Filtrado de datos para integraciones sin ETL de Amazon RDS
Las integraciones sin ETL de Amazon RDS admiten el filtrado de datos, lo que le permite controlar qué datos se replican desde la base de datos de Amazon RDS de origen al almacén de datos de destino. En lugar de replicar toda la base de datos, puede aplicar uno o más filtros para incluir o excluir selectivamente tablas específicas. Esto lo ayuda a optimizar el almacenamiento y el rendimiento de las consultas al garantizar que solo se transfieran los datos relevantes. Actualmente, el filtrado está limitado a los niveles de base de datos y tabla. No se admite el filtrado a nivel de columna y fila.
El filtrado de datos puede resultar útil cuando desee:
-
Una determinadas tablas de dos o más bases de datos de origen diferentes y no necesita datos completos de la base de datos.
-
Ahorrar costos realizando análisis utilizando únicamente un subconjunto de tablas en lugar de una flota completa de bases de datos.
-
Filtrar la información confidencial (como números de teléfono, direcciones o datos de tarjetas de crédito) de determinadas tablas.
Puede agregar filtros de datos a una integración sin ETL mediante la AWS Management Console, la AWS Command Line Interface (AWS CLI) o la API de Amazon RDS.
Si la integración tiene un clúster aprovisionado como destino, el clúster debe tener la revisión 180 o uno posterior para usar el filtrado de datos.
Temas
Formato de un filtro de datos
Puede definir varios filtros para una sola integración. Cada filtro incluye o excluye cualquier tabla de base de datos existente y futura que coincida con uno de los patrones de la expresión del filtro. Las integraciones sin ETL de Amazon RDS utilizan la sintaxis de filtro Maxwell
Cada filtro tiene los siguientes elementos:
| Element | Descripción |
|---|---|
| Tipo de filtro |
Un tipo de filtro |
| Expresión de filtro |
Una lista separada por comas de patrones. Las expresiones deben usar la sintaxis de filtro Maxwell |
| Pattern |
Un patrón de filtro en el formato notaPara RDS para MySQL, se admiten expresiones regulares tanto en el nombre de la base de datos como de la tabla. Para RDS para PostgreSQL, las expresiones regulares solo se admiten en el nombre del esquema y la tabla, no en el nombre de la base de datos. No pueden incluir filtros en columnas ni listas de denegación. Una sola integración puede tener un máximo de 99 patrones en total. En la consola, puede introducir patrones dentro de una sola expresión de filtro o distribuirlos entre varias expresiones. Un único patrón no puede superar los 256 caracteres de longitud. |
importante
Si selecciona una base de datos de origen de RDS para PostgreSQL, debe especificar al menos un patrón de filtro de datos. Como mínimo, el patrón debe incluir una única base de datos (database-name.*.*
En la imagen siguiente, se muestra la estructura de los filtros de datos de RDS para MySQL en la consola:
