Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
ElastiCache terminología
En octubre de 2016, Amazon ElastiCache lanzó el soporte para Redis OSS 3.2. En ese momento, añadimos la posibilidad de particionar los datos en hasta 500 fragmentos (denominados grupos de nodos en la ElastiCache API y). AWS CLI Para conservar la compatibilidad con versiones anteriores, hemos ampliado las operaciones de la versión de la API 2015-02-02 para incluir la nueva funcionalidad de Redis OSS.
Al mismo tiempo, empezamos a utilizar en la ElastiCache consola la terminología que se utiliza en esta nueva funcionalidad y que es común en todo el sector. Estos cambios implican que, en algunos aspectos, la terminología usada en la API y la CLI puede ser diferente de la terminología empleada en la consola. La siguiente lista identifica términos que pueden variar entre la API y la CLI y la consola.
- Clúster de caché o nodo frente a nodo
-
Si no hay nodos de réplica, existe una relación de uno a uno entre un nodo y un clúster. Por lo tanto, la ElastiCache consola solía utilizar los términos indistintamente. A partir de ahora, la consola utiliza el término nodo para todo. La única excepción es el botón Create Cluster, que lanza el proceso para crear un clúster con o sin nodos de réplica.
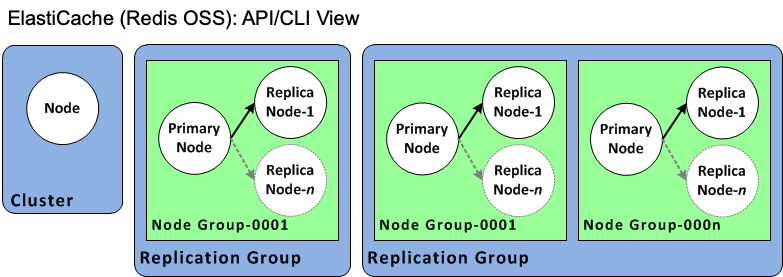
La ElastiCache API y AWS CLI seguimos utilizando los términos como lo han hecho en el pasado.
- Comparación entre el grupo de replicación de clúster y el grupo de replicación de Valkey o Redis OSS
-
La consola ahora usa el término clúster ElastiCache para todos los clústeres de Redis OSS. La consola utiliza el término clúster en todas estas circunstancias:
Cuando el clúster es un clúster de Valkey o Redis OSS de un solo nodo.
Cuando el clúster es un clúster de Valkey o Redis OSS (modo de clúster deshabilitado) que admite la replicación en una única partición (en la API y en la CLI, denominado grupo de nodos).
Cuando el clúster es un clúster de Valkey o Redis OSS (modo de clúster habilitado) que admite la replicación de entre 1 a 90 particiones o hasta 500 con una solicitud de aumento de límite. Para solicitar un aumento del límite, consulte AWS Service Limits y elija el tipo de límite Nodes per cluster per instance type (Nodos por clúster por tipo de instancias).
Para obtener más información acerca de los grupos de replicación de Valkey o Redis OSS, consulte. Alta disponibilidad a través de grupos de reproducción
El siguiente diagrama ilustra las distintas topologías de los clústeres OSS ElastiCache de Redis desde la perspectiva de la consola.
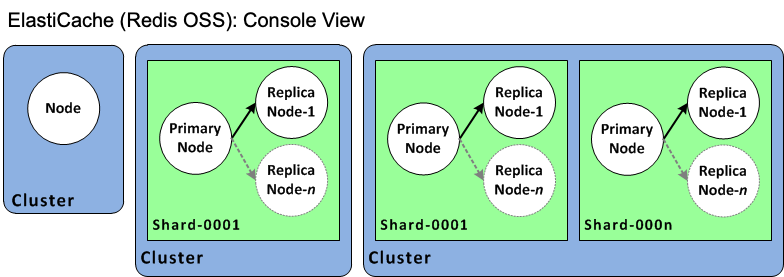
La ElastiCache API y AWS CLI las operaciones siguen distinguiendo un nodo único ElastiCache para los clústeres de OSS de Redis de los grupos de replicación de Valkey o Redis OSS de varios nodos. El siguiente diagrama ilustra las distintas topologías de OSS ElastiCache de Redis desde la API y desde la perspectiva. ElastiCache AWS CLI
- Grupo de replicación de Valkey o Redis OSS comparado con el almacén de datos global
Un almacén de datos global es una colección de uno o varios clústeres que se replican entre sí entre regiones, mientras que un grupo de replicación de Valkey o Redis OSS replica datos entre un clúster en modo de clúster habilitado con varias particiones. Un almacén de datos global consta de lo siguiente:
-
Clúster principal (activo): un clúster principal acepta escrituras que se replican en todos los clústeres dentro del almacén de datos global. Un clúster principal también acepta solicitudes de lectura.
-
Clúster secundario (pasivo): un clúster secundario solo acepta solicitudes de lectura y replica las actualizaciones de datos a partir de un clúster principal. Un clúster secundario debe estar en una AWS región diferente a la del clúster principal.
Para obtener información sobre almacenes de datos globales, consulte Replicación en AWS Regiones que utilizan almacenes de datos globales.
-
