AWS CLIEjemplos de la para Performance Insights
En las siguientes secciones, obtendrá más información sobre AWS Command Line Interface (AWS CLI) para Información de rendimiento, así como ejemplos de uso de la AWS CLI.
Temas
Ayuda integrada en la AWS CLI para Información de rendimiento
Recuperación del promedio de carga de base de datos para los eventos de espera principales
Recuperación del promedio de carga de base de datos para las instrucciones SQL principales
Recuperación del promedio de carga de base de datos filtrado por SQL
Creación de un informe de análisis de rendimiento para un período de tiempo
Enumeración de todos los informes de análisis de rendimiento de la instancia de base de datos
Adición de una etiqueta a un informe de análisis de rendimiento
Enumeración de todas las etiquetas de un informe de análisis de rendimiento
Eliminación de etiquetas de un informe de análisis de rendimiento
Ayuda integrada en la AWS CLI para Información de rendimiento
Puede ver los datos de Performance Insights a través de la AWS CLI. Puede obtener ayuda sobre los comandos de la AWS CLI de Performance Insights escribiendo lo siguiente en la línea de comandos.
aws pi help
Si no tiene instalada la AWS CLI, consulte Instalación de la AWS CLI en la Guía del usuario de la AWS CLI para obtener información sobre cómo instalarla.
Recuperación de métricas de contador
La siguiente captura de pantalla muestra dos gráficos de métricas de contador en la AWS Management Console.
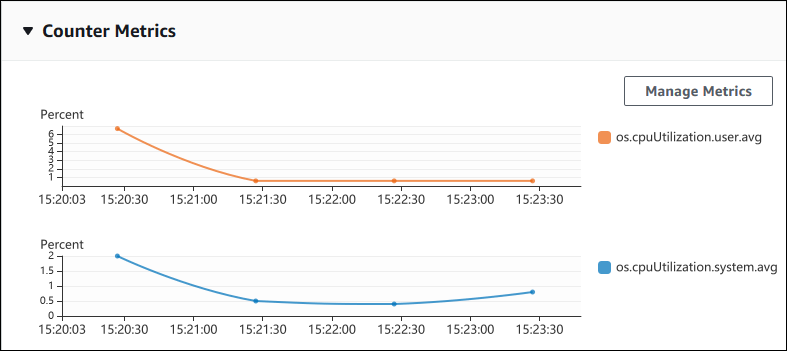
El siguiente ejemplo muestra cómo recopilar los mismos datos que utiliza la AWS Management Console para generar los dos gráficos de métricas de contador.
Para Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
También puede hacer que un comando sea más fácil de leer especificando un archivo para la opción --metrics-query. El siguiente ejemplo utiliza un archivo llamado query.json para la opción. El archivo tiene el siguiente contenido.
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
Ejecute el siguiente comando para utilizar el archivo.
Para Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
El ejemplo anterior especifica los siguientes valores para las opciones:
-
--service-type:RDSpara Amazon RDS -
--identifier: el ID de recurso para la instancia de base de datos -
--start-timey:--end-timelos valores ISO 8601DateTimepara el periodo de consulta, con varios formatos admitidos
Consulta durante un intervalo de una hora:
-
--period-in-seconds:60para una consulta por minuto -
--metric-queries: una matriz de dos consultas, cada una para una métrica.El nombre de la métrica utiliza puntos para clasificar la métrica en categorías útiles y el elemento final es una función. En el ejemplo, la función es
avgpara cada consulta. Al igual que con Amazon CloudWatch, las funciones admitidas sonmin,max,totalyavg.
La respuesta tiene un aspecto similar a la siguiente.
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { "Metric": "os.cpuUtilization.user.avg" //Metric1 }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 4.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 4.0 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 10.0 } //... 60 datapoints for the os.cpuUtilization.user.avg metric ] }, { "Key": { "Metric": "os.cpuUtilization.idle.avg" //Metric2 }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 12.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 13.5 }, //... 60 datapoints for the os.cpuUtilization.idle.avg metric ] } ] //end of MetricList } //end of response
La respuesta tiene Identifier, AlignedStartTime y AlignedEndTime. Como el valor --period-in-seconds era 60, los tiempos de inicio y final se han alineado con el minuto. Si el --period-in-seconds fuera 3600, los tiempos de inicio y final se habrían alineado con la hora.
La MetricList en la respuesta tiene una serie de entradas, cada una con una entrada Key y una entrada DataPoints. Cada DataPoint tiene un Timestamp y un Value. Cada lista de Datapoints tiene 60 puntos de datos porque las consultas son datos por minuto sobre una hora, con Timestamp1/Minute1, Timestamp2/Minute2 y así sucesivamente, hasta Timestamp60/Minute60.
