Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Grundlegendes zu Koordinatensystemen und Sensorfusion
Punktwolkendaten befinden sich immer in einem Koordinatensystem. Dieses Koordinatensystem kann für das Fahrzeug oder Gerät, das die Umgebung erkennt, lokal sein oder es kann sich um ein Weltkoordinatensystem handeln. Bei der Verwendung von Ground-Truth-3D-Punktwolkenbeschriftungsaufträgen werden alle Anmerkungen unter Verwendung des Koordinatensystems Ihrer Eingabedaten erstellt. Bei einigen Aufgabentypen und Funktionen der Kennzeichnungsaufträge müssen Sie Daten in einem Weltkoordinatensystem bereitstellen.
In diesem Thema erfahren Sie Folgendes:
-
Wenn Sie Eingabedaten in einem Weltkoordinatensystem oder einem globalen Referenzrahmen angeben müssen.
-
Was eine Weltkoordinate ist und wie Sie Punktwolkendaten in ein Weltkoordinatensystem konvertieren können.
-
Wie Sie Ihre extrinsischen Sensor- und Kameramatrizen verwenden können, um Posendaten bereitzustellen, wenn Sie die Sensorfusion verwenden.
Koordinatensystemanforderungen für Kennzeichnungsaufträge
Wenn Ihre Punktwolkendaten in einem lokalen Koordinatensystem erfasst wurden, können Sie eine extrinsische Matrix des Sensors verwenden, der zum Sammeln der Daten verwendet wird, um sie in ein Weltkoordinatensystem oder globalen Referenzrahmen zu konvertieren. Wenn Sie keine extrinsische Matrix für Ihre Punktwolkendaten erhalten können und daher keine Punktwolken in einem Weltkoordinatensystem abrufen können, können Sie Punktwolkendaten in einem lokalen Koordinatensystem für Aufgabentypen der 3D-Punktwolkenobjekterkennung und semantischen Segmentierung bereitstellen.
Für die Objektverfolgung müssen Sie Punktwolkendaten in einem Weltkoordinatensystem bereitstellen. Dies liegt daran, dass, wenn Sie Objekte über mehrere Frames verfolgen, sich das Ego-Fahrzeug selbst in der Welt bewegt und daher alle Frames einen Bezugspunkt benötigen.
Wenn Sie Kameradaten für die Sensorfusion einschließen, empfiehlt es sich, Kameraposen im selben Weltkoordinatensystem wie der 3D-Sensor (z. B. ein LiDAR-Sensor) bereitzustellen.
Verwenden von Punktwolkendaten in einem Weltkoordinatensystem
In diesem Abschnitt wird erläutert, was ein Weltkoordinatensystem (WKS), auch als globaler Referenzrahmen bezeichnet, ist, und erläutert, wie Sie Punktwolkendaten in einem Weltkoordinatensystem bereitstellen können.
Was ist ein Weltkoordinatensystem?
Ein WKS oder globaler Referenzrahmen ist ein festes universelles Koordinatensystem, in dem Fahrzeug- und Sensorkoordinatensysteme platziert werden. Wenn sich beispielsweise mehrere Punktwolkenframes in verschiedenen Koordinatensystemen befinden, weil sie von zwei Sensoren erfasst wurden, kann ein WKS verwendet werden, um alle Koordinaten in diesen Punktwolkenframes in ein einzelnes Koordinatensystem zu verschieben, wobei alle Frames denselben Ursprung haben (0,0,0). Diese Transformation erfolgt, indem der Ursprung jedes Frames mit einem Translationsvektor in den Ursprung des WKS verschoben und die drei Achsen (typischerweise x, y und z) mithilfe einer Rotationsmatrix in die richtige Ausrichtung gedreht werden. Diese starre Körpertransformation wird als homogene Transformation bezeichnet.
Ein Weltkoordinatensystem ist wichtig für die globale Pfadplanung, Lokalisierung, Kartierung und Simulation von Fahrszenarien. Ground Truth verwendet das kartesische Weltkoordinatensystem für Rechtshänder, wie es in ISO 8855
Der globale Referenzrahmen hängt von den Daten ab. Einige Datensätze verwenden die LiDAR-Position im ersten Frame als Ursprung. In diesem Szenario verwenden alle Frames den ersten Frame als Referenz und der Fahrkurs und die Position des Geräts befinden sich in der Nähe des Ursprungs im ersten Frame. Beispielsweise haben KITTI-Datensätze den ersten Frame als Referenz für Weltkoordinaten. Andere Datensätze verwenden eine Geräteposition, die vom Ursprung abweicht.
