Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Migración de datos desde un almacén de datos local a Amazon Redshift con AWS Schema Conversion Tool
Puede usar un AWS SCT agente para extraer datos de su almacén de datos local y migrarlos a Amazon Redshift. El agente extrae los datos y los carga en Amazon S3 o, en el caso de migraciones a gran escala, en un dispositivo AWS Snowball Edge Edge. A continuación, puede utilizar un AWS SCT agente para copiar los datos a Amazon Redshift.
Como alternativa, puede usar AWS Database Migration Service (AWS DMS) para migrar datos a Amazon Redshift. La ventaja de AWS DMS es que admite replicación continua (captura de datos de cambio). Sin embargo, para aumentar la velocidad de migración de datos, utilice varios AWS SCT agentes en paralelo. Según nuestras pruebas, los AWS SCT agentes migran los datos más rápido que entre un 15 y un 35 AWS DMS por ciento. La diferencia de velocidad se debe a la compresión de datos, al soporte de migración de particiones de tabla en paralelo y a los diferentes ajustes de configuración. Para obtener más información, consulte Uso de una base de datos de Amazon Redshift como destino de AWS Database Migration Service.
Amazon S3 es un servicio de almacenamiento y de recuperación. Para almacenar un objeto en Amazon S3, debe cargar en un bucket de Amazon S3 el archivo que quiera almacenar. Al cargar un archivo, puede configurar permisos en el objeto y también en cualquier metadato.
Migraciones a gran escala
Las migraciones de datos a gran escala pueden incluir muchos terabytes de información y pueden ralentizarse debido al rendimiento de la red y a la enorme cantidad de datos que hay que mover. AWS Snowball Edge Edge es un AWS servicio que puede utilizar para transferir datos a la nube a gran faster-than-network velocidad mediante un AWS dispositivo propio. Un dispositivo AWS Snowball Edge Edge puede almacenar hasta 100 TB de datos. Utiliza un cifrado de 256 bits y un módulo de plataforma segura (TPM) estándar del sector para garantizar la seguridad y la integridad de sus datos. chain-of-custody AWS SCT funciona con dispositivos Edge. AWS Snowball Edge
Cuando se utiliza AWS SCT un dispositivo AWS Snowball Edge Edge, se migran los datos en dos etapas. En primer lugar, se procesan AWS SCT los datos de forma local y, a continuación, se mueven esos datos al dispositivo AWS Snowball Edge Edge. A continuación, envía el dispositivo a AWS mediante el proceso AWS Snowball Edge Edge y, a continuación, carga AWS automáticamente los datos en un bucket de Amazon S3. A continuación, cuando los datos estén disponibles en Amazon S3, se AWS SCT suelen migrar a Amazon Redshift. Los agentes de extracción de datos pueden funcionar en segundo plano mientras AWS SCT está cerrado.
En el siguiente diagrama se muestran los escenarios admitidos.
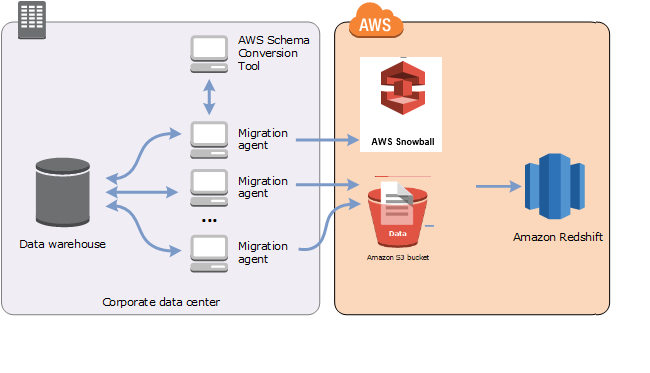
En la actualidad, los agentes de extracción de datos se admiten para los siguientes data warehouses de origen:
Azure Synapse Analytics
BigQuery
Greenplum Database (versión 4.3)
Microsoft SQL Server (versión 2008 y posteriores)
Netezza (versión 7.0.3 y posteriores)
Oracle (versión 10 y posteriores)
Snowflake (versión 3)
Teradata (versión 13 y posteriores)
Vertica (versión 7.2.2 y posteriores)
Puede conectarse a puntos de conexión de FIPS para Amazon Redshift si tiene que cumplir con los requisitos de seguridad del Estándar federal de procesamiento de la información (FIPS). Los puntos finales de FIPS están disponibles en las siguientes regiones: AWS
Región Este de EE. UU. (Norte de Virginia) (redshift-fips.us-east-1.amazonaws.com)
Región Este de EE. UU. (Ohio) (redshift-fips.us-east-2.amazonaws.com)
Región Oeste de EE. UU. (Norte de California) (redshift-fips.us-west-1.amazonaws.com)
Región Oeste de EE. UU. (Oregón) (redshift-fips.us-west-2.amazonaws.com)
Utilice la información en los temas siguientes para aprender a trabajar con los agentes de extracción de datos.
Temas
Requisitos previos para utilizar agentes de extracción de datos
Registrar los agentes de extracción con el AWS Schema Conversion Tool
Cambio de los ajustes de extracción y copia en la configuración del proyecto
Creación, ejecución y supervisión de una tarea AWS SCT de extracción de datos
Exportación e importación de una tarea de extracción de AWS SCT datos
Extracción de datos mediante un dispositivo AWS Snowball Edge Edge
Prácticas recomendadas y solución de problemas de agentes de extracción de datos
Requisitos previos para utilizar agentes de extracción de datos
Antes de trabajar con agentes de extracción de datos, añada los permisos necesarios para Amazon Redshift como destino al usuario de Amazon Redshift. Para obtener más información, consulte Permisos para Amazon Redshift como destino.
A continuación, almacene la información del bucket de Amazon S3 y configure el almacén de confianza y de claves de la capa de sockets seguros (SSL).
Configuración de Amazon S3
Después de que sus agentes extraigan los datos, los cargarán en el bucket de Amazon S3. Antes de continuar, debe proporcionar las credenciales para conectarse a su AWS cuenta y a su bucket de Amazon S3. Almacena sus credenciales y la información del bucket en un perfil en la configuración global de la aplicación y, a continuación, asocia el perfil a su AWS SCT proyecto. Si fuera necesario, seleccione Configuración global para crear un nuevo perfil. Para obtener más información, consulte Administración de perfiles en AWS Schema Conversion Tool.
Para migrar datos a la base de datos de Amazon Redshift de destino, el agente de extracción de AWS SCT datos necesita permiso para acceder al bucket de Amazon S3 en su nombre. Para conceder este permiso, cree un usuario AWS Identity and Access Management (IAM) con la siguiente política.
En el ejemplo anterior, reemplace bucket_name111122223333:user/DataExtractionAgentName
Asunción de roles de IAM
Para mayor seguridad, puede utilizar funciones AWS Identity and Access Management (IAM) para acceder a su bucket de Amazon S3. Para ello, cree un usuario de IAM para sus agentes de extracción de datos sin ningún permiso. A continuación, cree un rol de IAM que permita el acceso a Amazon S3 y especifique la lista de servicios y usuarios que pueden asumir este rol. Para obtener más información, consulte Roles de IAM en la Guía del usuario de IAM.
Para configurar roles de IAM para acceder al bucket de S3
-
Cree un usuario de IAM nuevo. En Credenciales de usuario, seleccione el tipo Acceso mediante programación.
-
Configure el entorno anfitrión para que su agente de extracción de datos pueda asumir la función que AWS SCT le proporciona. Asegúrese de que el usuario que configuró en el paso anterior permita que los agentes de extracción de datos utilicen la cadena de proveedores de credenciales. Para obtener más información, consulte Uso de credenciales en la Guía para desarrolladores de AWS SDK para Java .
-
Cree un nuevo rol de IAM que tenga acceso al bucket de Amazon S3.
-
Modifique la sección de confianza de este rol para confiar en el usuario que creó antes de asumir el rol. En el ejemplo siguiente, sustituya
111122223333:user/DataExtractionAgentName{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:user/DataExtractionAgentName" }, "Action": "sts:AssumeRole" } -
Modifique la sección de confianza de este rol para confiar en
redshift.amazonaws.com.rproxy.goskope.compara asumir el rol.{ "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com" ] }, "Action": "sts:AssumeRole" } -
Adjunte este rol al clúster de Amazon Redshift.
Ahora puede ejecutar el agente de extracción de datos en AWS SCT.
Cuando se utiliza la función de asumir un rol de IAM, la migración de datos funciona de la siguiente manera. El agente de extracción de datos se inicia y obtiene las credenciales de usuario mediante la cadena de proveedores de credenciales. A continuación, cree una tarea de migración de datos en AWS SCT, a continuación, especifique la función de IAM que deben asumir los agentes de extracción de datos e inicie la tarea. AWS Security Token Service (AWS STS) genera credenciales temporales para acceder a Amazon S3. El agente de extracción de datos utiliza estas credenciales para cargar datos en Amazon S3.
A continuación, AWS SCT proporciona a Amazon Redshift la función de IAM. A su vez, Amazon Redshift obtiene nuevas credenciales temporales AWS STS para acceder a Amazon S3. Amazon Redshift utiliza estas credenciales para copiar datos desde Amazon S3 a la tabla de Amazon Redshift.
