Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Migración de cargas de trabajo de Hadoop a Amazon EMR con AWS Schema Conversion Tool
Para migrar los clústeres de Apache Hadoop, asegúrese de utilizar la versión 1.0.670 o superior. AWS SCT Además, familiarícese con la interfaz de la línea de comandos (CLI) de AWS SCT. Para obtener más información, consulte Referencia CLI para AWS Schema Conversion Tool.
Información general sobre la migración
La siguiente imagen muestra el diagrama de la arquitectura de la migración de Apache Hadoop a Amazon EMR.
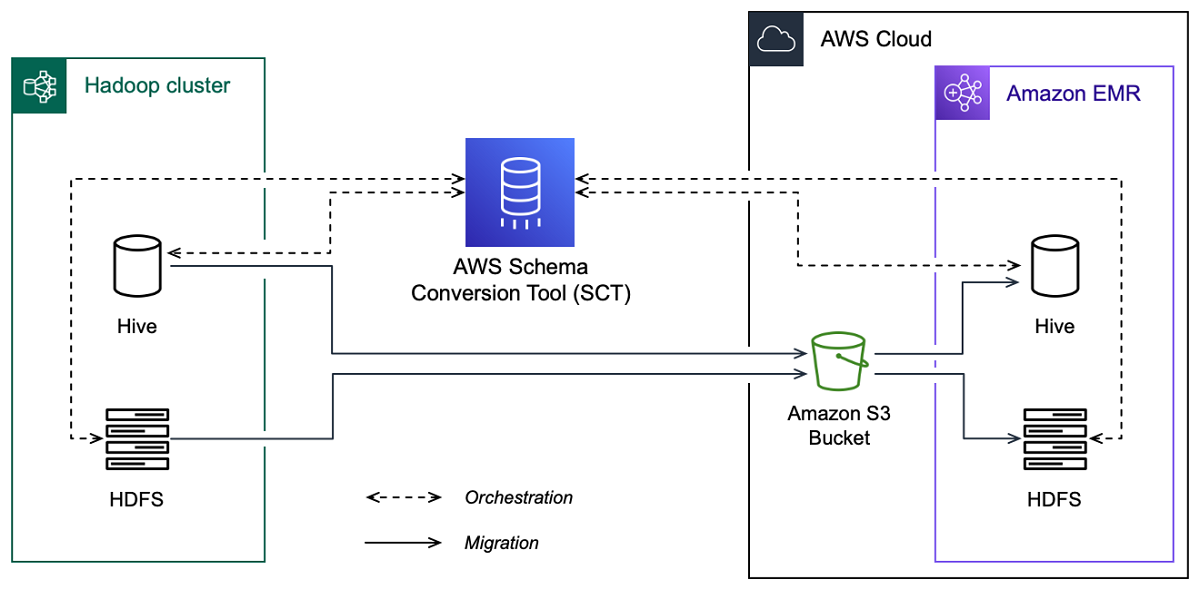
AWS SCT migra los datos y metadatos del clúster de Hadoop de origen a un bucket de Amazon S3. A continuación, AWS SCT utiliza los metadatos de Hive de origen para crear objetos de base de datos en el servicio de Hive de Amazon EMR. Si lo desea, puede configurar Hive para que lo utilice como metaalmacén. AWS Glue Data Catalog En este caso, AWS SCT migra los metadatos de Hive de origen a. AWS Glue Data Catalog
A continuación, puede utilizarlos AWS SCT para migrar los datos de un bucket de Amazon S3 a su servicio Amazon EMR HDFS de destino. Como alternativa, puede dejar los datos en el bucket de Amazon S3 y utilizarlos como repositorio de datos para las cargas de trabajo de Hadoop.
Para iniciar la migración de Hapood, debe crear y ejecutar el script AWS SCT CLI. Este script incluye el conjunto completo de comandos para ejecutar la migración. Puede descargar y editar una plantilla del script de migración de Hadoop. Para obtener más información, consulte Obtención de escenarios de la CLI.
Asegúrese de que el script incluye los siguientes pasos para poder ejecutar la migración de Apache Hadoop a Amazon S3 y Amazon EMR.
Paso 1: Conectarse a los clústeres de Hadoop
Para iniciar la migración de su clúster de Apache Hadoop, cree un proyecto nuevo. AWS SCT A continuación, conéctese a los clústeres de origen y destino. Asegúrese de crear y aprovisionar AWS los recursos de destino antes de iniciar la migración.
En este paso, se utilizan los siguientes comandos de AWS SCT CLI.
CreateProject— para crear un AWS SCT proyecto nuevo.AddSourceCluster: para conectarse al clúster de Hadoop de origen del proyecto de AWS SCT .AddSourceClusterHive: para conectarse al servicio de Hive de origen del proyecto.AddSourceClusterHDFS: para conectarse al servicio de HDFS de origen del proyecto.AddTargetCluster: para conectarse al clúster de Amazon EMR de destino del proyecto.AddTargetClusterS3: para agregar el bucket de Amazon S3 al proyecto.AddTargetClusterHive: para conectarse al servicio de Hive de destino del proyectoAddTargetClusterHDFS: para conectarse al servicio de HDFS de destino del proyecto
Para ver ejemplos del uso de estos comandos AWS SCT CLI, consulteConexión a Apache Hadoop.
