Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Modelltrainings
Die Trainingsphase des gesamten Lebenszyklus des maschinellen Lernens (ML) reicht vom Zugriff auf Ihren Trainingsdatensatz über die Generierung eines endgültigen Modells bis hin zur Auswahl des Modells mit der besten Leistung für den Einsatz. Die folgenden Abschnitte bieten einen Überblick über die verfügbaren SageMaker Schulungsfunktionen und Ressourcen mit ausführlichen technischen Informationen zu den einzelnen Funktionen.
Die grundlegende Architektur von SageMaker Training
Wenn Sie SageMaker KI zum ersten Mal verwenden und nach einer schnellen ML-Lösung suchen, um ein Modell anhand Ihres Datensatzes zu trainieren, sollten Sie die Verwendung einer No-Code- oder Low-Code-Lösung wie SageMaker Canvas JumpStartin SageMaker Studio Classic oder SageMaker Autopilot in Betracht ziehen.
Für fortgeschrittene Programmierkenntnisse sollten Sie ein SageMaker Studio Classic-Notizbuch oder Notebook-Instanzen verwenden. SageMaker Folgen Sie zunächst den Anweisungen im Trainieren eines Modells SageMaker KI-Leitfaden Erste Schritte. Wir empfehlen dies für Anwendungsfälle, in denen Sie Ihr eigenes Modell und Ihr eigenes Trainingsskript mithilfe eines ML-Frameworks erstellen.
Der Kern von SageMaker KI-Jobs ist die Containerisierung von ML-Workloads und die Fähigkeit, Rechenressourcen zu verwalten. Die SageMaker Trainingsplattform übernimmt die schwere Arbeit, die mit der Einrichtung und Verwaltung der Infrastruktur für ML-Schulungsworkloads verbunden ist. Mit SageMaker Training können Sie sich auf die Entwicklung, Schulung und Feinabstimmung Ihres Modells konzentrieren.
