Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfigurieren Sie Ihren Modellanbieter
Anmerkung
In diesem Abschnitt gehen wir davon aus, dass die Sprach- und Einbettungsmodelle, die Sie verwenden möchten, bereits bereitgestellt sind. Für Modelle, die von bereitgestellt werden AWS, sollten Sie bereits über Ihren SageMaker Endpunkt oder Zugriff auf Amazon Bedrock verfügen. ARN Bei anderen Modellanbietern sollten Sie den API Schlüssel haben, der zur Authentifizierung und Autorisierung von Anfragen an Ihr Modell verwendet wird.
Jupyter AI unterstützt eine Vielzahl von Modellanbietern und Sprachmodellen. In der Liste der unterstützten Modelle finden Sie Informationen zu den neuesten verfügbaren Modellen
Die Konfiguration von Jupyter AI hängt davon ab, ob Sie die Chat-Benutzeroberfläche oder magische Befehle verwenden.
Konfigurieren Sie Ihren Modellanbieter in der Chat-Benutzeroberfläche
Anmerkung
Sie können mehrere Modelle konfigurieren LLMs und sie einbetten, indem Sie denselben Anweisungen folgen. Sie müssen jedoch mindestens ein Sprachmodell konfigurieren.
Um Ihre Chat-Benutzeroberfläche zu konfigurieren
-
Rufen Sie in die Chat-Oberfläche auf JupyterLab, indem Sie im linken Navigationsbereich das Chat-Symbol (
 ) auswählen.
) auswählen. -
Wählen Sie das Konfigurationssymbol (
 ) in der oberen rechten Ecke des linken Bereichs. Dadurch wird das Jupyter AI-Konfigurationsfenster geöffnet.
) in der oberen rechten Ecke des linken Bereichs. Dadurch wird das Jupyter AI-Konfigurationsfenster geöffnet. -
Füllen Sie die Felder aus, die sich auf Ihren Dienstanbieter beziehen.
-
Für Modelle, die von JumpStart oder Amazon Bedrock bereitgestellt werden
-
Wählen Sie in der Dropdownliste Sprachmodell
sagemaker-endpointfür Modelle aus, die mit Amazon Bedrock bereitgestellt werden, JumpStart oderbedrockfür Modelle, die von Amazon Bedrock verwaltet werden. -
Die Parameter unterscheiden sich je nachdem, ob Ihr Modell auf Amazon Bedrock SageMaker oder Amazon Bedrock bereitgestellt wird.
-
Für Modelle, die bereitgestellt werden mit JumpStart:
-
Geben Sie im Feld Endpunktname den Namen Ihres Endpunkts und anschließend den Namen, AWS-Region in dem Ihr Modell bereitgestellt wird, unter Regionsname ein. Um die ARN SageMaker Endpunkte abzurufen, navigieren Sie zu Inference https://console.aws.amazon.com/sagemaker/
and Endpoints und wählen Sie dann im linken Menü aus. -
Fügen Sie das JSON auf Ihr Modell zugeschnittene Anforderungsschema und den entsprechenden Antwortpfad zum Analysieren der Modellausgabe ein.
Anmerkung
In den folgenden Beispielnotizbüchern
finden Sie das Anforderungs- und Antwortformat verschiedener JumpStart Foundation-Modelle. Jedes Notizbuch ist nach dem Modell benannt, das es vorstellt.
-
-
Für Modelle, die von Amazon Bedrock verwaltet werden: Fügen Sie das AWS Profil hinzu, in dem Ihre AWS Anmeldeinformationen auf Ihrem System gespeichert sind (optional), und dann das Profil, AWS-Region in dem Ihr Modell bereitgestellt wird, als Regionsname.
-
-
(Optional) Wählen Sie ein Einbettungsmodell aus, auf das Sie Zugriff haben. Einbettungsmodelle werden verwendet, um zusätzliche Informationen aus lokalen Dokumenten zu erfassen, sodass das Textgenerierungsmodell Fragen im Kontext dieser Dokumente beantworten kann.