Al ejecutar el comando que se conecta a un clúster de origen o destino, AWS SCT intenta establecer la conexión con este clúster. Si el intento de conexión falla, AWS SCT deja de ejecutar los comandos del script CLI y muestra un mensaje de error.
Paso 2: Configurar las reglas de asignación
Después de conectarse a los clústeres de origen y destino, configure las reglas de asignación. Una regla de asignación define el objetivo de migración de un clúster de origen. Asegúrese de configurar las reglas de mapeo para todos los clústeres de origen que haya agregado al AWS SCT proyecto. Para obtener más información acerca de las reglas de asignación, consulte Asignación de tipos de datos en AWS Schema Conversion Tool.
En este paso, utilice el comando AddServerMapping. Este comando usa dos parámetros, que definen los clústeres de origen y destino. Puede utilizar el comando AddServerMapping con la ruta explícita a los objetos de la base de datos o con el nombre de un objeto. En la primera opción, debe incluir el tipo de objeto y su nombre. Para la segunda opción, incluya solo los nombres de los objetos.
-
sourceTreePath: la ruta explícita a los objetos de la base de datos de origen.targetTreePath: la ruta explícita a los objetos de la base de datos de destino. -
sourceNamePath: la ruta que incluye solo los nombres de los objetos de origen.targetNamePath: la ruta que incluye solo los nombres de los objetos de destino.
El siguiente ejemplo de código crea una regla de asignación mediante rutas explícitas para la base de datos de Hive testdb de origen y el clúster de EMR de destino.
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
Puede usar este ejemplo y los ejemplos siguientes en Windows. Para ejecutar los comandos de la CLI en Linux, actualice las rutas de los archivos de forma adecuada según el sistema operativo.
El siguiente ejemplo de código crea una regla de asignación utilizando las rutas que incluyen solo los nombres de los objetos.
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
Puede elegir Amazon EMR o Amazon S3 como destino para el objeto de origen. Para cada objeto de origen, solo puede elegir un destino en un único AWS SCT proyecto. Para cambiar el destino de migración de un objeto de origen, elimine la regla de asignación existente y, a continuación, cree una regla de asignación nueva. Para eliminar una regla de asignación, utilice el comando DeleteServerMapping. Este comando usa uno de los dos parámetros siguientes.
sourceTreePath: la ruta explícita a los objetos de la base de datos de origen.sourceNamePath: la ruta que incluye solo los nombres de los objetos de origen.
Para obtener más información sobre los comandos AddServerMapping y DeleteServerMapping, consulte la Referencia de la CLI de AWS Schema Conversion Tool
Paso 3: Crear un informe de evaluación
Antes de iniciar la migración, le recomendamos que cree un informe de evaluación. Este informe resume todas las tareas de migración y detalla las acciones que surgirán durante la migración. Para asegurarse de que la migración no falle, consulte este informe y aborde las medidas que se deben tomar antes de la migración. Para obtener más información, consulte Informes de evaluación.
En este paso, utilice el comando CreateMigrationReport. Este comando emplea dos parámetros. El parámetro treePath es obligatorio y el parámetro forceMigrate es opcional.
treePath: la ruta explícita a los objetos de la base de datos de origen para los que guarda una copia del informe de evaluación.forceMigrate— si está configurado entrue, AWS SCT continúa la migración incluso si el proyecto incluye una carpeta HDFS y una tabla Hive que hagan referencia al mismo objeto. El valor predeterminado esfalse.
Puede guardar una copia del informe de evaluación en formato PDF o como un archivo de valores separados por comas (CSV). Para ello, utilice el comando SaveReportPDF o SaveReportCSV.
El comando SaveReportPDF guarda una copia del informe de evaluación en un archivo PDF. Este comando utiliza cuatro parámetros. El parámetro file es obligatorio, mientras que otros parámetros son opcionales.
file: la ruta al archivo PDF y su nombre.filter: el nombre del filtro que creó anteriormente para definir el alcance de los objetos de origen que desee migrar.treePath: la ruta explícita a los objetos de la base de datos de origen para los que guarda una copia del informe de evaluación.namePath: la ruta que incluye solo los nombres de los objetos de destino para los que guarda una copia del informe de evaluación.
El comando SaveReportCSV guarda el informe de evaluación en tres archivos CSV. Este comando utiliza cuatro parámetros. El parámetro directory es obligatorio, mientras que otros parámetros son opcionales.
directory— la ruta a la carpeta donde se AWS SCT guardan los archivos CSV.filter: el nombre del filtro que creó anteriormente para definir el alcance de los objetos de origen que desee migrar.treePath: la ruta explícita a los objetos de la base de datos de origen para los que guarda una copia del informe de evaluación.namePath: la ruta que incluye solo los nombres de los objetos de destino para los que guarda una copia del informe de evaluación.
El siguiente ejemplo de código guarda una copia del informe de evaluación en el archivo c:\sct\ar.pdf.