Configuración de seguridad
Los agentes de extracción AWS Schema Conversion Tool y los agentes de extracción pueden comunicarse a través de Secure Sockets Layer (SSL). Para habilitar la SSL, configure un almacén de confianza y un almacén de claves.
Para configurar una comunicación segura con el agente de extracción
-
Inicie el AWS Schema Conversion Tool.
-
Abra el menú Configuración y seleccione Configuración global. Aparecerá el cuadro de diálogo Configuración global.
-
Elija Seguridad.
-
Seleccione Generar almacén de confianza y claves o haga clic en Seleccionar almacén de confianza y claves existente.
Si selecciona Generar almacén de confianza y de claves, a continuación tendrá que especificar el nombre y la contraseña de los almacenes de confianza y de claves y la ruta a la ubicación de los archivos generados. Utilizará estos archivos en pasos posteriores.
Si selecciona Seleccionar almacén de confianza y claves existente, después especificará la contraseña y el nombre del archivo para los almacenes de confianza y de claves. Utilizará estos archivos en pasos posteriores.
-
Tras haber especificado el almacén de confianza y el almacén de claves, seleccione Aceptar para cerrar el cuadro de diálogo Configuración global.
Configuración del entorno para los agentes de extracción de datos
Puede instalar varios agentes de extracción de datos en un único host. Sin embargo, recomendamos que ejecute un agente de extracción de datos en un host.
Para ejecutar el agente de extracción de datos, asegúrese de utilizar un host con al menos cuatro v CPUs y 32 GB de memoria. Además, establezca la memoria mínima disponible en AWS SCT al menos cuatro GB. Para obtener más información, consulte Configuración de memoria adicional.
La configuración óptima y la cantidad de hosts de agentes dependen de la situación específica de cada cliente. Asegúrese de tener en cuenta factores como la cantidad de datos que se van a migrar, el ancho de banda de la red, el tiempo de extracción de los datos, etc. En primer lugar, puede realizar una prueba de concepto (PoC) y, a continuación, configurar los agentes de extracción de datos y los hosts de acuerdo con los resultados de esta PoC.
Instalación de agentes de extracción
Le recomendamos que instale varios agentes de extracción en equipos individuales, independientes del equipo en el que se esté ejecutando la AWS Schema Conversion Tool.
En la actualidad, los agentes de extracción son compatibles con los siguientes sistemas operativos:
Microsoft Windows
Red Hat Enterprise Linux (RHEL) 6.0
Ubuntu Linux (versión 14.04 y posteriores)
Utilice el siguiente procedimiento para instalar agentes de extracción. Repita este procedimiento para cada equipo en el que desee instalar un agente de extracción.
Para instalar un agente de extracción
-
Si aún no ha descargado el archivo de AWS SCT instalación, siga las instrucciones que aparecen en Instalación y configuración AWS Schema Conversion Tool para descargarlo. El archivo.zip que contiene el archivo de AWS SCT instalación también contiene el archivo de instalación del agente de extracción.
-
Descargue e instale la versión más reciente de Amazon Corretto 11. Para obtener más información, consulte Descargas para Amazon Corretto 11 en la Guía del Usuario de Amazon Corretto 11.
-
Localice el archivo del instalador para su agente de extracción en una subcarpeta llamada agentes. El archivo correcto para el sistema operativo del equipo en el que quiera instalar el agente de extracción se muestra a continuación.
Sistema operativo Nombre de archivo Microsoft Windows
aws-schema-conversion-tool-extractor-2.0.1.build-number.msiRHEL
aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpmUbuntu Linux
aws-schema-conversion-tool-extractor-2.0.1.build-number.deb -
Instale el agente de extracción en un equipo independiente copiando el archivo del instalador en el nuevo equipo.
-
Ejecute el archivo del instalador. Utilice las instrucciones para su sistema operativo, que se muestran a continuación.
Sistema operativo Instrucciones de instalación Microsoft Windows
Haga doble clic en el archivo para ejecutar el instalador.
RHEL
Ejecute los siguientes comandos en la carpeta en la que haya descargado o movido el archivo.
sudo rpm -ivh aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpm sudo ./sct-extractor-setup.sh --configUbuntu Linux
Ejecute los siguientes comandos en la carpeta en la que haya descargado o movido el archivo.
sudo dpkg -i aws-schema-conversion-tool-extractor-2.0.1.build-number.deb sudo ./sct-extractor-setup.sh --config -
Seleccione Siguiente, acepte el acuerdo de licencia y elija Siguiente.
-
Introduzca la ruta para instalar el agente AWS SCT de extracción de datos y seleccione Siguiente.
-
Elija Instalar para instalar el agente de extracción de datos.
AWS SCT instala el agente de extracción de datos. Para completar la instalación, configure el agente de extracción de datos. AWS SCT inicia automáticamente el programa de configuración. Para obtener más información, consulte Configuración de agentes de extracción.
-
Seleccione Finalizar para cerrar el asistente de instalación después de configurar el agente de extracción de datos.
Configuración de agentes de extracción
Utilice el siguiente procedimiento para configurar agentes de extracción. Repita este procedimiento para cada equipo en que tenga instalado un agente de extracción.
Para configurar su agente de extracción
-
Inicie el programa de configuración:
-
En Windows, AWS SCT inicia el programa de configuración automáticamente durante la instalación de un agente de extracción de datos.
Si es necesario, puede iniciar el programa de configuración manualmente. Para ello, ejecute el archivo
ConfigAgent.baten Windows. Encontrará este archivo en la carpeta en la que instaló el agente. -
En RHEL y Ubuntu, ejecute el archivo
sct-extractor-setup.shdesde la ubicación en la que instaló el agente.
El programa de instalación le pedirá información. Para cada solicitud, aparecerá un valor predeterminado.
-
-
Acepte el valor predeterminado en cada solicitud o introduzca un valor nuevo.
Especifique la siguiente información:
En Puerto oyente, escriba el número de puerto en el que esté escuchando el agente.
En Agregar un proveedor de origen, introduzca sí y, a continuación, introduzca la plataforma de almacenamiento de datos de origen.
En Controlador JDBC, introduzca la ubicación en la que haya instalado los controladores JDBC.
En la carpeta de trabajo, introduzca la ruta en la que el agente de extracción de AWS SCT datos almacenará los datos extraídos. La carpeta de trabajo puede estar en un equipo distinto al del agente, y una única carpeta de trabajo se puede compartir entre varios agentes en diferentes equipos.
En Habilitar comunicación SSL, escriba sí.
En Almacén de claves, introduzca la ubicación del archivo del almacén de claves.
En Contraseña del almacén de claves, introduzca la contraseña del almacén de claves.
En Habilitar autenticación SSL del cliente, escriba sí.
En Almacén de confianza, introduzca la ubicación del archivo del almacén de confianza.
En Contraseña del almacén de confianza, introduzca la contraseña del almacén de confianza.
El programa de instalación actualiza el archivo de configuración para el agente de extracción. El archivo de configuración se denomina settings.properties y se encuentra en la ubicación en la que haya instalado el agente de extracción.
A continuación se muestra un archivo de configuración de ejemplo.
$ cat settings.properties
#extractor.start.fetch.size=20000
#extractor.out.file.size=10485760
#extractor.source.connection.pool.size=20
#extractor.source.connection.pool.min.evictable.idle.time.millis=30000
#extractor.extracting.thread.pool.size=10
vendor=TERADATA
driver.jars=/usr/share/lib/jdbc/terajdbc4.jar
port=8192
redshift.driver.jars=/usr/share/lib/jdbc/RedshiftJDBC42-1.2.43.1067.jar
working.folder=/data/sct
extractor.private.folder=/home/ubuntu
ssl.option=OFFPara cambiar los ajustes de configuración, puede editar el archivo settings.properties mediante un editor de texto o volver a ejecutar la configuración del agente.
Instalación y configuración de agentes de extracción con agentes de copia dedicados
Puede instalar los agentes de extracción en una configuración que tenga almacenamiento compartido y un agente de copia dedicado. En el siguiente diagrama se ilustra este escenario.