-
Wählen Sie „Änderungen speichern“ und navigieren Sie zum Linkspfeilsymbol (
 ) in der oberen linken Ecke des linken Bereichs. Dadurch wird die Jupyter AI-Chat-Benutzeroberfläche geöffnet. Sie können beginnen, mit Ihrem Modell zu interagieren.
) in der oberen linken Ecke des linken Bereichs. Dadurch wird die Jupyter AI-Chat-Benutzeroberfläche geöffnet. Sie können beginnen, mit Ihrem Modell zu interagieren.
-
-
Für Modelle, die von Drittanbietern gehostet werden
-
Wählen Sie in der Dropdownliste für das Sprachmodell Ihre Anbieter-ID aus. Sie finden die Details der einzelnen Anbieter, einschließlich ihrer ID, in der Jupyter AI-Liste der
Modellanbieter. -
(Optional) Wählen Sie ein Einbettungsmodell aus, auf das Sie Zugriff haben. Einbettungsmodelle werden verwendet, um zusätzliche Informationen aus lokalen Dokumenten zu erfassen, sodass das Textgenerierungsmodell Fragen im Kontext dieser Dokumente beantworten kann.
-
Fügen Sie die Schlüssel Ihrer Modelle ein. API
-
Wählen Sie „Änderungen speichern“ und navigieren Sie zum Linkspfeilsymbol (
) in der oberen linken Ecke des linken Bereichs. Dadurch wird die Jupyter AI-Chat-Benutzeroberfläche geöffnet. Sie können beginnen, mit Ihrem Modell zu interagieren.
-
-
Der folgende Schnappschuss ist eine Veranschaulichung des Konfigurationsfensters für die Chat-Benutzeroberfläche, das so konfiguriert ist, dass es ein Flan-T5-Small-Modell aufruft, das von bereitgestellt und in diesem bereitgestellt wird. JumpStart SageMaker
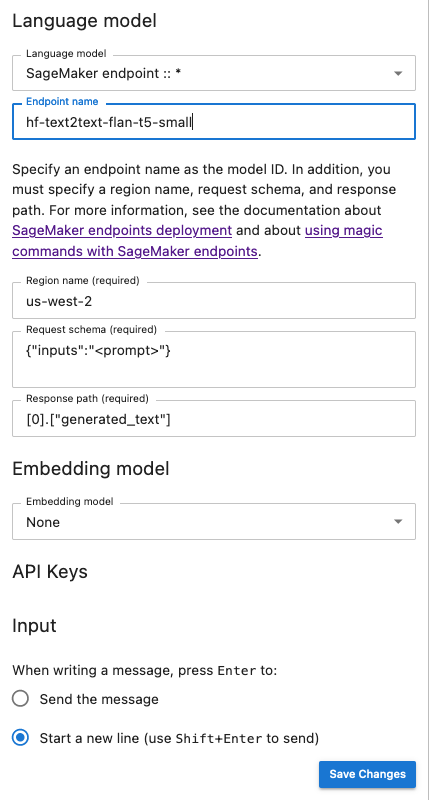
Übergeben Sie zusätzliche Modellparameter und benutzerdefinierte Parameter an Ihre Anfrage
Ihr Modell benötigt möglicherweise zusätzliche Parameter, z. B. ein benutzerdefiniertes Attribut für die Genehmigung der Benutzervereinbarung oder Anpassungen an anderen Modellparametern wie Temperatur oder Antwortlänge. Wir empfehlen, diese Einstellungen als Startoption Ihrer JupyterLab Anwendung mithilfe einer Lebenszykluskonfiguration zu konfigurieren. Informationen dazu, wie Sie eine Lebenszykluskonfiguration erstellen und sie über die SageMaker Konsole
Verwenden Sie das folgende JSON Schema, um Ihre zusätzlichen Parameter zu konfigurieren:
{ "AiExtension": { "model_parameters": { "<provider_id>:<model_id>": { Dictionary of model parameters which is unpacked and passed as-is to the provider.} } } } }
Das folgende Skript ist ein Beispiel für eine JSON Konfigurationsdatei, die Sie beim Erstellen einer JupyterLab Anwendung verwenden können, LCC um die maximale Länge eines AI21Labs Jurassic-2-Modells festzulegen, das auf Amazon Bedrock bereitgestellt wird. Wenn Sie die Länge der vom Modell generierten Antwort erhöhen, können Sie verhindern, dass die Antwort Ihres Modells systematisch gekürzt wird.
