Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Sprachidentifizierung mit Batch-Transkriptionsaufträgen
Verwenden Sie die Batch-Sprachidentifizierung, um die Sprache(n) in Ihrer Mediendatei automatisch zu identifizieren.
Wenn Ihre Medien nur eine Sprache enthalten, können Sie die einsprachige Identifizierung aktivieren, die die dominante Sprache identifiziert, die in Ihrer Mediendatei gesprochen wird und Ihr Transkript nur mit dieser Sprache erstellt.
Wenn Ihre Medien mehr als eine Sprache enthalten, können Sie die mehrsprachige Identifizierung aktivieren, die alle in Ihrer Mediendatei gesprochenen Sprachen identifiziert und Ihr Transkript unter Verwendung jeder identifizierten Sprache erstellt. Beachten Sie, dass ein mehrsprachiges Transkript erstellt wird. Sie können andere Dienste nutzen, z. B. Amazon Translate um Ihr Transkript zu übersetzen.
In der Tabelle der unterstützten Sprachen finden Sie eine vollständige Liste der unterstützten Sprachen und der zugehörigen Sprachcodes.
Um optimale Ergebnisse zu erzielen, sollten Sie sicherstellen, dass Ihre Mediendatei mindestens 30 Sekunden Sprache enthält.
Anwendungsbeispiele mit dem AWS Management Console, AWS CLI, und dem AWS Python-SDK finden Sie unterSprachidentifizierung mit Batch-Transkriptionen.
Identifizierung von Sprachen in mehrsprachigen Audiodateien
Multi-language Die Identifizierung ist für mehrsprachige Mediendateien vorgesehen und bietet Ihnen ein Transkript, das alle unterstützten Sprachen wiedergibt, die in Ihren Medien gesprochen werden. Das bedeutet, dass Ihre Transkriptionsausgabe jede Sprache korrekt erkennt und transkribiert, wenn die Sprecher während des Gesprächs die Sprache wechseln oder wenn jeder Teilnehmer eine andere Sprache spricht. Wenn Ihre Medien beispielsweise einen zweisprachigen Sprecher enthalten, der abwechselnd in US-Englisch (en-US) und Hindi (hi-IN) spricht, kann die Mehrsprachenerkennung gesprochenes US-Englisch als en-US und gesprochenes Hindi als hi-IN identifizieren und transkribieren.
Dies unterscheidet sich von der einsprachigen Identifizierung, bei der nur eine dominante Sprache zur Erstellung eines Transkripts verwendet wird. In diesem Fall wird jede gesprochene Sprache, die nicht die dominante Sprache ist, falsch transkribiert.
Anmerkung
Schwärzen und benutzerdefinierte Sprachmodelle werden derzeit bei mehrsprachiger Identifizierung nicht unterstützt.
Anmerkung
Die folgenden Sprachen werden derzeit mit mehrsprachiger Identifizierung unterstützt: en-AB, en-AU, en-GB, en-IE, en-NZ, en-US, en-WL, en-ZA, es-ES, es-US, fr-CA, fr-FR, zh-CN, zh-TW, pt-BR, pt-PT, de-CH, de-DE, Af-ZA, ar-AE, da-DK, He-IL, He-IL, Hi-IN, ID-ID, fa-IR, it-IT, jA-JP, ko-KR, MS-MY, nl-NL, ru-RU, Ta-in, Te-in, Th-TR, tr-TR
Multi-language Transkripte bieten eine Zusammenfassung der erkannten Sprachen und die Gesamtzeit, in der jede Sprache in Ihren Medien gesprochen wurde. Hier ein Beispiel:
"results": { "transcripts": [ { "transcript": "welcome to Amazon transcribe. ये तो उदाहरण हैं क्या कैसे कर सकते हैं ।一つのファイルに複数の言語を書き写す" } ],..."language_codes": [ { "language_code": "en-US", "duration_in_seconds": 2.45 }, { "language_code": "hi-IN", "duration_in_seconds": 5.325 }, { "language_code": "ja-JP", "duration_in_seconds": 4.15 } ] }
Verbesserung der Genauigkeit der Sprachidentifizierung
Bei der Sprachidentifizierung haben Sie die Möglichkeit, eine Liste von Sprachen anzugeben, von denen Sie glauben, dass sie in Ihren Medien vorkommen könnten. Durch das Einbeziehen von Sprachoptionen (LanguageOptions) Amazon Transcribe werden nur die Sprachen verwendet, die Sie bei der Zuordnung Ihres Audiomaterials zur richtigen Sprache angegeben haben. Dadurch kann die Sprachenerkennung beschleunigt und die Genauigkeit bei der Zuweisung des richtigen Sprachdialekts verbessert werden.
