Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Weltweite Dienste
Zusätzlich zu den regionalen und zonalen AWS Diensten gibt es eine kleine Gruppe von AWS Diensten, deren Steuerungsebenen und Datenebenen nicht in jeder Region unabhängig voneinander existieren. Da ihre Ressourcen nicht regionsspezifisch sind, werden sie allgemein als global bezeichnet. Globale AWS Dienste folgen immer noch dem herkömmlichen AWS Entwurfsmuster, bei dem die Steuerungsebene und die Datenebene getrennt werden, um statische Stabilität zu erreichen. Der wesentliche Unterschied bei den meisten globalen Diensten besteht darin, dass ihre Steuerungsebene auf einer einzigen Ebene gehostet wird AWS-Region, während ihre Datenebene global verteilt ist. Es gibt drei verschiedene Arten von globalen Diensten und eine Reihe von Diensten, die je nach der von Ihnen ausgewählten Konfiguration global erscheinen können.
In den folgenden Abschnitten werden die einzelnen Arten von globalen Diensten und die Trennung ihrer Steuerungsebenen und Datenebenen beschrieben. Anhand dieser Informationen können Sie sich beim Aufbau zuverlässiger Mechanismen für Hochverfügbarkeit (HA) und Notfallwiederherstellung (DR) orientieren, ohne auf eine globale Service-Kontrollebene angewiesen zu sein. Dieser Ansatz trägt dazu bei, einzelne Fehlerquellen in Ihrer Architektur zu beseitigen und mögliche regionsübergreifende Auswirkungen zu vermeiden, selbst wenn Sie in einer Region tätig sind, die sich von der Region unterscheidet, in der sich die globale Servicesteuerungsebene befindet. Es hilft Ihnen auch dabei, Failover-Mechanismen sicher zu implementieren, die nicht auf globale Servicesteuerungsebenen angewiesen sind.
Globale Dienste, die je nach Partition einzigartig sind
In jeder Partition gibt es einige globale AWS Dienste (in diesem paper als partitionelle Dienste bezeichnet). Partitionale Dienste stellen ihre Steuerungsebene in einer einzigen bereit. AWS-Region Einige partitionelle Dienste, wie AWS Network Manager, sind nur auf der Kontrollebene verfügbar und orchestrieren die Datenebene anderer Dienste. Andere