Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verteiltes Datenmanagement
In herkömmlichen Anwendungen teilen sich alle Komponenten häufig eine einzige Datenbank. Im Gegensatz dazu verwaltet jede Komponente einer auf Microservices basierenden Anwendung ihre eigenen Daten, was Unabhängigkeit und Dezentralisierung fördert. Dieser Ansatz, bekannt als verteiltes Datenmanagement, bringt neue Herausforderungen mit sich.
Eine solche Herausforderung ergibt sich aus dem Kompromiss zwischen Konsistenz und Leistung in verteilten Systemen. Es ist oft praktischer, geringfügige Verzögerungen bei Datenaktualisierungen in Kauf zu nehmen (letztendliche Konsistenz), als auf sofortigen Aktualisierungen zu bestehen (sofortige Konsistenz).
Manchmal ist es für den Geschäftsbetrieb erforderlich, dass mehrere Microservices zusammenarbeiten. Wenn ein Teil ausfällt, müssen Sie möglicherweise einige abgeschlossene Aufgaben rückgängig machen. Das Saga-Muster hilft dabei, dies zu bewältigen, indem es eine Reihe von Ausgleichsmaßnahmen koordiniert.
Damit Microservices synchron bleiben, kann ein zentraler Datenspeicher verwendet werden. Dieser Shop, der mit Tools wie AWS Lambda, und Amazon verwaltet wird AWS Step Functions EventBridge, kann bei der Bereinigung und Deduplizierung von Daten helfen.
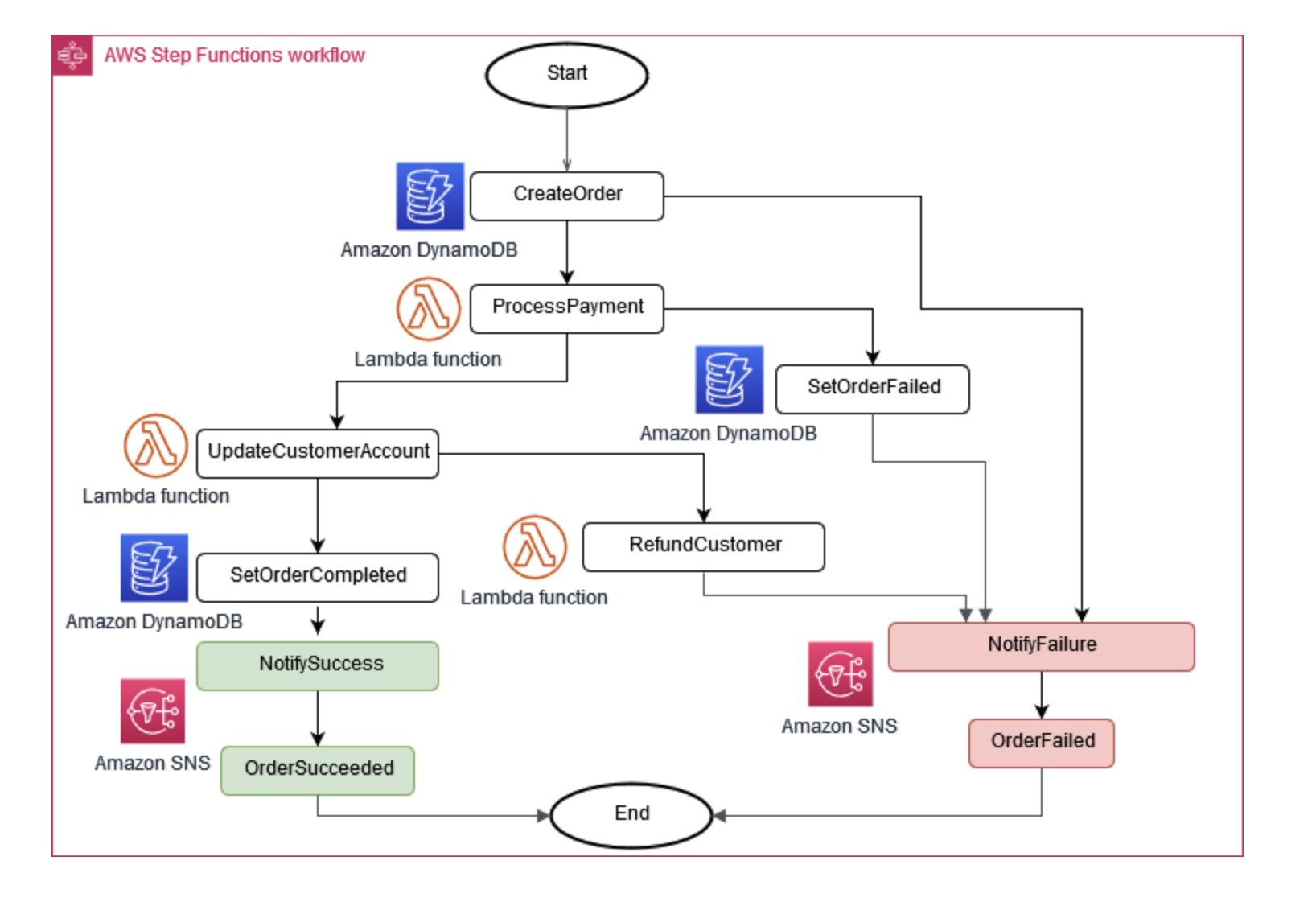
Abbildung 6: Saga-Ausführungskoordinator
Ein gängiger Ansatz bei der Verwaltung von Änderungen in Microservices ist das Event Sourcing. Jede Änderung in der Anwendung wird als Ereignis aufgezeichnet, wodurch ein Zeitplan für den Systemstatus erstellt wird. Dieser Ansatz hilft nicht nur beim Debuggen und Audit, sondern ermöglicht auch, dass verschiedene Teile einer Anwendung auf dieselben Ereignisse reagieren.