Wenn Sie Sprachcodes angeben möchten, müssen Sie mindestens zwei angeben. Es gibt keine Begrenzung für die Anzahl der Sprachcodes, die Sie einfügen können, aber wir empfehlen, zwischen zwei und fünf zu verwenden, um optimale Effizienz und Genauigkeit zu erzielen.
Anmerkung
Wenn Sie Ihrer Anfrage Sprachcodes beifügen und keiner der von Ihnen angegebenen Sprachcodes mit der Sprache oder den Sprachen übereinstimmt, die in Ihrem Audio identifiziert wurden, wird aus den von Ihnen angegebenen Sprachcodes die Sprache Amazon Transcribe ausgewählt, die am ehesten entspricht. Es wird dann eine Transkription in dieser Sprache erstellt. Wenn Ihre Medien beispielsweise in US-Englisch (en-US) verfasst sind und Sie die Sprachcodes angebenzh-CN, Amazon Transcribe ist es wahrscheinlichfr-FR, dass Ihre Medien Amazon Transcribe mit Deutsch (de-DE) übereinstimmen und eine German-language Transkription erstellt wird. de-DE Wenn Sprachcodes und gesprochene Sprachen nicht übereinstimmen, kann dies zu einem ungenauen Transkript führen, weshalb wir bei der Angabe von Sprachcodes zur Vorsicht raten.
Kombination der Sprachenidentifikation mit anderen Amazon Transcribe features
Sie können die Batch-Sprachidentifizierung in Kombination mit jedem anderen Amazon Transcribe
-Feature verwenden. Wenn Sie die Sprachidentifizierung mit anderen Features kombinieren, sind Sie auf die Sprachen beschränkt, die von diesen Features unterstützt werden. Wenn Sie beispielsweise die Sprachenidentifikation zusammen mit der Inhaltsredaktion verwenden, sind Sie auf US-Englisch (en-US) oder US-Spanisch (es-US) beschränkt, da dies nur die Sprache ist, die für die Schwärzung verfügbar ist. Weitere Informationen finden Sie unter Unterstützte Sprachen und sprachspezifische Funktionen.
Wichtig
Wenn Sie die automatische Sprachenerkennung mit aktivierter Inhaltsredaktion verwenden und Ihr Audio andere Sprachen als US-Englisch (en-US) oder US-Spanisch (es-US) enthält, werden in Ihrem Transkript nur die Inhalte in US-Englisch oder US-Spanisch redigiert. Andere Sprachen können nicht geschwärzt werden, und es gibt keine Warnungen oder Fehlschläge.
Benutzerdefinierte Sprachmodelle, benutzerdefinierte Vokabulare und benutzerdefinierte Wortschatzfilter
Wenn Sie ein oder mehrere benutzerdefinierte Sprachmodelle, benutzerdefinierte Vokabulare oder benutzerdefinierte Wortschatzfilter zu Ihrer Sprachidentifikationsanfrage hinzufügen möchten, müssen Sie den LanguageIdSettings-Parameter enthalten. Sie können dann einen Sprachcode mit einem entsprechenden benutzerdefinierten Sprachmodell, einem benutzerdefinierten Vokabular und einem benutzerdefinierten Wortschatzfilter angeben. Beachten Sie, dass die mehrsprachige Identifizierung keine benutzerdefinierten Sprachmodelle unterstützt.
Es wird empfohlen, dass Sie LanguageOptions einschließen, wenn Sie LanguageIdSettings verwenden, um sicherzustellen, dass der richtige Sprachdialekt erkannt wird. Wenn Sie beispielsweise ein en-US benutzerdefiniertes Vokabular angeben, aber Amazon Transcribe feststellen, dass es sich bei der in Ihren Medien gesprochenen Sprache um dieses handelten-AU, wird Ihr benutzerdefiniertes Vokabular nicht auf Ihre Transkription angewendet. Wenn Sie LanguageOptions einschließen und en-US als einzigen englischen Dialekt angeben, wird Ihr benutzerdefiniertes Vokabular auf Ihre Transkription angewendet.