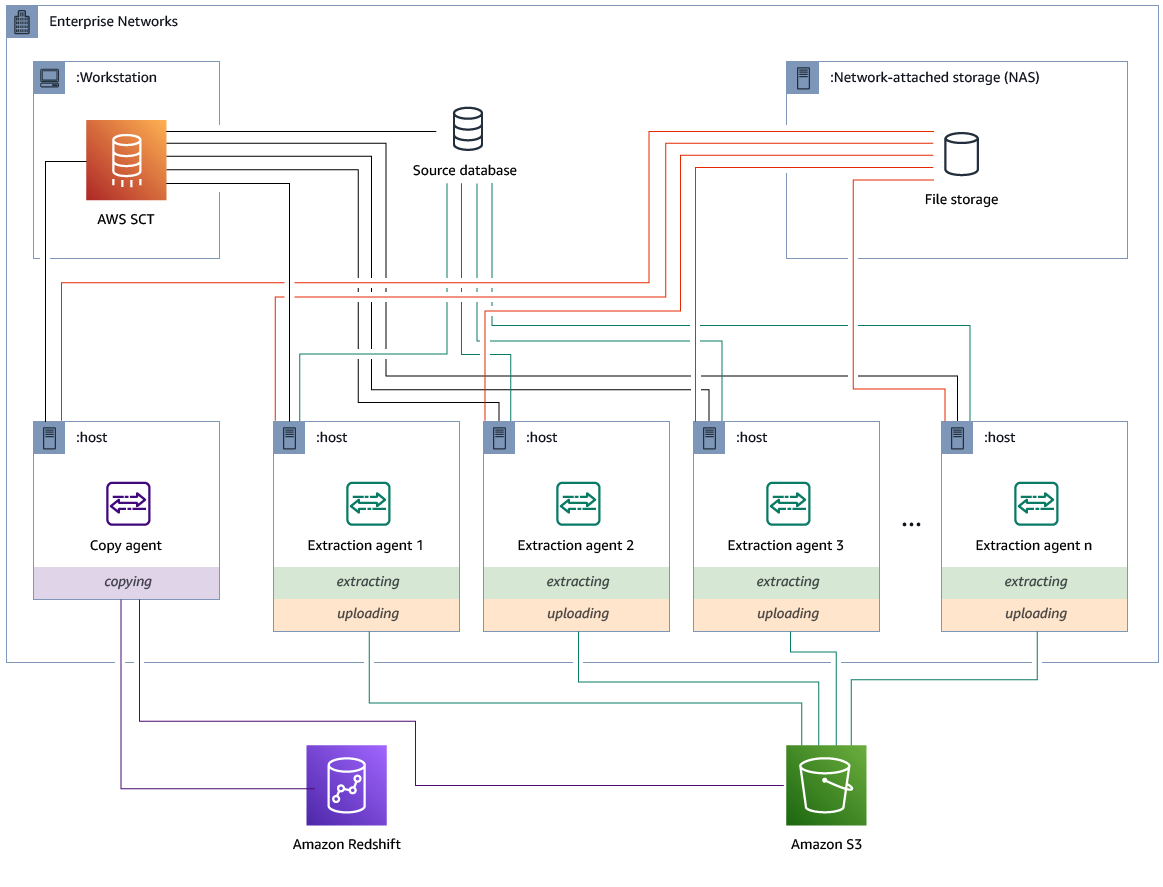
Esta configuración puede resultar útil cuando un servidor de base de datos de origen admite hasta 120 conexiones y la red tiene un amplio espacio de almacenamiento adjunto. Utilice el siguiente procedimiento para configurar los agentes de extracción que tengan un agente de copia dedicado.
Para instalar y configurar agentes de extracción y un agente de copia dedicado
-
Asegúrese de que el directorio de trabajo de todos los agentes de extracción utilice la misma carpeta en el almacenamiento compartido.
-
Instale los agentes de extracción siguiendo los pasos que se indican en Instalación de agentes de extracción.
-
Configure los agentes de extracción siguiendo los pasos que se indican en Configuración de agentes de extracción, pero especifique únicamente el controlador JDBC de origen.
-
Configure un agente de copia dedicado siguiendo los pasos que se indican en Configuración de agentes de extracción, pero especifique únicamente un controlador JDBC de Amazon Redshift.
Inicio de agentes de extracción
Utilice el siguiente procedimiento para iniciar agentes de extracción. Repita este procedimiento para cada equipo en que tenga instalado un agente de extracción.
Los agentes de extracción actúan en escucha. Cuando inicia un agente con este procedimiento, el agente comienza a escuchar para obtener instrucciones. Enviará a los agentes instrucciones para extraer los datos de su data warehouse en una sección posterior.
Para iniciar su agente de extracción
-
En el equipo en el que haya instalado el agente de extracción, ejecute el comando que aparezca a continuación para su sistema operativo.
Sistema operativo Comando de inicio Microsoft Windows
Haga doble clic en el archivo de lotes
StartAgent.bat.RHEL
Ejecute el siguiente comando en la ruta de la carpeta en la que haya instalado el agente:
sudo initctlstartsct-extractorUbuntu Linux
Ejecute el siguiente comando en la ruta de la carpeta en la que haya instalado el agente. Utilice el comando adecuado para su versión de Ubuntu.
Ubuntu 14.04:
sudo initctlstartsct-extractorUbuntu 15.04 y versiones posteriores:
sudo systemctlstartsct-extractor
Para comprobar el estado del agente, ejecute el mismo comando, pero sustituya start por status.
Para detener un agente, ejecute el mismo comando, pero sustituya start por stop.
Registrar los agentes de extracción con el AWS Schema Conversion Tool
Usted administra sus agentes de extracción mediante AWS SCT. Los agentes de extracción actúan como oyentes. Cuando reciben instrucciones AWS SCT, extraen datos de su almacén de datos.
Utilice el siguiente procedimiento para registrar los agentes de extracción en su AWS SCT proyecto.
Para registrar un agente de extracción
-
Inicie AWS Schema Conversion Tool y abra un proyecto.
-
Abra el menú Ver y seleccione Vista de migración de datos (otra). Aparecerá la pestaña Agentes. Si ya ha registrado agentes, AWS SCT los muestra en una cuadrícula en la parte superior de la pestaña.
-
Elija Registrar.
Después de registrar a un agente en un AWS SCT proyecto, no podrá registrar al mismo agente en un proyecto diferente. Si ya no utilizas un agente en un AWS SCT proyecto, puedes anular su registro. A continuación, puede registrarlo con otro proyecto diferente.
-
Seleccione Agente de datos de Redshift y, a continuación, elija Aceptar.
-
Introduzca su información en la pestaña Conexión del cuadro de diálogo:
-
En Descripción, escriba una descripción del agente.
-
En Nombre de host, escriba el nombre de host o la dirección IP del equipo del agente.
-
En Puerto, escriba el número de puerto en el que esté escuchando el agente.
-
Selecciona Registrar para registrar al agente en tu AWS SCT proyecto.
-
-
Repita los pasos anteriores para registrar múltiples agentes con su proyecto de AWS SCT .
Ocultar y recuperar la información de un AWS SCT agente
Un AWS SCT agente cifra una cantidad significativa de información, por ejemplo, las contraseñas de los almacenes de confianza clave de los usuarios, las cuentas de las bases de datos, la información de las cuentas y elementos similares. AWS Hace esto utilizando un archivo especial llamado seed.dat. De forma predeterminada, el agente crea este archivo en la carpeta de trabajo del usuario que configura el agente por primera vez.
Como diferentes usuarios pueden configurar y ejecutar el agente, la ruta de seed.dat se almacena en el parámetro {extractor.private.folder} del archivo settings.properties. Cuando se inicia el agente, puede utilizar esta ruta para encontrar el archivo seed.dat y obtener acceso a la información del almacén de claves y confianza de la base de datos correspondiente.
Es posible que necesite recuperar las contraseñas que un agente ha almacenado en estos casos:
Si el usuario pierde el
seed.datarchivo y la ubicación y el puerto del AWS SCT agente no han cambiado.Si el usuario pierde el
seed.datarchivo y la ubicación y el puerto del AWS SCT agente han cambiado. En este caso, el cambio suele ocurrir porque el agente se ha migrado a otro host o puerto y la información del archivoseed.datya no es válida.
En estos casos, si se inicia un agente sin SSL, este se inicia y después obtiene acceso al almacenamiento del agente creado con anterioridad. A continuación adopta el estado Esperando recuperación.
No obstante, en estos casos, si se inicia un agente con SSL, no puede reiniciarlo. Esto se debe a que el agente no puede descifrar las contraseñas para los certificados almacenados en el archivo settings.properties. En este tipo de inicio, el agente no se puede iniciar. Se escribe un error similar al siguiente en el registro: "El agente no se pudo iniciar con el modo SSL habilitado. Vuelva configurar el agente. Motivo: La contraseña de keystore es incorrecta".
Para solucionar este problema, cree un nuevo agente y configúrelo de forma que use las contraseñas existentes para obtener acceso a los certificados SSL. Para ello, siga el procedimiento que se indica a continuación.
Tras realizar este procedimiento, el agente debería ejecutarse y pasar al estado Esperando la recuperación. AWS SCT envía automáticamente las contraseñas necesarias a un agente en estado Esperando la recuperación. Cuando el agente tiene las contraseñas, reinicia todas las tareas. No se requiere ninguna acción adicional por parte de AWS SCT .
Para volver a configurar el agente y restaurar las contraseñas para obtener acceso a los certificados SSL
Instale un AWS SCT agente nuevo y ejecute la configuración.
Cambie la propiedad
agent.namedel archivoinstance.propertiesal nombre del agente para el que se creó el almacenamiento, para que el nuevo agente trabaje con el almacenamiento del agente existente.El archivo
instance.propertiesse almacena en la carpeta privada del agente, que recibe su nombre siguiendo esta convención:{.output.folder}\dmt\{hostName}_{portNumber}\Cambie el nombre de
{a la carpeta de salida del agente anterior.output.folder}En este punto, todavía AWS SCT está intentando acceder al antiguo extractor en el antiguo host y puerto. Por consiguiente, el extractor inaccesible obtiene el estado FAILED. A continuación, puede cambiar el host y el puerto.