partitionelle Dienste, wie z. B.IAM, verfügen über eine eigene Datenebene, die isoliert und auf alle Daten in der Partition verteilt ist. AWS-Regionen Fehler in einem partitionellen Dienst wirken sich nicht auf andere Partitionen aus. In der aws Partition befindet sich die Steuerungsebene des IAM Dienstes in der us-east-1 Region, mit isolierten Datenebenen in jeder Region der Partition. Partitionale Dienste verfügen außerdem über unabhängige Steuerungsebenen und Datenebenen in den aws-cn Partitionen aws-us-gov und. Die Trennung von Steuerungsebene und Datenebene für IAM ist in der folgenden Abbildung dargestellt.
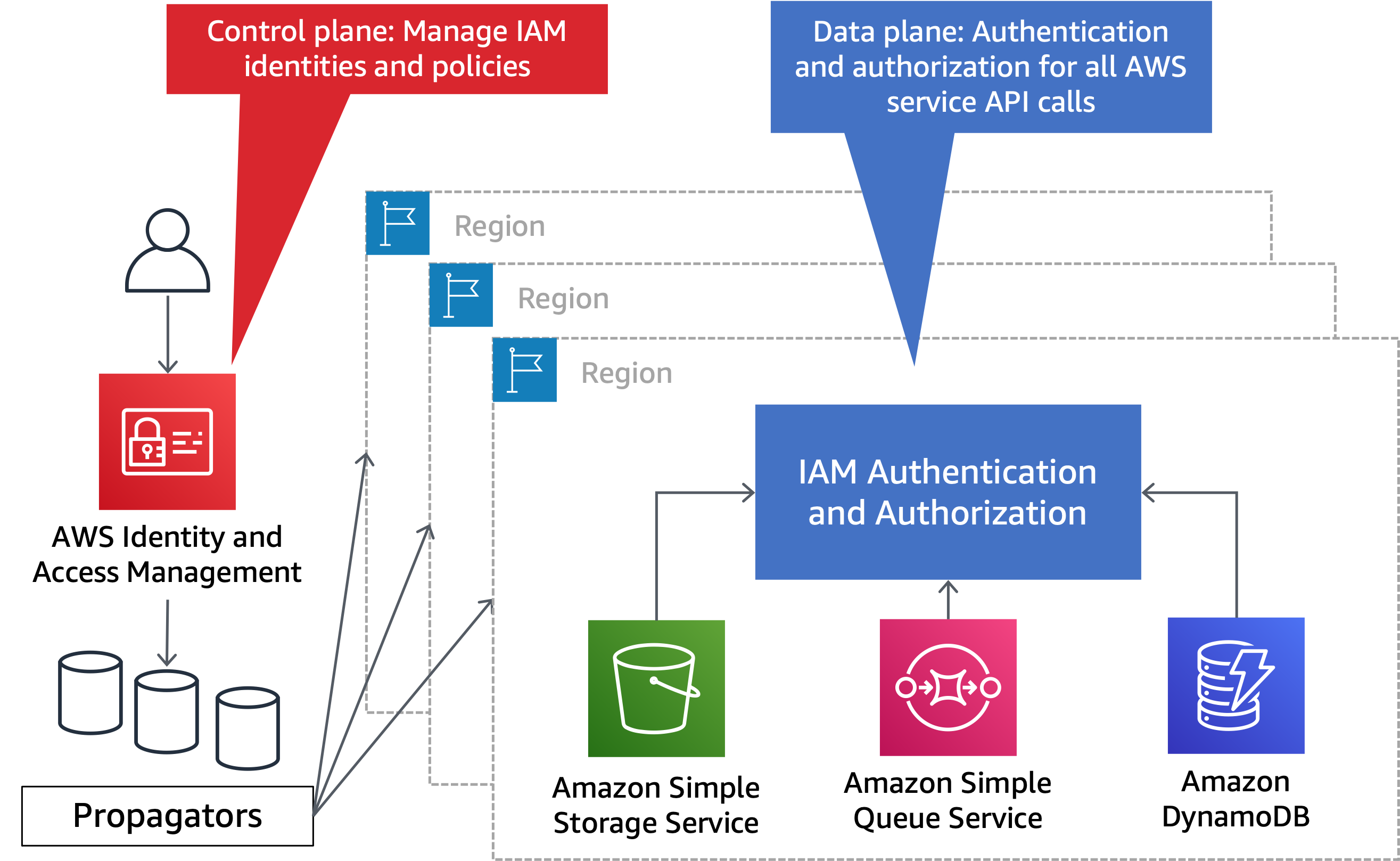
IAMhat eine einzige Steuerungsebene und eine regionalisierte Datenebene
Im Folgenden sind partitionelle Dienste und ihre Position auf der Steuerungsebene in der aws Partition aufgeführt:
-
AWS IAM (
us-east-1) -
AWS Organizations (
us-east-1) -
AWS Kontoverwaltung ()
us-east-1 -
Route 53 Application Recovery Controller (ARC) (
us-west-2) — Dieser Dienst ist nur in derawsPartition vorhanden -
AWS Netzwerkmanager (
us-west-2) -
Route 53 Privat DNS (
us-east-1)
Wenn auf einer dieser Servicesteuerungsebenen ein Ereignis auftritt, das sich auf die Verfügbarkeit auswirkt, können Sie die von diesen Diensten bereitgestellten Operationen CRUDL vom Typ -möglicherweise nicht nutzen. Wenn Ihre Wiederherstellungsstrategie also von diesen Vorgängen abhängt, verringert eine Auswirkung auf die Verfügbarkeit der Kontrollebene oder die Region, in der sich die Kontrollebene befindet, Ihre Chancen auf eine erfolgreiche Wiederherstellung. Anhang A — Anleitung zum partitionellen Servicebietet Strategien zur Beseitigung von Abhängigkeiten von globalen Service-Kontrollebenen während der Wiederherstellung.
Empfehlung
Verlassen Sie sich bei Ihrem Wiederherstellungspfad nicht auf die Steuerungsebenen partitioneller Dienste. Verlassen Sie sich stattdessen auf die Datenebenenoperationen dieser Dienste. Weitere Informationen dazu, wie Sie Anhang A — Anleitung zum partitionellen Service für partitionale Dienste entwerfen sollten, finden Sie unter.
