Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen eines benutzerdefinierten Sprachmodells
Bevor Sie Ihr benutzerdefiniertes Sprachmodell erstellen können, müssen Sie:
-
Bereiten Sie Ihre Daten vor. Die Daten müssen im reinen Textformat gespeichert werden und dürfen keine Sonderzeichen enthalten.
-
Laden Sie Ihre Daten in einen Amazon S3 Bucket hoch. Es wird empfohlen, getrennte Ordner für Trainings- und Tuningdaten anzulegen.
-
Stellen Sie sicher, Amazon Transcribe dass Sie Zugriff auf Ihren Amazon S3 Bucket haben. Sie müssen eine IAM Rolle angeben, die über Zugriffsberechtigungen für die Verwendung Ihrer Daten verfügt.
Aufbereitung Ihrer Daten
Sie können alle Ihre Daten in einer Datei zusammenfassen oder in mehreren Dateien speichern. Beachten Sie, dass die Abstimmungsdaten in einer von den Trainingsdaten getrennten Datei gespeichert werden müssen, wenn Sie sie einbeziehen möchten.
Es spielt keine Rolle, wie viele Textdateien Sie für Ihre Trainings- oder Tuningdaten verwenden. Das Hochladen einer Datei mit 100.000 Wörtern ergibt das gleiche Ergebnis wie das Hochladen von 10 Dateien mit 10.000 Wörtern. Bereiten Sie Ihre Textdaten so auf, wie es für Sie am bequemsten ist.
Vergewissern Sie sich, dass alle Ihre Datendateien die folgenden Kriterien erfüllen:
-
Sie sind alle in der gleichen Sprache wie das Modell, das Sie erstellen möchten. Wenn Sie beispielsweise ein benutzerdefiniertes Sprachmodell erstellen möchten, das Audio in US-Englisch transkribiert (
en-US), müssen alle Ihre Textdaten in US-Englisch sein. -
Sie sind im Klartextformat mit UTF-8 Kodierung.
-
Sie enthalten keine Sonderzeichen oder Formatierungen, wie z. B. HTML-Tags.
-
Sie sind zusammen maximal 2 GB groß für Trainingsdaten und 200 MB für Tuningdaten.
Wenn eines dieser Kriterien nicht erfüllt ist, schlägt Ihr Modell fehl.
Hochladen Ihrer Daten
Bevor Sie Ihre Daten hochladen, erstellen Sie einen neuen Ordner für Ihre Trainingsdaten. Wenn Sie Tuning-Daten verwenden, erstellen Sie einen weiteren separaten Ordner.
Die URIs für Ihre Buckets könnten wie folgt aussehen:
-
s3://amzn-s3-demo-bucket/my-model-training-data/ -
s3://amzn-s3-demo-bucket/my-model-tuning-data/
Laden Sie Ihre Trainings- und Abstimmungsdaten in die entsprechenden Buckets hoch.
Sie können zu einem späteren Zeitpunkt weitere Daten zu diesen Buckets hinzufügen. In diesem Fall müssen Sie Ihr Modell jedoch mit den neuen Daten neu erstellen. Bestehende Modelle können nicht mit neuen Daten aktualisiert werden.
Ermöglichung des Zugangs zu Ihren Daten
Um ein benutzerdefiniertes Sprachmodell zu erstellen, müssen Sie eine IAM Rolle angeben, die über Berechtigungen für den Zugriff auf Ihren Amazon S3 Bucket verfügt. Wenn Sie noch keine Rolle mit Zugriff auf den Amazon S3 Bucket haben, in dem Sie Ihre Trainingsdaten abgelegt haben, müssen Sie eine erstellen. Nachdem Sie eine Rolle erstellt haben, können Sie eine Richtlinie anhängen, um dieser Rolle Berechtigungen zu erteilen. Weisen Sie einem Benutzer keine Richtlinie zu.
Beispiele für Richtlinien finden Sie unter Amazon Transcribe Beispiele für identitätsbasierte Politik.
Informationen zum Erstellen einer neuen IAM Identität finden Sie unter IAM Identitäten (Benutzer, Benutzergruppen und Rollen).
Weitere Informationen zur Richtlinie finden Sie unter:
Erstellen eines eigenen Sprachmodells
Wenn Sie Ihr eigenes Sprachmodell erstellen, müssen Sie ein Basismodell wählen. Es gibt zwei Optionen für das Basismodell:
-
NarrowBand: Verwenden Sie diese Option für Audio mit einer Samplerate von weniger als 16.000 Hz. Dieser Modelltyp wird in der Regel für Telefongespräche verwendet, die mit 8.000 Hz aufgezeichnet werden. -
WideBand: Verwenden Sie diese Option für Audiodaten mit einer Samplerate größer oder gleich 16.000 Hz.
Mithilfe der AWS SDKs AWS-Managementkonsole AWS CLI, oder können Sie benutzerdefinierte Sprachmodelle erstellen. Weitere Beispiele finden Sie in den folgenden Beispielen:
-
Melden Sie sich an der AWS-Managementkonsole
an. -
Wählen Sie im Navigationsbereich die Option Benutzerdefiniertes Sprachmodell. Dadurch wird die Seite Benutzerdefinierte Sprachmodelle geöffnet, auf der Sie vorhandene benutzerdefinierte Sprachmodelle anzeigen oder ein neues benutzerdefiniertes Sprachmodell trainieren können.
-
Um ein neues Modell zu trainieren, wählen Sie Modell trainieren.
