Uso de la replicación lógica para realizar una actualización de la versión principal para Aurora PostgreSQL
Al usar la replicación lógica y la clonación rápida de Aurora, puede ejecutar una actualización de la versión principal, que utiliza la versión actual de la base de datos de Aurora PostgreSQL, mientras migra gradualmente los datos cambiantes a la base de datos de la nueva versión principal. Este proceso de actualización con un tiempo de inactividad bajo se denomina actualización azul/verde. La versión actual de la base de datos se denomina entorno “azul” y la nueva versión de la base de datos, entorno “verde”.
La clonación rápida de Aurora carga completamente los datos existentes mediante una instantánea de la base de datos de origen. La clonación rápida utiliza un protocolo de copia en escritura construido sobre la capa de almacenamiento de Aurora, que permite crear un clon de la base de datos en poco tiempo. Este método es muy eficaz cuando se actualiza a una base de datos de gran tamaño.
La replicación lógica en PostgreSQL rastrea y transfiere los cambios en los datos de la instancia inicial a una nueva instancia que se ejecuta en paralelo hasta que pase a la versión más reciente de PostgreSQL. La replicación lógica usa un modelo de publicación y suscripción. Para obtener más información acerca de la replicación lógica de Aurora PostgreSQL, consulte Replicación con Amazon Aurora PostgreSQL.
sugerencia
Puede minimizar el tiempo de inactividad necesario para la actualización de una versión principal mediante la característica de implementación azul/verde administrada de Amazon RDS. Para obtener más información, consulte Uso de las implementaciones azul/verde de Amazon Aurora para actualizar las bases de datos.
Temas
Requisitos
Debe cumplir los siguientes requisitos para llevar a cabo este proceso de actualización con bajo tiempo de inactividad:
-
Debe tener permisos de rds_superuser.
-
El clúster de base de datos de Aurora PostgreSQL que pretende actualizar debe ejecutar una versión compatible que pueda realizar actualizaciones de versiones importantes mediante la replicación lógica. Asegúrese de aplicar todas las actualizaciones y revisiones de versiones secundarias al clúster de base de datos. La característica
aurora_volume_logical_start_lsnque se utiliza en esta técnica es compatible con las siguientes versiones de Aurora PostgreSQL:Versión 15.2 y versiones posteriores a la 15
Versión 14.3 y versiones posteriores a la 14
Versión 13.6 y versiones posteriores a la 13
Versión 12.10 y versiones posteriores a la 12
Versión 11.15 y versiones posteriores a la 11
Versión 10.20 y versiones posteriores a la 10
Para obtener más información sobre las funciones de
aurora_volume_logical_start_lsn, consulte aurora_volume_logical_start_lsn. -
Todas las tablas deben tener una clave principal o incluir una columna de identidad de PostgreSQL
. -
Configure el grupo de seguridad de su VPC para permitir el acceso entrante y saliente entre los dos clústeres de base de datos de Aurora PostgreSQL, tanto antiguos como nuevos. Puede conceder acceso a un rango específico de enrutamiento entre dominios sin clases (CIDR) o a otro grupo de seguridad de su VPC o de una VPC del mismo nivel. (La VPC del mismo nivel requiere una conexión del mismo nivel de VPC).
nota
Para obtener información detallada sobre los permisos necesarios para configurar y administrar un escenario de replicación lógica en ejecución, consulte la documentación básica de PostgreSQL
Limitaciones
Al realizar una actualización con tiempo de inactividad bajo en el clúster de base de datos de Aurora PostgreSQL a una nueva versión principal, está utilizando la característica de replicación lógica nativa de PostgreSQL. Tiene las mismas capacidades y limitaciones que la replicación lógica de PostgreSQL. Para obtener más información, consulte Uso de la replicación lógica de PostgreSQL
-
Los comandos del lenguaje de definición de datos no se replican.
-
La replicación no admite cambios de esquema en una base de datos activa. El esquema se vuelve a crear en su formato original durante el proceso de clonación. Si cambia el esquema después de la clonación, pero antes de completar la actualización, no se reflejará en la instancia actualizada.
-
Los objetos grandes no se replican, pero se pueden almacenar datos en tablas normales.