Das folgende Architekturdiagramm zeigt, wie SageMaker KI ML-Schulungsjobs verwaltet und Amazon EC2 EC2-Instances im Namen von SageMaker KI-Benutzern bereitstellt. Sie als SageMaker KI-Benutzer können Ihren eigenen Trainingsdatensatz mitbringen und ihn in Amazon S3 speichern. Sie können ein ML-Modelltraining aus den verfügbaren integrierten SageMaker KI-Algorithmen auswählen oder Ihr eigenes Trainingsskript mit einem Modell mitbringen, das mit gängigen Frameworks für maschinelles Lernen erstellt wurde.
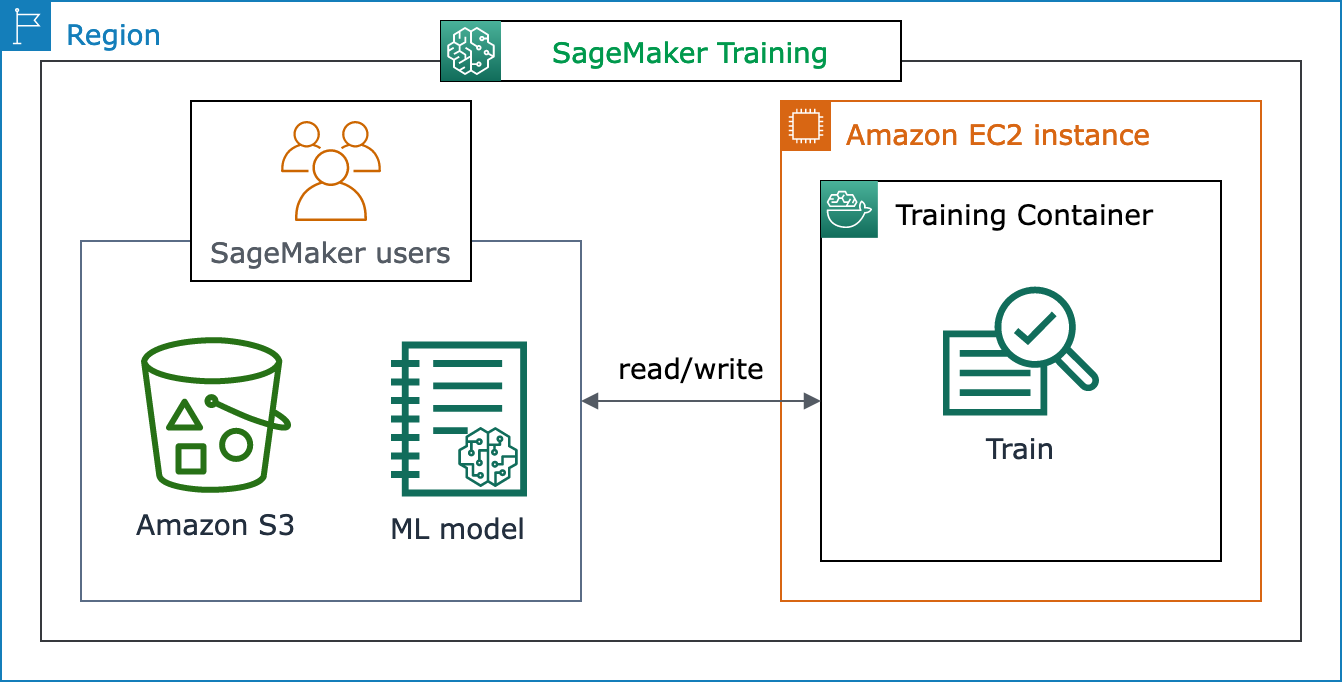
Vollständige Ansicht des SageMaker Trainingsablaufs und der Funktionen
Der gesamte Ablauf des ML-Trainings umfasst Aufgaben, die über die Datenaufnahme in ML-Modelle hinausgehen, Modelle auf Rechen-Instances trainieren und Modellartefakte und -ausgaben abrufen. Sie müssen jede Phase vor, während und nach dem Training auswerten, um sicherzustellen, dass Ihr Modell gut trainiert ist, damit es die Zielgenauigkeit für Ihre Ziele erreicht.
Das folgende Flussdiagramm zeigt einen allgemeinen Überblick über Ihre Aktionen (in blauen Feldern) und verfügbaren SageMaker Trainingsfunktionen (in hellblauen Feldern) während der gesamten Trainingsphase des ML-Lebenszyklus.
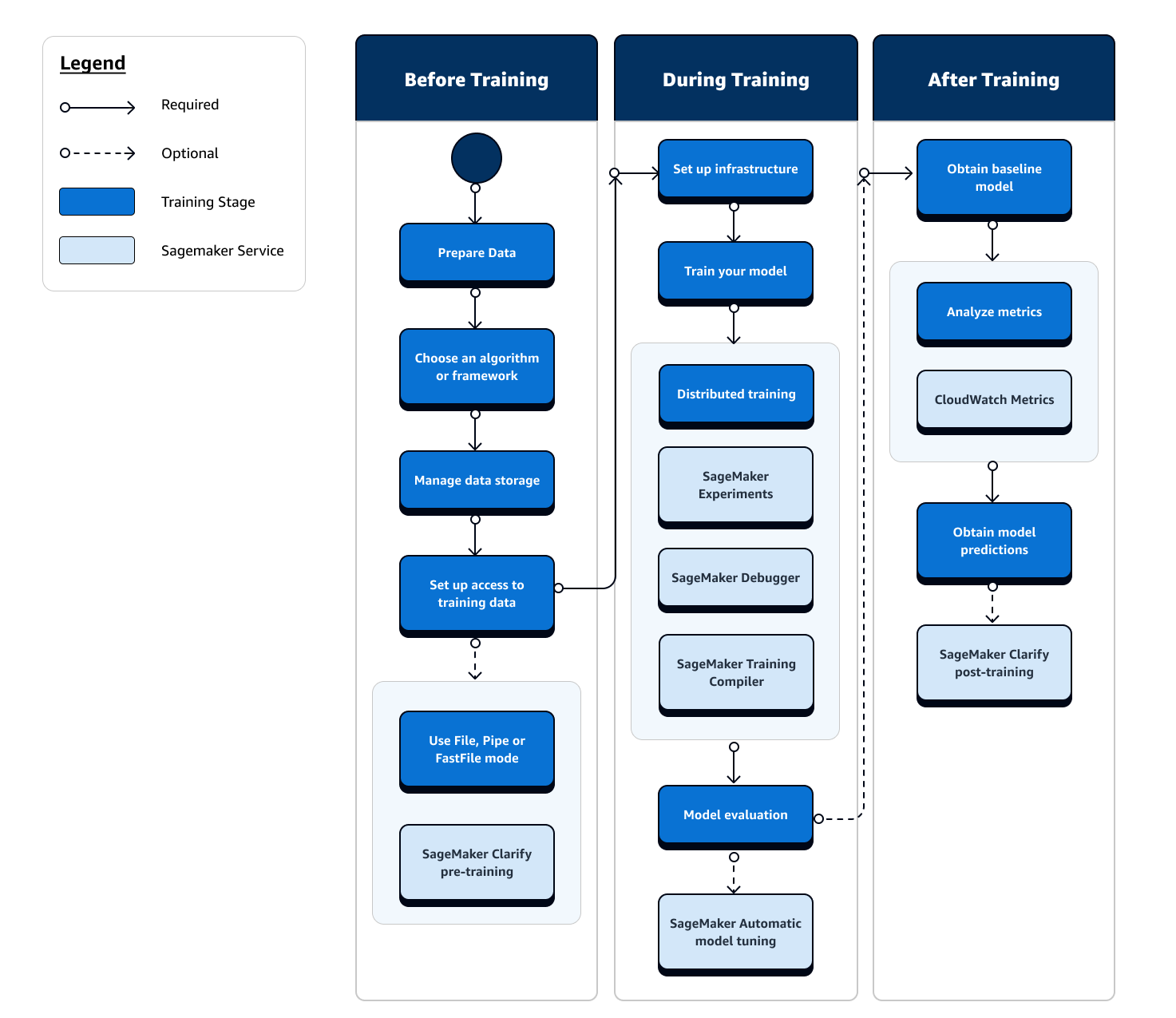
Die folgenden Abschnitte führen Sie durch die einzelnen Trainingsphasen, die im vorherigen Flussdiagramm dargestellt sind, sowie durch nützliche Funktionen, die SageMaker KI in den drei Unterphasen des ML-Trainings bietet.