Como la consulta es para dos métricas de contador distintas, hay dos elementos en la respuesta MetricList.
Recuperación del promedio de carga de base de datos para los eventos de espera principales
El siguiente ejemplo es la misma consulta que utiliza la AWS Management Console para generar un gráfico de línea de área apilada. Este ejemplo recupera el db.load.avg durante la última hora con la carga dividida según los siete eventos de espera principales. El comando es el mismo que el comando en Recuperación de métricas de contador. Sin embargo, el archivo query.json tiene los elementos indicados a continuación.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 7 } } ]
Ejecute el comando siguiente.
Para Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
El ejemplo especifica la métrica de db.load.avg y un GroupBy de los siete eventos de espera principales. Para obtener detalles acerca de los valores válidos para este ejemplo, consulte DimensionGroup en la Referencia de la API de Performance Insights.
La respuesta tiene un aspecto similar a la siguiente.
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 0.5166666666666667 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.38333333333333336 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 0.26666666666666666 } //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_event.name": "CPU", "db.wait_event.type": "CPU" } }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 0.35 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.15 }, //... 60 datapoints for the CPU key ] }, //... In total we have 8 key/datapoints entries, 1) total, 2-8) Top Wait Events ] //end of MetricList } //end of response
En esta respuesta, hay ocho entradas en la MetricList. Hay una entrada para el db.load.avg total y siete entradas para el db.load.avg divididas según uno de los siete eventos de espera principales. A diferencia del primer ejemplo, como había una dimensión de agrupación, debe haber una clave para cada agrupación de la métrica. No puede haber solo una clave para cada métrica, como en el caso de uso de métrica de contador básica.
Recuperación del promedio de carga de base de datos para las instrucciones SQL principales
El siguiente ejemplo agrupa db.wait_events por las 10 instrucciones SQL principales. Hay dos grupos distintos para instrucciones SQL:
-
db.sql– la instrucción SQL completa, comoselect * from customers where customer_id = 123 -
db.sql_tokenized– la instrucción SQL tokenizada, comoselect * from customers where customer_id = ?
Al analizar el desempeño de la base de datos, puede resultar útil tener en cuenta instrucciones SQL que solo se diferencien en sus parámetros como un elemento de lógica. Así pues, puede utilizar db.sql_tokenized al consultar. Sin embargo, sobre todo cuando le interese explicar planes, a veces es más útil examinar instrucciones SQL completas con parámetros y consultar agrupando por db.sql. Existe una relación principal-secundaria entre instrucciones SQL tokenizadas y completas, con varias instrucciones SQL completas (secundarias) agrupadas bajo la misma instrucción SQL tokenizada (principal).
El comando en este ejemplo es similar al comando en Recuperación del promedio de carga de base de datos para los eventos de espera principales. Sin embargo, el archivo query.json tiene los elementos indicados a continuación.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Limit": 10 } } ]
El siguiente ejemplo utiliza db.sql_tokenized.
Para Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-29T00:00:00Z\ --end-time2018-10-30T00:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-29T00:00:00Z^ --end-time2018-10-30T00:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
Este ejemplo consulta durante 24 horas, con un periodo de una hora en segundos.
El ejemplo especifica la métrica de db.load.avg y un GroupBy de los siete eventos de espera principales. Para obtener detalles acerca de los valores válidos para este ejemplo, consulte DimensionGroup en la Referencia de la API de Performance Insights.
La respuesta tiene un aspecto similar a la siguiente.
{ "AlignedStartTime": 1540771200.0, "AlignedEndTime": 1540857600.0, "Identifier": "db-XXX", "MetricList": [ //11 entries in the MetricList { "Key": { //First key is total "Metric": "db.load.avg" } "DataPoints": [ //Each DataPoints list has 24 per-hour Timestamps and a value { "Value": 1.6964980544747081, "Timestamp": 1540774800.0 }, //... 24 datapoints ] }, { "Key": { //Next key is the top tokenized SQL "Dimensions": { "db.sql_tokenized.statement": "INSERT INTO authors (id,name,email) VALUES\n( nextval(?) ,?,?)", "db.sql_tokenized.db_id": "pi-2372568224", "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" }, "Metric": "db.load.avg" }, "DataPoints": [ //... 24 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized SQL, 1 total key ] //End of MetricList } //End of response
Esta respuesta tiene 11 entradas en la MetricList (1 total, 10 SQL tokenizadas principales) y cada entrada tiene 24 DataPoints por hora.
