Incorporación de una Región de AWS a una base de datos global de Amazon Aurora
Puede usar el siguiente procedimiento para añadir un clúster secundario adicional a una base de datos global existente. También puede crear una base de datos global a partir de un clúster de base de datos de Aurora independiente mediante este procedimiento para añadir la primera región de AWS secundaria.
Una base de datos global de Aurora necesita al menos un clúster de base de datos de Aurora secundario en una Región de AWS diferente que la del clúster principal de base de datos de Aurora. Puede adjuntar hasta 10 clústeres de base de datos secundarios a la base de datos global de Aurora. Repita el siguiente procedimiento para cada clúster de base de datos secundario nuevo. Para cada clúster de base de datos secundaria que agregue a la base de datos de Aurora global, reduzca el número de réplicas de Aurora permitidas en el clúster de base de datos principal a una.
Por ejemplo, si la base de datos global de Aurora tiene 10 regiones secundarias, el clúster de la base de datos principal solo puede tener 5 (en lugar de 15) réplicas de Aurora. Para obtener más información, consulte Requisitos de configuración de una base de datos Amazon Aurora global.
El número de réplicas de Aurora (instancias de lectura) en el clúster de base de datos principal determina el número de clústeres de base de datos secundarias que puede agregar. El número total de instancias de lectura en el clúster de base de datos principal más el número de clústeres secundarios no puede ser mayor de 15. Por ejemplo, si tiene 14 instancias de lectura en el clúster de base de datos principal y 1 clúster secundario, no puede agregar otro clúster secundario a la base de datos global.
nota
En el caso de la versión 3 de Aurora MySQL, cuando cree un clúster secundario, asegúrese de que el valor de lower_case_table_names coincida con el valor del clúster principal. Esta configuración es un parámetro de la base de datos que afecta la forma en que el servidor gestiona la distinción entre mayúsculas y minúsculas del identificador. Para obtener más información acerca de los parámetros de la base de datos, consulte Grupos de parámetros para Amazon Aurora.
Se recomienda que, al crear un clúster secundario, utilice la misma versión del motor de base de datos para el principal y el secundario. Si es necesario, actualice la versión principal para que tenga la misma versión que la secundaria. Para obtener más información, consulte Compatibilidad de los niveles de parche para la transición o conmutación por error administrada entre regiones.
Para agregar una Región de AWS a una base de datos global de Aurora
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
En el panel de navegación de la AWS Management Console, elija Databases (Bases de datos).
-
Elija la base de datos Aurora global que necesita un clúster de base de datos Aurora secundario. Asegúrese de que el clúster de Aurora base de datos principal es
Available. -
En Acciones, elija Agregar región de AWS.

-
En la página Add a region (Agregar una región), seleccione la Región de AWS secundaria.
No puede elegir una Región de AWS que ya tenga un clúster secundario de base de datos de Aurora para la misma base de datos global de Aurora. Además, no puede ser la misma región que el clúster principal de la base de datos de Aurora.
nota
Las bases de datos globales de Babelfish para Aurora PostgreSQL solo funcionan en regiones secundarias si los parámetros que controlan las preferencias de Babelfish están activados en esas regiones. Para obtener más información, consulte Configuración del grupo de parámetros del clúster de base de datos para Babelfish

-
Complete los campos restantes para el clúster secundario de Aurora en la nueva región de AWS. Estas son las mismas opciones de configuración que para cualquier instancia de clúster de base de datos de Aurora, excepto la siguiente opción solo para bases de datos globales de Aurora basadas en Aurora MySQL–:
Habilitar el reenvío de escritura de réplica de lectura – Esta configuración opcional permite que los clústeres secundarios de la base de datos global de Aurora reenvíen operaciones de escritura al clúster principal. Para obtener más información, consulte Uso del reenvío de escritura en una base de datos Amazon Aurora global.

Elija Agregar región de AWS.
Después de terminar de agregar la región a la base de datos de Aurora global, puede verla en la lista de bases de datos en la AWS Management Console como se muestra en la captura de pantalla.
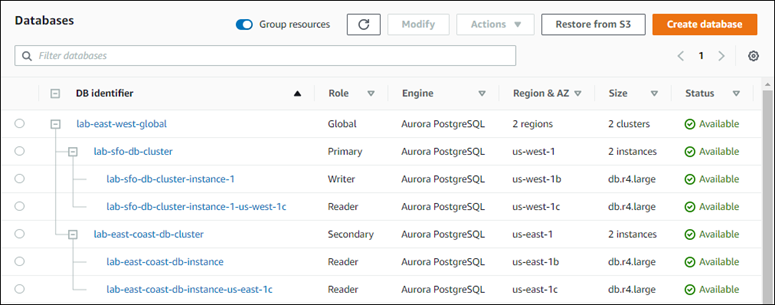
Para agregar una Región de AWS secundaria a una base de datos global de Aurora
Para añadir un clúster secundario a la base de datos global mediante la CLI, debe disponer ya del objeto contenedor del clúster global. Si aún no ha ejecutado el comando create-global-cluster, consulte el procedimiento de la CLI en Creación de una base de datos global de Amazon Aurora.
-
Utilice el comando
create-db-clusterCLI con el nombre (--global-cluster-identifier) de la base de datos Aurora global. Para otros parámetros, haga lo siguiente: Para
--region, elija una Región de AWS diferente a la de la región de Aurora principal.-
Elija valores específicos para los parámetros
--enginey--engine-version. Estos valores son los mismos que los del clúster principal de base de datos de Aurora de la base de datos global de Aurora. Para un clúster cifrado, especifique la Región de AWS principal como
--source-regionpara cifrado.
En el ejemplo siguiente se crea un nuevo clúster de base de datos Aurora y se adjunta a una base de datos Aurora global como clúster de base de datos Aurora secundario de solo lectura. En el último paso, se agrega una instancia Aurora de base de datos al nuevo clúster de Aurora base de datos.
Para Linux, macOS o Unix:
aws rds --regionsecondary_region\ create-db-cluster \ --db-cluster-identifiersecondary_cluster_id\ --global-cluster-identifierglobal_database_id\ --engineaurora-mysql | aurora-postgresql\ --engine-versionversionaws rds --regionsecondary_region\ create-db-instance \ --db-instance-classinstance_class\ --db-cluster-identifiersecondary_cluster_id\ --db-instance-identifierdb_instance_id\ --engineaurora-mysql | aurora-postgresql
Para Windows:
aws rds --regionsecondary_region^ create-db-cluster ^ --db-cluster-identifiersecondary_cluster_id^ --global-cluster-identifierglobal_database_id_id^ --engineaurora-mysql | aurora-postgresql^ --engine-versionversionaws rds --regionsecondary_region^ create-db-instance ^ --db-instance-classinstance_class^ --db-cluster-identifiersecondary_cluster_id^ --db-instance-identifierdb_instance_id^ --engineaurora-mysql | aurora-postgresql
Para agregar una nueva Región de AWS a una base de datos global de Aurora con la API de RDS, ejecute la operación CreateDBCluster. Especifique el identificador de la base de datos global existente utilizando el parámetro GlobalClusterIdentifier.