Globale Dienste im Edge-Netzwerk
Die nächsten globalen AWS Dienste haben eine Kontrollebene in der aws Partition und hosten ihre Datenebenen in der globalen PoP-Infrastruktur (und möglicherweise AWS-Regionen auch). Auf die darin gehosteten Datenebenen PoPs kann über Ressourcen in jeder Partition sowie über das Internet zugegriffen werden. Beispielsweise betreibt Route 53 ihre Kontrollebene in der us-east-1 Region, ihre Datenebene ist jedoch auf Hunderte von Ebenen PoPs weltweit verteilt, ebenso wie auf jede Ebene AWS-Region (zur Unterstützung der öffentlichen und privaten Route 53 DNS innerhalb der Region). Route 53-Zustandsprüfungen sind ebenfalls Teil der Datenebene und werden von acht Stellen AWS-Regionen in der aws Partition aus durchgeführt. Clients können DNS mithilfe von öffentlich gehosteten Zonen von Route 53 von überall im Internet, einschließlich anderer Partitionen wie GovCloud, sowie von einer AWS
Virtual Private Cloud (VPC) aus Probleme lösen. Im Folgenden sind die globalen Edge-Netzwerkdienste und ihre Position auf der Steuerungsebene in der aws Partition aufgeführt:
-
Route 53 Öffentlich DNS (
us-east-1) -
Amazon CloudFront (
us-east-1) -
AWS WAF Klassisch für CloudFront (
us-east-1) -
AWS WAF für CloudFront (
us-east-1) -
Amazon Certificate Manager (ACM) für CloudFront (
us-east-1) -
AWSGlobaler Beschleuniger (AGA) (
us-west-2) -
AWS Shield Advanced (
us-east-1)
Wenn Sie AGA Integritätsprüfungen für EC2 Instances oder Elastic IP-Adressen verwenden, verwenden diese Route 53-Zustandsprüfungen. Das Erstellen oder Aktualisieren von AGA Integritätsprüfungen hängt von der Route 53-Steuerebene ab, in der Sie sich befindenus-east-1. Für die Ausführung der AGA Integritätsprüfungen wird die Datenebene der Route 53-Systemdiagnose verwendet.
Bei einem Ausfall, der sich auf die Region auswirkt, in der sich die Steuerungsebenen für diese Dienste befinden, oder bei einem Ausfall, der sich auf die Steuerungsebene selbst auswirkt, können Sie die von diesen Diensten bereitgestellten Operationen CRUDL vom Typ -möglicherweise nicht verwenden. Wenn Sie in Ihrer Wiederherstellungsstrategie Abhängigkeiten von diesen Vorgängen berücksichtigt haben, ist die Erfolgswahrscheinlichkeit dieser Strategie möglicherweise geringer, als wenn Sie sich nur auf die Datenebene dieser Dienste verlassen würden.
Empfehlung
Verlassen Sie sich bei Ihrem Wiederherstellungspfad nicht auf die Steuerungsebene der Edge-Netzwerkdienste. Verlassen Sie sich stattdessen auf den Betrieb dieser Dienste auf der Datenebene. Weitere Informationen Anhang B — Globale Servicehinweise für Edge-Netzwerke zur Planung globaler Dienste im Edge-Netzwerk finden Sie unter.
Globaler Betrieb in einer einzigen Region
Die letzte Kategorie umfasst spezifische Operationen auf Kontrollebene innerhalb eines Dienstes, die globale Auswirkungen haben, und nicht ganze Dienste wie die vorherigen Kategorien. Während Sie mit zonalen und regionalen Diensten in der von Ihnen angegebenen Region interagieren, hängen bestimmte Operationen grundsätzlich von einer einzelnen Region ab, die sich von der Region unterscheidet, in der sich die Ressource befindet. Diese Dienste unterscheiden sich von Diensten, die nur in einer einzigen Region bereitgestellt werden. Eine Liste dieser Dienste finden Sie unter. Anhang C — Dienste für eine einzelne Region
Während eines Fehlers, der sich auf die zugrunde liegende globale Abhängigkeit auswirkt, können Sie die Aktionen CRUDL vom Typ -typ der abhängigen Operationen möglicherweise nicht verwenden. Wenn Sie in Ihrer Wiederherstellungsstrategie Abhängigkeiten von diesen Vorgängen berücksichtigt haben, ist die Erfolgswahrscheinlichkeit dieser Strategie möglicherweise geringer, als wenn Sie sich nur auf die Datenebene dieser Dienste verlassen würden. Sie sollten bei Ihrer Wiederherstellungsstrategie Abhängigkeiten von diesen Vorgängen vermeiden.
