Agregación de datos a un clúster de base de datos de Aurora de origen y realización de consultas
Para terminar de crear una integración sin ETL que replique los datos de Amazon Aurora en Amazon Redshift, debe crear una base de datos en el destino.
Para conexiones con Amazon Redshift, conéctese al clúster o grupo de trabajo de Amazon Redshift y cree una base de datos con una referencia al identificador de integración. A continuación, puede agregar datos al clúster de base de datos de Aurora de origen y verlos replicados en Amazon Redshift o Amazon SageMaker.
Temas
Creación de una base de datos de destino
Antes de empezar a replicar datos en Amazon Redshift y después de crear una integración, debe crear una base de datos en el almacén de datos de destino. Esta base de datos debe incluir una referencia al identificador de integración. También puede utilizar la consola de Amazon Redshift o el editor de consultas v2 para crear la base de datos.
Para obtener instrucciones sobre cómo crear una base de datos de destino, consulte Creación de una base de datos de destino en Amazon Redshift.
Añadir datos al clúster de base de datos de origen
Tras configurar la integración, puede completar el clúster de base de datos de Aurora de origen con datos que desea replicar en el almacén de datos.
nota
Existen diferencias entre los tipos de datos en Amazon Aurora y el almacén de análisis de destino. Para consultar una tabla de correspondencias de tipos de datos, consulte Diferencias de tipos de datos entre las bases de datos Aurora y Amazon Redshift.
Primero, conéctese al clúster de base datos de origen mediante el cliente MySQL o PostgreSQL que prefiera. Para obtener instrucciones, consulte Conexión a un clúster de base de datos Amazon Aurora.
A continuación, cree una tabla e inserte una fila de datos de muestra.
importante
Asegúrese de que la tabla tenga una clave principal. De lo contrario, no se podrá replicar en el almacenamiento de datos de destino.
Las utilidades pg_dump y pg_restore de PostgreSQL crean inicialmente tablas sin una clave principal y, después, la agregan. Si utiliza una de estas utilidades, le recomendamos que cree primero un esquema y, a continuación, cargue los datos en un comando independiente.
MySQL
En el siguiente ejemplo se usa la utilidad MySQL Workbench
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
PostgreSQL
En el siguiente ejemplo, se utiliza el terminal interactivo psql de PostgreSQL. Al conectarse al clúster, incluya la base de datos con nombre que especificó al crear la integración.
psql -hmycluster.cluster-123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
Consulta de los datos de en Amazon Redshift
Después de agregar datos al clúster de base datos de Aurora, se replican en la base de datos de destino y ya se pueden consultar.
Consulta de datos replicados
-
Vaya a la consola de Amazon Redshift y seleccione el editor de consultas v2 en el panel de navegación izquierdo.
-
Conéctese a su clúster o grupo de trabajo y elija su base de datos de destino (la que creó a partir de la integración) en el menú desplegable (destination_database en este ejemplo). Para obtener instrucciones sobre cómo crear una base de datos de destino, consulte Creación de una base de datos de destino en Amazon Redshift.
-
Utilice una instrucción SELECT para consultar los datos. En este ejemplo, puede ejecutar el siguiente comando para seleccionar todos los datos de la tabla que creó en el clúster de base datos de Aurora de origen:
SELECT * frommy_db."books_table";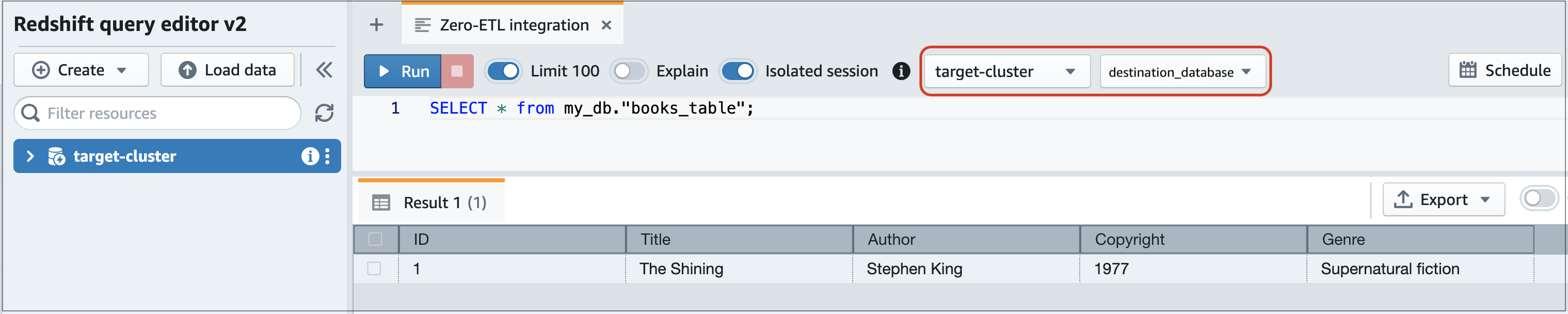
-
my_db -
books_table
-
También puede consultar los datos mediante un cliente de línea de comandos. Por ejemplo:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
nota
Para distinguir entre mayúsculas y minúsculas, utilice comillas dobles (" ") para los nombres de esquemas, tablas y columnas. Para obtener más información, consulte enable_case_sensitive_identifier.
