Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Clústeres de escalado automático de Valkey y Redis OSS
Requisitos previos
ElastiCache Auto Scaling se limita a lo siguiente:
-
Clústeres de Valkey o Redis OSS (modo de clúster habilitado) que ejecutan Valkey 7.2 y versiones posteriores o Redis OSS 6.0 y versiones posteriores
-
Clústeres de organización de datos en niveles (modo de clúster habilitado) que ejecutan Valkey 7.2 y versiones posteriores o Redis OSS 7.0.7 y versiones posteriores
-
Tamaños de instancia: Large, XLarge, 2XLarge
-
Familias de tipos de instancia: R7g, R6g, R6gd, R5, M7g, M6g, M5, C7gn
-
Auto Scaling in no ElastiCache es compatible con los clústeres que se ejecutan en almacenes de datos globales, Outposts o Zonas Locales.
Gestión automática de la capacidad con ElastiCache Auto Scaling con Valkey o Redis OSS
ElastiCache el escalado automático con Valkey o Redis OSS es la capacidad de aumentar o disminuir automáticamente los fragmentos o réplicas deseados en su servicio. ElastiCache ElastiCache aprovecha el servicio Application Auto Scaling para proporcionar esta funcionalidad. Para obtener más información, consulte Auto Scaling de aplicaciones. Para utilizar el escalado automático, debe definir y aplicar una política de escalado que utilice CloudWatch las métricas y los valores objetivo que usted asigne. ElastiCache el escalado automático utiliza la política para aumentar o disminuir la cantidad de instancias en respuesta a las cargas de trabajo reales.
Puede utilizarla Consola de administración de AWS para aplicar una política de escalado basada en una métrica predefinida. Se define una predefined metric en una enumeración, de manera que puede especificarla por el nombre en el código o utilizarla en la Consola de administración de AWS. Las métricas personalizadas no se pueden seleccionar utilizando la Consola de administración de AWS. Como alternativa, puede usar la API Application Auto Scaling AWS CLI o la API para aplicar una política de escalado basada en una métrica predefinida o personalizada.
ElastiCache para Valkey y Redis, el OSS admite el escalado de las siguientes dimensiones:
-
Fragmentos: se fragmenta automáticamente add/remove en el clúster de forma similar a la repartición manual en línea. En este caso, el escalado ElastiCache automático activa el escalado en tu nombre.
-
Réplicas: se add/remove replican automáticamente en el clúster de forma similar a las operaciones de Increase/Decrease réplica manuales. ElastiCache escalado automático para adds/removes réplicas de OSS de Valkey y Redis de manera uniforme en todos los fragmentos del clúster.
ElastiCache para Valkey y Redis, el OSS admite los siguientes tipos de políticas de escalado automático:
-
Políticas de escalado de seguimiento de destino— Aumente o disminuya la cantidad de shards/replicas unidades que ejecuta su servicio en función del valor objetivo para una métrica específica. Se asemeja a los termostatos que se utilizan para mantener la temperatura del hogar. Se selecciona una temperatura y el termostato hace el resto.
-
Escalado programado para su aplicación. — ElastiCache para Valkey y Redis, el escalado automático de OSS puede aumentar o disminuir el número de veces shards/replicas que se ejecuta su servicio en función de la fecha y la hora.
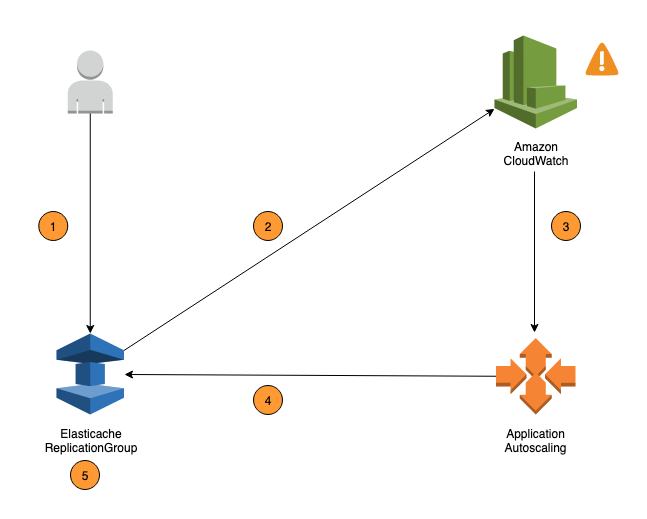
Los siguientes pasos resumen el proceso de autoescalado ElastiCache de Valkey y Redis OSS, tal como se muestra en el diagrama anterior:
-
Usted crea una política ElastiCache de escalado automático para su grupo de replicación.
