Monitoreo de las actualizaciones de estado de los dispositivos en DynamoDB
En este caso de uso se habla de utilizar DynamoDB para monitorear las actualizaciones del estado del dispositivo (o los cambios en el estado del dispositivo) en DynamoDB.
Caso de uso
En los casos de uso de IoT (una fábrica inteligente, por ejemplo), los operadores deben monitorear muchos dispositivos y estos envían periódicamente su estado o sus registros a un sistema de monitoreo. Cuando hay un problema con un dispositivo, el estado del mismo cambia de normal a advertencia. Existen diferentes niveles o estados de registro en función de la gravedad y el tipo de comportamiento anómalo del dispositivo. A continuación, el sistema asigna a un operario para que compruebe el dispositivo y este puede escalar el problema a su supervisor si es necesario.
Algunos patrones de acceso típicos de este sistema son:
-
Crear una entrada de registro para un dispositivo
-
Obtener todos los registros para un estado de dispositivo específico mostrando primero los registros más recientes
-
Obtener todos los registros de un operador dado entre dos fechas
-
Obtener todos los registros escalados de un supervisor determinado
-
Obtener todos los registros escalados con un estado de dispositivo específico para un supervisor determinado
-
Obtener todos los registros escalados con un estado de dispositivo específico para un supervisor determinado en una fecha concreta
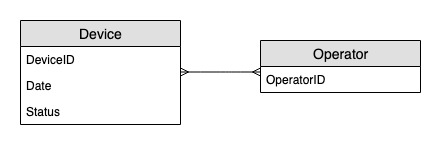
Diagrama de relaciones entre entidades
Este es el diagrama de relaciones entre entidades (ERD) que utilizaremos para monitorear las actualizaciones del estado de los dispositivos.
Patrones de acceso
Estos son los patrones de acceso que tendremos en cuenta para monitorear las actualizaciones de estado de los dispositivos.
-
createLogEntryForSpecificDevice -
getLogsForSpecificDevice -
getWarningLogsForSpecificDevice -
getLogsForOperatorBetweenTwoDates -
getEscalatedLogsForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisorForDate
Evolución del diseño de esquema
Paso 1: Abordar patrones de acceso 1 (createLogEntryForSpecificDevice) y 2 (getLogsForSpecificDevice)
La unidad de escala para un sistema de seguimiento de dispositivos serían los dispositivos individuales. En este sistema, un deviceID identifica de forma única a un dispositivo. Esto convierte a deviceID en un buen candidato para la clave de partición. Cada dispositivo envía información al sistema de seguimiento periódicamente ( por ejemplo, cada cinco minutos más o menos). Esta ordenación convierte a la fecha en un criterio lógico de clasificación y, por tanto, en la clave de clasificación. Los datos de muestra en este caso tendrían este aspecto:
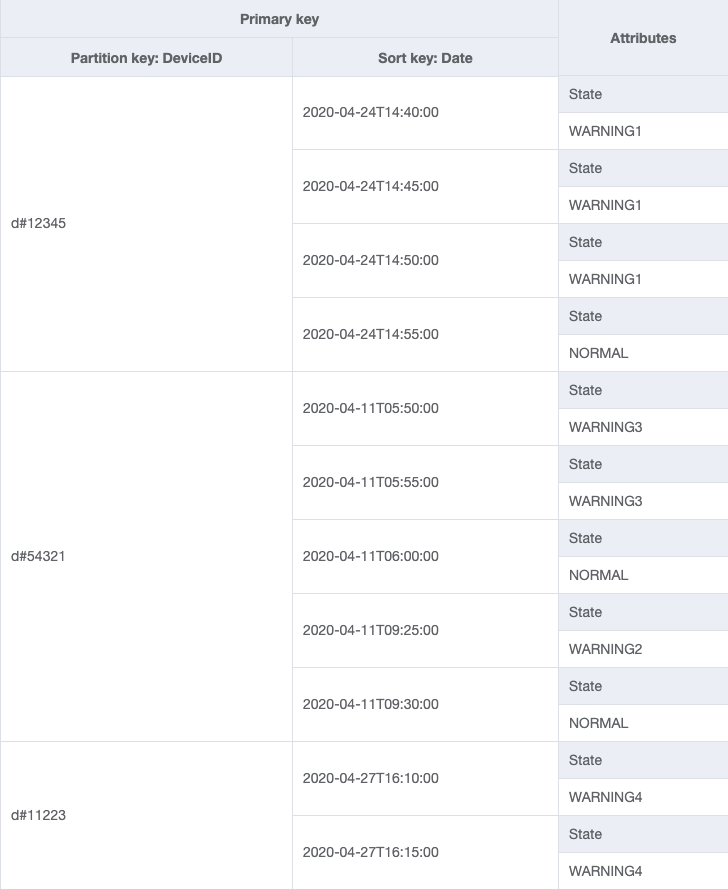
Para recuperar las entradas de registro de un dispositivo concreto, podemos realizar una operación de consulta con clave de partición DeviceID="d#12345".