Vor dem Training
Es gibt eine Reihe von Szenarien für die Einrichtung von Datenressourcen und den Zugriff, die Sie vor dem Training berücksichtigen müssen. Anhand des folgenden Diagramms und der Einzelheiten der einzelnen Phasen vor dem Training können Sie sich ein Bild davon machen, welche Entscheidungen Sie treffen müssen.
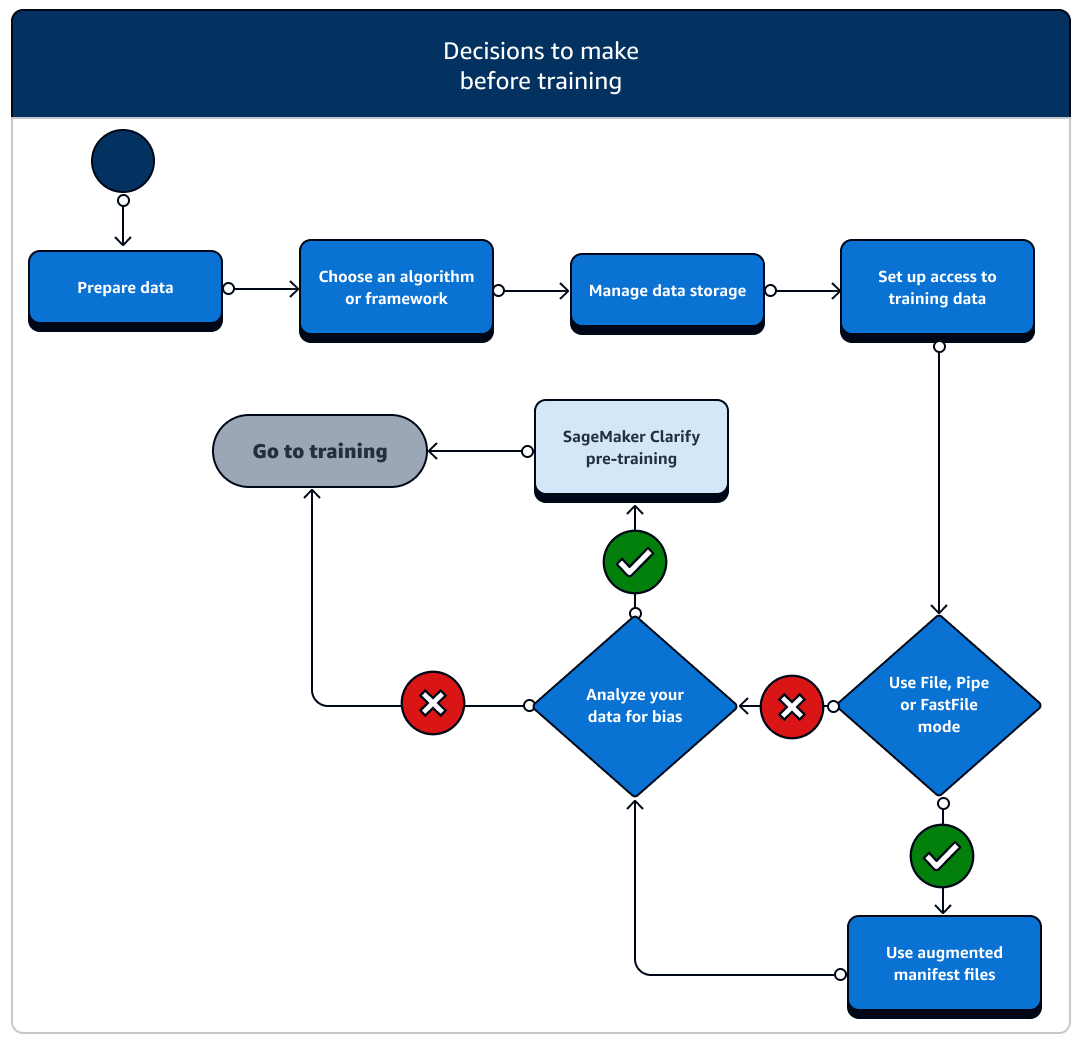
-
Daten vorbereiten: Vor dem Training müssen Sie die Datenbereinigung und das Feature-Engineering während der Datenvorbereitungsphase abgeschlossen haben. SageMaker KI verfügt über mehrere Tools für Kennzeichnung und Feature-Engineering, die Ihnen dabei helfen. Weitere Informationen finden Sie unter Daten kennzeichnen, Datensätze vorbereiten und analysieren, Daten verarbeiten und Funktionen erstellen, speichern und teilen.
-
Wählen Sie einen Algorithmus oder ein Framework: Je nachdem, wie viele Anpassungen Sie benötigen, gibt es unterschiedliche Optionen für Algorithmen und Frameworks.
-
Wenn Sie eine Low-Code-Implementierung eines vorgefertigten Algorithmus bevorzugen, verwenden Sie einen der von KI angebotenen integrierten Algorithmen. SageMaker Weitere Informationen finden Sie unter Auswahl eines Algorithmus.
-
Wenn Sie mehr Flexibilität bei der Anpassung Ihres Modells benötigen, führen Sie Ihr Trainingsskript mit Ihren bevorzugten Frameworks und Toolkits innerhalb von KI aus. SageMaker Weitere Informationen finden Sie unter ML Frameworks und Toolkits.
