Información general sobre la importación de datos desde los datos de Amazon S3
Para importar datos de S3 en Aurora PostgreSQL , realice el siguiente procedimiento:
Primero, reúna los detalles que necesita proporcionar a la función. Entre ellos se incluye el nombre de la tabla en la instancia del clúster de base de datos de Aurora PostgreSQL, y el nombre del bucket, la ruta del archivo, el tipo de archivo y la Región de AWS donde se almacenan los datos de Amazon S3. Para obtener más información, consulte el tema para ver un objeto en la guía del usuario de Amazon Simple Storage Service.
nota
Actualmente no se admite la importación de datos multiparte desde Amazon S3.
Obtenga el nombre de la tabla en la que la función
aws_s3.table_import_from_s3va a importar los datos. A modo de ejemplo, el siguiente comando crea una tablat1que se puede utilizar en pasos posteriores.postgres=>CREATE TABLE t1 (col1 varchar(80), col2 varchar(80), col3 varchar(80));Obtenga información sobre el bucket de Amazon S3 y los datos que se van a importar. Para ello, abra la consola de Amazon S3 en https://console.aws.amazon.com/s3/
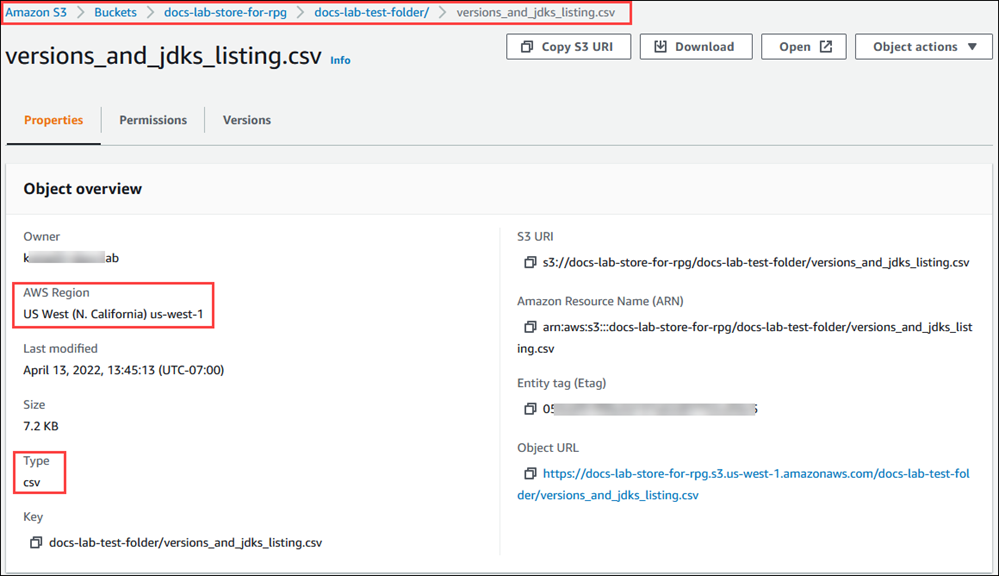
y elija Buckets. Busque el bucket que contiene sus datos en la lista. Elija el bucket, abra la página de información general de objetos y, a continuación, Properties (Propiedades). Anote el nombre del bucket, la ruta, la Región de AWS y el tipo de archivo. Necesitará el nombre de recurso de Amazon (ARN) más adelante para configurar el acceso a Amazon S3 a través de un rol de IAM. Para obtener más información, consulte Configuración del acceso a un bucket de Amazon S3. En la siguiente imagen se muestra un ejemplo.
Para verificar la ruta a los datos en el bucket de Amazon S3, utilice el comando de AWS CLI
aws s3 cp. Si la información es correcta, este comando descarga una copia del archivo de Amazon S3.aws s3 cp s3://amzn-s3-demo-bucket/sample_file_path./-
Configure los permisos de clúster de base de datos de Aurora PostgreSQL para permitir el acceso al archivo en el bucket de Amazon S3. Para ello, utilice un rol de AWS Identity and Access Management (IAM) o las credenciales de seguridad. Para obtener más información, consulte Configuración del acceso a un bucket de Amazon S3.
Proporcione la ruta y otros detalles del objeto de Amazon S3 recopilados (consulte el paso 2) para la función
create_s3_uripara construir un objeto URI de Amazon S3. Para obtener más información sobre esta función, consulte aws_commons.create_s3_uri. A continuación se muestra un ejemplo de cómo construir este objeto durante una sesión de psql.postgres=>SELECT aws_commons.create_s3_uri( 'docs-lab-store-for-rpg', 'versions_and_jdks_listing.csv', 'us-west-1' ) AS s3_uri \gsetEn el paso siguiente, pase este objeto (
aws_commons._s3_uri_1) a la funciónaws_s3.table_import_from_s3para importar los datos a la tabla.-
Invoque la función
aws_s3.table_import_from_s3para importar los datos de Amazon S3 a la tabla. Para obtener información de referencia, consulte aws_s3.table_import_from_s3. Para ver ejemplos, consulte Importación de datos de Amazon S3 a un clúster de base de datos de Aurora PostgreSQL .