Im Folgenden finden Sie eine Liste von Diensten, von denen andere Dienste abhängig sein können und die globalen Geltungsbereich haben:
-
Route 53
Verschiedene AWS Dienste erstellen Ressourcen, die einen oder mehrere ressourcenspezifische DNS Namen bereitstellen. Wenn Sie beispielsweise einen Elastic Load Balancer (ELB) bereitstellen, erstellt der Service öffentliche DNS Aufzeichnungen und Zustandsprüfungen in Route 53 für dieELB. Dies hängt von der Route 53-Steuerebene ab.
us-east-1Andere Dienste, die Sie verwendenELB, müssen möglicherweise ebenfalls im Rahmen ihrer Workflows auf der Kontrollebene eine Bereitstellung bereitstellen, öffentliche Route DNS 53-Datensätze erstellen oder Route 53-Zustandsprüfungen erstellen. Wenn Sie beispielsweise eine Amazon API REST API Gateway-Ressource, eine Amazon Relational Database Service (AmazonRDS) -Datenbank oder eine Amazon OpenSearch Service-Domain bereitstellen, werden DNS Datensätze in Route 53 erstellt. Im Folgenden finden Sie eine Liste von Diensten, deren Kontrollebene von der Route 53-Steuerebene abhängt,us-east-1um DNS Datensätze, Hosting-Zonen und/oder Route-53-Zustandsprüfungen zu erstellen, zu aktualisieren oder zu löschen. Diese Liste erhebt keinen Anspruch auf Vollständigkeit. Sie soll einige der am häufigsten verwendeten Dienste hervorheben, deren Aktionen auf der Kontrollebene zum Erstellen, Aktualisieren oder Löschen von Ressourcen von der Route 53-Steuerebene abhängen:-
Amazon API Gateway REST und HTTP APIs
-
RDSAmazon-Instanzen
-
Amazon Aurora Aurora-Datenbanken
-
Amazon ELB Load Balancer
-
AWS PrivateLink VPCEndpunkte
-
AWS Lambda URLs
-
Amazon ElastiCache
-
OpenSearch Amazon-Dienst
-
Amazon CloudFront
-
Amazon MemoryDB
-
Amazon Neptune
-
Amazon DynamoDB DynamoDB-Beschleuniger () DAX
-
AGA
-
Amazon Elastic Container Service (AmazonECS) mit DNS basiertem Service Discovery (das AWS Cloud Map API zur Verwaltung von Route 53 verwendetDNS)
-
Amazon EKS Kubernetes-Steuerebene
Es ist wichtig zu beachten, dass der VPC DNS Service, zum EC2Beispiel Hostnamen, unabhängig voneinander existiert AWS-Region und nicht von der Route 53-Steuerebene abhängt. Datensätze, die für EC2 Instanzen im VPC DNS Service wie,
ip-10-0-10.ec2.internalip-10-0-1-5.compute.us-west-2.compute.internal,i-0123456789abcdef.ec2.internalund AWS erstellt werdeni-0123456789abcdef.us-west-2.compute.internal, sind nicht auf die Route 53-Steuerebene angewiesen.us-east-1Empfehlung
Verlassen Sie sich in Ihrem Wiederherstellungspfad nicht darauf, Ressourcen zu erstellen, zu aktualisieren oder zu löschen, die die Erstellung, Aktualisierung oder Löschung von Route 53-Ressourceneinträgen, Hosting-Zonen oder Zustandsprüfungen erfordern. Stellen Sie diese Ressourcen vorab bereitELBs, z. B. um eine Abhängigkeit von der Route 53-Steuerebene in Ihrem Wiederherstellungspfad zu verhindern.