Beachten Sie, dass dies nicht das GPS/IMU coordinate system, which is typically rotated by 90 degrees along the z-axis. If your point cloud data is in a GPS/IMU Koordinatensystem ist (wie OxTS im Open-Source-AV KITTI-Datensatz). Dann müssen Sie den Ursprung in ein Weltkoordinatensystem transformieren (normalerweise das Referenzkoordinatensystem des Fahrzeugs). Sie wenden diese Transformation an, indem Sie Ihre Daten mit Transformationsmetriken (Rotationsmatrix und Translationsvektor) multiplizieren. Dadurch werden die Daten vom ursprünglichen Koordinatensystem in ein globales Referenzkoordinatensystem transformiert. Weitere Informationen zu dieser Transformation finden Sie im nächsten Abschnitt.
Konvertieren von 3D-Punktwolkendaten in ein WKS
Ground Truth geht davon aus, dass Ihre Punktwolkendaten bereits in ein Referenzkoordinatensystem Ihrer Wahl transformiert worden sind. Sie können beispielsweise das Referenzkoordinatensystem des Sensors (z. B. LiDAR) als globales Referenzkoordinatensystem auswählen. Sie können auch Punktwolken von verschiedenen Sensoren nehmen und sie von der Sensoransicht in die Referenzkoordinatensystemansicht des Fahrzeugs transformieren. Sie verwenden die extrinsische Matrix eines Sensors, bestehend aus einer Rotationsmatrix und einem Translationsvektor, um Ihre Punktwolkendaten in ein WKS oder einen globalen Referenzrahmen zu konvertieren.
Zusammenfassend können der Translationsvektor und die Rotationsmatrix verwendet werden, um eine extrinsische Matrix zu bilden, die verwendet werden kann, um Daten aus einem lokalen Koordinatensystem in ein WKS zu konvertieren. Beispielsweise kann Ihre extrinsische LiDAR-Matrix wie folgt zusammengesetzt werden, wobei R die Rotationsmatrix und T der Translationsvektor ist:
LiDAR_extrinsic = [R T;0 0 0 1]
Das KITTI-Datensatz für autonomes Fahren enthält beispielsweise eine Rotationsmatrix und einen Translationsvektor für die extrinsische LiDAR-Transformationsmatrix für jeden Frame. Das pykittidataset.oxts[i].T_w_imu die extrinsische LiDAR-Transformation für den i. Frame bereit und kann mit Punkten in diesem Frame multipliziert werden, um sie in ein festes Referenzsystem zu konvertieren – np.matmul(lidar_transform_matrix, points). Wenn Sie einen Punkt im LiDAR-Frame mit einer extrinsischen LiDAR-Matrix multiplizieren, wird er in Weltkoordinaten umgewandelt. Wenn Sie einen Punkt im festen Referenzsystem mit der extrinsischen Matrix der Kamera multiplizieren, werden die Punktkoordinaten im Referenzrahmen der Kamera angezeigt.
Im folgenden Codebeispiel wird veranschaulicht, wie Sie Punktwolkenframes aus dem KITTI-Datensatz in ein WKS konvertieren können.