Diferencias de tipos de datos entre las bases de datos Aurora y Amazon Redshift
Las siguientes tablas muestran las asignaciones de Aurora MySQL y Aurora PostgreSQL a tipos de datos de destino correspondiente. Actualmente, Amazon Aurora solo admite estos tipos de datos para integraciones sin ETL.
Si una tabla de la base de datos de origen incluye un tipo de datos no compatible, la tabla no se sincroniza y el destino no puede utilizarla. La transmisión desde el origen al destino continúa, pero la tabla con el tipo de datos no admitido no está disponible. Para corregir la tabla y hacer que esté disponible en el destino, debe revertir manualmente el cambio de ruptura y, a continuación, actualizar la integración ejecutando ALTER DATABASE...INTEGRATION
REFRESH.
nota
No puede actualizar las integraciones sin ETL con un Amazon SageMaker Lakehouse. En su lugar, elimine e intente crear la integración de nuevo.
Aurora MySQL
| Tipo de datos de o Aurora MySQL | Tipo de datos de destino | Descripción | Limitaciones |
|---|---|---|---|
| INT | INTEGER | Entero firmado de cuatro bytes | Ninguno |
| SMALLINT | SMALLINT | Entero firmado de dos bytes | Ninguno |
| TINYINT | SMALLINT | Entero firmado de dos bytes | Ninguno |
| MEDIUMINT | INTEGER | Entero firmado de cuatro bytes | Ninguno |
| BIGINT | BIGINT | Entero firmado de ocho bytes | Ninguno |
| INT UNSIGNED | BIGINT | Entero firmado de ocho bytes | Ninguno |
| TINYINT UNSIGNED | SMALLINT | Entero firmado de dos bytes | Ninguno |
| MEDIUMINT UNSIGNED | INTEGER | Entero firmado de cuatro bytes | Ninguno |
| BIGINT UNSIGNED | DECIMAL(20,0) | Numérico exacto de precisión seleccionable | Ninguno |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL(p,s) | Numérico exacto de precisión seleccionable |
No se admiten precisiones superiores a 38 ni escalas superiores a 37 |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL(p,s) | Numérico exacto de precisión seleccionable |
No se admiten precisiones superiores a 38 ni escalas superiores a 37 |
| FLOAT4/REAL | REAL | Número en coma flotante de precisión única | Ninguno |
| FLOAT4/REAL UNSIGNED | REAL | Número en coma flotante de precisión única | Ninguno |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | Número en coma flotante de precisión doble | Ninguno |
| DOUBLE/REAL/FLOAT8 UNSIGNED | DOUBLE PRECISION | Número en coma flotante de precisión doble | Ninguno |
| BIT(n) | VARBYTE (8) | Valor binario de longitud variable | Ninguno |
| BINARY(n) | VARBYTE(n) | Valor binario de longitud variable | Ninguno |
| VARBINARY(n) | VARBYTE(n) | Valor binario de longitud variable | Ninguno |
| CHAR (n) | VARCHAR(n) | Valor de cadena de longitud variable | Ninguno |
| VARCHAR(n) | VARCHAR(n) | Valor de cadena de longitud variable | Ninguno |
| TEXT | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| TINYTEXT | VARCHAR(255) | Valor de cadena de longitud variable de hasta 255 caracteres | Ninguno |
| MEDIUMTEXT | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| LONGTEXT | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| ENUM | VARCHAR(1020) | Valor de cadena de longitud variable de hasta 1020 caracteres | Ninguno |
| SET | VARCHAR(1020) | Valor de cadena de longitud variable de hasta 1020 caracteres | Ninguno |
| DATE | DATE | Fecha de calendario (año, mes, día) | Ninguno |
| DATETIME | TIMESTAMP | Fecha y hora (sin zona horaria) | Ninguno |
| TIMESTAMP(p) | TIMESTAMP | Fecha y hora (sin zona horaria) | Ninguno |
| TIME | VARCHAR(18) | Valor de cadena de longitud variable de hasta 18 caracteres | Ninguno |
| YEAR | VARCHAR(4) | Valor de cadena de longitud variable de hasta 4 caracteres | Ninguno |
| JSON | SUPER | Datos o documentos semiestructurados como valores | Ninguno |
Aurora PostgreSQL
Las integraciones sin ETL para Aurora PostgreSQL no admiten tipos de datos personalizados ni tipos de datos creados por extensiones.