-
Informationen zur Erweiterung vorgefertigter SageMaker KI-Docker-Images als Basis-Image Ihres eigenen Containers finden Sie unter Verwenden von Pre-built SageMaker KI-Docker-Images.
-
Informationen dazu, wie Sie Ihren benutzerdefinierten Docker-Container auf SageMaker KI übertragen können, finden Sie unter Anpassen Ihres eigenen Docker-Containers für die Arbeit mit KI. SageMaker Sie müssen das sagemaker-training-toolkit
in Ihrem Container installieren.
-
-
Datenspeicher verwalten: Machen Sie sich mit der Zuordnung zwischen dem Datenspeicher (wie Amazon S3, Amazon EFS oder Amazon FSx) und dem Trainingscontainer vertraut, der in der Amazon EC2 EC2-Recheninstanz ausgeführt wird. SageMaker KI hilft dabei, die Speicherpfade und lokalen Pfade im Trainingscontainer abzubilden. Sie können sie auch manuell angeben. Nachdem das Mapping abgeschlossen ist, sollten Sie einen der Datenübertragungsmodi in Betracht ziehen: File, Pipe und FastFile Mode. Informationen dazu, wie SageMaker KI Speicherpfade zuordnet, finden Sie unter Speicherordner für Schulungen.
-
Richten Sie den Zugriff auf Trainingsdaten ein: Verwenden Sie eine Amazon SageMaker AI-Domain, ein Domain-Benutzerprofil, IAM und Amazon VPC, AWS KMS um die Anforderungen der sicherheitssensibelsten Organisationen zu erfüllen.
-
Informationen zur Kontoverwaltung finden Sie unter Amazon SageMaker AI-Domain.
-
Eine vollständige Referenz zu IAM-Richtlinien und -Sicherheit finden Sie unter Sicherheit in Amazon SageMaker AI.
