Implementaciones de clústeres de base de datos multi-AZ para Amazon RDS
La implementación de un clúster de base de datos multi-AZ es un modo de implementación de alta disponibilidad semisíncrono de Amazon RDS con dos instancias de base de datos de réplica legibles. Un clúster de base de datos Multi-AZ tiene una instancia de base de datos del escritor y dos instancias de base de datos del lector en tres zonas de disponibilidad diferentes en la misma Región de AWS. Los clústeres de base de datos Multi-AZ proporcionan alta disponibilidad, mayor capacidad para cargas de trabajo de lectura y menor latencia de escritura en comparación con las implementaciones de las instancias de base de datos Multi-AZ.
Puede importar datos de una base de datos en las instalaciones a un clúster de base de datos Multi-AZ siguiendo las instrucciones de Importación de datos a una base de datos de Amazon RDS para MySQL con un tiempo de inactividad reducido.
Puede comprar instancias de base de datos reservadas para un clúster de base de datos multi-AZ. Para obtener más información, consulte Instancias de base de datos reservadas para un clúster de base de datos multi-AZ.
La disponibilidad de las características varía según las versiones específicas de cada motor de base de datos y entre Regiones de AWS. Para obtener más información sobre la disponibilidad en versiones y regiones de Amazon RDS con clústeres de base de datos Multi-AZ, consulte Regiones y motores de base de datos admitidos para clústeres de bases de datos Multi-AZ en Amazon RDS.
Temas
Disponibilidad de clase de instancia para los clústeres de base de datos multi-AZ
Grupos de parámetros para clústeres de base de datos multi-AZ
Creación de un clúster de base de datos multi-AZ para Amazon RDS
Conexión a un clúster de base de datos multi-AZ para Amazon RDS
Modificación de un clúster de base de datos multi-AZ para Amazon RDS.
Actualización de la versión del motor de un clúster de base de datos multi-AZ para Amazon RDS
Cambio de nombre de un clúster de base de datos multi-AZ para Amazon RDS
Conmutación por error de un clúster de base de datos multi-AZ para Amazon RDS
Uso de réplicas de lectura de clústeres de base de datos multi-AZ para Amazon RDS
Eliminación de un clúster de base de datos multi-AZ para Amazon RDS
Limitaciones de clústeres de base de datos multi-AZ para Amazon RDS
importante
Los clústeres de base de datos multi-AZ no son los mismos que los clústeres de base de datos de Aurora. Para obtener información acerca de los clústeres de base de datos de Amazon Aurora, consulte la Guía del usuario de Amazon Aurora.
Disponibilidad de clase de instancia para los clústeres de base de datos multi-AZ
Las implementaciones de clústeres de bases de datos multi-AZ son compatibles con las siguientes clases de instancias de base de datos: db.c6gd, db.m5d, db.m6gd, db.m6id, db.m6idn, db.m8gd, db.r5d, db.r6gd, db.r6id, db.r6idn, db.r8gd y db.x2iedn.
nota
Las clases de instancias c6gd son las únicas que admiten el tamaño de la instancia medium.
Para obtener más información sobre las clases de instancias de bases de datos, consulte Clases de instancia de base de datos de .
Arquitectura de clúster de base de datos multi-AZ
Con un clúster de base de datos Multi-AZ, Amazon RDS replica los datos de la instancia de base de datos del escritor en las dos instancias de base de datos del lector mediante las capacidades de replicación nativa del motor de base de datos. Cuando se realiza un cambio en la instancia de base de datos del escritor, se envía a cada instancia de base de datos del lector.
Las implementaciones de clústeres de base de datos multi-AZ utilizan la replicación semisíncrona, que requiere el reconocimiento de al menos una instancia de base de datos del lector para confirmar un cambio. No es necesario que se reconozca que los eventos se han ejecutado y confirmado en su totalidad en todas las réplicas.
