senden der
CreateClusterAnfrageCreateClusterAPI in Ihrem Namen und führt sie im Backend aus. In diesem Fall müssen Sie nichts erstellen. Stellen Siecreate_cluster.jsonstattdessen sicher, dass Sie die richtigen Informationen zur Clusterkonfiguration in das Formular „Cluster erstellen“ eingeben. -
on_create.sh— Für jede Instanzgruppe müssen Sie ein Einstiegs-Shell-Skript bereitstellen, um Befehle auszuführenon_create.sh, Skripte zur Installation von Softwarepaketen auszuführen und die HyperPod Clusterumgebung mit Slurm einzurichten. Die beiden Dinge, die Sie vorbereiten müssen, sind eine HyperPod für die Einrichtung von Slurmprovisioning_parameters.jsonerforderliche Version und eine Reihe von Lifecycle-Skripten für die Installation von Softwarepaketen. Dieses Skript sollte geschrieben werden, um die folgenden Dateien zu finden und auszuführen, wie im Beispielskript unteron_create.shgezeigt. Anmerkung
Stellen Sie sicher, dass Sie den gesamten Satz von Lifecycle-Skripten an den von Ihnen angegebenen S3-Speicherort hochladen
create_cluster.json. Sie sollten Ihre auchprovisioning_parameters.jsonam selben Ort platzieren.-
provisioning_parameters.json— Das ist einKonfigurationsformular für die Bereitstellung von Slurm-Knoten auf HyperPod. Dason_create.shSkript findet diese JSON Datei und definiert eine Umgebungsvariable zur Identifizierung des Pfads zu ihr. Über diese JSON Datei können Sie Slurm-Knoten und Speicheroptionen wie Amazon FSx for Lustre for Slurm für die Kommunikation konfigurieren. Stellen Sie sicherprovisioning_parameters.json, dass Sie die HyperPod Cluster-Instanzgruppen mit den Namen, die Sie angegeben haben, den Slurm-Knoten entsprechend zuweisen, je nachdem, wie Sie sie einrichten möchten.create_cluster.jsonDas folgende Diagramm zeigt ein Beispiel dafür, wie die beiden JSON Konfigurationsdateien
create_cluster.jsongeschrieben werdenprovisioning_parameters.jsonsollten, um den Slurm-Knoten HyperPod Instanzgruppen zuzuweisen. In diesem Beispiel gehen wir von der Einrichtung von drei Slurm-Knoten aus: Controller-Knoten (Verwaltungsknoten), Login-Knoten (optional) und Compute-Knoten (Worker-Knoten).Tipp
Um Ihnen bei der Validierung dieser beiden JSON Dateien zu helfen, stellt das HyperPod Serviceteam ein Validierungsskript zur Verfügung.
validate-config.pyWeitere Informationen hierzu finden Sie unter Überprüfen Sie die JSON Konfigurationsdateien, bevor Sie einen Slurm-Cluster erstellen auf HyperPod. 
Abbildung: Direkter Vergleich zwischen
create_cluster.jsonder HyperPod Clustererstellung undprovisiong_params.jsonder Slurm-Konfiguration. Die Anzahl der Instanzgruppen increate_cluster.jsonsollte der Anzahl der Knoten entsprechen, die Sie als Slurm-Knoten konfigurieren möchten. Im Fall des Beispiels in der Abbildung werden drei Slurm-Knoten auf einem HyperPod Cluster aus drei Instanzgruppen konfiguriert. Sie sollten die HyperPod Cluster-Instanzgruppen den Slurm-Knoten zuweisen, indem Sie die Namen der Instanzgruppen entsprechend angeben. -
resource_config.json— Während der Clustererstellung wird daslifecycle_script.pySkript so geschrieben, dass es eineresource_config.jsonDatei von HyperPod erwartet. Diese Datei enthält Informationen über den Cluster, z. B. Instance-Typen und IP-Adressen.Wenn Sie den ausführen
CreateClusterAPI, HyperPod erstellt eine Ressourcenkonfigurationsdatei unter, die auf dercreate_cluster.jsonDatei/opt/ml/config/resource_config.jsonbasiert. Der Dateipfad wird in der Umgebungsvariablen namens gespeichertSAGEMAKER_RESOURCE_CONFIG_PATH.Wichtig
Die
resource_config.jsonDatei wird automatisch von der HyperPod Plattform generiert, und Sie NOT müssen sie erstellen. Der folgende Code soll ein Beispiel dafür zeigen, wieresource_config.jsondas aus der Clustererstellung aufcreate_cluster.jsonder Grundlage des vorherigen Schritts erstellt wurde, und soll Ihnen helfen zu verstehen, was im Backend passiert und wie ein automatisch generierter Code aussehenresource_config.jsonwürde.{ "ClusterConfig": { "ClusterArn": "arn:aws:sagemaker:us-west-2:111122223333:cluster/abcde01234yz", "ClusterName": "your-hyperpod-cluster" }, "InstanceGroups": [ { "Name": "controller-machine", "InstanceType": "ml.c5.xlarge", "Instances": [ { "InstanceName": "controller-machine-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "login-group", "InstanceType": "ml.m5.xlarge", "Instances": [ { "InstanceName": "login-group-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "compute-nodes", "InstanceType": "ml.trn1.32xlarge", "Instances": [ { "InstanceName": "compute-nodes-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-2", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-3", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-4", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] } ] } -