-
-
Amazon S3
Die folgenden Operationen auf der Amazon S3 S3-Steuerebene hängen grundsätzlich von
us-east-1derawsPartition ab. Ein Ausfall, der sich auf Amazon S3 oder andere Dienste auswirkt,us-east-1könnte dazu führen, dass die Aktionen dieser Kontrollebenen in anderen Regionen beeinträchtigt werden:PutBucketCorsDeleteBucketCorsPutAccelerateConfigurationPutBucketRequestPaymentPutBucketObjectLockConfigurationPutBucketTaggingDeleteBucketTaggingPutBucketReplicationDeleteBucketReplicationPutBucketEncryptionDeleteBucketEncryptionPutBucketLifecycleDeleteBucketLifecyclePutBucketNotificationPutBucketLoggingDeleteBucketLoggingPutBucketVersioningPutBucketPolicyDeleteBucketPolicyPutBucketOwnershipControlsDeleteBucketOwnershipControlsPutBucketAclPutBucketPublicAccessBlockDeleteBucketPublicAccessBlockDie Steuerungsebene für Amazon S3 Multiregion Access Points (MRAP) wird nur in dieser Region gehostet,
us-west-2und Anfragen zum Erstellen, Aktualisieren oder Löschen von Zielen MRAPs richten sich direkt an diese Region. Die Steuerungsebene für hat MRAP auch grundlegende Abhängigkeiten von AGA inus-west-2, Route 53 in und in jeder Regionus-east-1, ACM in der sie für die Bereitstellung von Inhalten konfiguriert MRAP ist. Sie sollten sich nicht auf die Verfügbarkeit der MRAP Kontrollebene in Ihrem Wiederherstellungspfad oder in den Datenebenen Ihrer eigenen Systeme verlassen. Dies unterscheidet sich von MRAPFailover-Steuerungen, mit denen der aktive oder passive Routing-Status für jeden Ihrer Buckets in der festgelegt wird. MRAP Diese APIs werden in fünf Modulen gehostet AWS-Regionen und können verwendet werden, um den Datenverkehr mithilfe der Datenebene des Dienstes effektiv zu verlagern.Darüber hinaus sind Amazon S3 S3-Bucket-Namen global eindeutig und alle Aufrufe an
CreateBucketundDeleteBucketAPIs hängen davon abus-east-1, dass in derawsPartition die Einzigartigkeit des Namens gewährleistet ist, auch wenn der API Aufruf an die spezifische Region gerichtet ist, in der Sie den Bucket erstellen möchten. Und schließlich sollten Sie sich bei wichtigen Workflows zur Bucket-Erstellung nicht auf die Verfügbarkeit einer bestimmten Schreibweise eines Bucket-Namens verlassen, insbesondere nicht auf solche, die einem erkennbaren Muster folgen.Empfehlung
Verlassen Sie sich im Rahmen Ihres Wiederherstellungspfads nicht darauf, neue S3-Buckets zu löschen oder zu erstellen oder S3-Bucket-Konfigurationen zu aktualisieren. Stellen Sie alle erforderlichen S3-Buckets vorab mit den erforderlichen Konfigurationen bereit, sodass Sie keine Änderungen vornehmen müssen, um sich nach einem Ausfall zu erholen. Dieser Ansatz gilt MRAPs auch für.
-
CloudFront
Amazon API Gateway bietet Edge-optimierte Endgeräte API. Die Erstellung dieser Endpunkte hängt von der CloudFront Steuerungsebene ab, auf der die Verteilung vor dem Gateway-Endpunkt erstellt wird.
us-east-1Empfehlung
Verlassen Sie sich nicht darauf, im Rahmen Ihres Wiederherstellungspfads neue Edge-optimierte API Gateway-Endpunkte zu erstellen. Stellen Sie alle erforderlichen Gateway-Endpunkte vorab bereit. API
Bei allen in diesem Abschnitt erörterten Abhängigkeiten handelt es sich um Aktionen auf Steuerungsebene, nicht um Aktionen auf Datenebene. Wenn Ihre Workloads so konfiguriert sind, dass sie statisch stabil sind, sollten sich diese Abhängigkeiten nicht auf Ihren Wiederherstellungspfad auswirken. Beachten Sie, dass die Implementierung statischer Stabilität zusätzliche Arbeit oder Dienste erfordert.
Dienste, die globale Standardendpunkte verwenden
In einigen Fällen stellen AWS Dienste einen standardmäßigen, globalen Endpunkt bereit, wie der AWS Security Token Service (AWS STS). Andere Dienste können diesen globalen Standardendpunkt in ihrer Standardkonfiguration verwenden. Das bedeutet, dass ein regionaler Dienst, den Sie verwenden, global von einem einzigen Dienst abhängig sein könnte AWS-Region. In den folgenden Details wird erklärt, wie unbeabsichtigte Abhängigkeiten von globalen Standardendpunkten entfernt werden können, sodass Sie den Dienst auf regionale Weise verwenden können.