-
-
Streamen Sie Ihre Eingabedaten: SageMaker AI bietet drei Dateneingabemodi: File, Pipe und FastFile. Der Standardeingabemodus ist der Dateimodus, bei dem der gesamte Datensatz während der Initialisierung des Trainingsjobs geladen wird. Allgemeine bewährte Methoden für das Streamen von Daten aus Ihrem Datenspeicher in den Trainingscontainer finden Sie unter Zugriff auf Trainingsdaten.
Im Pipe-Modus können Sie auch erwägen, eine erweiterte Manifestdatei zu verwenden, um Ihre Daten direkt von Amazon Simple Storage Service (Amazon S3) zu streamen und Ihr Modell zu trainieren. Durch die Verwendung des Pipe-Modus wird der Speicherplatz reduziert, da Amazon Elastic Block Store nur Ihre endgültigen Modellartefakte speichern muss, anstatt Ihren gesamten Trainingsdatensatz zu speichern. Weitere Informationen finden Sie unter Bereitstellen von Datensatz-Metadaten für Trainingsaufträge mit einer erweiterten Manifestdatei.
-
Analysieren Sie Ihre Daten auf Verzerrungen: Vor dem Training können Sie Ihren Datensatz und Ihr Modell auf Verzerrungen im Vergleich zu einer benachteiligten Gruppe analysieren, sodass Sie überprüfen können, ob Ihr Modell mithilfe von Clarify einen unverzerrten Datensatz lernt. SageMaker
-
Wählen Sie, welches SageMaker SDK Sie verwenden möchten: Es gibt zwei Möglichkeiten, einen Schulungsjob in SageMaker KI zu starten: mit dem SageMaker High-Level-AI-Python-SDK oder mit den SageMaker Low-Level-APIs für das SDK für Python (Boto3) oder das. AWS CLI Das SageMaker Python-SDK abstrahiert die SageMaker Low-Level-API, um praktische Tools bereitzustellen. Wie bereits unter erwähntDie grundlegende Architektur von SageMaker Training, können Sie mit SageMaker Canvas JumpStart in SageMaker Studio Classic oder AI Autopilot auch Optionen ohne Code oder mit minimalem Code verwenden. SageMaker
Während des Trainings
Während des Trainings müssen Sie die Trainingsstabilität, die Trainingsgeschwindigkeit und die Trainingseffizienz kontinuierlich verbessern und gleichzeitig die Rechenressourcen, die Kostenoptimierung und vor allem die Modellleistung skalieren. Lesen Sie weiter, um weitere Informationen zu Trainingsphasen und relevanten Trainingsfunktionen zu erhalten. SageMaker
