Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Alta disponibilidad a través de grupos de reproducción
Los clústeres OSS de Amazon ElastiCache Valkey y Redis de un solo nodo son entidades en memoria con servicios de protección de datos (AOF) limitados. Si el clúster produce un error por cualquier motivo, se perderán todos los datos del clúster. Sin embargo, si utiliza un motor OSS de Valkey o Rediss, puede agrupar de 2 a 6 nodos en un clúster con réplicas, en el que de 1 a 5 nodos de solo lectura contengan datos replicados del único nodo del grupo que haya fallado. read/write primary node. In this scenario, if one node fails for any reason, you do not lose all your data since it is replicated in one or more other nodes. Due to replication latency, some data may be lost if it is the primary read/write
Como se observa en el siguiente gráfico, la estructura de la replicación se encuentra en una partición (denominada grupo de nodos en la API/CLI), que a su vez se encuentra en un clúster de Valkey o Redis OSS. Los clústeres de Valkey o Redis OSS (modo de clúster deshabilitado) siempre tienen una partición. Los clústeres de Valkey o Redis OSS (modo de clúster habilitado) pueden tener hasta 500 particiones, con sus datos del clúster divididos entre las particiones. Puede crear un clúster con un mayor número de particiones y un menor número de réplicas con un total de hasta 90 nodos por clúster. Esta configuración de clúster puede variar desde 90 particiones y 0 réplicas hasta 15 particiones y 5 réplicas, que es el número máximo de réplicas permitido.
El límite de nodos o fragmentos se puede aumentar hasta un máximo de 500 por clúster con Valkey y con ElastiCache la versión 5.0.6 o superior ElastiCache para Redis OSS. Por ejemplo, puede elegir configurar un clúster de 500 nodos que oscila entre 83 particiones (uno primario y 5 réplicas por partición) y 500 particiones (único primario y sin réplicas). Asegúrese de que hay suficientes direcciones IP disponibles para acomodar el aumento. Algunos problemas comunes incluyen que las subredes del grupo de subredes tienen un rango CIDR demasiado pequeño o que otros clústeres comparten y utilizan considerablemente las subredes. Para obtener más información, consulte Creación de un grupo de subredes.
Para las versiones inferiores a 5.0.6, el límite es de 250 por clúster.
Para solicitar un aumento del límite, consulte AWS Service Limits y elija el tipo de límite Nodes per cluster per instance type (Nodos por clúster por tipo de instancias).
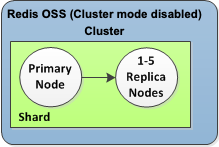
El clúster de Valkey o Redis OSS (modo de clúster deshabilitado) tiene una sola partición y de 0 a 5 nodos de réplica
Si el clúster con réplicas tiene habilitado Multi-AZ y el nodo principal produce un error, el principal realizará una conmutación por error a una réplica de lectura. Dado que los datos se actualizan en los nodos de réplica de forma asíncrona, es posible que haya algunas pérdidas de datos debido a la latencia en la actualización de los nodos de réplica. Para obtener más información, consulte Mitigación de errores al ejecutar Valkey o Redis OSS.
Temas