| Tipos de datos de Aurora PostgreSQL | Tipos de datos de Amazon Redshift | Descripción | Limitaciones |
|---|---|---|---|
| matriz | SUPER | Datos o documentos semiestructurados como valores | Ninguno |
| bigint | BIGINT | Entero firmado de ocho bytes | Ninguno |
| bigserial | BIGINT | Entero firmado de ocho bytes | Ninguno |
| bit varying(n) | VARBYTE(n) | Valor de cadena de longitud variable de hasta 16 777 216 bytes | Ninguno |
| bit(n) | VARBYTE(n) | Valor de cadena de longitud variable de hasta 16 777 216 bytes | Ninguno |
| bit, bit varying | VARBYTE(16777216) | Valor de cadena de longitud variable de hasta 16 777 216 bytes | Ninguno |
| booleano | BOOLEANO | Booleano lógico (true/false) | Ninguno |
| bytea | VARBYTE(16777216) | Valor de cadena de longitud variable de hasta 16 777 216 bytes | Ninguno |
| char(n) | CHAR (n) | Valor de cadena de longitud fija de hasta 65 535 bytes | Ninguno |
| char varying(n) | VARCHAR(65535) | Valor de cadena de caracteres de longitud variable de hasta 65 535 caracteres | Ninguno |
| cid | BIGINT |
Entero firmado de ocho bytes |
Ninguno |
| cidr |
VARCHAR(19) |
Valor de cadena de longitud variable de hasta 19 caracteres |
Ninguno |
| date | DATE | Fecha de calendario (año, mes, día) |
No se admiten valores superiores a 294 276 a. C. |
| double precision | DOUBLE PRECISION | Números con coma flotante de precisión doble | Los valores inferiores a los normales no son totalmente compatibles |
|
gtsvector |
VARCHAR(65535) |
Valor de cadena de longitud variable de hasta 65 535 caracteres |
Ninguno |
| inet |
VARCHAR(19) |
Valor de cadena de longitud variable de hasta 19 caracteres |
Ninguno |
| entero | INTEGER | Entero firmado de cuatro bytes | Ninguno |
|
int2vector |
SUPER | Datos o documentos semiestructurados como valores. | Ninguno |
| intervalo | INTERVAL | Duración del tiempo | Solo se admiten los tipos de INTERVAL que especifican un calificador de año a mes o de un día a otro. |
| json | SUPER | Datos o documentos semiestructurados como valores | Ninguno |
| jsonb | SUPER | Datos o documentos semiestructurados como valores | Ninguno |
| jsonpath | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
|
macaddr |
VARCHAR(17) | Valor de cadena de longitud variable de hasta 17 caracteres | Ninguno |
|
macaddr8 |
VARCHAR(23) | Valor de cadena de longitud variable de hasta 23 caracteres | Ninguno |
| money | DECIMAL(203) | Importe de la divisa | Ninguno |
| name | VARCHAR(64) | Valor de cadena de longitud variable de hasta 64 caracteres | Ninguno |
| numeric(p,s) | DECIMAL(p,s) | Valor de precisión fijo definido por el usuario |
|
| oid | BIGINT | Entero firmado de ocho bytes | Ninguno |
| oidvector | SUPER | Datos o documentos semiestructurados como valores. | Ninguno |
| pg_brin_bloom_summary | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| pg_dependencies | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| pg_lsn | VARCHAR(17) | Valor de cadena de longitud variable de hasta 17 caracteres | Ninguno |
| pg_mcv_list | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| pg_ndistinct | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| pg_node_tree | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| pg_snapshot | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| real | REAL | Número en coma flotante de precisión única | Los valores inferiores a los normales no son totalmente compatibles |
| refcursor | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| smallint | SMALLINT | Entero firmado de dos bytes | Ninguno |
| smallserial | SMALLINT | Entero firmado de dos bytes | Ninguno |
| serial | INTEGER | Entero firmado de cuatro bytes | Ninguno |
| text | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| tid | VARCHAR(23) | Valor de cadena de longitud variable de hasta 23 caracteres | Ninguno |
| Hora [(p)] sin zona horaria | VARCHAR(19) | Valor de cadena de longitud variable de hasta 19 caracteres | No se admiten valores Infinity y -Infinity |
| time [(p)] con zona horaria | VARCHAR(22) | Valor de cadena de longitud variable de hasta 22 caracteres | No se admiten valores Infinity y -Infinity |
| timestamp [(p)] sin zona horaria | TIMESTAMP | Fecha y hora (sin zona horaria) |