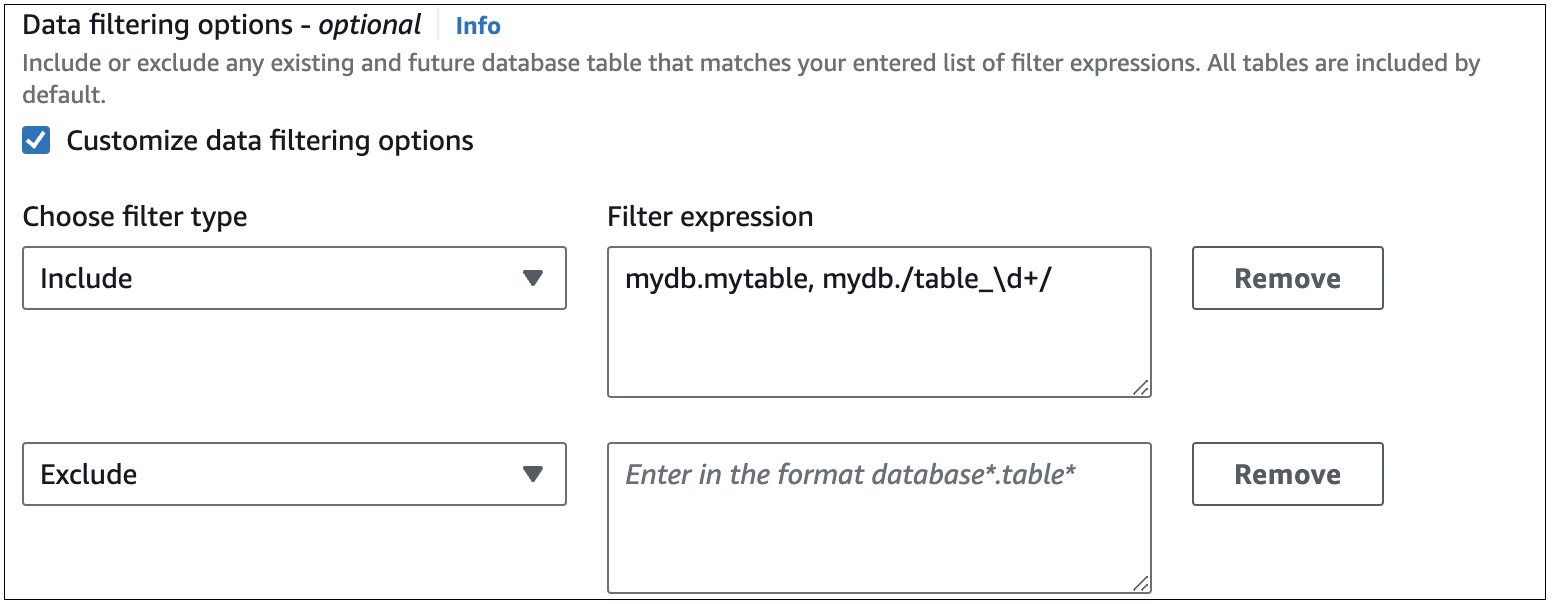
importante
No incluya información de identificación personal, confidencial o sensible en sus patrones de filtros.
Filtros de datos en la AWS CLI
Cuando se utiliza la AWS CLI para agregar un filtro de datos, la sintaxis es ligeramente diferente a la de la consola. Debe asignar un tipo de filtro (Include o Exclude) a cada patrón individualmente, por lo que no puede agrupar varios patrones en un mismo tipo de filtro.
Por ejemplo, en la consola puede agrupar los siguientes patrones separados por comas en una sola instrucción Include:
RDS para MySQL
mydb.mytable,mydb./table_\d+/
RDS para PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
Sin embargo, al utilizar la AWS CLI, el mismo filtro de datos debe tener el siguiente formato:
RDS para MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
RDS para PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
Lógica de filtros
Si no especifica ningún filtro de datos en la integración, Amazon RDS asume un filtro predeterminado de include:*.*, que replica todas las tablas en el almacén de datos de destino. No obstante, si agrega al menos un filtro, la lógica predeterminada cambia a exclude:*.*, que excluye todas las tablas de forma predeterminada. Esto le permite definir explícitamente qué bases de datos y tablas se incluirán en la replicación.
Por ejemplo, si hace lo siguiente:
'include: db.table1, include: db.table2'
Amazon RDS evalúa el filtro de la siguiente manera:
'exclude:*.*, include: db.table1, include: db.table2'
Por lo tanto, Amazon RDS solo replica table1 y table2 de la base de datos llamada db en el almacén de datos de destino.
Prioridad del filtro
Amazon RDS evalúa los filtros de datos en el orden que especifique. En la AWS Management Console, procesa las expresiones de filtro de izquierda a derecha y de arriba abajo. Un segundo filtro o un patrón individual que siga al primero puede anularlo.
Por ejemplo, si el primer filtro es Include books.stephenking, solo incluye la tabla stephenking de la base de datos books. Sin embargo, si agrega un segundo filtro, Exclude books.*, este anulará el primer filtro. Esto evita que las tablas del índice de books se repliquen en el almacén de datos de destino.
Cuando especifica al menos un filtro, la lógica comienza con la suposición de exclude:*.* de forma predeterminada, lo que excluye automáticamente todas las tablas de la replicación. Como práctica recomendada, defina los filtros de más amplio a más específico. Comience con una o más instrucciones Include para especificar los datos que desea replicar; a continuación, agregue filtros Exclude para eliminar selectivamente ciertas tablas.
El mismo principio se aplica a los filtros que se definen mediante la AWS CLI. Amazon RDS evalúa estos patrones de filtro en el orden en que los especifique, por lo que un patrón podría anular a otro especificado antes que él.