Für Beispiele von LanguageIdSettings in einer Anfrage finden Sie unter Option 2 in den SDKs AWS CLI und AWS in den Dropdown-Bereichen im Abschnitt Sprachidentifizierung mit Batch-Transkriptionen.
Sprachidentifizierung mit Batch-Transkriptionen
Sie können die automatische Sprachidentifizierung in einem Batch-Transkriptionsauftrag mithilfe der AWS -, AWS Management Console- oder AWS CLI-SDKs verwenden. Beispiele finden Sie im Folgenden:
-
Melden Sie sich an der AWS Management Console
an. -
Wählen Sie im Navigationsbereich Transkriptionsaufträge und dann Auftrag erstellen (oben rechts). Dies öffnet die Seite Auftragsdetails angeben.
-
Suchen Sie im Bereich Auftragseinstellungen den Abschnitt Spracheinstellungen und wählen Sie Automatische Sprachidentifizierung oder Automatische Mehrsprachenidentifizierung.
Sie haben die Möglichkeit, mehrere Sprachen auszuwählen (aus dem Dropdown-Feld Sprachen auswählen), wenn Sie wissen, welche Sprachen in Ihrer Audiodatei enthalten sind. Die Bereitstellung von Sprachoptionen kann die Genauigkeit verbessern, ist aber nicht erforderlich.
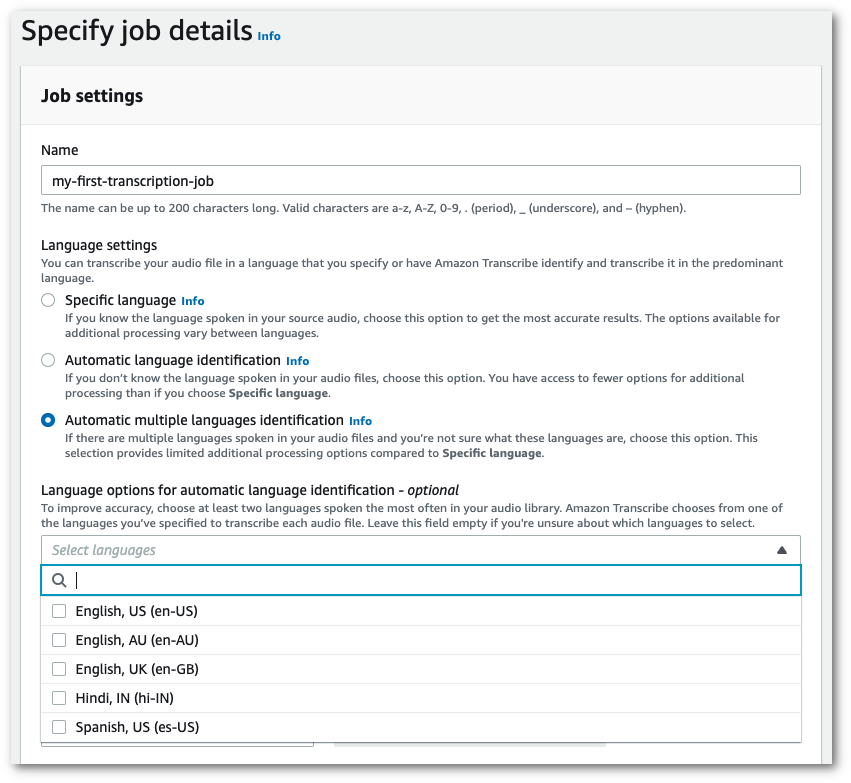
-
Füllen Sie alle anderen Felder aus, die Sie auf der Seite Auftragsdetails angeben möchten, und wählen Sie dann Weiter. Dadurch gelangen Sie zur Seite Auftrag konfigurieren – optional.
-
Wählen Sie Auftrag erstellen, um Ihren Transkriptionsauftrag auszuführen.
In diesem Beispiel werden der Befehl start-Transkription-jobIdentifyLanguage verwendet. Weitere Informationen erhalten Sie unter StartTranscriptionJob und LanguageIdSettings.