|
| timestamp [(p)] con zona horaria | TIMESTAMPTZ | Fecha y hora (con zona horaria) |
|
| TSQUERY | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| tsvector | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| txid_snapshot | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
| uuid | VARCHAR(36) | Cadena de 36 caracteres de longitud variable | Ninguno |
| xid | BIGINT | Entero firmado de ocho bytes | Ninguno |
| xid8 | DECIMAL(20, 0) | Decimal de precisión fija | Ninguno |
| xml | VARCHAR(65535) | Valor de cadena de longitud variable de hasta 65 535 caracteres | Ninguno |
Operaciones DDL para Aurora PostgreSQL
Amazon Redshift se deriva de PostgreSQL, por lo que comparte varias características con Aurora PostgreSQL debido a su arquitectura PostgreSQL común. Las integraciones sin ETL aprovechan estas similitudes para agilizar la replicación de datos desde Aurora PostgreSQL a Amazon Redshift, asignando las bases de datos por nombre y utilizando la base de datos, el esquema y la estructura de tablas compartidos.
Tenga en cuenta los siguientes puntos al administrar las integraciones sin ETL de Aurora PostgreSQL:
-
El aislamiento se administra por base de datos.
-
La replicación se produce por base de datos.
-
Las bases de datos de Aurora PostgreSQL se asignan a las bases de datos de Amazon Redshift por nombre, con datos que fluyen a la base de datos de Redshift con el nombre correspondiente si se cambia el nombre de la original.
A pesar de sus similitudes, Amazon Redshift y Aurora PostgreSQL presentan diferencias importantes. En las siguientes secciones se describen las respuestas del sistema Amazon Redshift para las operaciones de DDL más comunes.
Operaciones de base de datos
En la siguiente tabla, se muestran las respuestas del sistema para las operaciones de DDL de base de datos.
| Operaciones DDL | Respuesta del sistema Redshift |
|---|---|
CREATE DATABASE |
Sin operación |
DROP DATABASE |
Amazon Redshift elimina todos los datos de la base de datos Redshift de destino. |
RENAME DATABASE |
Amazon Redshift elimina todos los datos de la base de datos de destino original y vuelve a sincronizarlos en la nueva base de datos de destino. Si la nueva base de datos no existe, debe crearla manualmente. Para obtener instrucciones, consulte Creación de bases de datos de destino en Amazon Redshift. |
Operaciones de esquema
En la siguiente tabla, se muestran las respuestas del sistema para las operaciones DDL de esquema.
| Operaciones DDL | Respuesta del sistema Redshift |
|---|---|
CREATE SCHEMA |
Sin operación |
DROP SCHEMA |
Amazon Redshift elimina el esquema original. |
RENAME SCHEMA |
Amazon Redshift elimina el esquema original y, a continuación, vuelve a sincronizar los datos en el nuevo esquema. |
Operaciones de tabla
En la siguiente tabla, se muestran las respuestas del sistema para las operaciones DDL de tabla.
| Operaciones DDL | Respuesta del sistema Redshift |
|---|---|
CREATE TABLE |
Amazon Redshift crea la tabla. Algunas operaciones provocan un error en la creación de la tabla, como la creación de una tabla sin una clave principal o la realización de particiones declarativas. Para obtener más información, consulte Limitaciones y Solución de problemas de integraciones sin ETL de Aurora. |
DROP TABLE |
Amazon Redshift elimina la tabla. |
TRUNCATE TABLE |
Amazon Redshift trunca la tabla. |
ALTER TABLE
(RENAME...) |
Amazon Redshift cambia el nombre de la tabla o columna. |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift elimina la tabla del esquema original y vuelve a sincronizar la tabla en el nuevo esquema. |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift agregue una clave principal y vuelve a sincronizar la tabla. |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift agrega una columna a la tabla. |
ALTER TABLE (DROP
COLUMN) |
Amazon Redshift elimina la columna si no es una columna de clave principal. De lo contrario, vuelve a sincronizar la tabla. |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
Si cambia la tabla a registrada, Amazon Redshift vuelve a sincronizarla. Si cambia la tabla a no registrada, Amazon Redshift la elimina. |