lifecycle_script.py— Dies ist das wichtigste Python-Skript, das gemeinsam Lifecycle-Skripte ausführt, die Slurm auf dem HyperPod Cluster einrichten, während es bereitgestellt wird. Dieses Skript liest die Pfade einprovisioning_parameters.jsonundresource_config.jsonaus den Pfaden, die angegeben oder identifiziert sindon_create.sh, leitet die relevanten Informationen an jedes Lifecycle-Skript weiter und führt dann die Lifecycle-Skripte der Reihe nach aus.Lifecycle-Skripts sind eine Reihe von Skripten, die Sie völlig flexibel anpassen können, um Softwarepakete zu installieren und notwendige oder benutzerdefinierte Konfigurationen während der Clustererstellung einzurichten, z. B. Slurm einzurichten, Benutzer zu erstellen, Conda oder Docker zu installieren. Das
lifecycle_script.pyBeispielskript ist darauf vorbereitet, andere grundlegende Lebenszyklusskripte im Repository auszuführen, z. B. Slurm deamons ( start_slurm.sh) zu starten, Amazon FSx for Lustre ( mount_fsx.sh) zu mounten und MariaDB-Buchhaltung () und Buchhaltung ( setup_mariadb_accounting.sh) einzurichten. RDS setup_rds_accounting.shSie können auch weitere Skripte hinzufügen, sie in dasselbe Verzeichnis packen und Codezeilen hinzufügen, um die Skripte ausführen zu lifecycle_script.pylassen. HyperPod Weitere Informationen zu den grundlegenden Lebenszyklus-Skripten finden Sie auch unter 3.1 Lifecycle-Skriptenim Awsome Distributed Training GitHub Repository. Anmerkung
HyperPod läuft SageMaker HyperPod DLAMI auf jeder Instanz eines Clusters und AMI verfügt über vorinstallierte Softwarepakete, die die Kompatibilitäten zwischen diesen und deren Funktionalitäten gewährleisten. HyperPod Beachten Sie, dass Sie bei der Neuinstallation eines der vorinstallierten Pakete für die Installation kompatibler Pakete verantwortlich sind und dass einige HyperPod Funktionen möglicherweise nicht wie erwartet funktionieren.
Zusätzlich zu den Standard-Setups sind im Ordner weitere Skripts für die Installation der folgenden Software verfügbar.
utilsDie lifecycle_script.pyDatei ist bereits so vorbereitet, dass sie Codezeilen für die Ausführung der Installationsskripten enthält. Lesen Sie daher die folgenden Hinweise, um diese Zeilen zu durchsuchen und sie zu deaktivieren, um sie zu aktivieren.-
Die folgenden Codezeilen beziehen sich auf die Installation von Docker
, Enroot und Pyxis. Diese Pakete sind erforderlich, um Docker-Container auf einem Slurm-Cluster auszuführen. Um diesen Installationsschritt zu aktivieren, setzen Sie den
enable_docker_enroot_pyxisParameterTruein derconfig.pyDatei auf. # Install Docker/Enroot/Pyxis if Config.enable_docker_enroot_pyxis: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_enroot_pyxis.sh").run(node_type) -
Sie können Ihren HyperPod Cluster mit Amazon Managed Service for Prometheus und Amazon Managed Grafana integrieren, um Metriken über den HyperPod Cluster und die Clusterknoten in Amazon Managed Grafana-Dashboards zu exportieren. Um Metriken zu exportieren und das Slurm-Dashboard
, das NVIDIADCGMExporter-Dashboard und das EFAMetrics-Dashboard auf Amazon Managed Grafana zu verwenden, müssen Sie den Slurm-Exporter für Prometheus, den Exporter und den NVIDIA DCGM Node-Exporter installieren. EFA Weitere Informationen zur Installation der Exportpakete und zur Verwendung von Grafana-Dashboards in einem Amazon Managed Grafana-Arbeitsbereich finden Sie unter. SageMaker HyperPod Überwachung von Cluster-Ressourcen Um diesen Installationsschritt zu aktivieren, setzen Sie den
enable_observabilityParameter in der Datei aufTrue.config.py# Install metric exporting software and Prometheus for observability if Config.enable_observability: if node_type == SlurmNodeType.COMPUTE_NODE: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_dcgm_exporter.sh").run() ExecuteBashScript("./utils/install_efa_node_exporter.sh").run() if node_type == SlurmNodeType.HEAD_NODE: wait_for_scontrol() ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_slurm_exporter.sh").run() ExecuteBashScript("./utils/install_prometheus.sh").run()
-
-
-
Stellen Sie sicher, dass Sie alle Konfigurationsdateien und Setup-Skripts aus Schritt 2 in den S3-Bucket hochladen, den Sie in der
CreateClusterAnfrage in Schritt 1 angeben. Gehen Sie beispielsweise davon aus, dass Ihrcreate_cluster.jsonSystem über Folgendes verfügt."LifeCycleConfig": { "SourceS3URI": "s3://sagemaker-hyperpod-lifecycle/src", "OnCreate": "on_create.sh" }Dann
"s3://sagemaker-hyperpod-lifecycle/src"sollten Sie,on_create.shlifecycle_script.pyprovisioning_parameters.json, und alle anderen Setup-Skripte enthalten. Gehen Sie davon aus, dass Sie die Dateien in einem lokalen Ordner wie folgt vorbereitet haben.└── lifecycle_files // your local folder ├── provisioning_parameters.json ├── on_create.sh ├── lifecycle_script.py └── ... // more setup scrips to be fed into lifecycle_script.pyVerwenden Sie den S3-Befehl wie folgt, um die Dateien hochzuladen.
aws s3 cp --recursive./lifecycle_scriptss3://sagemaker-hyperpod-lifecycle/src