Modifique el host, el puerto o ambas cosas del agente anterior mediante el comando Modify para redirigir el flujo de solicitudes al nuevo agente.
Cuando AWS SCT puede hacer ping al nuevo agente, AWS SCT recibe el estado Esperando la recuperación del agente. AWS SCT a continuación, recupera automáticamente las contraseñas del agente.
Cada agente que trabaja con el almacenamiento del agente actualiza un archivo especial llamado storage.lck ubicado en {. Este archivo contiene el ID de red del agente y el tiempo hasta que el almacenamiento está bloqueado. Cuando el agente trabaja con el almacenamiento del agente, actualiza el archivo output.folder}\{agentName}\storage\storage.lck y amplía el arrendamiento del almacenamiento en 10 minutos cada 5 minutos. Ninguna otra instancia puede trabajar con el almacenamiento de este agente hasta que finalice el arrendamiento.
Crear reglas de migración de datos en AWS SCT
Antes de extraer los datos con el AWS Schema Conversion Tool, puede configurar filtros que reduzcan la cantidad de datos que extrae. Puede crear reglas de migración de datos mediante el uso de cláusulas WHERE para reducir los datos que puede extraer. Por ejemplo, puede escribir una cláusula WHERE que seleccione los datos de una única tabla.
Puede crear reglas de migración de datos y guardar los filtros como parte del proyecto. Con el proyecto abierto, utilice el siguiente procedimiento para crear reglas de migración de datos.
Para crear reglas de migración de datos
-
Abra el menú Ver y seleccione Vista de migración de datos (otra).
-
Elija Reglas de migración de datos y, a continuación, elija Agregar nueva regla.
-
Configure su regla de migración de datos:
-
En Nombre, introduzca un nombre para la regla de migración de datos.
-
En Donde el nombre del esquema es como, escriba un filtro para aplicárselo a los esquemas. En este filtro, una cláusula
WHEREse evalúa mediante una cláusulaLIKE. Para elegir un esquema, introduzca un nombre de esquema exacto. Para elegir varios esquemas, utilice el carácter «%» como comodín para que coincida con cualquier número de caracteres del nombre del esquema. -
En Nombre de tabla como, escriba un filtro para aplicárselo a las tablas. En este filtro, una cláusula
WHEREse evalúa mediante una cláusulaLIKE. Para elegir una tabla, introduzca un nombre exacto. Para elegir varias tablas, utilice el carácter «%» como comodín para que coincida con cualquier número de caracteres del nombre de la tabla. -
En Cláusula Where, escriba una cláusula
WHEREpara filtrar los datos.
-
-
Una vez que haya configurado su filtro, seleccione Guardar para guardar el filtro o Cancelar para cancelar los cambios.
-
Cuando haya acabado de agregar, editar y eliminar filtros, seleccione Guardar todo para guardar todos los cambios.
Puede utilizar el icono de alternar para desactivar un filtro sin eliminarlo. También puede utilizar el icono de copia para duplicar un filtro existente. Para borrar un filtro existente, utilice el icono de eliminar. Para guardar los cambios que realice en sus filtros, seleccione Guardar todo.
Cambio de los ajustes de extracción y copia en la configuración del proyecto
Desde la ventana de configuración del proyecto AWS SCT, puede elegir la configuración para los agentes de extracción de datos y el comando Amazon RedshiftCOPY.
Para elegir estos ajustes, seleccione Configuración, Configuración del proyecto y, a continuación, Migración de datos. Aquí puede editar los Ajustes de extracción, la Configuración de S3 y los Ajustes de copia.
Siga las instrucciones de la tabla siguiente para proporcionar la información sobre los Ajustes de extracción.
| Para este parámetro | Haga lo siguiente |
|---|---|
Formato de compresión |
Especifique el formato de compresión de los archivos de entrada. Elija una de las siguientes opciones: GZIP BZIP2, ZSTD o Sin compresión. |
Carácter delimitador |
Especifique el carácter ASCII que separa los campos de los archivos de entrada. No se admiten caracteres no imprimibles. |
Valor NULL como cadena |
Active esta opción si los datos incluyen un terminador null. Si esta opción está desactivada, el comando |
Estrategia de ordenación |
Utilice la ordenación para reiniciar la extracción desde el punto en el que se produjo el error. Elija una de las siguientes estrategias de ordenación: Usar la ordenación después del primer fallo (recomendado), Usar la ordenación si es posible o No usar nunca la ordenación. Para obtener más información, consulte Ordenar los datos antes de migrarlos mediante AWS SCT. |
Esquema temporal de origen |
Introduzca el nombre del esquema en la base de datos de origen, donde el agente de extracción puede crear los objetos temporales. |
Tamaño del archivo de salida (en MB) |
Introduzca el tamaño, en MB, de los archivos cargados en Amazon S3. |
Tamaño del archivo de salida de Snowball (en MB) |
Introduzca el tamaño, en MB, de los archivos cargados en. AWS Snowball Edge Los archivos pueden tener un tamaño de 1 a 1000 MB. |
Usar particionamiento automático. Para Greenplum y Netezza, introducir el tamaño mínimo de las tablas admitidas (en megabytes) |
Active esta opción para utilizar particiones en las tablas y, a continuación, introduzca el tamaño de las tablas que desee particionar para las bases de datos fuente de Greenplum y Netezza. Para las migraciones de Oracle a Amazon Redshift, puedes mantener este campo vacío porque AWS SCT crea subtareas para todas las tablas particionadas. |
Extraer LOBs |
Active esta opción para extraer objetos grandes (LOBs) de la base de datos de origen. LOBs incluir BLOBs CLOBs, NCLOBs,, archivos XML, etc. Para cada LOB, los agentes de extracción de AWS SCT crean un archivo de datos. |
LOBs Carpeta de cubos Amazon S3 |
Introduzca la ubicación en la que desea almacenar los agentes de AWS SCT extracción LOBs. |
Aplicar RTRIM a columnas de cadenas |
Active esta opción para recortar un conjunto específico de caracteres del final de las cadenas extraídas. |
Conservar los archivos de forma local después de subirlos a Amazon S3 |
Active esta opción para conservar los archivos en su máquina local después de que los agentes de extracción de datos los carguen en Amazon S3. |
Siga las instrucciones de la siguiente tabla para proporcionar la información sobre la Configuración de Amazon S3.
| Para este parámetro | Haga lo siguiente |
|---|---|
Usar proxy |
Active esta opción para utilizar un servidor proxy para cargar datos en Amazon S3. Luego elija el protocolo de transferencia de datos e introduzca el nombre del host, el puerto, el nombre de usuario y la contraseña. |
Tipo de punto de conexión |
Elija FIPS para usar el punto de conexión del estándar federal de procesamiento de información (FIPS). Seleccione VPCE para usar el punto de conexión de la nube privada virtual (VPC). Seguidamente, en Punto de conexión de VPC, introduzca el sistema de nombres de dominio (DNS) del punto de conexión de VPC. |
Conservar los archivos en Amazon S3 después de copiarlos en Amazon Redshift |
Active esta opción para conservar los archivos extraídos en Amazon S3 después de copiarlos en Amazon Redshift. |
Siga las instrucciones de la siguiente tabla para proporcionar la información sobre los Ajustes de copia.
| Para este parámetro | Haga lo siguiente |
|---|---|
Recuento máximo de errores |
Introduzca el número de errores de carga. Una vez que la operación alcanza este límite, los agentes de extracción de AWS SCT datos finalizan el proceso de carga de datos. El valor predeterminado es 0, lo que significa que los agentes de extracción de AWS SCT datos continúan con la carga de datos independientemente de los errores. |
Sustituir caracteres UTF-8 no válidos |
Active esta opción para reemplazar los caracteres UTF-8 no válidos por el carácter especificado y continuar con la operación de carga de datos. |
Usar espacio en blanco como valor nulo |
Active esta opción para cargar como nulos los campos en blanco que constan de espacios en blanco. |
Usar vacío como valor nulo |
Active esta opción para cargar como nulos los campos |
Truncar columnas |
Active esta opción para truncar los datos de las columnas de forma que se ajusten a la especificación del tipo de datos. |
Compresión automática |
Active esta opción para aplicar la codificación de compresión durante una operación de copia. |
Actualización automática de estadísticas |
Active esta opción para actualizar las estadísticas al final de una operación de copia. |
Comprobar archivo antes de cargar |
Active esta opción para validar los archivos de datos antes de cargarlos en Amazon Redshift. |
Ordenar los datos antes de migrarlos mediante AWS SCT
Clasificar los datos antes de la migración AWS SCT ofrece algunas ventajas. Si primero ordena los datos, AWS SCT puede reiniciar el agente de extracción en el último punto guardado después de un error. Además, si va a migrar datos a Amazon Redshift y los ordena primero AWS SCT , podrá insertarlos en Amazon Redshift más rápido.