Las instancias de base de datos del lector actúan como destinos de la conmutación por error automática y también proporcionan tráfico de lectura para aumentar el rendimiento de lectura de las aplicaciones. Si se produce una interrupción en la instancia de base de datos de escritor, RDS administra la conmutación por error a una de las instancias de base de datos de lector. RDS hace esto en función de qué instancia de base de datos del lector tiene el registro de cambios más reciente.
El siguiente diagrama muestra un clúster de base de datos Multi-AZ.
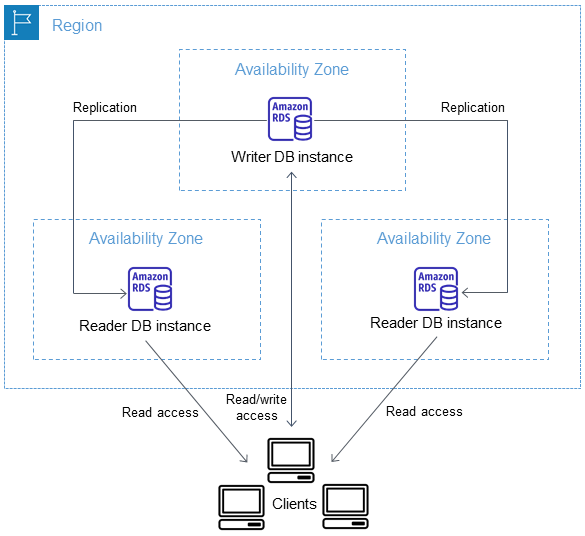
Los clústeres de base de datos Multi-AZ suelen tener menor latencia de escritura en comparación con las implementaciones de instancias de base de datos Multi-AZ. También permiten que las cargas de trabajo de solo lectura se ejecuten en instancias de base de datos del lector. La consola de RDS muestra la zona de disponibilidad de la instancia de base de datos del escritor y las zonas de disponibilidad de las instancias de base de datos del lector. También puede utilizar el comando de la CLI describe-db-clusters o la operación de la API DescribeDBClusters para encontrar esta información.
importante
Para evitar errores de réplica en clústeres de base de datos Multi-AZ de RDS para MySQL, recomendamos encarecidamente que todas las tablas tengan una clave principal.
Grupos de parámetros para clústeres de base de datos multi-AZ
En un clúster de base de datos Multi-AZ, un grupo de parámetros del clúster de base de datos funciona como un contenedor de los valores de configuración del motor que se aplican a cada instancia de base de datos en un clúster de base de datos Multi-AZ.
En un clúster de base de datos Multi-AZ, un grupo de parámetros de base de datos se establece en el grupo de parámetros de base de datos predeterminado para el motor de base de datos y la versión del motor de base de datos. La configuración del grupo de parámetros del clúster de base de datos se utiliza para todas las instancias de base de datos del clúster.
Para obtener información acerca de los grupos de parámetros, consulte Trabajo con grupos de parámetros de clúster de base de datos para clústeres de base de datos Multi-AZ.
RDS Proxy con clústeres de bases de datos multi-AZ
Puede utilizar Amazon RDS Proxy para crear un proxy para sus clústeres de base de datos multi-AZ. Con RDS Proxy, las aplicaciones pueden agrupar y compartir conexiones de base de datos para mejorar su capacidad de escala. Todos los proxy hacen multiplexación de conexión, algo conocido también como reutilización de la conexión. Con la multiplexación, el proxy de RDS realiza todas las operaciones de una transacción mediante una conexión de base de datos subyacente. RDS Proxy también puede reducir el tiempo de inactividad de una actualización de una versión secundaria de un clúster de base de datos multi-AZ a un segundo o menos. Para obtener más información sobre las ventajas de RDS Proxy, consulte Amazon RDS Proxy.
Para configurar un proxy para un clúster de base de datos Multi-AZ, seleccione Creación de un proxy de RDS al crear el clúster. Para obtener instrucciones sobre cómo crear y administrar los puntos de conexión del proxy de RDS, consulte Trabajo con puntos de enlace del proxy de Amazon RDS.