AWS STS: STS ist ein Webdienst, mit dem Sie temporäre Anmeldeinformationen mit eingeschränkten Rechten für IAM Benutzer oder für Benutzer, die Sie authentifizieren (Verbundbenutzer), anfordern können. STSDie Verwendung aus dem AWS Software Development Kit (SDK) und der Befehlszeilenschnittstelle (CLI) ist standardmäßig auf. us-east-1 Der STS Service bietet auch regionale Endpunkte. Diese Endpunkte sind in Regionen, die ebenfalls standardmäßig aktiviert sind, standardmäßig aktiviert. Sie können diese jederzeit nutzen, indem Sie Ihre Endgeräte konfigurieren SDK oder die CLI folgenden Anweisungen befolgen: AWS STSRegionalisierte Endpunkte. Für die Verwendung von SigV4a sind außerdem temporäre Anmeldeinformationen erforderlich, die von einem regionalen Endpunkt angefordert werden. STS Sie können den globalen STS Endpunkt nicht für diesen Vorgang verwenden.
Empfehlung
Aktualisieren Sie Ihre SDK CLI AND-Konfiguration, um die regionalen STS Endpunkte zu verwenden.
Security Assertion Markup Language (SAML) Anmeldung: SAML Dienste sind überall vorhanden. AWS-Regionen Um diesen Service zu nutzen, wählen Sie den entsprechenden regionalen SAML Endpunkt aus, z. B. https://us-west-2.signin.aws.amazon.com/saml
Wenn Sie einen IdP verwenden, auf dem auch gehostet wird AWS, besteht das Risiko, dass dieser auch bei einem AWS Ausfall beeinträchtigt wird. Dies kann dazu führen, dass Sie Ihre IdP-Konfiguration nicht aktualisieren können oder dass Sie den Verbund möglicherweise nicht vollständig durchführen können. Sie sollten „Break-Glass“ -Benutzer vorab einrichten, falls Ihr IdP beeinträchtigt oder nicht verfügbar ist. Nähere Informationen darüber, Anhang A — Anleitung zum partitionellen Service wie Sie Break-Glass-Benutzer auf statisch stabile Weise erstellen können, finden Sie unter.
Empfehlung
Aktualisieren Sie Ihre Richtlinien für die IAM Vertrauensstellung von Rollen, sodass Anmeldungen aus mehreren Regionen akzeptiert SAML werden. Aktualisieren Sie bei einem Ausfall Ihre IdP-Konfiguration, sodass ein anderer regionaler SAML Endpunkt verwendet wird, falls Ihr bevorzugter Endpunkt beeinträchtigt ist. Erstellen Sie einen oder mehrere Break-Glass-Benutzer für den Fall, dass Ihr IdP beeinträchtigt oder nicht verfügbar ist.
AWS IAMIdentity Center: Identity Center ist ein cloudbasierter Dienst, der es einfach macht, den Single Sign-On-Zugriff auf Kunden- und Cloud-Anwendungen zentral zu verwalten. AWS-Konten Identity Center muss in einer einzigen Region Ihrer Wahl bereitgestellt werden. Das Standardverhalten für den Dienst besteht jedoch darin, den globalen SAML Endpunkt (https://signin.aws.amazon.com/samlus-east-1. Wenn Sie Identity Center auf einem anderen Server bereitgestellt haben AWS-Region, sollten Sie den Relaystatus URL jedes Berechtigungssatzes so aktualisieren, dass er auf denselben regionalen Konsolenendpunkt abzielt wie Ihre Identity Center-Bereitstellung. Wenn Sie beispielsweise Identity Center in bereitgestellt habenus-west-2, sollten Sie den Relaystate Ihrer Berechtigungssätze so aktualisieren, dass er https://us-west-2.console.aws.amazon.com verwendet.us-east-1 von Ihrer Identity Center-Bereitstellung entfernt.
Da IAM Identity Center nur in einer einzigen Region bereitgestellt werden kann, sollten Sie außerdem „Break-Glass“ -Benutzer vorab einrichten, falls Ihre Bereitstellung beeinträchtigt wird. Nähere Informationen darüber, Anhang A — Anleitung zum partitionellen Service wie Sie Break-Glass-Benutzer auf statisch stabile Weise erstellen können, finden Sie unter.
Empfehlung
Stellen Sie den Relaystatus Ihrer Berechtigungssätze in IAM Identity Center so ein, dass er URL der Region entspricht, in der Sie den Dienst bereitgestellt haben. Für den Fall, dass Ihre IAM Identity Center-Bereitstellung nicht verfügbar ist, richten Sie einen oder mehrere Benutzer ein, die sich durch die Nutzung von „Breakglass“ auszeichnen.