import pykitti import numpy as np basedir = '/Users/nameofuser/kitti-data' date = '2011_09_26' drive = '0079' # The 'frames' argument is optional - default: None, which loads the whole dataset. # Calibration, timestamps, and IMU data are read automatically. # Camera and velodyne data are available via properties that create generators # when accessed, or through getter methods that provide random access. data = pykitti.raw(basedir, date, drive, frames=range(0, 50, 5)) # i is frame number i = 0 # lidar extrinsic for the ith frame lidar_extrinsic_matrix = data.oxts[i].T_w_imu # velodyne raw point cloud in lidar scanners own coordinate system points = data.get_velo(i) # transform points from lidar to global frame using lidar_extrinsic_matrix def generate_transformed_pcd_from_point_cloud(points, lidar_extrinsic_matrix): tps = [] for point in points: transformed_points = np.matmul(lidar_extrinsic_matrix, np.array([point[0], point[1], point[2], 1], dtype=np.float32).reshape(4,1)).tolist() if len(point) > 3 and point[3] is not None: tps.append([transformed_points[0][0], transformed_points[1][0], transformed_points[2][0], point[3]]) return tps # customer transforms points from lidar to global frame using lidar_extrinsic_matrix transformed_pcl = generate_transformed_pcd_from_point_cloud(points, lidar_extrinsic_matrix)
Sensorfusion
Ground Truth unterstützt die Sensorfusion von Punktwolkendaten mit bis zu 8 Videokameraeingängen. Diese Funktion ermöglicht es menschlichen Kennzeichnern, das 3D-Punktwolkenbild side-by-side mit dem synchronisierten Videobild zu betrachten. Neben der Bereitstellung von mehr visuellem Kontext für die Beschriftung ermöglicht die Sensorfusion den Auftragnehmern, Anmerkungen in der 3D-Szene und in 2D-Bildern anzupassen, und die Anpassung wird in die andere Ansicht projiziert. Das folgende Video zeigt einen 3D-Punktwolken-Kennzeichnungsauftrag mit LiDAR und der Kamerasensorfusion.

Um optimale Ergebnisse zu erzielen, sollte sich Ihre Punktwolke bei Verwendung der Sensorfusion in einem WKS befinden. Ground Truth verwendet Ihren Sensor (wie LiDAR), Ihre Kamera und die Poseninformationen Ihres Ego-Fahrzeugs, um extrinsische und intrinsische Matrizen für die Sensorfusion zu berechnen.
Extrinsische Matrix
Ground Truth verwendet die extrinsischen und intrinsischen Matrizen des Sensors (z. B. LiDAR) und der Kamera, um Objekte aus dem Referenzrahmen der Punktwolkendaten auf den Referenzrahmen der Kamera zu projizieren.
Um beispielsweise eine Beschriftung aus der 3D-Punktwolke auf die Kamerabildebene zu projizieren, transformiert Ground Truth die 3D-Punkte aus dem LiDAR-Koordinatensystem in das Koordinatensystem der Kamera. Dazu werden in der Regel zunächst 3D-Punkte mithilfe der extrinsischen LiDAR-Matrix aus dem eigenen LiDAR-Koordinatensystem in ein Weltkoordinatensystem (oder einen globalen Referenzrahmen) transformiert. Ground Truth verwendet dann die inverse extrinsische Kamera (die Punkte von einem globalen Referenzrahmen in den Referenzrahmen der Kamera umwandelt), um die 3D-Punkte aus dem Weltkoordinatensystem, die im vorherigen Schritt erhalten wurden, in die Kamerabildebene zu transformieren. Die extrinsische LiDAR-Matrix kann auch verwendet werden, um 3D-Daten in ein Weltkoordinatensystem zu transformieren. Wenn Ihre 3D-Daten bereits in ein Weltkoordinatensystem umgewandelt werden, hat die erste Transformation keine Auswirkungen auf die Beschriftungstranslation, und die Beschriftungstranslation hängt nur von der inversen extrinsischen Matrix der Kamera ab. Eine Ansichtsmatrix wird verwendet, um projizierte Beschriftungen zu visualisieren. Weitere Informationen zu diesen Transformationen und der Ansichtsmatrix finden Sie unter Transformationen zur Fusion von Ground-Truth-Sensoren.
Ground Truth berechnet diese extrinsischen Matrizen anhand von LiDAR- und Kamerapositionsdaten, die Sie zur Verfügung stellen: heading ( in Quaternionen: qx, qy, qz, und qw) und position (x, y, z). Für das Fahrzeug werden normalerweise der Fahrkurs und die Position im Referenzrahmen des Fahrzeugs in einem Weltkoordinatensystem beschrieben und werden als Ego-Fahrzeugpose bezeichnet. Für jede extrinsische Matrix der Kamera können Sie Poseninformationen für diese Kamera hinzufügen. Weitere Informationen finden Sie unter Pose.