-
ElastiCache el escalado automático crea un par de CloudWatch alarmas en tu nombre. Cada par representa los límites superiores e inferiores de las métricas. Estas CloudWatch alarmas se activan cuando la utilización real del clúster se desvía de la utilización objetivo durante un período prolongado. Puede ver las alarmas en la consola.
-
Si el valor de la métrica configurada supera su uso objetivo (o cae por debajo del objetivo) durante un período de tiempo específico, CloudWatch activa una alarma que invoca el escalado automático para evaluar su política de escalado.
-
ElastiCache el escalado automático emite una solicitud de modificación para ajustar la capacidad del clúster.
-
ElastiCache procesa la solicitud de modificación, aumentando (o disminuyendo) de forma dinámica la Shards/Replicas capacidad del clúster para que se acerque al uso deseado.
Para entender cómo funciona ElastiCache Auto Scaling, supongamos que tiene un clúster denominadoUsersCluster. Al supervisar las CloudWatch métricasUsersCluster, se determinan los fragmentos máximos que necesita el clúster cuando el tráfico está en su punto máximo y los fragmentos mínimos cuando el tráfico está en su punto más bajo. También decide un valor objetivo para el uso de la CPU en el UsersCluster clúster. ElastiCache el escalado automático utiliza su algoritmo de seguimiento de objetivos para garantizar que las particiones aprovisionadas se ajusten según sea necesario, de UsersCluster modo que la utilización se mantenga en el valor objetivo o cerca de él.
nota
El escalado puede llevar un tiempo considerable y requerir recursos de clúster adicionales para que los fragmentos se reequilibren. ElastiCache Auto Scaling modifica la configuración de los recursos solo cuando la carga de trabajo real permanece elevada (o reducida) durante un período prolongado de varios minutos. El algoritmo de seguimiento de destino del escalado automático intenta mantener el objetivo de utilización en el valor elegido o en valores próximos a él a largo plazo.
Permisos de IAM requeridos para el escalado automático
ElastiCache para Valkey y Redis OSS Auto Scaling es posible gracias a una combinación de las API ElastiCache CloudWatch, y Application Auto Scaling. Los clústeres se crean y actualizan con ElastiCache, las alarmas se crean con CloudWatch y las políticas de escalado se crean con Application Auto Scaling. Además de los permisos de IAM estándar para crear y actualizar clústeres, el usuario de IAM que accede a la configuración de ElastiCache Auto Scaling debe tener los permisos adecuados para los servicios que admiten el escalado dinámico. En esta política más reciente, hemos añadido compatibilidad con el escalado vertical de Memcached con la acción elasticache:ModifyCacheCluster. Los usuarios de IAM deben contar con los permisos necesarios para utilizar las acciones que se muestran en la siguiente política de ejemplo:
Service-linked rol
El servicio de escalado automático OSS ElastiCache para Valkey y Redis también necesita permiso para describir sus clústeres y CloudWatch alarmas, y permisos para modificar su capacidad ElastiCache objetivo en su nombre. Si habilita el escalado automático para su clúster, crea un rol vinculado a servicios denominado AWSServiceRoleForApplicationAutoScaling_ElastiCacheRG. Esta función vinculada al servicio otorga permiso de escalado ElastiCache automático para describir las alarmas de sus políticas, monitorear la capacidad actual de la flota y modificar la capacidad de la flota. La función vinculada al servicio es la función predeterminada para el escalado ElastiCache automático. Para obtener más información, consulte las Service-linked funciones del autoescalado ElastiCache de Redis OSS en la Guía del usuario de Application Auto Scaling.
Prácticas recomendadas de Auto Scaling
Antes de registrarse en Auto Scaling, recomendamos lo siguiente:
-
Utilizar solo una métrica de seguimiento: identifique si el clúster tiene CPU o cargas de trabajo intensivas de datos y utilice una métrica predefinida correspondiente para definir la política de escalado.