SaveReportPDF -file:'c:\sct\ar.pdf' /
El siguiente ejemplo de código guarda una copia del informe de evaluación en archivos CSV en la carpeta c:\sct.
SaveReportCSV -file:'c:\sct' /
Para obtener más información sobre los comandos SaveReportPDF y SaveReportCSV, consulte la Referencia de la CLI de AWS Schema Conversion Tool
Paso 4: Migre su clúster de Apache Hadoop a Amazon EMR con AWS SCT
Tras configurar el AWS SCT proyecto, inicie la migración del clúster de Apache Hadoop local al. Nube de AWS
En este paso, utilice los comandos Migrate, MigrationStatus y ResumeMigration.
El comando Migrate migra los objetos de origen al clúster de destino. Este comando utiliza cuatro parámetros. Especifique el parámetro filter o treePath. El resto de los parámetros son opcionales.
filter: el nombre del filtro que creó anteriormente para definir el alcance de los objetos de origen que desee migrar.treePath: la ruta explícita a los objetos de la base de datos de origen para los que guarda una copia del informe de evaluación.forceLoad— cuando se establece entrue, carga AWS SCT automáticamente los árboles de metadatos de la base de datos durante la migración. El valor predeterminado esfalse.forceMigrate— si se establece entrue, AWS SCT continúa la migración incluso si el proyecto incluye una carpeta HDFS y una tabla Hive que hagan referencia al mismo objeto. El valor predeterminado esfalse.
El comando MigrationStatus devuelve información sobre el progreso de la migración. Para ejecutar este comando, introduzca el nombre del proyecto de migración para el parámetro name. Especificó este nombre en el comando CreateProject.
El comando ResumeMigration reanuda la migración interrumpida que inició con el comando Migrate. El comando ResumeMigration no utiliza parámetros. Para reanudar la migración, debe conectarse a los clústeres de origen y destino. Para obtener más información, consulte Administración del proyecto de migración.
El siguiente ejemplo de código migra los datos del servicio de HDFS de origen a Amazon EMR.
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
Ejecución del script de la CLI
Cuando termine de editar el script AWS SCT CLI, guárdelo como un archivo con la .scts extensión. Ahora, puede ejecutar el script desde la app carpeta de la ruta de AWS SCT instalación. Para ello, utilice el siguiente comando.
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
En el ejemplo anterior, script_path sustitúyalo por la ruta del archivo con el script CLI. Para obtener más información sobre la ejecución de scripts CLI en AWS SCT, consulteModo script.
Administración del proyecto de migración de macrodatos
Después de completar la migración, puede guardar y editar el AWS SCT proyecto para usarlo en el futuro.
Para guardar el AWS SCT proyecto, utilice el SaveProject comando. El comando no utiliza parámetros.
El siguiente ejemplo de código guarda el AWS SCT proyecto.
SaveProject /
Para abrir el AWS SCT proyecto, utilice el OpenProject comando. Este comando usa un parámetro obligatorio. Para el file parámetro, introduzca la ruta del archivo de AWS SCT proyecto y su nombre. Especificó el nombre del proyecto en el comando CreateProject. Agregue la extensión .scts al nombre del archivo de proyecto para ejecutar el comando OpenProject.
El siguiente ejemplo de código abre el proyecto de hadoop_emr desde la carpeta c:\sct.
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
Tras abrir el AWS SCT proyecto, no es necesario añadir los clústeres de origen y destino porque ya los ha añadido al proyecto. Para empezar a trabajar con los clústeres de origen y destino, debe conectarse a ellos. Para ello, utilice los comandos ConnectSourceCluster y ConnectTargetCluster. Estos comandos utilizan los mismos parámetros que los comandos AddSourceCluster y AddTargetCluster. Puede editar el script de la CLI y reemplazar el nombre de estos comandos dejando la lista de parámetros sin cambios.
El siguiente ejemplo de código se conecta al clúster de Hadoop de origen.
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
El siguiente ejemplo de código se conecta al clúster de Amazon EMR de destino.
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
En el ejemplo anterior, hadoop_address sustitúyalo por la dirección IP del clúster de Hadoop. Si es necesario, configure el valor de la variable de puerto. A continuación, sustituya hadoop_user y hadoop_password por el nombre de su usuario de Hadoop y la contraseña de este usuario. Para ellopath\name, introduzca el nombre y la ruta del archivo PEM del clúster de Hadoop de origen. Para obtener más información acerca de cómo agregar los clústeres de origen y destino, consulte Conectarse a las bases de datos de Apache Hadoop con el AWS Schema Conversion Tool.
Tras conectarse a los clústeres de Hadoop de origen y destino, debe conectarse a los servicios de Hive y HDFS, así como al bucket de Amazon S3. Para ello, utilice los comandos ConnectSourceClusterHive, ConnectSourceClusterHdfs, ConnectTargetClusterHive, ConnectTargetClusterHdfs y ConnectTargetClusterS3. Estos comandos utilizan los mismos parámetros que los comandos que utilizó para agregar los servicios de Hive y HDFS y el bucket de Amazon S3 al proyecto. Edite el script de la CLI para reemplazar el prefijo Add por Connect en los nombres de los comandos.