-
La replicación solo es compatible con tablas, incluidas las tablas particionadas. No se admite la replicación en otros tipos de relaciones, como vistas, vistas materializadas o tablas externas.
-
Los datos de la secuencia no se replican y requieren una actualización manual después de la conmutación por error.
nota
Esta actualización no admite la creación automática de scripts. Hay que realizar todos los pasos de forma manual.
Configuración y comprobación de valores de parámetros
Antes de realizar la actualización, configure la instancia de escritor de su clúster de base de datos de Aurora PostgreSQL para que funcione como un servidor de publicación. La instancia debe utilizar un grupo de parámetros de clúster de base de datos personalizado con la siguiente configuración:
-
rds.logical_replication: establezca este parámetro en 1. El parámetrords.logical_replicationtiene el mismo propósito que el parámetrowal_levelde un servidor PostgreSQL independiente y otros parámetros que controlan la administración de archivos de registro de escritura anticipada. -
max_replication_slots: establezca este parámetro en el número total de suscripciones que tiene previsto crear. Si utiliza AWS DMS, establezca este parámetro en el número de tareas de AWS DMS que tiene pensado utilizar para la captura de datos cambiados desde este clúster de base de datos. -
max_wal_senders: establezca el número de conexiones simultáneas, más algunas adicionales, para que estén disponibles para tareas de administración y sesiones nuevas. Si utiliza AWS DMS, el número de max_wal_senders debe ser igual al número de sesiones simultáneas más el número de tareas AWS DMS que pueden estar funcionando en un momento dado. -
max_logical_replication_workers: establezca el número de trabajadores de replicación lógica y trabajadores de sincronización de tablas que espera tener. Por lo general, es seguro establecer el número de trabajadores de replicación en el mismo valor que se utiliza para max_wal_senders. Los trabajadores se toman del conjunto de procesos en segundo plano (max_worker_processes) asignado para el servidor. -
max_worker_processes: establezca el número de procesos en segundo plano para el servidor. Este número debe ser lo suficientemente grande como para asignar trabajadores a la replicación, los procesos auto-vacuum y otros procesos de mantenimiento que puedan llevarse a cabo simultáneamente.
Al actualizar a una versión más reciente de Aurora PostgreSQL, debe duplicar los parámetros que haya modificado en la versión anterior del grupo de parámetros. Estos parámetros se aplican a la versión actualizada. Puede consultar la tabla pg_settings para obtener una lista de las configuraciones de parámetros para poder volver a crearlos en el nuevo clúster de base de datos de Aurora PostgreSQL.
Por ejemplo, para obtener la configuración de los parámetros de replicación, ejecute la siguiente consulta:
SELECT name, setting FROM pg_settings WHERE name in ('rds.logical_replication','max_replication_slots','max_wal_senders','max_logical_replication_workers','max_worker_processes');
Actualización de Aurora PostgreSQL a una nueva versión principal
Para preparar el publicador (azul)
-
En el ejemplo siguiente, la instancia del escritor de origen (azul) es un clúster de base de datos de Aurora PostgreSQL que ejecuta la versión 11.15 de PostgreSQL. Este es el nodo de publicación de nuestro escenario de replicación. Para esta demostración, nuestra instancia de escritor de origen aloja una tabla de ejemplo que contiene una serie de valores:
CREATE TABLEmy_table(a int PRIMARY KEY); INSERT INTOmy_tableVALUES (generate_series(1,100)); -
Para crear una publicación en la instancia de origen, conéctese al nodo de escritura de la instancia con psql (la CLI de PostgreSQL o con el cliente que elija). Introduzca el siguiente comando en cada base de datos:
CREATE PUBLICATIONpublication_nameFOR ALL TABLES;publication_name especifica el nombre de la publicación.
-
También debe crear una ranura de replicación en la instancia. El siguiente comando crea una ranura de replicación y carga el plugin de descodificación lógica
pgoutput. El plugin cambia el contenido leído del registro de lectura anticipada (WAL) al protocolo de replicación lógica y filtra los datos de acuerdo con la especificación de la publicación.SELECT pg_create_logical_replication_slot('replication_slot_name','pgoutput');
Para clonar el publicador
-
Use la consola de Amazon RDS para crear un clon de la instancia de origen. Resalte el nombre de la instancia en la consola de Amazon RDS y, a continuación, elija Create clone (Crear clon) en el menú Actions (Acciones).