Retraso de réplica y clústeres de base de datos Multi-AZ
El retraso de réplica es la diferencia de tiempo entre la última transacción en la instancia de base de datos del escritor y la última transacción aplicada en una instancia de base de datos del lector. La métrica ReplicaLag de Amazon CloudWatch representa esta diferencia de tiempo. Para obtener más información acerca de las métricas de CloudWatch, consulte Supervisión de métricas de Amazon RDS con Amazon CloudWatch.
Aunque los clústeres de bases de datos Multi-AZ permiten un alto rendimiento de escritura, puede producirse un retraso de réplica debido a la naturaleza de la replicación basada en motor. Dado que cualquier conmutación por error debe resolver el retraso de réplica antes de promover una nueva instancia de base de datos de escritor, la supervisión y administración de este retraso de réplica es una consideración.
Para clústeres de base de datos RDS para MySQL Multi-AZ, el tiempo de conmutación por error depende del retraso de réplica de las dos instancias de base de datos de lectores restantes. Ambas instancias de base de datos de lectura deben aplicar transacciones no aplicadas antes de que una de ellas se promueva a la nueva instancia de base de datos de escritor.
Para clústeres de base de datos RDS para PostgreSQL Multi-AZ, el tiempo de conmutación por error depende del retraso de réplica más bajo de las dos instancias de base de datos de lector restantes. La instancia de base de datos del lector con el retraso de réplica más bajo debe aplicar transacciones no aplicadas antes de que se promueva a la nueva instancia de base de datos del escritor.
Para ver un tutorial que le muestra cómo crear una alarma de CloudWatch cuando el retraso de la réplica supera una cantidad de tiempo establecida, consulte Tutorial: creación de una alarma de Amazon CloudWatch para el retardo de réplica del clúster de base de datos multi-AZ para Amazon RDS.
Causas comunes del retraso de réplica
En general, el retraso de réplica se produce cuando la carga de trabajo de escritura es demasiado alta para que las instancias de base de datos del lector apliquen las transacciones de manera eficiente. Varias cargas de trabajo pueden provocar un retraso de réplica temporal o continuo. Ejemplos de causas comunes:
-
Alta simultaneidad de escritura o actualización por lotes pesados en la instancia de base de datos del escritor, lo que hace que el proceso de aplicación en las instancias de base de datos del lector se demore.
-
Carga de trabajo de lectura pesada que utiliza recursos en una o más instancias de base de datos del lector. La ejecución de consultas lentas o grandes puede afectar al proceso de aplicación y provocar un retraso de réplica.
-
Las transacciones que modifican grandes cantidades de datos o instrucciones DDL a veces pueden provocar un aumento temporal del retraso de réplica porque la base de datos debe conservar el orden de confirmación.
Mitigación del retraso de réplica
En el caso de los clústeres de bases de datos Multi-AZ para RDS para MySQL y RDS para PostgreSQL, puede reducir la carga de la instancia de base de datos del escritor para mitigar el retraso de réplica. También puede usar el control de flujo para reducir el retraso de la réplica. El control de flujo funciona limitando las escrituras en la instancia de base de datos del escritor, lo que garantiza que el retraso de réplica no siga creciendo de forma ilimitada. La limitación de escritura se logra añadiendo un retardo al final de una transacción, lo que reduce el rendimiento de escritura en la instancia de base de datos del escritor. Aunque el control de flujo no garantiza la eliminación del retraso, puede ayudar a reducir el retraso general en muchas cargas de trabajo. Las siguientes secciones brindan información sobre el uso del control de flujo con RDS para MySQL y RDS para PostgreSQL.