Intrinsische Matrix
Ground Truth verwendet die extrinsischen und intrinsischen Matrizen der Kamera, um Ansichtsmetriken zu berechnen, um Beschriftungen von und zur 3D-Szene in Kamerabilder umzuwandeln. Ground Truth berechnet die kamerainterne Matrix anhand der von Ihnen angegebenen Kamerabrennweite (fx,fy) und der optischen Mittelpunktkoordinaten (cx,cy). Weitere Informationen finden Sie unter Intrinsische Matrix und Verzeichnung.
Bildverzeichnung
Bildverzeichnungen können aus einer Vielzahl von Gründen auftreten. Beispielsweise können Bilder aufgrund von Tonnen- oder Fischaugeneffekten verzerrt sein. Ground Truth verwendet intrinsische Parameter zusammen mit einem Verzerrungskoeffizienten, um verzerrte Bilder zu korrigieren, die Sie bei der Erstellung von 3D-Punktwolken-Beschriftungsaufträgen bereitstellen. Wenn ein Kamerabild bereits unverzerrt ist, sollten alle Verzeichnungskoeffizienten auf 0 gesetzt werden.
Weitere Informationen zu den Transformationen, die Ground Truth durchführt, um Bilder zu entzerren, finden Sie unter Kamerakalibrierungen: extrinsisch, intrinsisch und Verzeichnung.
Ego-Fahrzeug
Um Daten für autonome Fahranwendungen zu sammeln, werden die Messungen zur Generierung von Punktwolkendaten von Sensoren entnommen, die an einem Fahrzeug oder dem Ego-Fahrzeug montiert sind. Um Beschriftungsanpassungen auf die 3D-Szene und 2D-Bilder zu projizieren, benötigt Ground Truth die Ego-Fahrzeugpose in einem Weltkoordinatensystem. Die Ego-Fahrzeugpose besteht aus Positionskoordinaten und dem Ausrichtungsquaternion.
Ground Truth verwendet die Ego-Fahrzeugpose Ihres Fahrzeugs zur Berechnung von Rotations- und Transformationsmatrizen. Rotationen in 3 Dimensionen können durch eine Folge von 3 Rotationen um eine Folge von Achsen dargestellt werden. Theoretisch reichen drei Achsen aus, die sich über den dreidimensionalen euklidischen Raum erstrecken. In der Praxis werden die Rotationsachsen als Basisvektoren gewählt. Es wird erwartet, dass sich die drei Rotationen in einem globalen Referenzrahmen (extrinsisch) befinden. Ground Truth unterstützt kein körperzentriertes Referenzsystem (intrinsisch), das an dem Objekt befestigt ist und sich mit diesem bewegt, wenn es sich dreht. Um Objekte zu verfolgen, muss die Bodenwahrheit von einer globalen Referenz aus gemessen werden, in der sich alle Fahrzeuge bewegen. Bei der Verwendung von Ground-Truth-3D-Punktwolkenbeschriftungsaufträgen gibt z die Rotationsachse (extrinsische Rotation) und die Gier-Euler-Winkel in Radiant (Rotationswinkel) an.
Pose
Ground Truth verwendet Pose-Informationen für 3D-Visualisierungen und Sensor-Fusion. Poseninformationen, die Sie über Ihre Manifestdatei eingeben, werden verwendet, um extrinsische Matrizen zu berechnen. Wenn Sie bereits über eine extrinsische Matrix verfügen, können Sie diese verwenden, um Sensor- und Kameraposendaten zu extrahieren.
Beispielsweise kann im KITTI-Datensatz für autonomes Fahren das pykittidataset.oxts[i].T_w_imu die extrinsische LiDAR-Transformation für den i. Frame bereit und kann mit den Punkten multipliziert werden, um sie in ein festes Referenzsystem einzufügen – matmul(lidar_transform_matrix,
points). Diese Transformation kann für das Eingabemanifestdatei-JSON-Format in LiDAR-Position (Translationsvektor) und -Fahrkurs (in Quaternion) umgewandelt werden. Die extrinsische Kameratransformation für cam0 im i. Frame kann von inv(matmul(dataset.calib.T_cam0_velo,
inv(dataset.oxts[i].T_w_imu))) berechnet werden und dies kann in Fahrkurs und Position für cam0 umgewandelt werden.