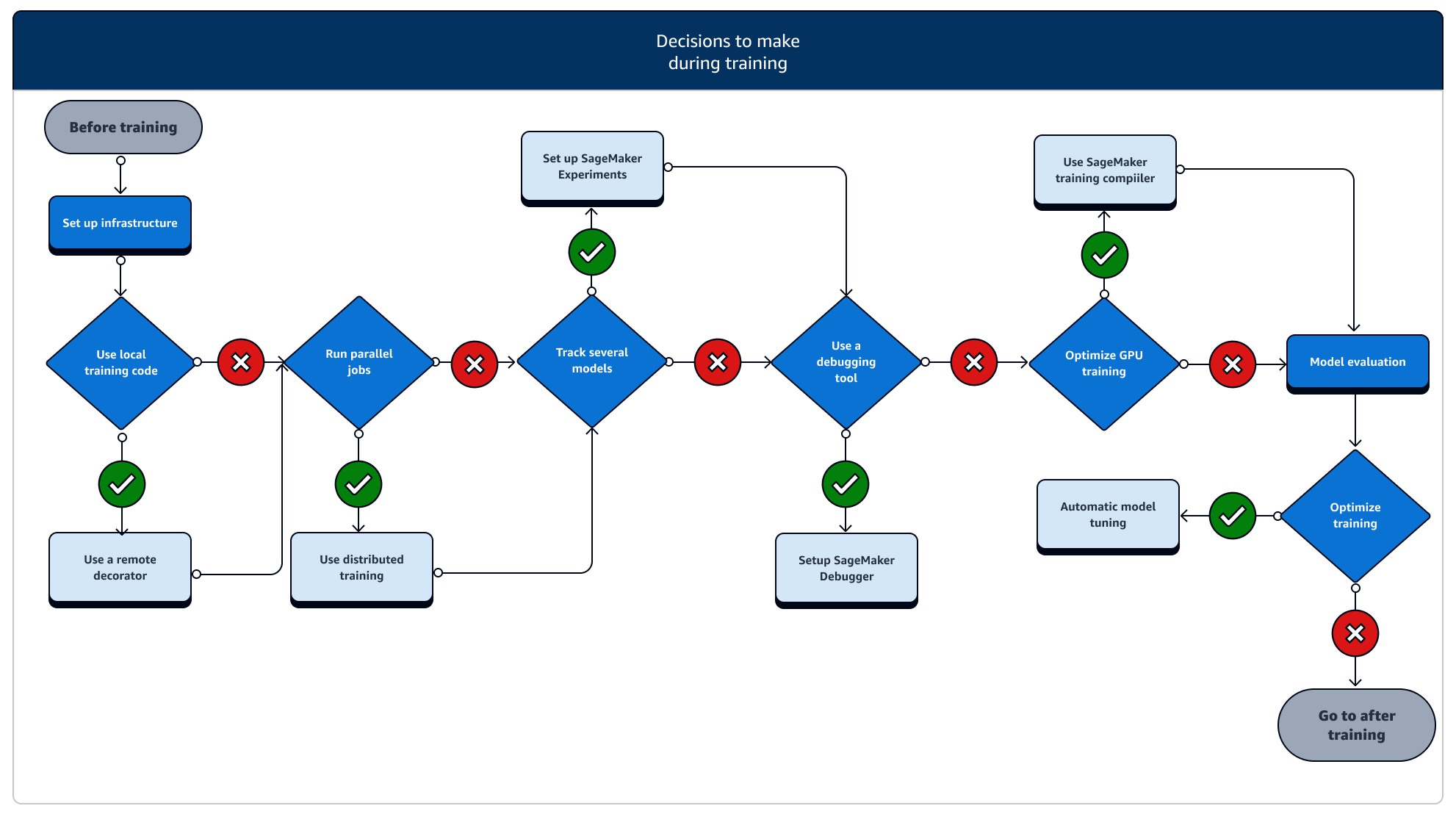
-
Infrastruktur einrichten: Wählen Sie den richtigen Instance-Typ und die richtigen Infrastrukturmanagement-Tools für Ihren Anwendungsfall aus. Sie können mit einer kleinen Instance beginnen und diese je nach Arbeitslast hochskalieren. Um ein Modell anhand eines tabellarischen Datensatzes zu trainieren, beginnen Sie mit der kleinsten CPU-Instance der C4- oder C5-Instance-Familien. Um ein großes Modell für Computer Vision oder Verarbeitung natürlicher Sprache zu trainieren, beginnen Sie mit der kleinsten GPU-Instance der P2-, P3-, G4dn- oder G5-Instance-Familien. Sie können auch verschiedene Instanztypen in einem Cluster mischen oder Instanzen mit den folgenden Instanzverwaltungstools, die von SageMaker AI angeboten werden, in warmen Pools speichern. Sie können auch persistenten Cache verwenden, um die Latenz und die abzurechnende Zeit bei iterativen Trainingsaufgaben zu reduzieren, anstatt die Latenz allein durch warme Pools zu reduzieren. Weitere Informationen finden Sie unter den folgenden Themen.
Sie müssen über ein ausreichendes Kontingent verfügen, um einen Trainingsjob ausführen zu können. Wenn Sie Ihren Trainingsjob auf einer Instance ausführen, für die das Kontingent nicht ausreicht, erhalten Sie eine
ResourceLimitExceeded-Fehlermeldung. Um die derzeit verfügbaren Kontingente in Ihrem Konto zu überprüfen, verwenden Sie Ihre Service Quotas-Konsole. Informationen zum Anfordern einer Kontingenterhöhung finden Sie unter Unterstützte Regionen und Quotas. Preisinformationen und je nach verfügbaren Instance-Typen finden Sie auch in den Tabellen auf der SageMaker Amazon-Preisseite . AWS-Regionen -
Führen Sie einen Trainingsjob von einem lokalen Code aus aus: Sie können Ihren lokalen Code mit einem Remote-Decorator kommentieren, um Ihren Code als SageMaker Trainingsjob in Amazon SageMaker Studio Classic, einem SageMaker Amazon-Notizbuch oder in Ihrer lokalen integrierten Entwicklungsumgebung auszuführen. Weitere Informationen finden Sie unter Führen Sie Ihren lokalen Code als SageMaker Trainingsjob aus.