Ejemplos de RDS para MySQL
En los siguientes ejemplos, se muestra cómo funciona el filtrado de datos para las integraciones sin ETL de ejemplos de RDS para MySQL:
-
Incluir todas las bases de datos y todas las tablas:
'include: *.*' -
Incluir todas las tablas en la base de datos
books:'include: books.*' -
Excluya cualquier tabla con el nombre
mystery:'include: *.*, exclude: *.mystery' -
Incluir dos tablas específicas en la base de datos
books:'include: books.stephen_king, include: books.carolyn_keene' -
Incluya todas las tablas de la base de datos
books, excepto las que contengan la subcadenamystery:'include: books.*, exclude: books./.*mystery.*/' -
Incluya todas las tablas de la base de datos
books, excepto las que comiencen pormystery:'include: books.*, exclude: books./mystery.*/' -
Incluya todas las tablas de la base de datos
books, excepto las que finalicen pormystery:'include: books.*, exclude: books./.*mystery/' -
Incluya todas las tablas de la base de datos
booksque comiencen portable_, excepto la que se llamatable_stephen_king. Por ejemplo,table_moviesotable_booksse replicaría, pero notable_stephen_king.'include: books./table_.*/, exclude: books.table_stephen_king'
Ejemplos de RDS para PostgreSQL
En los siguientes ejemplos, se muestra cómo funciona el filtrado de datos para las integraciones sin ETL de RDS para PostgreSQL:
-
Incluir todas las tablas en la base de datos
books:'include: books.*.*' -
Excluya cualquier tabla nombrada
mysteryen la base de datosbooks:'include: books.*.*, exclude: books.*.mystery' -
Incluya una tabla dentro de la base de datos
booksen el esquemamysteryy una tabla dentro de la base de datosemployeeen el esquemafinance:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Incluya todas las tablas de la base de datos
booksy el esquemascience_fiction, excepto las que contengan la subcadenaking:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
Incluya todas las tablas de la base de datos
books, excepto las que tengan un nombre de esquema que comience porsci:'include: books.*.*, exclude: books./sci.*/.*' -
Incluya todas las tablas de la base de datos
books, excepto las que estén en el esquemamysteryy acaben enking:'include: books.*.*, exclude: books.mystery./.*king/' -
Incluya todas las tablas de la base de datos
booksque comiencen portable_, excepto la que se llamatable_stephen_king. Por ejemplo,table_moviesen el esquemafictionytable_booksen el esquemamysteryse replican, pero notable_stephen_kingen ninguno de los dos esquemas:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
Ejemplos de RDS para Oracle
En los siguientes ejemplos, se muestra cómo funciona el filtrado de datos para las integraciones sin ETL de RDS para Oracle:
-
Incluya todas las tablas en la base de datos books:
'include: books.*.*' -
Excluya las tablas denominadas mistery en la base de datos books:
'include: books.*.*, exclude: books.*.mystery' -
Incluya una tabla dentro de la base de datos books en el esquema mystery y una tabla dentro de la base de datos employee en el esquema finance:
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Incluya todas las tablas en el esquema de mistery dentro de la base de datos books:
'include: books.mystery.*'
Consideraciones sobre diferenciación entre mayúsculas y minúsculas
Oracle Database y Amazon Redshift gestionan las mayúsculas y minúsculas de los nombres de los objetos de forma diferente, lo que afecta a la configuración del filtro de datos y a las consultas de destino. Tenga en cuenta lo siguiente:
-
Oracle Database almacena los nombres de bases de datos, esquemas y objetos en mayúsculas, a menos que se indique explícitamente en la instrucción
CREATE. Por ejemplo, si creamytable(sin comillas), el diccionario de datos de Oracle almacena el nombre de la tabla comoMYTABLE. Si cita el nombre del objeto, el diccionario de datos conserva las mayúsculas y minúsculas. -
Los filtros de datos zero-ETL distinguen entre mayúsculas y minúsculas y deben coincidir exactamente con las mayúsculas y minúsculas de los nombres de los objetos tal como aparecen en el diccionario de datos de Oracle.
-
Las consultas de Amazon Redshift utilizan de forma predeterminada los nombres de objetos en minúscula, a menos que se cite explícitamente. Por ejemplo, una consulta de
MYTABLE(sin comillas) buscamytable.
Tenga en cuenta las diferencias entre mayúsculas y minúsculas cuando cree el filtro de Amazon Redshift y consulte los datos.
Creación de una integración en mayúsculas
Al crear una tabla sin especificar el nombre entre comillas dobles, Oracle Database almacena el nombre en mayúsculas en el diccionario de datos. Por ejemplo, puede crear MYTABLE con cualquiera de las siguientes instrucciones SQL.
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Como no ha citado el nombre de la tabla en las instrucciones anteriores, Oracle Database almacena el nombre del objeto en mayúsculas como MYTABLE.