Para consultas SQL tokenizadas, hay tres entradas en cada lista de dimensiones:
-
db.sql_tokenized.statement: la instrucción SQL tokenizada. -
db.sql_tokenized.db_id: el ID de base de datos nativo utilizado para hacer referencia a SQL, o un ID sintético que genera Performance Insights para usted si no se encuentra disponible el ID de base de datos nativo. Este ejemplo devuelve el ID sintético depi-2372568224. -
db.sql_tokenized.id: el ID de la consulta dentro del panel Performance Insights.En la AWS Management Console, este ID se denomina ID de soporte. Se denomina así porque el ID es sobre datos que AWS Support puede examinar para ayudarle a solucionar un problema con la base de datos. AWS se toma muy en serio la seguridad y privacidad de sus datos, y casi todos los datos se almacenan encriptados con su clave AWS KMS. Por lo tanto, nadie dentro de AWS puede ver estos datos. En el ejemplo anterior, tanto
tokenized.statementcomotokenized.db_idse almacenan cifrados. Si tiene un problema con su base de datos, AWS Support puede ayudarle, ya que hace referencia al ID de Support.
Al realizar consultas, puede ser conveniente especificar un Group en GroupBy. Sin embargo, para un control de más precisión sobre los datos que se devuelven, especifique la lista de dimensiones. Por ejemplo, si todo lo que se necesita es db.sql_tokenized.statement, entonces se puede añadir un atributo Dimensions al archivo query.json.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Dimensions":["db.sql_tokenized.statement"], "Limit": 10 } } ]
Recuperación del promedio de carga de base de datos filtrado por SQL
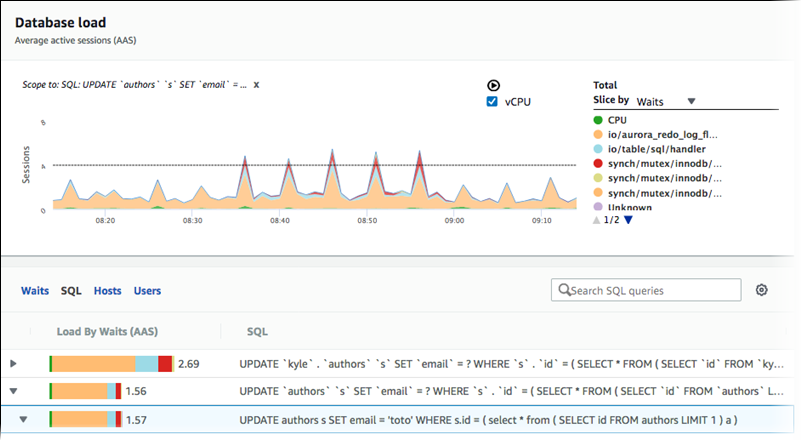
La imagen anterior muestra que se ha seleccionado una consulta concreta y el gráfico de línea de área apilada de principales sesiones activas promedio se limita a esa consulta. Aunque se siguen consultando los siete eventos de espera generales principales, se filtra el valor de la respuesta. El filtro hace que solo tenga en cuenta las sesiones que coinciden con el filtro concreto.
La consulta de API correspondiente en este ejemplo es similar al comando en Recuperación del promedio de carga de base de datos para las instrucciones SQL principales. Sin embargo, el archivo query.json tiene los elementos indicados a continuación.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 5 }, "Filter": { "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
Para Linux, macOS o Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
La respuesta tiene un aspecto similar a la siguiente.
{ "Identifier": "db-XXX", "AlignedStartTime": 1556215200.0, "MetricList": [ { "Key": { "Metric": "db.load.avg" }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.4878117913832196 }, { "Timestamp": 1556222400.0, "Value": 1.192823803967328 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/aurora_redo_log_flush" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.1360544217687074 }, { "Timestamp": 1556222400.0, "Value": 1.058051341890315 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/table/sql/handler" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.16241496598639457 }, { "Timestamp": 1556222400.0, "Value": 0.05163360560093349 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/aurora_lock_thread_slot_futex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.11479591836734694 }, { "Timestamp": 1556222400.0, "Value": 0.013127187864644107 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "CPU", "db.wait_event.name": "CPU" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.05215419501133787 }, { "Timestamp": 1556222400.0, "Value": 0.05805134189031505 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/lock_wait_mutex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.017573696145124718 }, { "Timestamp": 1556222400.0, "Value": 0.002333722287047841 } ] } ], "AlignedEndTime": 1556222400.0 } //end of response
En esta respuesta, todos los valores se filtran según la contribución del SQL tokenizado AKIAIOSFODNN7EXAMPLE especificado en el archivo query.json. Las claves también podrían seguir un orden distinto de una consulta sin un filtro, porque el SQL filtrado afectaba a los cinco eventos de espera principales.