Estos beneficios tienen que ver con la forma en que AWS SCT crea las consultas de extracción de datos. En algunos casos, AWS SCT utiliza la función analítica DENSE_RANK en estas consultas. Sin embargo, DENSE_RANK puede utilizar mucho tiempo y recursos del servidor para ordenar el conjunto de datos que resulta de la extracción, de modo que si AWS SCT puede funcionar sin él, lo hará.
Para ordenar los datos antes de migrarlos utilizando AWS SCT
Abra un AWS SCT proyecto.
Abra el menú contextual (clic secundario) para el objeto y seleccione Crear tarea local.
Seleccione la pestaña Avanzado y elija una opción para Estrategia de ordenación:
No usar nunca la ordenación: el agente de extracción no utiliza la función analítica DENSE_RANK y se reinicia desde el principio si se produce un error.
Usar la ordenación si es posible: el agente de extracción utiliza DENSE_RANK si la tabla tiene una clave principal o una restricción única.
Usar la ordenación después del primer fallo (recomendado): el agente de extracción intenta primero obtener los datos sin usar DENSE_RANK. Si el primer intento falla, el agente de extracción reconstruye la consulta mediante DENSE_RANK y conserva su ubicación en caso de error.
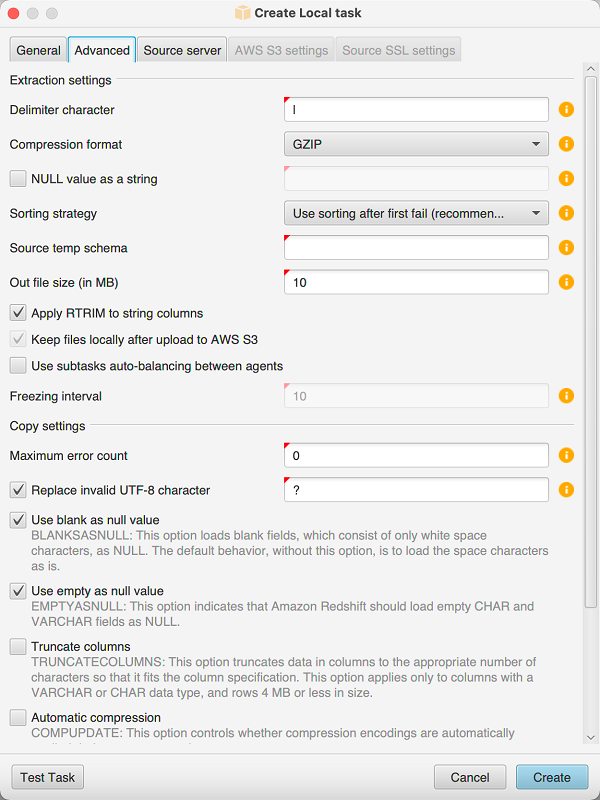
Establezca parámetros adicionales, como se describe a continuación, y seleccione Crear para crear la tarea de extracción de datos.
Creación, ejecución y supervisión de una tarea AWS SCT de extracción de datos
Utilice los siguientes procedimientos para crear, ejecutar y supervisar tareas de extracción de datos.
Para asignar tareas a agentes y migrar datos
-
En el panel izquierdo del proyecto AWS Schema Conversion Tool, después de convertir el esquema, elige una o más tablas del panel izquierdo del proyecto.
Puede seleccionar todas las tablas, pero no se lo recomendamos por motivos de desempeño. Le recomendamos que cree varias tareas para varias tablas basadas en el tamaño de las tablas en su almacenamiento de datos.
-
Abra el menú contextual (clic secundario) para cada tabla y seleccione Crear tarea. Se abre el cuadro de diálogo Crear tarea local.
-
En Nombre de tarea, escriba un nombre para la tarea.
-
En Modo de migración, seleccione una de las siguientes opciones:
-
Solo extraer: extrae los datos y los guarda en sus carpetas de trabajo locales.
-
Extraer y cargar: extrae los datos y los carga en Amazon S3.
-
Extraer, cargar y copiar: extrae los datos, los carga en Amazon S3 y los copia en el almacenamiento de datos de Amazon Redshift.
-
-
En Tipo de cifrado, seleccione una de las opciones siguientes:
-
NONE: desactive el cifrado de datos durante todo el proceso de migración de datos.
-
CSE_SK: utilice el cifrado del lado del cliente con una clave simétrica para migrar los datos. AWS SCT genera automáticamente las claves de cifrado y las transmite a los agentes de extracción de datos mediante Secure Sockets Layer (SSL). AWS SCT no cifra objetos grandes (LOBs) durante la migración de datos.
-
-
Elija Extraer LOBs para extraer objetos grandes. Si no es necesario extraer objetos grandes, puede quitar la marca de selección de la casilla. Esto reduce la cantidad de datos que extrae.
-
Si desea ver información detallada sobre una tarea, seleccione Habilitar registro de tareas. Puede utilizar el registro de tareas para depurar problemas.
Si habilita el registro de tareas, seleccione el nivel de detalle que desea ver. Los niveles son los siguientes y cada nivel incluye todos los mensajes del nivel anterior:
ERROR: La cantidad mínima de detalles.WARNINGINFODEBUGTRACE: La cantidad máxima de detalles.
-
Para exportar datos BigQuery, AWS SCT usa la carpeta bucket de Google Cloud Storage. En esta carpeta, los agentes de extracción de datos almacenan los datos de origen.
Para introducir la ruta en la carpeta del bucket de Google Cloud Storage, seleccione Avanzado. En Carpeta del bucket de Google CS, introduzca el nombre del bucket y el nombre de la carpeta.
-
Para asumir un rol como usuario del agente de extracción de datos, seleccione Configuración de Amazon S3. En Rol de IAM, introduzca el nombre del rol que desea usar. En Región, elige la Región de AWS para este rol.
-
Seleccione Probar tarea para comprobar que se puede conectar a su carpeta de trabajo, bucket de Amazon S3 y almacenamiento de datos de Amazon Redshift. La verificación depende del modo de migración que elija.
-
Seleccione Crear para crear la tarea.
-
Repita los pasos anteriores para crear tareas para todos los datos que quiera migrar.
Para ejecutar y supervisar tareas
-
En Vista, elija Vista de migración de datos. Aparecerá la pestaña Agentes.
-
Elija la pestaña Tareas. Sus tareas aparecen en la cuadrícula en la parte superior tal y como se muestra a continuación. Podrá ver el estado de una tarea en la cuadrícula superior y el estado de las tareas secundarias en la cuadrícula inferior.
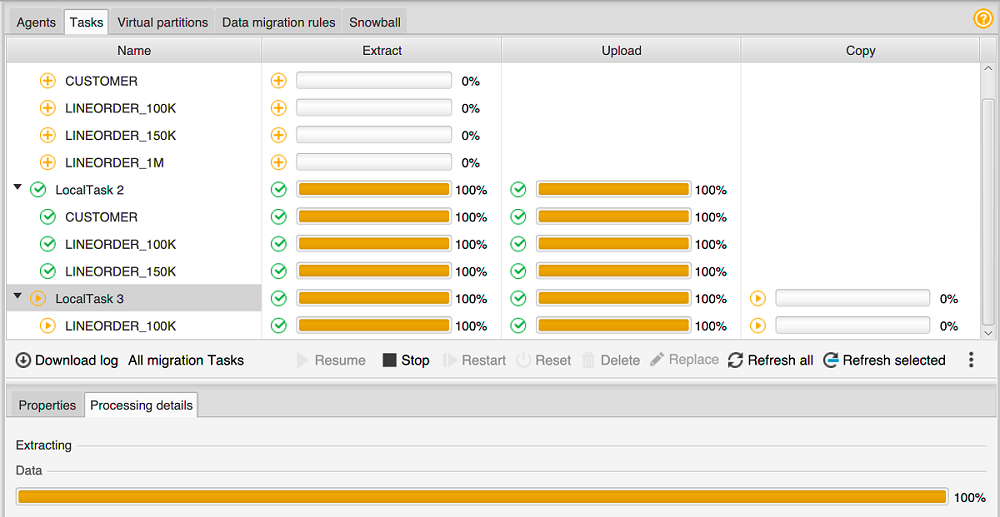
-
Seleccione una tarea en la cuadrícula superior y amplíela. En función del modo de migración que elija, verá la tarea dividida en Extraer, Cargar y Copiar.
-
Para comenzar una tarea, seleccione Iniciar para esa tarea. Puede supervisar el estado de sus tareas mientras están en ejecución. Las tareas secundarias se ejecutan en paralelo. Las funciones de extracción, carga y copia también se ejecutan en paralelo.
-
Si ha habilitado el registro al configurar la tarea, podrá ver el registro:
-
Seleccione Descargar registro. Aparecerá un mensaje con el nombre de la carpeta que contiene el archivo de registro. Omita el mensaje.
-
Aparecerá un enlace en la pestaña Detalles de tarea. Seleccione el enlace para abrir la carpeta que contiene el archivo de registro.
-
Puedes cerrar AWS SCT y tus agentes y tareas seguirán funcionando. Puedes volver a abrirlas AWS SCT más tarde para comprobar el estado de las tareas y ver los registros de las tareas.