Amazon S3 Storage Lens: Storage Lens bietet ein Standard-Dashboard namens default-account-dashboard. Die Dashboard-Konfiguration und die zugehörigen Metriken werden in gespeichertus-east-1. Sie können zusätzliche Dashboards in anderen Regionen erstellen, indem Sie die Heimatregion für die Dashboard-Konfiguration und die Metrikdaten angeben.
Empfehlung
Wenn Sie während eines Fehlers, der sich auf den Service auswirkt, Daten aus dem standardmäßigen S3 Storage Lens-Dashboard benötigenus-east-1, erstellen Sie ein zusätzliches Dashboard in einer alternativen Heimatregion. Sie können auch alle anderen benutzerdefinierten Dashboards, die Sie in weiteren Regionen erstellt haben, duplizieren.
Zusammenfassung der globalen Dienste
Bei den Datenebenen für globale Dienste gelten ähnliche Isolations- und Unabhängigkeitsprinzipien wie bei regionalen AWS Diensten. Ein Ausfall, der sich auf die Datenebene einer IAM Region auswirkt, hat keine Auswirkungen auf den Betrieb der IAM Datenebene in einer anderen AWS-Region Region. In ähnlicher Weise hat ein Fehler, der sich auf die Datenebene von Route 53 in einem PoP auswirkt, keine Auswirkungen auf den Betrieb der Route 53-Datenebene im Rest der. PoPs Daher müssen wir Ereignisse zur Dienstverfügbarkeit berücksichtigen, die sich auf die Region auswirken, in der die Kontrollebene betrieben wird, oder auf die Kontrollebene selbst. Da es für jeden globalen Dienst nur eine einzige Kontrollebene gibt, kann ein Ausfall, der sich auf diese Kontrollebene auswirkt, regionsübergreifende Auswirkungen auf Operationen CRUDL vom Typ -typ haben (das sind die Konfigurationsvorgänge, die normalerweise zur Einrichtung oder Konfiguration eines Dienstes verwendet werden, im Gegensatz zur direkten Nutzung des Dienstes).
Die effektivste Methode, Workloads so zu gestalten, dass globale Dienste stabil genutzt werden können, ist die Verwendung statischer Stabilität. Bei einem Ausfallszenario sollten Sie Ihren Workload so gestalten, dass keine Änderungen erforderlich sind. Verwenden Sie dazu eine Kontrollebene, um die Auswirkungen zu minimieren, oder ein Failover an einen anderen Standort durchzuführen. Anleitungen zur Anhang A — Anleitung zum partitionellen Service Nutzung dieser Art von globalen Services zur Beseitigung von Abhängigkeiten auf der Kontrollebene und zur Eliminierung einzelner Fehlerquellen finden Sie unter und. Anhang B — Globale Servicehinweise für Edge-Netzwerke Wenn Sie die Daten aus einem Vorgang auf der Steuerungsebene für die Wiederherstellung benötigen, zwischenspeichern Sie diese Daten in einem Datenspeicher, auf den über dessen Datenebene zugegriffen werden kann, z. B. einem AWS Systems ManagerDescribeCluster API Vorgangs können Sie die Endpunkte für Ihre Route ARC 53-Cluster auflisten.
Im Folgenden finden Sie eine Zusammenfassung einiger der häufigsten Fehlkonfigurationen oder Anti-Pattern, die zu Abhängigkeiten von den Steuerungsebenen globaler Dienste führen:
-
Änderungen an Route 53-Datensätzen vornehmen, z. B. den Wert eines A-Datensatzes aktualisieren oder die Gewichtung eines gewichteten Datensatzes ändern, um ein Failover durchzuführen.
-
Erstellen oder Aktualisieren von IAM Ressourcen, einschließlich IAM Rollen und Richtlinien, während eines Failovers. Dies ist in der Regel nicht beabsichtigt, kann aber das Ergebnis eines ungetesteten Failover-Plans sein.
-
Bediener verlassen sich bei einem Ausfall auf IAM Identity Center, um Zugriff auf Produktionsumgebungen zu erhalten.
-
Verlassen Sie sich bei der Nutzung der Konsole auf die IAM Identity Center-Standardkonfiguration
us-east-1, wenn Sie Identity Center in einer anderen Region bereitgestellt haben. -
Vornehmen von Änderungen an den Wählgewichten für den AGA Traffic, um ein regionales Failover manuell durchzuführen.