Recuperación del texto completo de una instrucción SQL
En el siguiente ejemplo se recupera el texto completo de una instrucción SQL para una instancia de base de datos db-10BCD2EFGHIJ3KL4M5NO6PQRS5. El --group es db.sql y el --group-identifier es db.sql.id. En este ejemplo, my-sql-id representa un ID de SQL recuperado al invocar a pi
get-resource-metrics opi describe-dimension-keys.
Ejecute el siguiente comando.
Para Linux, macOS o Unix:
aws pi get-dimension-key-details \ --service-type RDS \ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 \ --group db.sql \ --group-identifiermy-sql-id\ --requested-dimensions statement
Para Windows:
aws pi get-dimension-key-details ^ --service-type RDS ^ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 ^ --group db.sql ^ --group-identifiermy-sql-id^ --requested-dimensions statement
En este ejemplo, los detalles de las dimensiones están disponibles. Por lo tanto, Performance Insights recupera el texto completo de la instrucción SQL, sin truncarlo.
{ "Dimensions":[ { "Value": "SELECT e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id", "Dimension": "db.sql.statement", "Status": "AVAILABLE" }, ... ] }
Creación de un informe de análisis de rendimiento para un período de tiempo
En el siguiente ejemplo, se crea un informe de análisis de rendimiento con la hora de inicio 1682969503 y la hora de finalización 1682979503 para la base de datos db-loadtest-0.
aws pi create-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --start-time 1682969503 \ --end-time 1682979503 \ --region us-west-2
La respuesta es el identificador único report-0234d3ed98e28fb17 para el informe.
{ "AnalysisReportId": "report-0234d3ed98e28fb17" }
Recuperación de un informe de análisis de rendimiento
En el siguiente ejemplo se recuperan los detalles del informe de análisis del informe report-0d99cc91c4422ee61.
aws pi get-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
La respuesta proporciona el estado del informe, el identificador, los detalles del tiempo y la información.
{ "AnalysisReport": { "Status": "Succeeded", "ServiceType": "RDS", "Identifier": "db-loadtest-0", "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61", "EndTime": 1680587086.584, "CreateTime": 1680587087.139, "Insights": [ ... (Condensed for space) ] } }
Enumeración de todos los informes de análisis de rendimiento de la instancia de base de datos
En el siguiente ejemplo se enumeran todos los informes de análisis de rendimiento disponibles para la base de datos db-loadtest-0.
aws pi list-performance-analysis-reports \ --service-type RDS \ --identifier db-loadtest-0 \ --region us-west-2
La respuesta enumera todos los informes con el ID del informe, el estado y los detalles del período de tiempo.
{ "AnalysisReports": [ { "Status": "Succeeded", "EndTime": 1680587086.584, "CreationTime": 1680587087.139, "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61" }, { "Status": "Succeeded", "EndTime": 1681491137.914, "CreationTime": 1681491145.973, "StartTime": 1681487537.914, "AnalysisReportId": "report-002633115cc002233" }, { "Status": "Succeeded", "EndTime": 1681493499.849, "CreationTime": 1681493507.762, "StartTime": 1681489899.849, "AnalysisReportId": "report-043b1e006b47246f9" }, { "Status": "InProgress", "EndTime": 1682979503.0, "CreationTime": 1682979618.994, "StartTime": 1682969503.0, "AnalysisReportId": "report-01ad15f9b88bcbd56" } ] }
Eliminación de un informe de análisis de rendimiento
En el siguiente ejemplo, se elimina el informe de análisis de la base de datos db-loadtest-0.
aws pi delete-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
Adición de una etiqueta a un informe de análisis de rendimiento
En el siguiente ejemplo, se agrega una etiqueta con una clave name y valor test-tag al informe report-01ad15f9b88bcbd56.
aws pi tag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tags Key=name,Value=test-tag \ --region us-west-2
Enumeración de todas las etiquetas de un informe de análisis de rendimiento
En el ejemplo siguiente se enumeran todas las etiquetas del informe report-01ad15f9b88bcbd56.
aws pi list-tags-for-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --region us-west-2
La respuesta enumera el valor y la clave de todas las etiquetas agregadas al informe:
{ "Tags": [ { "Value": "test-tag", "Key": "name" } ] }
Eliminación de etiquetas de un informe de análisis de rendimiento
En el siguiente ejemplo se elimina la etiqueta name de un informe report-01ad15f9b88bcbd56.
aws pi untag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tag-keys name \ --region us-west-2
Después de eliminar la etiqueta, llamar a la API list-tags-for-resource no muestra esta etiqueta.