Puede guardar las tareas de extracción de datos en el disco local y restaurarlas en el mismo proyecto o en otro proyecto mediante las funciones de exportación e importación. Para exportar una tarea, asegúrese de haber creado al menos una tarea de extracción en un proyecto. Puede importar una sola tarea de extracción o todas las tareas creadas en el proyecto.
Al exportar una tarea de extracción, AWS SCT crea un .xml archivo independiente para esa tarea. El archivo .xml almacena la información de los metadatos de la tarea, como las propiedades, la descripción y las tareas secundarias de la tarea. El archivo .xml no contiene información sobre el procesamiento de una tarea de extracción. Al importar la tarea, se vuelve a crear la siguiente información:
-
Progreso de la tarea
-
Estados de tareas secundarias y fases
-
Distribución de los agentes de extracción por tareas secundarias y fases
-
Tarea y subtarea IDs
-
Nombre de la tarea
Exportación e importación de una tarea de extracción de AWS SCT datos
Puede guardar rápidamente una tarea existente de un proyecto y restaurarla en otro proyecto (o en el mismo proyecto) mediante la AWS SCT exportación y la importación. Utilice el siguiente procedimiento para exportar e importar tareas de extracción de datos.
Para exportar e importar una tarea de extracción de datos
-
En Vista, elija Vista de migración de datos. Aparecerá la pestaña Agentes.
-
Elija la pestaña Tareas. Sus tareas se muestran en la cuadrícula que aparece.
-
Elija los tres puntos alineados verticalmente (icono de puntos suspensivos verticales) situados en la esquina inferior derecha, debajo de la lista de tareas.
-
Seleccione Exportar tarea en el menú emergente.
-
Elija la carpeta en la que desee AWS SCT colocar el
.xmlarchivo de exportación de la tarea.AWS SCT crea el archivo de exportación de la tarea con un formato de nombre de archivo de
TASK-DESCRIPTION_TASK-ID.xml -
Elija los tres puntos alineados verticalmente (icono de puntos suspensivos verticales) situados en la esquina inferior derecha, debajo de la lista de tareas.
-
Seleccione Importar tarea en el menú emergente.
Puede importar una tarea de extracción a un proyecto conectado a la base de datos de origen y el proyecto tiene al menos un agente de extracción registrado activo.
-
Seleccione el archivo
.xmlpara la tarea de extracción que ha exportado.AWS SCT obtiene los parámetros de la tarea de extracción del archivo, crea la tarea y añade la tarea a los agentes de extracción.
-
Repita estos pasos para exportar e importar tareas adicionales de extracción de datos.
Al final de este proceso, la exportación e importación finalizarán y las tareas de extracción de datos estarán listas para su uso.
Extracción de datos mediante un dispositivo AWS Snowball Edge Edge
El proceso de uso AWS SCT de AWS Snowball Edge Edge consta de varios pasos. La migración implica una tarea local, en la que se AWS SCT utiliza un agente de extracción de datos para mover los datos al dispositivo AWS Snowball Edge Edge y, a continuación, una acción intermedia en la que se AWS copian los datos del dispositivo AWS Snowball Edge Edge a un bucket de Amazon S3. El proceso termina AWS SCT de cargar los datos del bucket de Amazon S3 en Amazon Redshift.
Las secciones que siguen a esta descripción general proporcionan una step-by-step guía para cada una de estas tareas. El procedimiento supone que ha AWS SCT instalado, configurado y registrado un agente de extracción de datos en una máquina dedicada.
Realice los siguientes pasos para migrar los datos de un almacén de datos local a un almacén de AWS datos mediante AWS Snowball Edge Edge.
Cree un trabajo de AWS Snowball Edge Edge con la AWS Snowball Edge consola.
Desbloquee el dispositivo AWS Snowball Edge Edge con la máquina Linux local dedicada.
Cree un nuevo proyecto en AWS SCT.
Instalar y configurar los agentes de extracción de datos.
Crear y establecer permisos para que el bucket de Amazon S3 los utilice.
Importa un AWS Snowball Edge trabajo a tu AWS SCT proyecto.
Registrar el agente de extracción de datos en AWS SCT.
Cree una tarea local en AWS SCT.
Ejecutar y supervisar la tarea de migración de datos en AWS SCT.
Step-by-step procedimientos para migrar datos mediante AWS SCT Edge AWS Snowball Edge
En las secciones siguientes se incluye información detallada sobre los pasos para la migración.
Paso 1: Crear un trabajo de AWS Snowball Edge Edge
Cree un AWS Snowball Edge trabajo siguiendo los pasos descritos en la sección Creación de un trabajo de AWS Snowball Edge Edge de la Guía para desarrolladores de AWS Snowball Edge Edge.
Paso 2: desbloquea el dispositivo AWS Snowball Edge Edge
Ejecute los comandos que desbloquean y proporcionan credenciales al dispositivo Snowball Edge desde el equipo en el que instaló el AWS DMS agente. Al ejecutar estos comandos, puede estar seguro de que la llamada al AWS DMS agente se conecta al dispositivo AWS Snowball Edge Edge. Para obtener más información sobre cómo desbloquear el dispositivo AWS Snowball Edge Edge, consulte Desbloquear Snowball Edge.
aws s3 ls s3://<bucket-name> --profile <Snowball Edge profile> --endpoint http://<Snowball IP>:8080 --recursive
Paso 3: Crea un nuevo proyecto AWS SCT
A continuación, crea un AWS SCT proyecto nuevo.
Para crear un proyecto nuevo en AWS SCT
-
Inicie el AWS Schema Conversion Tool. En el menú Archivo, seleccione Proyecto nuevo. Aparece el cuadro de diálogo Proyecto nuevo.
-
Introduzca un nombre para su proyecto, que se almacenará localmente en su equipo.
-
Introduzca la ubicación del archivo local del proyecto.
-
Pulse Aceptar para crear su AWS SCT proyecto.
-
Seleccione Añadir fuente para añadir una nueva base de datos fuente a su AWS SCT proyecto.
-
Seleccione Añadir destino para añadir una nueva plataforma de destino a su AWS SCT proyecto.
-
Elija el esquema de la base de datos de origen en el panel izquierdo.
-
En el panel derecho, especifique la plataforma de la base de datos de destino para el esquema de origen seleccionado.
-
Seleccione Crear asignación. Este botón se activa después de elegir el esquema de la base de datos de origen y la plataforma de la base de datos de destino.
Paso 4: Instalar y configurar su agente de extracción de datos
AWS SCT utiliza un agente de extracción de datos para migrar los datos a Amazon Redshift. El archivo.zip que descargó para la instalación incluye el archivo AWS SCT instalador del agente de extracción. Puede instalar el agente de extracción de datos en Windows, Red Hat Enterprise Linux o Ubuntu. Para obtener más información, consulte Instalación de agentes de extracción.
Para configurar el agente de extracción de datos, introduzca los motores de base de datos de origen y destino. Además, asegúrese de haber descargado los controladores JDBC para las bases de datos de origen y destino en el equipo en el que ejecuta el agente de extracción de datos. Los agentes de extracción de datos utilizan estos controladores para conectarse a las bases de datos de origen y de destino. Para obtener más información, consulte Instalación de controladores JDBC para AWS Schema Conversion Tool.
En Windows, el instalador del agente de extracción de datos inicia el asistente de configuración en la ventana de símbolo del sistema. En Linux, ejecute el archivo sct-extractor-setup.sh desde la ubicación en la que instaló el agente.
Paso 5: Configurar el acceso AWS SCT al bucket de Amazon S3
Para obtener más información acerca la configuración de un bucket de Amazon S3, consulte Descripción general de los buckets en la Guía del usuario de Amazon Simple Storage Service.
Paso 6: Importa un AWS Snowball Edge trabajo a tu AWS SCT proyecto
Para conectar el AWS SCT proyecto con el dispositivo AWS Snowball Edge Edge, importe el AWS Snowball Edge trabajo.
Para importar tu AWS Snowball Edge trabajo
-
Abra el menú Configuración y seleccione Configuración global. Aparecerá el cuadro de diálogo Configuración global.
-
Seleccione Perfiles de servicios de AWS y, a continuación, seleccione Importar trabajo.
Elige tu AWS Snowball Edge trabajo.
-
Introduzca el IP de AWS Snowball Edge . Para obtener más información, consulte Cambio de la dirección IP en la Guía del usuario de AWS Snowball Edge .
-
Introduce tu AWS Snowball Edge puerto. Para obtener más información, consulte los puertos necesarios para usar AWS los servicios en un dispositivo AWS Snowball Edge Edge en la Guía para desarrolladores de AWS Snowball Edge Edge.
-
Especifique su clave de acceso de AWS Snowball Edge y su clave secreta de AWS Snowball Edge . Para obtener más información, consulte Autenticación y control de acceso en AWS Snowball Edge en la Guía del usuario de AWS Snowball Edge .
Elija Aplicar y, después, Aceptar.
Paso 7: Registre un agente de extracción de datos en AWS SCT
En esta sección, registrará el agente de extracción de datos en AWS SCT.
