Clústeres de base de datos de Amazon Aurora
Un clúster de bases de datos de Amazon Aurora se compone de una o varias instancias de base de datos y de un volumen de clúster que administra los datos de esas instancias de base de datos. Un volumen de clúster de Aurora es un volumen de almacenamiento de base de datos virtual que abarca varias zonas de disponibilidad, de modo que una de esas zonas tiene una copia de los datos del clúster de bases de datos. Un clúster de bases de datos Aurora se compone de dos tipos de instancias de base de datos:
-
Instancia de base de datos principal (escritor): admite operaciones de lectura y escritura y realiza todas las modificaciones de los datos en el volumen de clúster. Cada clúster de bases de datos Aurora tiene una instancia de base de datos principal.
-
Réplica de Aurora (instancia de base de datos de lector): se conecta con el mismo volumen de almacenamiento que la instancia de base de datos principal, pero solo admite operaciones de lectura. Cada clúster de bases de datos Aurora puede tener hasta 15 réplicas de Aurora, además de la instancia de base de datos principal. Mantenga una alta disponibilidad localizando réplicas de Aurora en distintas zonas de disponibilidad. Aurora cambiará automáticamente a una réplica de Aurora en caso de que la instancia de base de datos principal deje de estar disponible. Puede especificar la prioridad de conmutación por error para réplicas de Aurora. Las réplicas de Aurora también pueden descargar las cargas de trabajo de lectura desde la instancia de base de datos principal.
El siguiente diagrama muestra la relación entre el volumen del clúster, la instancia de base de datos de escritor y las instancias de base de datos de lector en un clúster de bases de datos de Aurora.
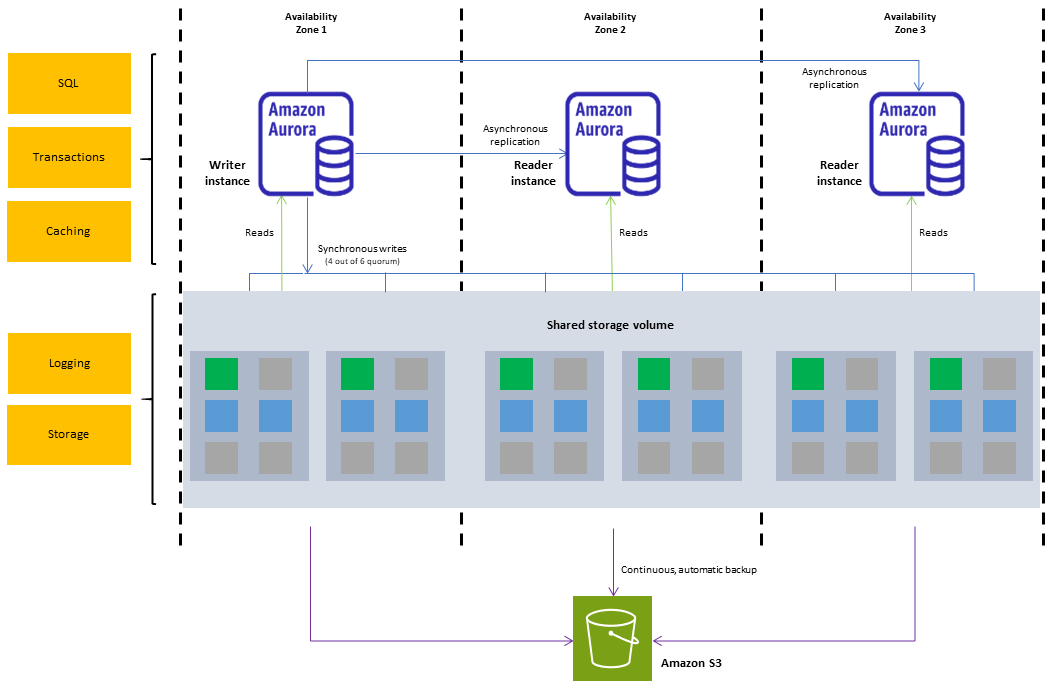
nota
La información anterior se aplica a todos los clústeres de bases de datos de Aurora: aprovisionados, de consultas paralelas, de base de datos global de Aurora, de Aurora Serverless y los compatibles con Aurora MySQL y Aurora PostgreSQL.
El clúster de base de datos de Aurora muestra la separación entre la capacidad de computación y el almacenamiento. Por ejemplo, una configuración de Aurora con solo una instancia de base de datos sigue siendo un clúster, pero el volumen de almacenamiento subyacente implica que haya varios nodos de almacenamiento distribuidos en varias zonas de disponibilidad (AZ).
Las operaciones de entrada/salida (E/S) en los clústeres de base de datos de Aurora se cuentan de la misma manera, independientemente de si se encuentran en una instancia de base de datos de escritor o de lector. Para obtener más información, consulte Configuraciones de almacenamiento para los clústeres de base de datos de Amazon Aurora.