#!/bin/bash set -eux mkdir -p /home/sagemaker-user/.jupyter json='{"AiExtension": {"model_parameters": {"bedrock:ai21.j2-mid-v1": {"model_kwargs": {"maxTokens": 200}}}}}' # equivalent to %%ai bedrock:ai21.j2-mid-v1 -m {"model_kwargs":{"maxTokens":200}} # File path file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json" #jupyter --paths # Write JSON to file echo "$json" > "$file_path" # Confirmation message echo "JSON written to $file_path" restart-jupyter-server # Waiting for 30 seconds to make sure the Jupyter Server is up and running sleep 30
Das folgende Skript ist ein Beispiel für eine JSON Konfigurationsdatei zur Erstellung einer JupyterLab LCC Anwendung, mit der zusätzliche Modellparameter für ein auf Amazon Bedrock bereitgestelltes Anthropic-Claude-Modell festgelegt werden.
#!/bin/bash set -eux mkdir -p /home/sagemaker-user/.jupyter json='{"AiExtension": {"model_parameters": {"bedrock:anthropic.claude-v2":{"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":25 0,"max_tokens_to_sample":2}}}}}' # equivalent to %%ai bedrock:anthropic.claude-v2 -m {"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":250,"max_tokens_to_sample":2000}} # File path file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json" #jupyter --paths # Write JSON to file echo "$json" > "$file_path" # Confirmation message echo "JSON written to $file_path" restart-jupyter-server # Waiting for 30 seconds to make sure the Jupyter Server is up and running sleep 30
Nachdem Sie Ihr Profil LCC an Ihre Domain oder Ihr Benutzerprofil angehängt haben, fügen Sie es LCC zu Ihrem Bereich hinzu, wenn Sie Ihre JupyterLab Anwendung starten. Um sicherzustellen, dass Ihre Konfigurationsdatei von der aktualisiert wirdLCC, führen Sie sie more ~/.jupyter/jupyter_jupyter_ai_config.json in einem Terminal aus. Der Inhalt der Datei sollte dem Inhalt der JSON Datei entsprechen, die an die übergeben wurdeLCC.
Konfigurieren Sie Ihren Modellanbieter in einem Notizbuch
Um ein Modell über Jupyter AI in JupyterLab oder Studio Classic-Notebooks mit den Befehlen und Magic aufzurufen %%ai%ai
-
Installieren Sie die für Ihren Modellanbieter spezifischen Client-Bibliotheken in Ihrer Notebook-Umgebung. Wenn Sie beispielsweise OpenAI-Modelle verwenden, müssen Sie die
openaiClient-Bibliothek installieren. Sie finden die Liste der pro Anbieter erforderlichen Clientbibliotheken in der Spalte Python-Paket (e) der Jupyter AI Model-Anbieterliste. Anmerkung
Bei Modellen, die von gehostet werden AWS,
boto3ist bereits im SageMaker Distribution-Image installiert, das von verwendet wird JupyterLab, oder in einem beliebigen Data Science-Image, das mit Studio Classic verwendet wird. -
-
Für Modelle, die gehostet werden von AWS
Stellen Sie sicher, dass Ihre Ausführungsrolle berechtigt ist, Ihren SageMaker Endpunkt für Modelle aufzurufen, die von Amazon Bedrock bereitgestellt werden JumpStart oder dass Sie Zugriff darauf haben.
-
Für Modelle, die von Drittanbietern gehostet werden
Exportieren Sie den API Schlüssel Ihres Anbieters mithilfe von Umgebungsvariablen in Ihre Notebook-Umgebung. Sie können den folgenden magischen Befehl verwenden. Ersetzen Sie das
provider_API_keyim Befehl enthaltene durch die Umgebungsvariable in der Spalte Umgebungsvariable der Jupyter AI Model-Anbieterliste für Ihren Anbieter. %env provider_API_key=your_API_key
-
