Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
SageMaker HyperPod Rezept-Repository
Verwenden Sie das SageMaker HyperPod Rezept-Repository
-
main.py: Diese Datei dient als primärer Einstiegspunkt für die Einleitung des Prozesses, bei dem ein Schulungsjob entweder einem Cluster oder einem SageMaker Schulungsjob zugewiesen wird. -
launcher_scripts: Dieses Verzeichnis enthält eine Sammlung häufig verwendeter Skripte, die den Trainingsprozess für verschiedene Large Language Models (LLMs) erleichtern sollen. -
recipes_collection: Dieser Ordner enthält eine Zusammenstellung von vordefinierten LLM Rezepten, die von den Entwicklern bereitgestellt wurden. Benutzer können diese Rezepte in Verbindung mit ihren benutzerdefinierten Daten nutzen, um LLM Modelle zu trainieren, die auf ihre spezifischen Anforderungen zugeschnitten sind.
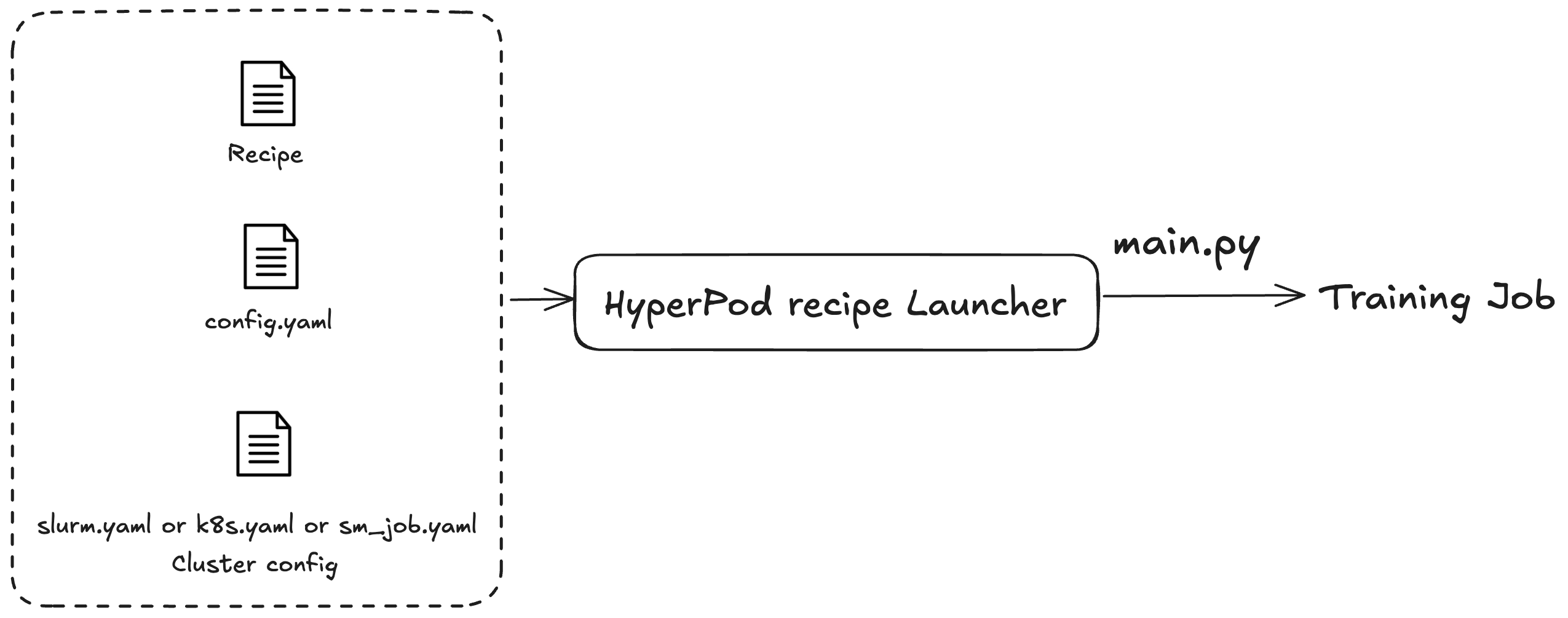
Sie verwenden die SageMaker HyperPod Rezepte, um Schulungs- oder Feinabstimmungsaufgaben zu starten. Unabhängig davon, welchen Cluster Sie verwenden, ist das Verfahren zum Einreichen des Jobs derselbe. Sie können beispielsweise dasselbe Skript verwenden, um einen Job an einen Slurm- oder Kubernetes-Cluster zu senden. Der Launcher sendet einen Trainingsjob auf der Grundlage von drei Konfigurationsdateien aus:
-
Allgemeine Konfiguration (
config.yaml): Beinhaltet allgemeine Einstellungen wie die Standardparameter oder Umgebungsvariablen, die im Trainingsjob verwendet werden. -
Cluster-Konfiguration (Cluster): Nur für Trainingsaufgaben, bei denen Cluster verwendet werden. Wenn Sie einen Trainingsjob an einen Kubernetes-Cluster senden, müssen Sie möglicherweise Informationen wie Volumen, Bezeichnung oder Neustartrichtlinie angeben. Für Slurm-Cluster müssen Sie möglicherweise den Slurm-Jobnamen angeben. Alle Parameter beziehen sich auf den spezifischen Cluster, den Sie verwenden.
-
Rezept (Rezepte): Rezepte enthalten die Einstellungen für Ihren Trainingsjob, z. B. die Modelltypen, den Grad der Aufteilung oder die Datensatzpfade. Sie können beispielsweise Llama als Ihr Trainingsmodell angeben und es mithilfe von Modell- oder Datenparallelitätstechniken wie Fully Sharded Distributed Parallel () FSDP auf acht Computern trainieren. Sie können auch verschiedene Checkpoint-Frequenzen oder Pfade für Ihren Trainingsjob angeben.
Nachdem Sie ein Rezept angegeben haben, führen Sie das Launcher-Skript aus, um einen end-to-end Trainingsjob auf einem Cluster auf der Grundlage der Konfigurationen über den main.py Einstiegspunkt anzugeben. Zu jedem Rezept, das Sie verwenden, gibt es zugehörige Shell-Skripts im Ordner launch_scripts. Diese Beispiele führen Sie durch das Einreichen und Initiieren von Schulungsaufträgen. Die folgende Abbildung zeigt, wie ein SageMaker HyperPod Recipe Launcher einen Trainingsjob auf der Grundlage des Vorstehenden an einen Cluster weiterleitet. Derzeit basiert der SageMaker HyperPod Recipe Launcher auf dem Nvidia NeMo Framework Launcher. Weitere Informationen finden Sie im NeMo Launcher-Handbuch