Paso 2: Abordar el patrón de acceso 3 (getWarningLogsForSpecificDevice)
Dado que State es un atributo no clave, abordar el patrón de acceso 3 con el esquema actual requeriría una expresión de filtro. En DynamoDB, las expresiones de filtro se aplican después de leer los datos mediante expresiones de condición clave. Por ejemplo, si quisiéramos obtener los registros de advertencias de d#12345, la operación de consulta con clave de partición DeviceID="d#12345" leerá cuatro elementos de la tabla anterior y, a continuación, filtrará el único elemento sin el estado de advertencia. Este enfoque no es eficiente a escala. Una expresión de filtro puede ser una buena forma de excluir elementos consultados si la proporción de elementos excluidos es baja o la consulta se realiza con poca frecuencia. No obstante, para los casos en los que se recuperan muchos elementos de una tabla y la mayoría de los elementos se filtran, podemos seguir evolucionando el diseño de nuestra tabla para que funcione de forma más eficiente.
Cambiemos la forma de gestionar este patrón de acceso mediante claves de clasificación compuestas. Puede importar datos de muestra de DeviceStateLog_3.jsonState#Date. Esta clave de clasificación es la composición de los atributos State, # y Date. En este ejemplo, # se utiliza como delimitador. Los datos tienen ahora este aspecto:
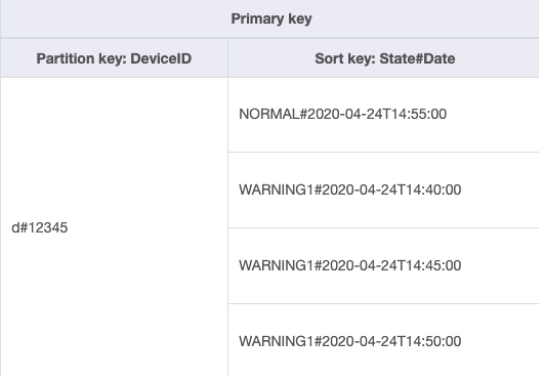
Para obtener solo los registros de advertencia de un dispositivo, la consulta se vuelve más específica con este esquema. La condición clave para la consulta utiliza la clave de partición DeviceID="d#12345" y la clave de clasificación State#Date begins_with
“WARNING”. Esta consulta solo leerá los tres elementos relevantes con el estado de advertencia.
Paso 3: Abordar el patrón de acceso 4 (getLogsForOperatorBetweenTwoDates)
Puede importar DeviceStateLog_4.jsonDOperator a la tabla DeviceStateLog con datos de ejemplo.