Mitigación del retraso de la réplica con control de flujo para RDS para MySQL
Cuando utiliza RDS para clústeres de base de datos MySQL Multi-AZ, el control de flujo se activa de forma predeterminada mediante el parámetro dinámico rpl_semi_sync_master_target_apply_lag. Este parámetro especifica el límite superior que desea para el retraso de la réplica. A medida que el retardo de la réplica se acerca a este límite configurado, el control de flujo acelera las transacciones de escritura en la instancia de la base de datos del escritor para intentar contener el retardo de la réplica por debajo del valor especificado. En algunos casos, el retraso de réplica supera el límite especificado. De forma predeterminada, este parámetro se establece en 120 segundos. Para desactivar el control de flujo, establezca este parámetro en su valor máximo de 86 400 segundos (un día).
Para ver el retraso actual inyectado por el control de flujo, muestre el parámetro Rpl_semi_sync_master_flow_control_current_delay al ejecturar la siguiente consulta.
SHOW GLOBAL STATUS like '%flow_control%';
El resultado debería tener un aspecto similar al siguiente.
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)nota
El retraso se muestra en microsegundos.
Cuando tiene Información sobre rendimiento activado para un clúster de base de datos RDS para MySQL Multi-AZ, puede supervisar el evento de espera correspondiente a una instrucción SQL que indica que las consultas se retrasaron por un control de flujo. Cuando un control de flujo introdujo un retraso, puede ver el evento de espera /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond correspondiente a la instrucción SQL del panel de Performance Insights (Información sobre rendimiento). Para ver estas métricas, asegúrese de que el esquema de rendimiento esté activado. Para obtener más información acerca de Información sobre rendimiento, consulte Monitoreo de la carga de base de datos con Performance Insights en Amazon RDS.
Mitigación del retraso de la réplica con control de flujo para RDS para PostgreSQL
Cuando utiliza RDS para clústeres de base de datos Multi-AZ de PostgreSQL, el control de flujo se implementa como una extensión. Activa un empleado en segundo plano para todas las instancias de base de datos en el clúster de base de datos. De forma predeterminada, los empleados en segundo plano de las instancias de base de datos del lector comunican el retraso de réplica actual al empleado en segundo plano de la instancia de base de datos del escritor. Si el retardo supera los dos minutos en cualquier instancia de base de datos del lector, el empleado en segundo plano de la instancia de base de datos del escritor agrega un retraso al final de una transacción. Para controlar el umbral de retraso, utilice el parámetro flow_control.target_standby_apply_lag.
Cuando un control de flujo limita un proceso de PostgreSQL, el evento de espera Extension en pg_stat_activity e Información sobre rendimiento lo indican. La función get_flow_control_stats muestra detalles sobre cuánto retardo se está agregando actualmente.
El control de flujo puede beneficiar a la mayoría de las cargas de trabajo de procesamiento de transacciones en línea (OLTP) que tienen transacciones cortas, pero muy simultáneas. Si el retraso se debe a transacciones de larga duración, como operaciones por lotes, el control de flujo no proporciona tanto beneficio.
Para desactivar el control de flujo, elimine la extensión de shared_preload_libraries y reinicie la instancia de base de datos.
Instantáneas de clúster de base de datos multi-AZ
Amazon RDS crea y guarda copias de seguridad automatizadas del clúster de base de datos multi-AZ durante el periodo de copia de seguridad configurado. RDS crea una instantánea del volumen de almacenamiento del clúster de base de datos y realiza una copia de seguridad de todo el clúster y no solo de las instancias individuales.
También puede realizar copias de seguridad manuales del clúster de base de datos multi-AZ. Para copias de seguridad a largo plazo, plantéese exportar datos de instantáneas a Amazon S3. Para obtener más información, consulte Creación de una instantánea de clúster de base de datos multi-AZ.
Para restaurar un clúster de base de datos Multi-AZ a un momento específico, cree un nuevo clúster de base de datos Multi-AZ. Para obtener instrucciones, consulte Restauración de un clúster de base de datos Multi-AZ a un momento indicado.
De forma alternativa, puede restaurar una instantánea de clúster de base de datos multi-AZ a una implementación single-AZ o a una implementación de instancia de base de datos multi-AZ. Para obtener instrucciones, consulte Restauración desde una instantánea de clúster de base de datos Multi-AZ a una instancia de base de datos.