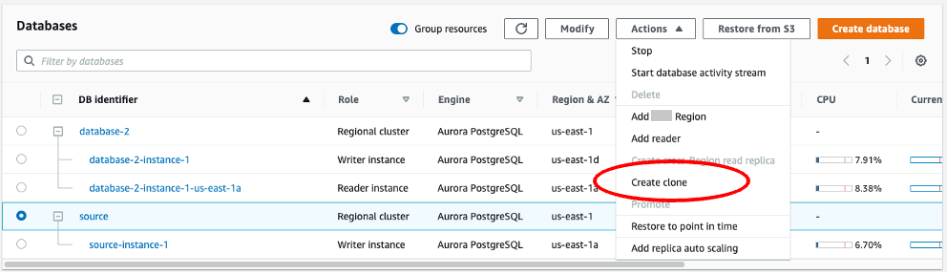
-
Introduzca un nombre único para la instancia. La mayoría de los ajustes son los valores predeterminados de la instancia de origen. Cuando haya realizado los cambios necesarios para la nueva instancia, seleccione Create clone (Crear clon).

-
Mientras se inicia la instancia de destino, la columna Status (Estado) del nodo de escritura muestra Creating (Creando) en la columna Status (Estado). Cuando la instancia esté lista, su estado cambiará a Available (Disponible).
Para preparar el clon para una actualización
-
El clon es la instancia “verde” del modelo de implementación. Es el host del nodo de suscripción de replicación. Cuando el nodo esté disponible, conéctese con psql y consulte el nuevo nodo de escritor para obtener el número de secuencia de registro (LSN). El LSN identifica el principio de un registro en el flujo de WAL.
SELECT aurora_volume_logical_start_lsn(); -
En la respuesta de la consulta, encontrará el número LSN. Necesitará este número más adelante en el proceso, así que anótelo.
postgres=>SELECT aurora_volume_logical_start_lsn();aurora_volume_logical_start_lsn --------------- 0/402E2F0 (1 row) -
Antes de actualizar el clon, elimine la ranura de replicación del clon.
SELECT pg_drop_replication_slot('replication_slot_name');
Para actualizar un clúster a una nueva versión principal
-
Tras clonar el nodo del proveedor, utilice la consola de Amazon RDS para iniciar una actualización de la versión principal en el nodo de suscripción. Resalte el nombre de la instancia en la consola de RDS y seleccione el botón Modify (Modificar). Seleccione la versión actualizada y los grupos de parámetros actualizados y aplique la configuración inmediatamente para actualizar la instancia de destino.
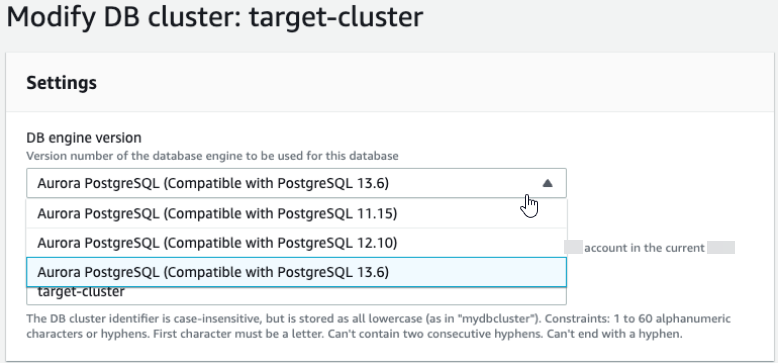
-
También puede utilizar la CLI para realizar una actualización:
aws rds modify-db-cluster —db-cluster-identifier $TARGET_Aurora_ID —engine-version 13.6 —allow-major-version-upgrade —apply-immediately
Para preparar al suscriptor (verde)
-
Cuando el clon esté disponible tras la actualización, conéctese con psql y defina la suscripción. Para ello, debe especificar las siguientes opciones en el comando
CREATE SUBSCRIPTION:-
subscription_name: el nombre de la suscripción. -
admin_user_name: el nombre de un usuario administrativo con permisos de rds_superuser. -
admin_user_password: la contraseña asociada al usuario administrativo. -
source_instance_URL: la URL de la instancia del servidor de publicaciones. -
database: la base de datos a la que se conectará el servidor de suscripciones. -
publication_name: el nombre del servidor de publicación. -
replication_slot_name: el nombre del grupo de replicación.
