Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
RL-Umgebungen in Amazon SageMaker AI
Amazon SageMaker AI RL verwendet Umgebungen, um reale Szenarien nachzuahmen. Der Simulator verarbeitet ausgehend vom aktuellen Zustand der Umgebung und einer Aktion des oder der Agenten die Auswirkung der Aktion und gibt den nächsten Zustand und eine Belohnung zurück. Simulatoren können hilfreich sein, wenn das Training eines Agenten in der realen Welt nicht sicher wäre (beispielsweise beim Fliegen einer Drone) oder wenn das Konvergieren des RL-Algorithmus lange dauert (z. B. beim Schachspielen).
Die folgende Darstellung enthält ein Beispiel der Interaktionen mit einem Simulator für ein Autorennspiel.
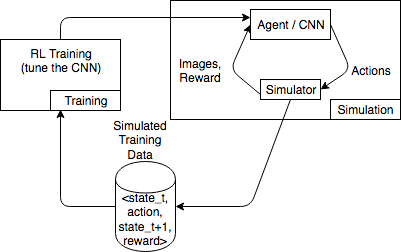
Die Simulationsumgebung besteht aus einem Agenten und einem Simulator. Hier verarbeitet ein Convolutional Neural Network (CNN) Bilder eines Simulators und generiert Aktionen zum Steuern des Spielecontrollers. Mit mehreren Simulationen generiert diese Umgebung Trainingsdaten der Form state_t, action, state_t+1 und reward_t+1. Das Definieren der Belohnung ist nicht unbedeutend und beeinflusst die Qualität des RL-Modells. Wir möchten einige Beispiele für Belohnungsfunktionen zur Verfügung stellen, sie aber durch den Benutzer konfigurierbar machen.
Themen
Verwenden Sie die OpenAI Gym-Schnittstelle für Umgebungen in SageMaker AI RL
Verwenden Sie die folgenden API-Elemente, um SageMaker OpenAI Gym-Umgebungen in AI RL zu verwenden. Weitere Informationen zu OpenAI Gym finden Sie in der Fitnessstudio-Dokumentation
-
env.action_space– Definiert die Aktionen, die der Agent ausführen kann, gibt an, ob jede Aktion kontinuierlich oder diskret ist, und gibt das Minimum und das Maximum an, wenn die Aktion kontinuierlich ist. -
env.observation_space– Definiert die Beobachtungen, die der Agent aus der Umgebung erhält, sowie die Mindest- und Höchstwerte für kontinuierliche Beobachtungen. -
env.reset()– Initialisiert eine Trainingsepisode. Diereset()Funktion gibt den anfänglichen Zustand der Umgebung zurück und der Agent nutzt den anfänglichen Zustand zum Einleiten seiner ersten Aktion. Die Aktion wird dannstep()wiederholt gesendet, bis die Episode einen abschließenden Zustand erreicht. Wennstep()gibtdone = Truezurück, endet die Episode. Das RL-Toolkit ruftreset()auf, um die Umgebung zu reinitialisieren. -
step()– Verwendet die Agentenaktion als Eingabe und gibt den nächsten Zustand der Umgebung, die Belohnung, ob die Episode beendet wurde, und eininfoWörterbuch zur Übermittlung von Debugging-Informationen aus. Die Umgebung ist für das Validieren der Eingaben zuständig. -
env.render()–Wird für Umgebungen mit Visualisierungen verwendet. Das RL-Toolkit ruft diese Funktion auf, um Visualisierungen der Umgebung nach jedem Aufruf derstep()-Funktion zu erfassen.
Verwenden Sie Umgebungen Open-Source
Sie können Open-Source-Umgebungen wie EnergyPlus und in SageMaker AI RL verwenden RoboSchool, indem Sie Ihren eigenen Container erstellen. Weitere Informationen zu finden Sie EnergyPlus unter https://energyplus.net/
Verwenden von kommerziellen Umgebungen
Sie können kommerzielle Umgebungen wie MATLAB und Simulink in SageMaker AI RL verwenden, indem Sie Ihren eigenen Container erstellen. Sie müssen Ihre eigenen Lizenzen verwalten.