Para registrar un agente de extracción de datos
-
En el menú Ver, seleccione Vista de migración de datos (otra) y, seguidamente, seleccione Registrar.
-
En Descripción, introduzca un nombre para el agente de extracción de datos.
-
En Nombre de host, introduzca la dirección IP del equipo en el que ejecuta el agente de extracción de datos.
-
En Puerto, introduzca el puerto oyente que configuró previamente.
-
Elija Registro.
Paso 8: Crear una tarea local
A continuación, cree la tarea de migración. La tarea incluye dos tareas secundarias. Una subtarea migra los datos de la base de datos de origen al dispositivo AWS Snowball Edge Edge. La otra tarea secundaria toma los datos que el dispositivo cara a un bucket de Amazon S3 y los migra a la base de datos de destino.
Para crear una tarea de migración
-
En el menú Ver, seleccione Vista de migración de datos (otra).
En el panel de la izquierda que muestra el esquema de la base de datos de origen, seleccione un objeto del esquema para su migración. Abra el menú contextual (clic secundario) para el objeto y seleccione Crear tarea local.
-
En Nombre de la tarea, introduzca un nombre para la tarea de migración de datos.
-
En Modo de migración, seleccione Extraer, cargar y copiar.
-
Seleccione Configuración de Amazon S3.
-
Seleccione Usar Snowball Edge.
-
Introduzca las carpetas y subcarpetas en el bucket de Amazon S3 donde el agente de extracción de datos pueda almacenar los datos.
-
Seleccione Crear para crear la tarea.
Paso 9: Ejecutar y monitorear la tarea de migración de datos en AWS SCT
Para iniciar la tarea de migración de datos, elija Iniciar. Asegúrese de haber establecido conexiones con la base de datos de origen, el bucket de Amazon S3, el AWS Snowball Edge dispositivo y la conexión con la base de datos de destino en ella AWS.
Puede supervisar y administrar las tareas de migración de datos y sus tareas secundarias en la pestaña Tareas. Puede ver el progreso de la migración de datos, así como pausar o reiniciar las tareas de migración de datos.
Resultado de la tarea de extracción de datos
Tras completarse sus tareas de migración, sus datos estarán listos. Utilice la siguiente información para determinar cómo proceder en función del modo de migración que haya elegido y la ubicación de los datos.
| Modo de migración | Ubicación de los datos |
|---|---|
|
Extraer, cargar y copiar |
Los datos ya están en el almacenamiento de datos de Amazon Redshift. Puede verificar que los datos están ahí y empezar a utilizarlos. Para obtener más información, consulte la sección Conectar a clústeres desde herramientas cliente y código. |
|
Extraer y cargar |
Los agentes de extracción guardaron sus datos como archivos en el bucket de Amazon S3. Puede usar el comando COPY de Amazon Redshift para cargar los datos en Amazon Redshift. Para obtener más información, consulte Cargar datos desde Amazon S3 en la documentación de Amazon Redshift. En el bucket de Amazon S3 hay varias carpetas, que se corresponden con las tareas de extracción que configuró. Al cargar sus datos en Amazon Redshift, especifique el nombre del archivo de manifiesto creado por cada tarea. El archivo de manifiesto aparece en la carpeta de tareas del bucket de Amazon S3, tal y como se muestra a continuación. 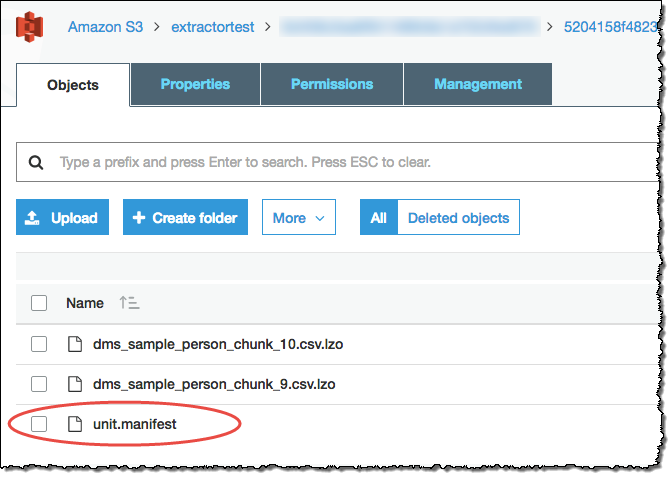
|
|
Solo extraer |
Los agentes de extracción guardaron sus datos en su carpeta de trabajo. Copie a mano sus datos en el bucket de Amazon S3; y, a continuación, proceda con las instrucciones para Extraer y cargar. |
Uso de particiones virtuales con AWS Schema Conversion Tool
A menudo, podrá administrar mejor grandes tablas sin particiones mediante la creación de tareas secundarias que crean particiones virtuales de los datos de la tabla utilizando reglas de filtrado. En AWS SCT, puede crear particiones virtuales para los datos migrados. Existen tres tipos de partición, que funcionan con determinados tipos de datos:
El tipo de partición RANGE funciona con tipos de datos de fecha y hora y numéricos.
El tipo de partición LIST funciona con tipos de datos de fecha y hora, numéricos y caracteres.
El tipo de partición DATE AUTO SPLIT funciona con tipos de datos numéricos, de fecha y de hora.
AWS SCT valida los valores que proporciona para crear una partición. Por ejemplo, si intenta particionar una columna con el tipo de datos NUMERIC pero proporciona valores de un tipo de datos diferente, AWS SCT arroja un error.
Además, si va AWS SCT a migrar datos a Amazon Redshift, puede utilizar la partición nativa para gestionar la migración de tablas grandes. Para obtener más información, consulte Uso de particiones nativas.
Límites del particionamiento virtual
Estas son las limitaciones al crear una partición virtual:
Solo puede utilizar particionamiento virtual para tablas no particionadas.
Solo puede utilizar particionamiento virtual en la vista de migración de datos.
No puede utilizar la opción UNION ALL VIEW con particionamiento virtual.
Tipo de partición RANGE
El tipo de partición RANGE realiza particiones de datos basadas en un intervalo de valores de la columna para tipos de datos de fecha y hora y numéricos. Este tipo de partición crea una cláusula WHERE y usted proporciona el intervalo de valores de cada partición. Para especificar una lista de valores para la columna particionada, utilice el cuadro Valores. Puede cargar información del valor mediante un archivo .csv.
El tipo de partición RANGE crea particiones predeterminadas en ambos extremos de los valores de las particiones. Estas particiones predeterminadas capturan cualquier dato inferior o superior a los valores de partición especificados.
Por ejemplo, puede crear varias particiones basadas en un intervalo de valores que proporcione. En el siguiente ejemplo, se especifican los valores de particionamiento para LO_TAX para crear varias particiones.
Partition1: WHERE LO_TAX <= 10000.9 Partition2: WHERE LO_TAX > 10000.9 AND LO_TAX <= 15005.5 Partition3: WHERE LO_TAX > 15005.5 AND LO_TAX <= 25005.95
Para crear una partición virtual RANGE
Abrir. AWS SCT
Elija el modo Vista de migración de datos (otra).
Elija la tabla en la que desea configurar el particionamiento virtual. Abra el menú contextual (clic secundario) de la tabla y seleccione Agregar particionamiento virtual.
En el cuadro de diálogo Agregar particionamiento virtual, introduzca la información, como sigue.
Opción Action Tipo de partición
Seleccione RANGE. La interfaz de usuario del cuadro de diálogo cambia en función del tipo que elija.
Nombre de la columna
Seleccione la columna en la que desea realizar la partición.
Tipo de columna
Elija el tipo de datos para los valores en la columna.
Valores
Para agregar nuevos valores, escriba cada valor en el cuadro Valor nuevo y, a continuación, elija el signo más para agregar el valor.
Cargar desde archivo
(Opcional) Escriba el nombre de un archivo .csv que contenga valores de partición.
-
Seleccione Aceptar.
Tipo de partición LIST
El tipo de partición LIST realiza particiones de datos basadas en los valores de la columna para tipos de datos de fecha y hora, numéricos y caracteres. Este tipo de partición crea una cláusula WHERE y usted proporciona los valores de cada partición. Para especificar una lista de valores para la columna particionada, utilice el cuadro Valores. Puede cargar información del valor mediante un archivo .csv.
Por ejemplo, puede crear varias particiones basadas en un valor que proporcione. En el siguiente ejemplo, se especifican los valores de particionamiento para LO_ORDERKEY para crear varias particiones.
Partition1: WHERE LO_ORDERKEY = 1 Partition2: WHERE LO_ORDERKEY = 2 Partition3: WHERE LO_ORDERKEY = 3 … PartitionN: WHERE LO_ORDERKEY = USER_VALUE_N
También puede crear una partición predeterminada para valores no incluidos en los especificados.
Puede usar el tipo de partición LIST para filtrar los datos de origen si desea excluir determinados valores de la migración. Por ejemplo, suponga que desea omitir filas con LO_ORDERKEY = 4. En este caso, no incluya el valor 4 en la lista de valores de partición y asegúrese de que no se elija la opción Incluir otros valores.