Option 1: Ohne den Parameter language-id-settings. Verwenden Sie diese Option, wenn Sie kein benutzerdefiniertes Sprachmodell, kein benutzerdefiniertes Vokabular und keinen benutzerdefinierten Wortschatzfilter in Ihre Anfrage aufnehmen. language-options ist optional, wird aber empfohlen.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) \ --language-options "en-US" "hi-IN"
Option 2: Mit dem Parameter language-id-settings. Verwenden Sie diese Option, wenn Sie ein benutzerdefiniertes Sprachmodell, ein benutzerdefiniertes Vokabular oder einen benutzerdefinierten Wortschatzfilter in Ihre Anfrage aufnehmen.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) --language-options "en-US" "hi-IN" \ --language-id-settingsen-US=VocabularyName=my-en-US-vocabulary,en-US=VocabularyFilterName=my-en-US-vocabulary-filter,en-US=LanguageModelName=my-en-US-language-model,hi-IN=VocabularyName=my-hi-IN-vocabulary,hi-IN=VocabularyFilterName=my-hi-IN-vocabulary-filter
Hier ein weiteres Beispiel mit dem Befehl start-Transkription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-language-id-job.json
Die Datei my-first-language-id-job.json enthält den folgenden Anforderungstext.
Option 1: Ohne den Parameter LanguageIdSettings. Verwenden Sie diese Option, wenn Sie kein benutzerdefiniertes Sprachmodell, kein benutzerdefiniertes Vokabular und keinen benutzerdefinierten Wortschatzfilter in Ihre Anfrage aufnehmen. LanguageOptions ist optional, wird aber empfohlen.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true), "LanguageOptions": [ "en-US", "hi-IN" ] }
Option 2: Mit dem Parameter LanguageIdSettings. Verwenden Sie diese Option, wenn Sie ein benutzerdefiniertes Sprachmodell, ein benutzerdefiniertes Vokabular oder einen benutzerdefinierten Wortschatzfilter in Ihre Anfrage aufnehmen.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true) "LanguageOptions": [ "en-US", "hi-IN" ], "LanguageIdSettings": { "en-US" : { "LanguageModelName": "my-en-US-language-model", "VocabularyFilterName": "my-en-US-vocabulary-filter", "VocabularyName": "my-en-US-vocabulary" }, "hi-IN": { "VocabularyName": "my-hi-IN-vocabulary", "VocabularyFilterName": "my-hi-IN-vocabulary-filter" } } }
In diesem Beispiel wird die AWS SDK für Python (Boto3) Sprache Ihrer Datei mithilfe des IdentifyLanguage Arguments für die Methode start_transcription_jobStartTranscriptionJob und LanguageIdSettings.
Weitere Beispiele für die Verwendung der AWS SDKs, einschließlich funktionsspezifischer, szenarienspezifischer und serviceübergreifender Beispiele, finden Sie im Kapitel. Codebeispiele für Amazon Transcribe mit AWS SDKs
Option 1: Ohne den Parameter LanguageIdSettings. Verwenden Sie diese Option, wenn Sie kein benutzerdefiniertes Sprachmodell, kein benutzerdefiniertes Vokabular und keinen benutzerdefinierten Wortschatzfilter in Ihre Anfrage aufnehmen. LanguageOptions ist optional, wird aber empfohlen.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', MediaFormat = 'flac', IdentifyLanguage =True, (or IdentifyMultipleLanguages =True), LanguageOptions = [ 'en-US', 'hi-IN' ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Option 2: Mit dem Parameter LanguageIdSettings. Verwenden Sie diese Option, wenn Sie ein benutzerdefiniertes Sprachmodell, ein benutzerdefiniertes Vokabular oder einen benutzerdefinierten Wortschatzfilter in Ihre Anfrage aufnehmen.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', MediaFormat='flac', IdentifyLanguage=True, (or IdentifyMultipleLanguages=True) LanguageOptions = [ 'en-US', 'hi-IN' ], LanguageIdSettings={ 'en-US': { 'VocabularyName': 'my-en-US-vocabulary', 'VocabularyFilterName': 'my-en-US-vocabulary-filter', 'LanguageModelName': 'my-en-US-language-model' }, 'hi-IN': { 'VocabularyName': 'my-hi-IN-vocabulary', 'VocabularyFilterName': 'my-hi-IN-vocabulary-filter' } } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