Para replicar esta tabla en Amazon Redshift, debe especificar el nombre en mayúsculas en el filtro de datos del comando create-integration. El nombre del filtro zero-ETL y el nombre del diccionario de datos de Oracle deben coincidir.
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
De forma predeterminada, Amazon Redshift almacena los datos en minúsculas. Para consultar MYTABLE en la base de datos replicada en Amazon Redshift, debe citar el nombre en mayúsculas MYTABLE para que coincida con el del diccionario de datos de Oracle.
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
Las consultas siguientes no utilizan el mecanismo de entrecomillado. Todas devuelven un error porque buscan una tabla de Amazon Redshift llamada mytable, que usa el nombre en minúsculas predeterminado, pero la tabla se llama MYTABLE en el diccionario de datos de Oracle.
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
Las siguientes consultas utilizan el mecanismo de entrecomillado para especificar un nombre en mayúsculas y minúsculas combinadas. Todas las consultas devuelven un error porque buscan una tabla de Amazon Redshift que no se llama MYTABLE.
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
Creación de una integración en minúsculas
En el siguiente ejemplo alternativo, se utilizan comillas dobles para almacenar el nombre de la tabla en minúsculas en el diccionario de datos de Oracle. Se crea mytable de la siguiente manera.
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle Database almacena el nombre de la tabla como mytable en minúsculas. Para replicar esta tabla en Amazon Redshift, debe especificar el nombre en minúsculas mytable en el filtro de datos zero-ETL.
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
Al consultar esta tabla en la base de datos replicada en Amazon Redshift, puede especificar el nombre en minúsculas mytable. La consulta se realiza correctamente porque busca una tabla llamada mytable, que es el nombre de la tabla en el diccionario de datos de Oracle.
SELECT * FROM targetdb1."REINVENT".mytable;
Como Amazon Redshift utiliza de forma predeterminada los nombres de objetos en minúsculas, las siguientes consultas de mytable también se encuentran correctamente.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
Las consultas siguientes utilizan el mecanismo de entrecomillado para el nombre del objeto. Todas devuelven un error porque buscan una tabla de Amazon Redshift cuyo nombre es diferente de mytable.
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
Creación de una tabla con integración compuesta por mayúsculas y minúsculas
En el siguiente ejemplo, se utilizan comillas dobles para almacenar el nombre de la tabla en minúsculas en el diccionario de datos de Oracle. Se crea MyTable de la siguiente manera.
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle Database almacena el nombre de esta tabla como MyTable con mayúsculas y minúsculas combinadas. Para replicar esta tabla en Amazon Redshift, debe especificar el nombre en mayúsculas y minúsculas combinadas en el filtro de datos.
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
Al consultar esta tabla en la base de datos replicada en Amazon Redshift, debe especificar el nombre MyTable en mayúsculas y minúsculas combinadas entrecomillando el nombre del objeto.
SELECT * FROM targetdb1."REINVENT"."MyTable";
Como Amazon Redshift utiliza de forma predeterminada los nombres de objetos en minúsculas, las siguientes consultas no encuentran el objeto porque buscan el nombre mytable en minúscula.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
nota
No puede usar expresiones regulares en el valor de filtro de nombre de la base de datos, el esquema o el nombre de la tabla en las integraciones de RDS para Oracle.
Adición de filtros de datos a una integración
Puede configurar el filtrado de datos mediante la AWS Management Console, la AWS CLI o la API de Amazon RDS.
importante
Si agrega un filtro después de crear una integración, Amazon RDS lo trata como si hubiera existido siempre. Elimina todos los datos del almacén de datos de destino que no coincidan con los nuevos criterios de filtrado y vuelve a sincronizar todas las tablas afectadas.
Adición de filtros de datos a una integración sin ETL
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
En el panel de navegación, elija Integraciones sin ETL. Seleccione la integración a la que desea agregar filtros de datos y, a continuación, elija Modificar.