Para crear una partición virtual LIST
Abrir AWS SCT.
Elija el modo Vista de migración de datos (otra).
Elija la tabla en la que desea configurar el particionamiento virtual. Abra el menú contextual (clic secundario) de la tabla y seleccione Agregar particionamiento virtual.
En el cuadro de diálogo Agregar particionamiento virtual, introduzca la información, como sigue.
Opción Action Tipo de partición
Elija LIST. La interfaz de usuario del cuadro de diálogo cambia en función del tipo que elija.
Nombre de la columna
Seleccione la columna en la que desea realizar la partición.
Valor nuevo
Aquí puede escribir un valor que se agregará al conjunto de valores de particionamiento.
Incluir otros valores
Seleccione esta opción para crear una partición predeterminada en la que se almacenan todos los valores que no cumplen los criterios de particionamiento.
Cargar desde archivo
(Opcional) Escriba el nombre de un archivo .csv que contenga valores de partición.
Seleccione Aceptar.
Tipo de partición DATE AUTO SPLIT
El tipo de partición DATE AUTO SPLIT es una forma automática de generar particiones RANGE. Con DATA AUTO SPLIT, usted AWS SCT indica el atributo de partición, dónde empezar y dónde terminar, y el tamaño del rango entre los valores. A continuación, AWS SCT calcula los valores de la partición automáticamente.
DATA AUTO SPLIT automatiza gran parte del trabajo que implica la creación de particiones de rango. El equilibrio entre el uso de esta técnica y el particionamiento de rango es el grado de control que se necesita sobre los límites de las particiones. El proceso de división automática siempre crea rangos de igual tamaño (uniformes). El particionamiento de rango le permite variar el tamaño de cada rango según sea necesario para su distribución de datos particular. Por ejemplo, puede usar diariamente, semanalmente, quincenalmente, mensualmente, entre otros.
Partition1: WHERE LO_ORDERDATE >= ‘1954-10-10’ AND LO_ORDERDATE < ‘1954-10-24’ Partition2: WHERE LO_ORDERDATE >= ‘1954-10-24’ AND LO_ORDERDATE < ‘1954-11-06’ Partition3: WHERE LO_ORDERDATE >= ‘1954-11-06’ AND LO_ORDERDATE < ‘1954-11-20’ … PartitionN: WHERE LO_ORDERDATE >= USER_VALUE_N AND LO_ORDERDATE <= ‘2017-08-13’
Para crear una partición virtual DATE AUTO SPLIT
Abrir AWS SCT.
Elija el modo Vista de migración de datos (otra).
Elija la tabla en la que desea configurar el particionamiento virtual. Abra el menú contextual (clic secundario) de la tabla y seleccione Agregar particionamiento virtual.
En el cuadro de diálogo Agregar particionamiento virtual, introduzca la siguiente información.
Opción Action Tipo de partición
Seleccione DATE AUTO SPLIT. La interfaz de usuario del cuadro de diálogo cambia en función del tipo que elija.
Nombre de la columna
Seleccione la columna en la que desea realizar la partición.
Fecha de inicio
Escriba una fecha de inicio.
Fecha de finalización
Escriba una fecha de finalización.
Intervalo
Escriba la unidad del intervalo y elija el valor de dicha unidad.
Seleccione Aceptar.
Uso de particiones nativas
Para acelerar la migración de datos, sus agentes de extracción de datos pueden usar particiones nativas de tablas en el servidor de almacenamiento de datos de origen. AWS SCT admite el particionamiento nativo para las migraciones de Greenplum, Netezza y Oracle a Amazon Redshift.
Por ejemplo, después de crear un proyecto, puede recopilar estadísticas en un esquema y analizar el tamaño de las tablas seleccionadas para la migración. En el caso de las tablas que superen el tamaño especificado, se activa el mecanismo de particionamiento nativo AWS SCT .
Para usar particionamiento nativo
-
Abra AWS SCT y elija Nuevo proyecto para Archivo. Aparece el cuadro de diálogo Proyecto nuevo.
-
Cree un proyecto nuevo, añada los servidores de origen y destino, y cree reglas de asignación. Para obtener más información, consulte Iniciar y gestionar proyectos en AWS SCT.
-
Haga clic en Ver y, a continuación, seleccione Vista principal.
-
En Configuración del proyecto, elija la pestaña Migración de datos. Seleccione Usar particiones automáticas. Para las bases de datos de origen de Greenplum y Netezza, introduzca el tamaño mínimo de las tablas admitidas en megabytes (por ejemplo, 100). AWS SCT crea automáticamente tareas secundarias de migración independientes para cada partición nativa que no esté vacía. Para las migraciones de Oracle a Amazon Redshift, AWS SCT crea subtareas para todas las tablas particionadas.
-
En el panel de la izquierda que muestra el esquema de la base de datos de origen, seleccione un esquema. Abra el menú contextual (clic secundario) para el objeto y seleccione Recopilar estadísticas. Para migrar datos desde Oracle a Amazon Redshift, puede omitir este paso.
-
Elija todas las tablas que desee migrar.
-
Registre el número necesario de agentes. Para obtener más información, consulte Registrar los agentes de extracción con el AWS Schema Conversion Tool.
-
Cree una tarea de extracción de datos para las tablas seleccionadas. Para obtener más información, consulte Creación, ejecución y supervisión de una tarea AWS SCT de extracción de datos.
Compruebe si las tablas grandes se dividen en tareas secundarias y si cada tarea secundaria coincide con el conjunto de datos que presenta una parte de la tabla ubicada en un sector del almacenamiento de datos de origen.
-
Inicie y supervise el proceso de migración hasta que AWS SCT los agentes de extracción de datos completen la migración de los datos de sus tablas de origen.
Migración LOBs a Amazon Redshift
Amazon Redshift no admite el almacenamiento de objetos binarios de gran tamaño ()LOBs. Sin embargo, si necesita migrar uno o más LOBs a Amazon Redshift, AWS SCT puede realizar la migración. Para ello, AWS SCT utiliza un bucket de Amazon S3 para almacenar LOBs y escribe la URL del bucket de Amazon S3 en los datos migrados almacenados en Amazon Redshift.
Para migrar LOBs a Amazon Redshift
Abra un AWS SCT proyecto.
Conéctese a bases de datos de origen y destino. Actualice los metadatos de la base de datos de destino y asegúrese de que las tablas convertidas estén allí.
En Acciones, seleccione Crear tarea local.
-
En Modo de migración, seleccione una de las siguientes opciones:
-
Extraer y cargar para extraer sus datos y los cargarlos en Amazon S3.
-
Extraer, cargar y copiar para extraer sus datos, cargarlos en Amazon S3 y copiarlos en el almacenamiento de datos de Amazon Redshift.
-
Seleccione Configuración de Amazon S3.
En el caso de la LOBs carpeta de bucket de Amazon S3, introduzca el nombre de la carpeta de un bucket de Amazon S3 en la que desee LOBs guardarla.
Si utiliza el perfil de AWS servicio, este campo es opcional. AWS SCT puede usar la configuración predeterminada de su perfil. Para usar otro bucket de Amazon S3, introduzca la ruta aquí.
-
Active la opción Usar proxy para utilizar un servidor proxy para cargar datos en Amazon S3. Luego elija el protocolo de transferencia de datos e introduzca el nombre del host, el puerto, el nombre de usuario y la contraseña.
-
En Tipo de punto de conexión, seleccione FIPS para usar el punto de conexión del estándar federal de procesamiento de información (FIPS). Seleccione VPCE para usar el punto de conexión de la nube privada virtual (VPC). Seguidamente, en Punto de conexión de VPC, introduzca el sistema de nombres de dominio (DNS) del punto de conexión de VPC.
-
Active la opción Conservar archivos en Amazon S3 después de copiarlos en Amazon Redshift para conservar los archivos extraídos en Amazon S3 después de copiarlos en Amazon Redshift.
Seleccione Crear para crear la tarea.
Prácticas recomendadas y solución de problemas de agentes de extracción de datos
A continuación se indican algunas prácticas recomendadas y sugerencias de resolución de problemas para el uso de los agentes de extracción.
| Problema | Sugerencias para la solución de problemas |
|---|---|
|
El desempeño es lento |
Para mejorar el desempeño, le recomendamos lo siguiente:
|
|
Evite los retrasos |
Evite tener demasiados agentes que obtengan acceso a su almacenamiento de datos al mismo tiempo. |
|
Un agente deja de funcionar de forma temporal |
Si un agente deja de funcionar, el estado de cada una de sus tareas aparecerá como erróneo en la AWS SCT. En algunos casos, el agente puede recuperarse con solo esperar. En este caso, el estado de sus tareas se actualiza en la AWS SCT. |
|
Un agente deja de funcionar de forma permanente |
Si el equipo que ejecuta un agente deja de funcionar de forma permanente, y ese agente está ejecutando una tarea, puede sustituirlo por un nuevo agente que continúe con la tarea. Solo puede sustituir un nuevo agente si la carpeta de trabajo del agente original no se encuentra en el mismo equipo que el agente original. Para sustituir un nuevo agente, haga lo siguiente:
|