-
Aktualisierung der Ausgangskonfiguration einer CloudFront Distribution, sodass ein Failaway von einem beeinträchtigten Ursprung aus erfolgt.
-
Bereitstellung von Notfallwiederherstellungsressourcen (DR), wie z. B. ELBs RDS Instanzen bei einem Ausfall, die von der Erstellung von DNS Datensätzen in Route 53 abhängig sind.
Im Folgenden finden Sie eine Zusammenfassung der in diesem Abschnitt enthaltenen Empfehlungen für eine zuverlässige Nutzung globaler Dienste, die dazu beitragen würden, die bisher üblichen Anti-Pattern-Angriffe zu verhindern.
Zusammenfassung der Empfehlungen
Verlassen Sie sich bei Ihrem Wiederherstellungspfad nicht auf die Steuerungsebenen partitionaler Dienste. Verlassen Sie sich stattdessen auf die Datenebenenoperationen dieser Dienste. Weitere Informationen dazu, wie Sie Anhang A — Anleitung zum partitionellen Service für partitionale Dienste entwerfen sollten, finden Sie unter.
Verlassen Sie sich bei Ihrem Wiederherstellungspfad nicht auf die Steuerungsebene der Edge-Netzwerkdienste. Verlassen Sie sich stattdessen auf den Betrieb dieser Dienste auf der Datenebene. Weitere Informationen Anhang B — Globale Servicehinweise für Edge-Netzwerke zur Planung globaler Dienste im Edge-Netzwerk finden Sie unter.
Verlassen Sie sich in Ihrem Wiederherstellungspfad nicht darauf, Ressourcen zu erstellen, zu aktualisieren oder zu löschen, die die Erstellung, Aktualisierung oder Löschung von Route 53-Ressourceneinträgen, Hosting-Zonen oder Zustandsprüfungen erfordern. Stellen Sie diese Ressourcen vorab bereitELBs, z. B. um eine Abhängigkeit von der Route 53-Steuerebene in Ihrem Wiederherstellungspfad zu verhindern.
Verlassen Sie sich nicht darauf, im Rahmen Ihres Wiederherstellungspfads S3-Buckets zu löschen oder neue S3-Buckets zu erstellen oder S3-Bucket-Konfigurationen zu aktualisieren. Stellen Sie alle erforderlichen S3-Buckets vorab mit den erforderlichen Konfigurationen bereit, sodass Sie keine Änderungen vornehmen müssen, um sich nach einem Ausfall zu erholen. Dieser Ansatz gilt MRAPs auch für.
Verlassen Sie sich nicht darauf, im Rahmen Ihres Wiederherstellungspfads neue Edge-optimierte API Gateway-Endpunkte zu erstellen. Stellen Sie alle erforderlichen Gateway-Endpunkte vorab bereit. API
Aktualisieren Sie Ihre SDK CLI Land-Konfiguration, um die regionalen STS Endpunkte zu verwenden.
Aktualisieren Sie Ihre Richtlinien für IAM Rollenvertrauensstellungen, sodass SAML Anmeldungen aus mehreren Regionen akzeptiert werden. Aktualisieren Sie bei einem Ausfall Ihre IdP-Konfiguration, sodass ein anderer regionaler SAML Endpunkt verwendet wird, falls Ihr bevorzugter Endpunkt beeinträchtigt ist. Erstellen Sie Break-Glass-Benutzer für den Fall, dass Ihr IdP beeinträchtigt oder nicht verfügbar ist.
Stellen Sie den Relaystatus URL Ihrer Berechtigungssätze in IAM Identity Center so ein, dass er der Region entspricht, in der Sie den Dienst bereitgestellt haben. Für den Fall, dass Ihre Identity Center-Bereitstellung nicht verfügbar ist, richten Sie einen oder mehrere Benutzer ein, die sich durch die Nutzung von „Breakglass“ auszeichnen.
Wenn Sie während eines Fehlers, der sich auf den Service auswirkt, Daten aus dem standardmäßigen S3 Storage Lens-Dashboard benötigenus-east-1, erstellen Sie ein zusätzliches Dashboard in einer anderen Heimatregion. Sie können auch alle anderen benutzerdefinierten Dashboards, die Sie in weiteren Regionen erstellt haben, duplizieren.