-
Trainingsjobs nachverfolgen: Überwachen und verfolgen Sie Ihre Trainingsjobs mit SageMaker Experiments, SageMaker Debugger oder Amazon CloudWatch. Mithilfe von SageMaker KI-Experimenten können Sie die Leistung des Modells in Bezug auf Genauigkeit und Konvergenz beobachten und eine vergleichende Analyse der Metriken mehrerer Trainingsjobs durchführen. Sie können die Nutzungsrate der Rechenressourcen mithilfe der Profiling-Tools von SageMaker Debugger oder Amazon verfolgen. CloudWatch Weitere Informationen finden Sie unter den folgenden Themen.
Verwenden Sie für Deep-Learning-Aufgaben außerdem die Debugging-Tools und integrierten Regeln von Amazon SageMaker Debugger, um komplexere Probleme bei der Modellkonvergenz und Gewichtsupdate zu identifizieren.
-
Verteiltes Training: Wenn Ihr Trainingsjob in eine stabile Phase übergeht, ohne dass er aufgrund einer Fehlkonfiguration der Trainingsinfrastruktur oder aufgrund von Speicherproblemen unterbrochen wird, sollten Sie nach weiteren Optionen suchen, um Ihren Job zu skalieren und über einen längeren Zeitraum von Tagen oder sogar Monaten zu laufen. Wenn Sie bereit sind, zu skalieren, sollten Sie verteilte Schulungen in Betracht ziehen. SageMaker KI bietet verschiedene Optionen für verteilte Berechnungen, von leichten ML-Workloads bis hin zu schweren Deep-Learning-Workloads.
Bei Deep-Learning-Aufgaben, bei denen sehr große Modelle auf sehr großen Datensätzen trainiert werden, sollten Sie erwägen, eine der verteilten SageMaker KI-Trainingsstrategien zu verwenden, um zu skalieren und Datenparallelität, Modellparallelität oder eine Kombination aus beiden zu erreichen. Sie können den SageMaker Training Compiler auch zum Kompilieren und Optimieren von Modelldiagrammen auf GPU-Instanzen verwenden. Diese SageMaker KI-Funktionen unterstützen Deep-Learning-Frameworks wie PyTorch TensorFlow, und Hugging Face Transformers.
-
Modell-Hyperparameter-Tuning: Optimieren Sie Ihre Modell-Hyperparameter mithilfe der automatischen Modelloptimierung mit KI. SageMaker SageMaker KI bietet Hyperparameter-Tuning-Methoden wie Grid-Suche und Bayes-Suche und startet parallel Hyperparameter-Tuning-Jobs mit Early-Stopp-Funktionalität für Hyperparameter-Tuning-Jobs, die sich nicht verbessern.
-
Verwenden von Prüfpunkten und Kosteneinsparung mit Spot-Instances: Wenn Trainingszeit kein großes Problem darstellt, könnten Sie erwägen, die Kosten für das Modelltraining mit verwalteten Spot-Instances zu optimieren. Beachten Sie, dass Sie Checkpointing für Spot-Trainings aktivieren müssen, um die Wiederherstellung nach zeitweiligen Job-Pausen aufgrund des Austauschs von Spot-Instances aufrechtzuerhalten. Sie können die Checkpoint-Funktion auch verwenden, um Ihre Modelle für den Fall einer unerwarteten Kündigung des Trainingsauftrags zu sichern. Weitere Informationen finden Sie unter den folgenden Themen.
Nach dem Training
Nach dem Training erhalten Sie ein fertiges Modellartefakt, das Sie für die Modellbereitstellung und Inferenz verwenden können. In der Phase nach dem Training sind weitere Maßnahmen erforderlich, wie im folgenden Diagramm veranschaulicht.