import numpy rotation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01]] origin= [1.71104606e+00, 5.80000039e-01, 9.43144935e-01] from scipy.spatial.transform import Rotation as R # position is the origin position = origin r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"pose:{position}\nheading: {heading}")
Position
position bezieht sich in der Eingabemanifestdatei auf die Position des Sensors in Bezug auf ein festes Referenzsystem. Wenn Sie die Geräteposition nicht in ein Weltkoordinatensystem einfügen können, können Sie LiDAR-Daten mit lokalen Koordinaten verwenden. Ebenso können Sie bei montierten Videokameras Position und Fahrkurs in einem Weltkoordinatensystem angeben. Wenn Sie für die Kamera keine Positionsinformationen haben, verwenden Sie bitte (0, 0, 0).
Im Folgenden sind die Felder im Positionsobjekt aufgeführt:
-
x(float) – x-Koordinate der Ego-Fahrzeug-, Sensor- oder Kameraposition in Metern. -
y(float) – y-Koordinate der Ego-Fahrzeug-, Sensor- oder Kameraposition in Metern. -
z(float) – z-Koordinate der Ego-Fahrzeug-, Sensor- oder Kameraposition in Metern.
Nachfolgend finden Sie ein Beispiel für ein position-JSON-Objekt:
{ "position": { "y": -152.77584902657554, "x": 311.21505956090624, "z": -10.854137529636024 } }
Heading
In der Eingabemanifestdatei ist heading ein Objekt, das die Ausrichtung eines Geräts in Bezug auf ein festes Referenzsystem darstellt. Fahrkurswerte sollten in Quaternion vorliegen. Ein Quaternion(qx = 0, qy = 0, qz
= 0, qw = 1). In ähnlicher Weise geben Sie bei Kameras den Fahrkurs in Quaternionen an. Wenn Sie keine extrinsischen Kamerakalibrierungsparameter erhalten können, verwenden Sie bitte auch das Identitätsquaternion.
Felder im Objekt heading lauten wie folgt:
-
qx(Gleitkommazahl) – x-Komponente der Ego-Fahrzeug-, Sensor- oder Kameraausrichtung. -
qy(Gleitkommazahl) – y-Komponente der Ego-Fahrzeug-, Sensor- oder Kameraausrichtung. -
qz(Gleitkommazahl) – z-Komponente der Ego-Fahrzeug-, Sensor- oder Kameraausrichtung. -
qw(Gleitkommazahl) – w-Komponente der Ego-Fahrzeug-, Sensor- oder Kameraausrichtung.
Nachfolgend finden Sie ein Beispiel für ein heading-JSON-Objekt:
{ "heading": { "qy": -0.7046155108831117, "qx": 0.034278837280808494, "qz": 0.7070617895701465, "qw": -0.04904659893885366 } }
Weitere Informationen hierzu finden Sie unter Berechnen von Ausrichtungsquaternionen und Position.
Berechnen von Ausrichtungsquaternionen und Position
Die Ground Truth erfordert, dass alle Orientierungs- oder Kursdaten in Quaternionen angegeben werden. Bei Quaternionen
Sie können Quaternionen aus einer Rotationsmatrix oder einer Transformationsmatrix berechnen.
Wenn Sie eine Rotationsmatrix (bestehend aus den Achsenrotierungen) und einen Translationsvektor (oder Ursprung) im Weltkoordinatensystem anstelle einer einzelnen starren 4x4-Transformationsmatrix haben, können Sie direkt die Rotationsmatrix und den Translationsvektor verwenden, um Quaternionen zu berechnen. Bibliotheken wie scipy
import numpy rotation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01]] origin = [1.71104606e+00, 5.80000039e-01, 9.43144935e-01] from scipy.spatial.transform import Rotation as R # position is the origin position = origin r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"position:{position}\nheading: {heading}")
Ein Benutzeroberflächen-Tool wie 3D Rotation Converter
Wenn Sie eine extrinsische 4x4-Transformationsmatrix haben, beachten Sie, dass die Transformationsmatrix die Form [R T; 0 0 0 1] hat, wobei R die Rotationsmatrix und T der Translationsvektor des Ursprungs ist. Das bedeutet, dass Sie die Rotationsmatrix und den Translationsvektor wie folgt aus der Transformationsmatrix extrahieren können.