Event Sourcing arbeitet häufig hand-in-hand mit dem Command Query Responsibility Segregation (CQRS) -Muster, das Datenänderung und Datenabfrage in verschiedene Module unterteilt, um Leistung und Sicherheit zu verbessern.
Bei „On AWS“ können Sie diese Muster mithilfe einer Kombination von Diensten implementieren. Wie Sie in Abbildung 7 sehen können, kann Amazon Kinesis Data Streams als Ihr zentraler Ereignisspeicher dienen, während Amazon S3 einen dauerhaften Speicher für alle Ereignisaufzeichnungen bietet. AWS Lambda, Amazon DynamoDB und Amazon API Gateway arbeiten zusammen, um diese Ereignisse zu behandeln und zu verarbeiten.
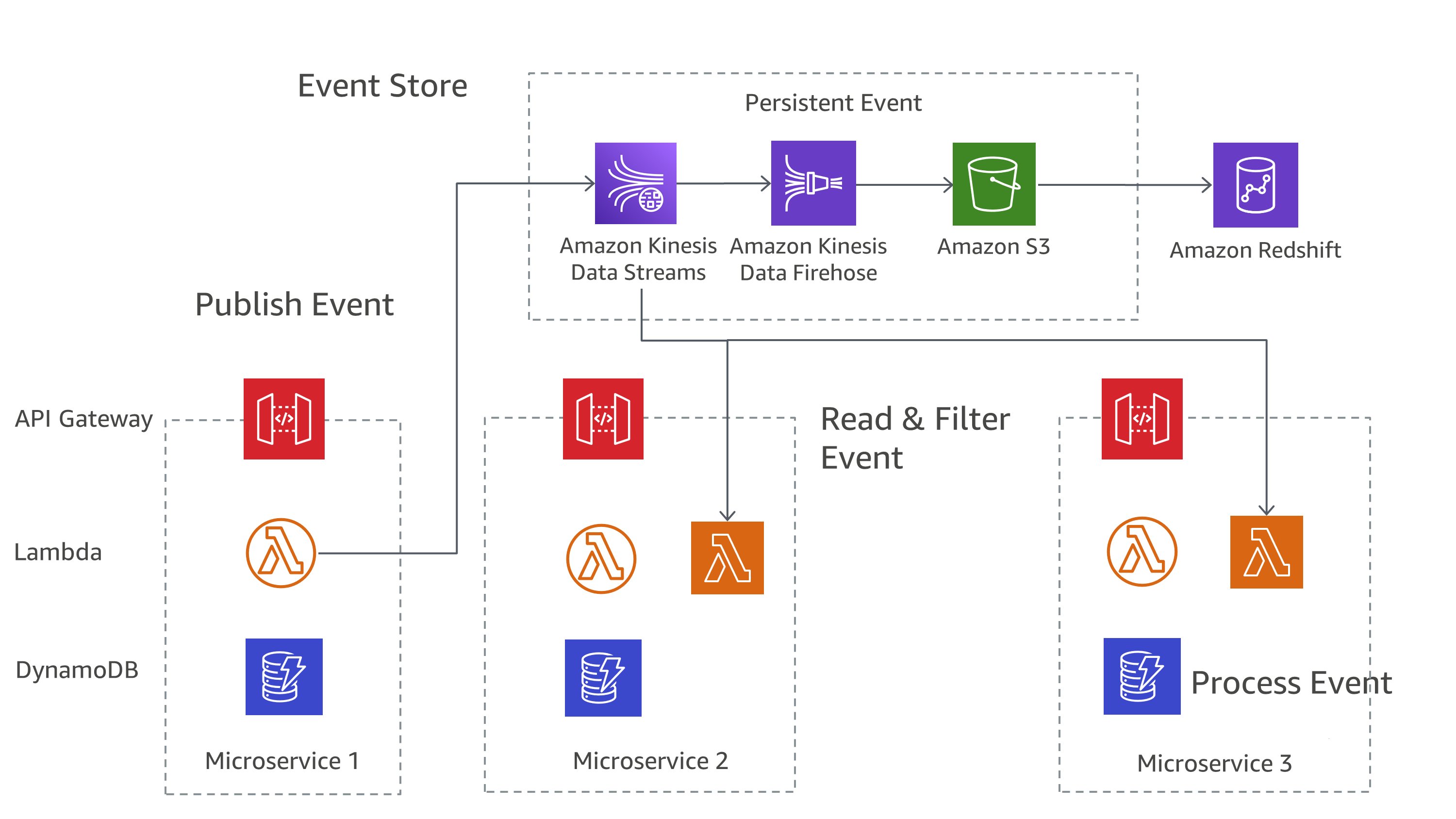
Abbildung 7: Muster für die Ereignisbeschaffung aktiviert AWS
Denken Sie daran, dass in verteilten Systemen Ereignisse aufgrund von Wiederholungsversuchen möglicherweise mehrfach zugestellt werden. Daher ist es wichtig, Ihre Anwendungen so zu gestalten, dass sie dies handhaben.