CREATE SUBSCRIPTIONsubscription_nameCONNECTION'postgres://admin_user_name:admin_user_password@source_instance_URL/database'PUBLICATIONpublication_nameWITH (copy_data = false, create_slot = false, enabled = false, connect = true, slot_name ='replication_slot_name'); -
-
Tras crear la suscripción, consulte la vista pg_replication_origin
para recuperar el valor roname, que es el identificador del origen de la replicación. Cada instancia tiene un solo roname:SELECT * FROM pg_replication_origin;Por ejemplo:
postgres=>SELECT * FROM pg_replication_origin;roident | roname ---------+---------- 1 | pg_24586 -
Introduzca el LSN que guardó de la consulta anterior del nodo de publicación y el
ronamedevuelto desde [INSTANCIA] del nodo de suscripción en el comando. Este comando usa la funciónpg_replication_origin_advancepara especificar el punto inicial de la secuencia de registro para la replicación.SELECT pg_replication_origin_advance('roname','log_sequence_number');ronamees el identificador devuelto por la vista pg_replication_origin.log_sequence_numberes el valor devuelto por la consulta anterior de la funciónaurora_volume_logical_start_lsn. -
A continuación, utilice la cláusula
ALTER SUBSCRIPTION... ENABLEpara activar la replicación lógica.ALTER SUBSCRIPTIONsubscription_nameENABLE; -
En este punto, puede confirmar que la replicación funciona. Añada un valor a la instancia de publicación y, a continuación, confirme que el valor se replica en el nodo de suscripción.
A continuación, utilice el siguiente comando para supervisar el retardo de replicación en el nodo de publicación:
SELECT now() AS CURRENT_TIME, slot_name, active, active_pid, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) AS diff_size, pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn) AS diff_bytes FROM pg_replication_slots WHERE slot_type = 'logical';Por ejemplo:
postgres=>SELECT now() AS CURRENT_TIME, slot_name, active, active_pid, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) AS diff_size, pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn) AS diff_bytes FROM pg_replication_slots WHERE slot_type = 'logical';current_time | slot_name | active | active_pid | diff_size | diff_bytes -------------------------------+-----------------------+--------+------------+-----------+------------ 2022-04-13 15:11:00.243401+00 | replication_slot_name | t | 21854 | 136 bytes | 136 (1 row)Puede supervisar el retardo de replicación mediante los valores
diff_sizeydiff_bytes. Cuando estos valores lleguen a 0, la réplica estará funcionando al mismo ritmo que la instancia de base de datos de origen.
Realización de tareas posteriores a la actualización
Cuando finalice la actualización, el estado de la instancia aparecerá como Available (Disponible) en la columna Status (Estado) del panel de control de la consola. En la nueva instancia, recomendamos que haga lo siguiente:
-
Redirija sus aplicaciones para que apunten al nodo de escritor.
-
Añada nodos de lector para administrar el número de casos y ofrecer una alta disponibilidad en caso de que surja un problema con el nodo de escritor.
-
En ocasiones, los clústeres de base de datos de Aurora PostgreSQL requieren actualizaciones del sistema operativo. Estas actualizaciones a veces pueden incluir una versión más reciente de la biblioteca glibc. Durante estas actualizaciones, le recomendamos que siga las directrices que se describen en Intercalaciones admitidas en Aurora PostgreSQL .
-
Actualice los permisos de usuario en la nueva instancia para garantizar el acceso.
Tras probar la aplicación y los datos en la nueva instancia, le recomendamos que realice una copia de seguridad final de la instancia inicial antes de eliminarla. Para obtener más información acerca del uso de la replicación lógica en un host de Aurora, consulte Configuración de la replicación lógica para el clúster de base de datos de Aurora PostgreSQL.