import numpy as np transformation = [[ 9.96714314e-01, -8.09890350e-02, 1.16333982e-03, 1.71104606e+00], [ 8.09967396e-02, 9.96661051e-01, -1.03090934e-02, 5.80000039e-01], [-3.24531964e-04, 1.03694477e-02, 9.99946183e-01, 9.43144935e-01], [ 0, 0, 0, 1]] transformation = np.array(transformation ) rotation = transformation[0:3,0:3] translation= transformation[0:3,3] from scipy.spatial.transform import Rotation as R # position is the origin translation position = translation r = R.from_matrix(np.asarray(rotation)) # heading in WCS using scipy heading = r.as_quat() print(f"position:{position}\nheading: {heading}")
Mit Ihrem eigenen Setup können Sie eine extrinsische Transformationsmatrix mithilfe der GPS/IMU-Position und -Ausrichtung (Breitengrad, Längengrad, Höhe und Rollen, Nicken, Gieren) in Bezug auf den LiDAR-Sensor am Ego-Fahrzeug berechnen. Sie können z. B. Posen aus KITTI-Rohdaten mithilfe von pose = convertOxtsToPose(oxts) berechnen, um die OxTS-Daten in lokale euklidische Posen umzuwandeln, die durch starre 4x4-Transformationsmatrizen angegeben werden. Anschließend können Sie diese Posentransformationsmatrix mithilfe der Referenzrahmen-Transformationsmatrix im Weltkoordinatensystem in einen globalen Referenzrahmen transformieren.
struct Quaternion { double w, x, y, z; }; Quaternion ToQuaternion(double yaw, double pitch, double roll) // yaw (Z), pitch (Y), roll (X) { // Abbreviations for the various angular functions double cy = cos(yaw * 0.5); double sy = sin(yaw * 0.5); double cp = cos(pitch * 0.5); double sp = sin(pitch * 0.5); double cr = cos(roll * 0.5); double sr = sin(roll * 0.5); Quaternion q; q.w = cr * cp * cy + sr * sp * sy; q.x = sr * cp * cy - cr * sp * sy; q.y = cr * sp * cy + sr * cp * sy; q.z = cr * cp * sy - sr * sp * cy; return q; }
Transformationen zur Fusion von Ground-Truth-Sensoren
In den folgenden Abschnitten werden die Ground-Truth-Sensorfusionstransformationen, die anhand der von Ihnen bereitgestellten Pose-Daten durchgeführt werden, genauer erläutert.
Extrinsische LiDAR-Matrix
Um zu und von einer 3D-LiDAR-Szene auf ein 2D-Kamerabild zu projizieren, berechnet Ground Truth die starren Transformationsprojektionsmetriken anhand der Pose und der Richtung des Ego-Fahrzeugs. Ground Truth berechnet die Rotation und Translation von Weltkoordinaten in die 3D-Ebene, indem eine einfache Abfolge von Rotationen und Translationen ausgeführt wird.
Ground Truth berechnet die Rotationsmetriken unter Verwendung der Kursquaternionen wie folgt:

[x, y, z, w]Dies entspricht den Parametern im heading JSON-Objekt,. [qx, qy, qz, qw] Ground Truth berechnet den Übersetzungsspaltenvektor alsT = [poseX, poseY, poseZ]. Dann sind die extrinsischen Metriken einfach wie folgt:
LiDAR_extrinsic = [R T;0 0 0 1]
Kamerakalibrierungen: extrinsisch, intrinsisch und Verzeichnung
Die geometrische Kamerakalibrierung, auch als Kamera-Resektionierung bezeichnet, schätzt die Parameter eines Objektivs und eines Bildsensors einer Bild- oder Videokamera. Sie können diese Parameter verwenden, um Objektivverzeichnungen zu korrigieren, die Größe eines Objekts in Welteinheiten zu messen oder die Position der Kamera in der Szene zu bestimmen. Kameraparameter umfassen intrinsische Matrizen und Verzeichnungskoeffizienten.