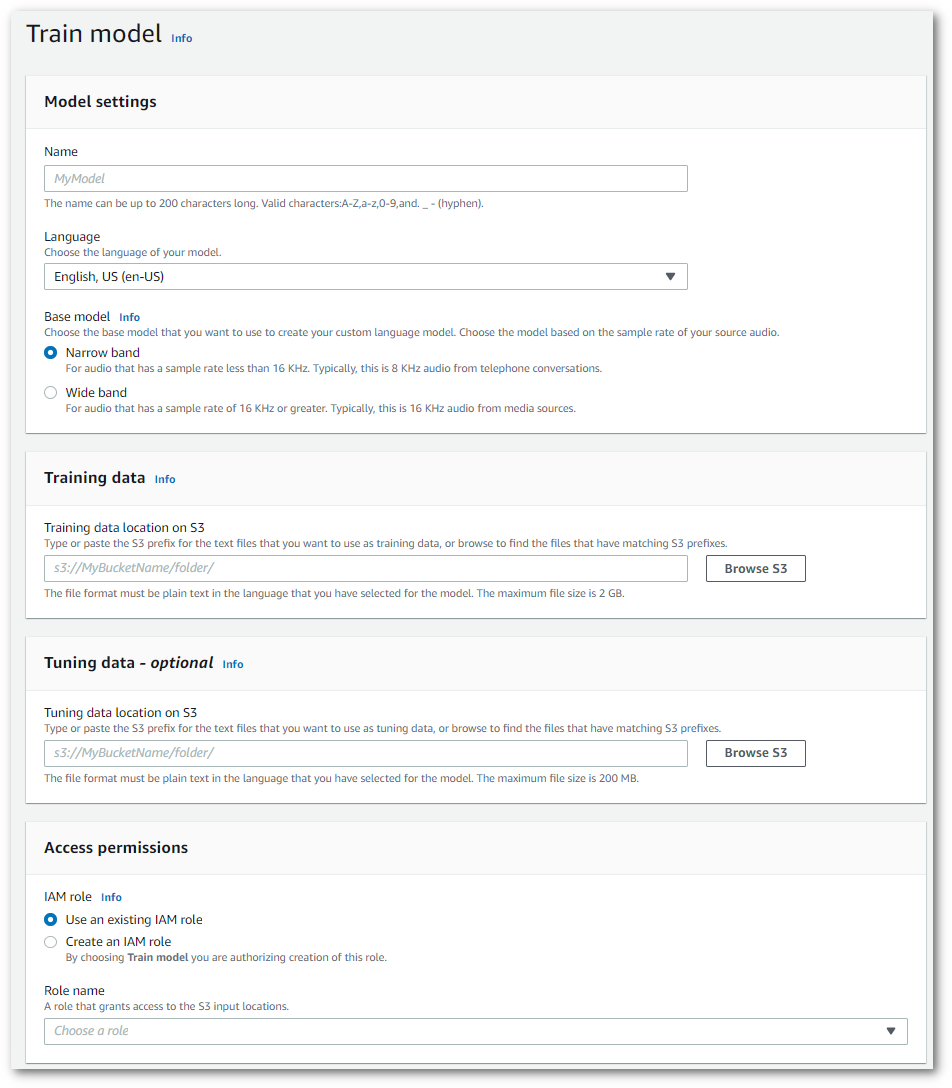
Dies führt Sie zur Seite Zugmodell. Fügen Sie einen Namen hinzu, geben Sie die Sprache an, und wählen Sie das gewünschte Basismodell für Ihr Modell. Fügen Sie dann den Pfad zu Ihren Trainings- und optional zu Ihren Tuning-Daten hinzu. Sie müssen eine IAM Rolle angeben, die über Berechtigungen für den Zugriff auf Ihre Daten verfügt.
-
Wenn Sie alle Felder ausgefüllt haben, wählen Sie unten auf der Seite das Zugmodell aus.
In diesem Beispiel wird der Befehl create-language-modelCreateLanguageModel und LanguageModel.
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://amzn-s3-demo-bucket/my-clm-training-data/,TuningDataS3Uri=s3://amzn-s3-demo-bucket/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
Hier ein weiteres Beispiel mit dem Befehl create-language-model
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
Die Datei my-first-language-model.json enthält den folgenden Anforderungstext.
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://amzn-s3-demo-bucket/my-clm-training-data/", "TuningDataS3Uri"="s3://amzn-s3-demo-bucket/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
In diesem Beispiel wird mithilfe der Methode AWS SDK für Python (Boto3) create_language_model ein CLM erstellt.CreateLanguageModel und LanguageModel.
Weitere Beispiele für die Verwendung der AWS SDKs, einschließlich funktionsspezifischer, szenarienspezifischer und serviceübergreifender Beispiele, finden Sie im Kapitel. Codebeispiele für Amazon Transcribe mit AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://amzn-s3-demo-bucket/my-clm-training-data/', 'TuningDataS3Uri':'s3://amzn-s3-demo-bucket/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Aktualisierung des benutzerdefinierten Sprachmodells
Amazon Transcribe aktualisiert kontinuierlich die für benutzerdefinierte Sprachmodelle verfügbaren Basismodelle. Um von diesen Aktualisierungen zu profitieren, empfehlen wir, alle 6 bis 12 Monate neue benutzerdefinierte Sprachmodelle zu trainieren.
Um zu sehen, ob Ihr benutzerdefiniertes Sprachmodell das neueste Basismodell verwendet, führen Sie eine DescribeLanguageModelAnfrage mit dem AWS CLI oder einem AWS SDK aus und suchen Sie dann das UpgradeAvailability Feld in Ihrer Antwort.
Wenn UpgradeAvailability true lautet, läuft auf Ihrem Modell nicht die neueste Version des Basismodells. Um das neueste Basismodell in einem benutzerdefinierten Sprachmodell zu verwenden, müssen Sie ein neues benutzerdefiniertes Sprachmodell erstellen. Benutzerdefinierte Sprachmodelle können nicht aktualisiert werden.