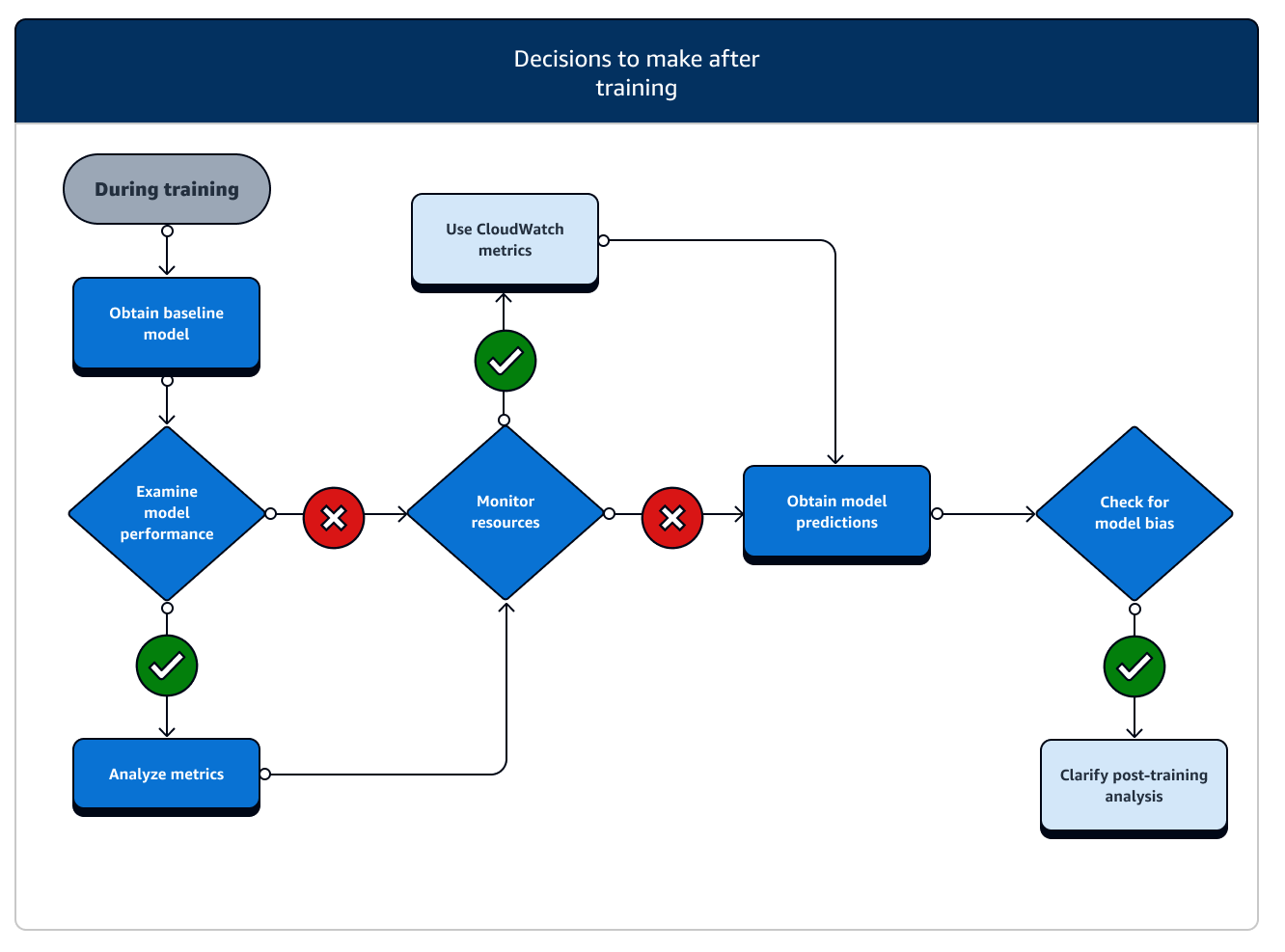
-
Basismodell abrufen: Nachdem Sie das Modellartefakt haben, können Sie es als Basismodell festlegen. Ziehen Sie die folgenden Maßnahmen nach dem Training und der Verwendung von SageMaker KI-Funktionen in Betracht, bevor Sie mit der Bereitstellung des Modells in der Produktion fortfahren.
-
Untersuchen Sie die Modellleistung und prüfen Sie, ob sie verzerrt ist: Verwenden Sie Amazon CloudWatch Metrics und SageMaker Clarify für Verzerrungen nach dem Training, um jegliche Verzerrungen in den eingehenden Daten zu erkennen und im Laufe der Zeit im Vergleich zum Ausgangswert zu modellieren. Sie müssen Ihre neuen Daten und Modellprognosen regelmäßig oder in Echtzeit anhand der neuen Daten auswerten. Mithilfe dieser Funktionen können Sie Benachrichtigungen über akute Veränderungen oder Anomalien sowie über allmähliche Änderungen oder Abweichungen von Daten und Modellen erhalten.
-
Sie können auch die Funktion Inkrementelles Training von SageMaker KI verwenden, um Ihr Modell mit einem erweiterten Datensatz zu laden und zu aktualisieren (oder eine Feinabstimmung vorzunehmen).
-
Sie können das Modelltraining als einen Schritt in Ihrer SageMaker KI-Pipeline oder als Teil anderer von KI angebotener Workflow-Funktionen registrieren, um den gesamten ML-Lebenszyklus zu orchestrieren. SageMaker