-
CPU del motor:
ElastiCachePrimaryEngineCPUUtilization(dimensión de partición) oElastiCacheReplicaEngineCPUUtilization(dimensión de réplica) -
Uso de bases de datos:
ElastiCacheDatabaseCapacityUsageCountedForEvictPercentageEsta política de escalado funciona mejor si la política maxmemory está configurada como noeviction en el clúster.
Le recomendamos que evite tener varias políticas por dimensión en el clúster. ElastiCache en el caso de Valkey y Redis OSS, el escalado automático ampliará el objetivo escalable si hay alguna política de seguimiento de objetivos preparada para ampliarla, pero solo se ampliará si todas las políticas de seguimiento de objetivos (con la parte de escalamiento interno habilitada) están preparadas para ampliarse. Si varias políticas indican al destino escalable que se realice una reducción o escalado horizontal al mismo tiempo, se escala en función de la política que proporciona la mayor capacidad para la reducción o el escalado horizontal.
-
-
Métricas personalizadas para el seguimiento de Target: tenga cuidado al utilizar métricas personalizadas para el seguimiento de Target, ya que el escalado automático es el más adecuado para escalarlo de forma out/in proporcional a los cambios en las métricas elegidas para la política. Si esas métricas no cambian proporcionalmente a las acciones de escalado usadas para la creación de políticas, es posible que den lugar a acciones continuas de escalar horizontalmente o reducir horizontalmente que es posible que afecten a la disponibilidad o el costo.
En el caso de los clústeres de datos por niveles (tipos de instancias de la familia r6gd), evite utilizar métricas basadas en memoria para escalar.
-
Escalamiento programado: si detecta que su carga de trabajo es determinista (llega high/low en un momento específico), le recomendamos que utilice el escalado programado y configure la capacidad objetivo de acuerdo con las necesidades. El seguimiento de destino es el más adecuado para las cargas de trabajo no determinista y para que el clúster funcione con la métrica de destino requerida al escalar horizontalmente cuando necesite más recursos y reducir horizontalmente cuando necesite menos.
-
Desactivar Scale-In: el escalado automático en Target Tracking es ideal para clústeres con cargas increase/decrease de trabajo graduales, ya que spikes/dip las métricas pueden provocar oscilaciones de escala consecutivas. out/in Para evitar tales oscilaciones, puede comenzar con la reducción horizontal deshabilitada y luego siempre puede reducir horizontalmente de forma manual según sus necesidades.
-
Pruebe su aplicación: le recomendamos que pruebe su aplicación con las Min/Max cargas de trabajo estimadas para determinar los valores mínimos y máximos absolutos shards/replicas necesarios para el clúster y, al mismo tiempo, cree políticas de escalado para evitar problemas de disponibilidad. Auto Scaling puede escalar horizontalmente hasta el máximo y reducir horizontalmente en el umbral mínimo configurado para el destino.
-
Definición del valor objetivo: puede analizar CloudWatch las métricas correspondientes a la utilización del clúster durante un período de cuatro semanas para determinar el umbral del valor objetivo. Si aún no se encuentra seguro de qué valor elegir, se recomienda comenzar con el valor mínimo admitido de métrica predefinida.
-
AutoScaling on Target Tracking es ideal para clústeres con una distribución uniforme de las cargas de trabajo en todas shards/replicas las dimensiones. Tener una distribución no uniforme puede conducir a:
-
Se puede escalar cuando no es necesario debido a la carga de trabajo spike/dip en unos pocos lugares. shards/replicas
-
No se escala cuando es necesario debido a que la media general está cerca del objetivo a pesar de tener calor shards/replicas.
-
nota
Al ampliar el clúster, ElastiCache replicará automáticamente las funciones cargadas en uno de los nodos existentes (seleccionadas al azar) en los nuevos nodos. Si el clúster tiene Valkey o Redis 7.0 o una versión posterior y la aplicación usa funciones
Después de registrarte AutoScaling, ten en cuenta lo siguiente:
-
Existen limitaciones en las configuraciones compatibles con Auto Scaling, por lo que recomendamos no cambiar la configuración de un grupo de reproducción que se haya registrado para Auto Scaling. A continuación se muestran algunos ejemplos:
-
Modificación manual del tipo de instancias a tipos no admitidos.
-
Asociación del grupo de reproducción a un almacén de datos global.
-
Cambio del parámetro
ReservedMemoryPercent. -
Superó increasing/decreasing shards/replicas manualmente la Min/Max capacidad configurada durante la creación de la política.
-