-
En Origen, agregue una o más instrucciones
IncludeyExclude.En la imagen siguiente, se muestra un ejemplo de filtros de datos para una integración de MySQL:
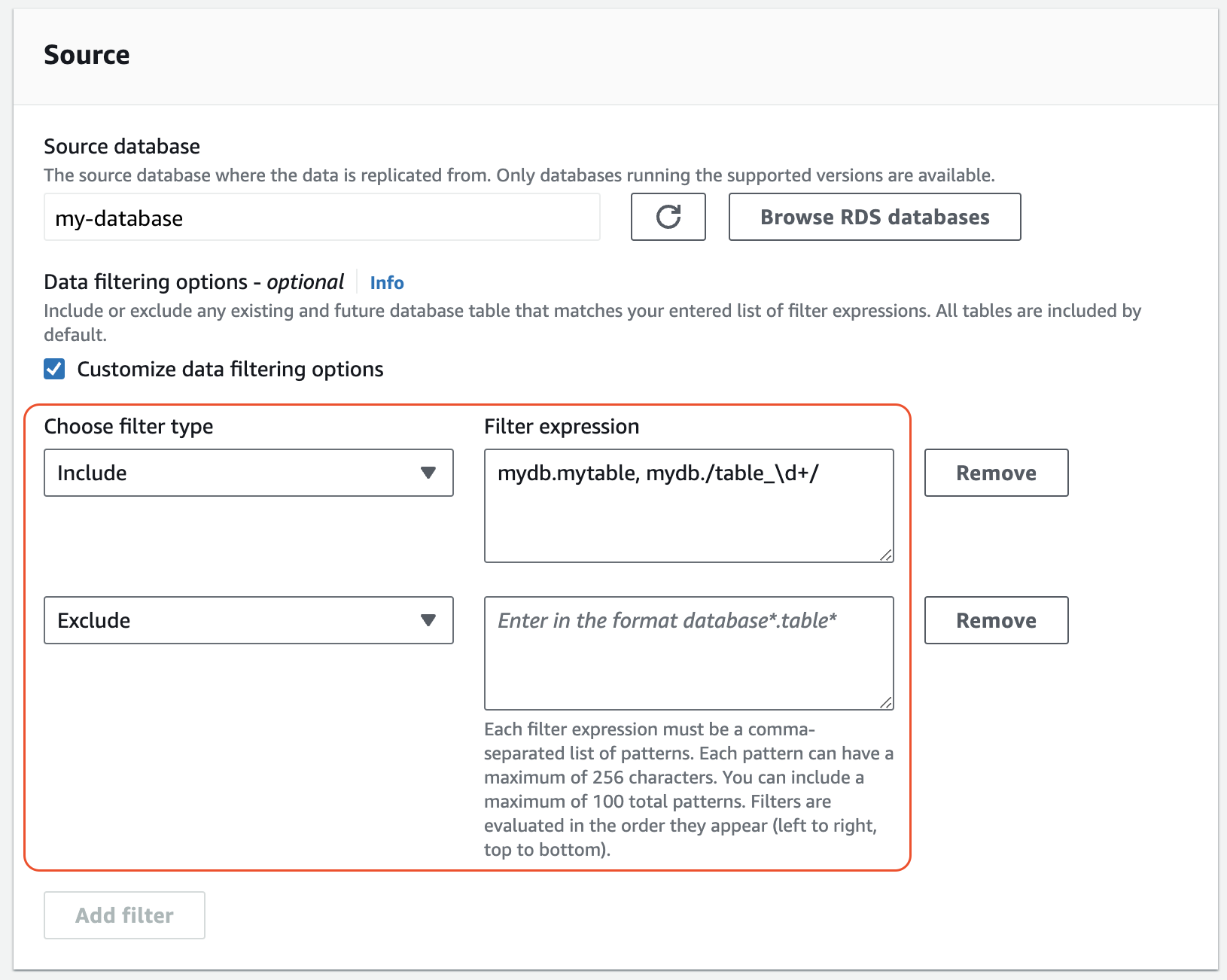
-
Cuando esté satisfecho con los cambios, elija Continuar y Guardar cambios.
Para agregar filtros de datos a una integración sin ETL mediante la AWS CLI, llame al comando modify-integration--data-filter con una lista separada por comas de filtros Include y Exclude Maxwell.
ejemplo
En el siguiente ejemplo, se agregan patrones de filtro a my-integration.
Para Linux, macOS o Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Para Windows:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Para modificar una integración sin ETL mediante la API de RDS, llame a la operación ModifyIntegration. Especifique el identificador de integración y proporcione una lista separada por comas de patrones de filtro.
Eliminación de filtros de datos de una integración
Al eliminar un filtro de datos de una integración, Amazon RDS vuelve a evaluar los filtros restantes como si el filtro eliminado nunca hubiera existido. A continuación, replica en el almacén de datos de destino cualquier dato excluido anteriormente que ahora cumpla los criterios. Esto desencadena una nueva sincronización de todas las tablas afectadas.