Extrinsische Matrix der Kamera
Wenn die Kameraposition gegeben ist, berechnet Ground Truth die Kameraextrinsik auf der Grundlage einer starren Transformation von der 3D-Ebene in die Kameraebene. Die Berechnung ist die gleiche wie die für Extrinsische LiDAR-Matrix, außer dass Ground Truth die Kamerapose (position und heading) verwendet und die inverse Extrinsik berechnet.
camera_inverse_extrinsic = inv([Rc Tc;0 0 0 1]) #where Rc and Tc are camera pose components
Intrinsische Matrix und Verzeichnung
Bei einigen Kameras, z. B. Lochkameras oder Fischaugenkameras, kann es zu erheblichen Verzerrungen bei Fotos kommen. Diese Verzerrung kann mithilfe von Verzerrungskoeffizienten und der Brennweite der Kamera korrigiert werden. Weitere Informationen finden Sie unter Kamerakalibrierung mit OpenCV
Es gibt zwei Arten von Verzerrungen, die Ground Truth korrigieren kann: radiale Verzerrung und tangentiale Verzerrung.
Radiale Verzeichnung tritt auf, wenn Lichtstrahlen sich mehr in der Nähe der Kanten einer Linse biegen als in ihrer optischen Mitte. Je kleiner das Objektiv, desto größer die Verzeichnung. Das Vorhandensein der radialen Verzerrung manifestiert sich in Form des Tonnen- oder Fischaugen-effekts, und Ground Truth verwendet die Formel 1, um ihn zu entzerren.
Formel 1:

Die tangentiale Verzerrung entsteht, weil die Objektive, mit denen die Bilder aufgenommen werden, nicht perfekt parallel zur Bildebene liegen. Dies kann mit der Formel 2 korrigiert werden.
Formel 2:
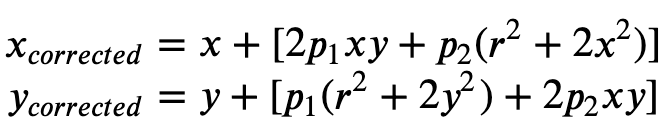
In der manifesten Eingabedatei können Sie Verzeichnungskoeffizienten angeben, und die Ground Truth wird Ihre Bilder unverzerrt darstellen. Alle Verzeichnungskoeffizienten sind Gleitkommazahlen.
-
k1,k2,k3,k4– Radialer Verzeichnungskoeffizient. Unterstützt sowohl für Fischaugen- als auch Lochkameramodelle. -
p1,p2– Tangentiale Verzeichnungskoeffizienten. Unterstützt für Lochkameramodelle.
Wenn Bilder bereits unverzerrt sind, sollten alle Verzeichnungskoeffizienten in Ihrem Eingabemanifest 0 sein.
Um das korrigierte Bild korrekt zu rekonstruieren, führt Ground Truth eine Einheitenumrechnung der Bilder auf der Grundlage von Brennweiten durch. Wenn eine gemeinsame Brennweite mit einem bestimmten Seitenverhältnis für beide Achsen verwendet wird, z. B. 1, haben wir in der oberen Formel eine einzige Brennweite. Die Matrix, die diese vier Parameter enthält, wird als die kamerainterne intrinsische Kalibrierungsmatrix bezeichnet.

Obwohl die Verzeichnungskoeffizienten unabhängig von den verwendeten Kameraauflösungen gleich sind, sollten diese mit der aktuellen Auflösung aus der kalibrierten Auflösung skaliert werden.
Die folgenden Werte sind Gleitkommawerte.
-
fx– Brennweite in x-Richtung. -
fy– Brennweite in y-Richtung. -
cx– x-Koordinate des Hauptpunkts. -
cy– y-Koordinate des Hauptpunkts.
Ground Truth verwendet die Kameraextrinsik und Kameraintrinsik zur Berechnung von Ansichtsmetriken, wie im folgenden Codeblock gezeigt, um Bezeichnungen zwischen der 3D-Szene und 2D-Bildern zu transformieren.
def generate_view_matrix(intrinsic_matrix, extrinsic_matrix): intrinsic_matrix = np.c_[intrinsic_matrix, np.zeros(3)] view_matrix = np.matmul(intrinsic_matrix, extrinsic_matrix) view_matrix = np.insert(view_matrix, 2, np.array((0, 0, 0, 1)), 0) return view_matrix