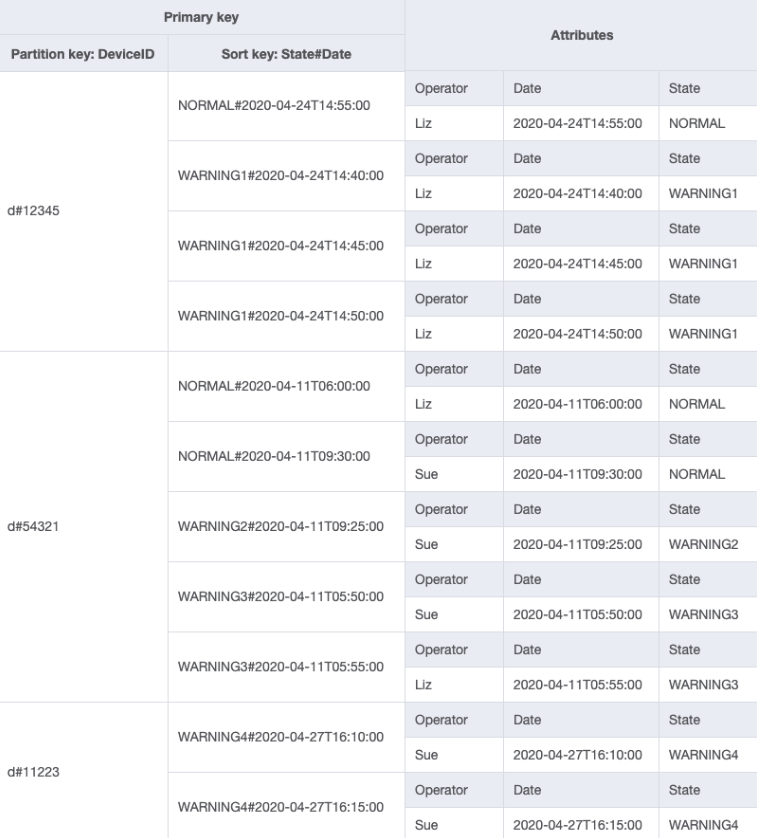
Dado que Operator no es actualmente una clave de partición, no hay forma de realizar una búsqueda directa de clave-valor en esta tabla basada en OperatorID. Tendremos que crear una nueva colección de elementos con un índice secundario global en OperatorID. El patrón de acceso requiere una búsqueda basada en fechas, por lo que Fecha es el atributo de clave de clasificación para el índice secundario global (GSI). Este es el aspecto actual del GSI:
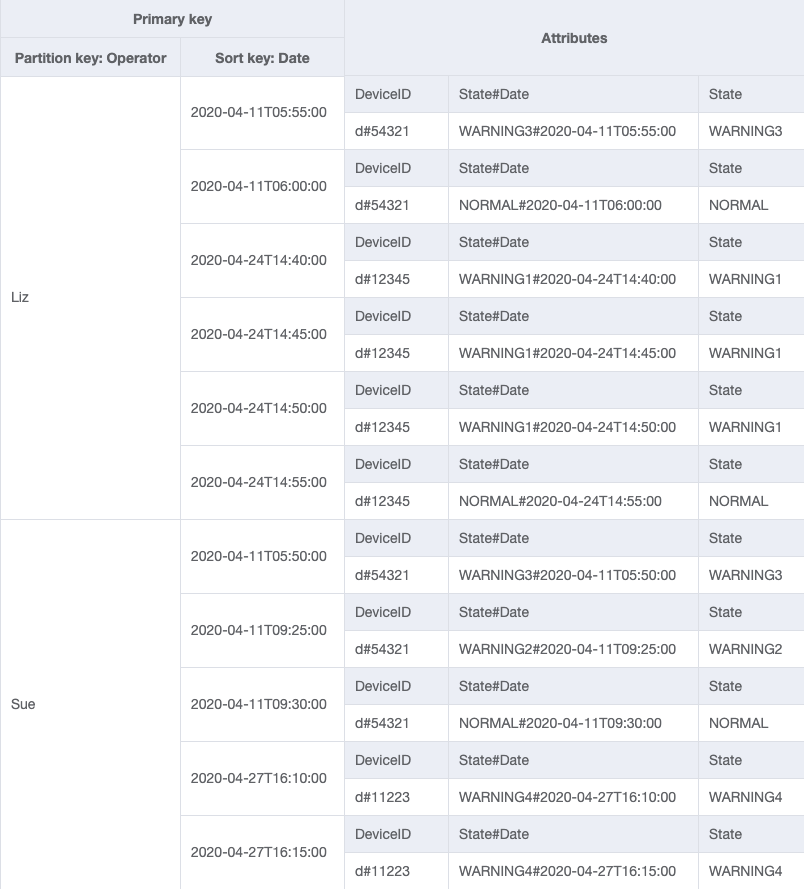
Para el patrón de acceso 4 (getLogsForOperatorBetweenTwoDates), puede consultar este GSI con clave de partición OperatorID=Liz y clave de clasificación Date entre 2020-04-11T05:58:00 y 2020-04-24T14:50:00.
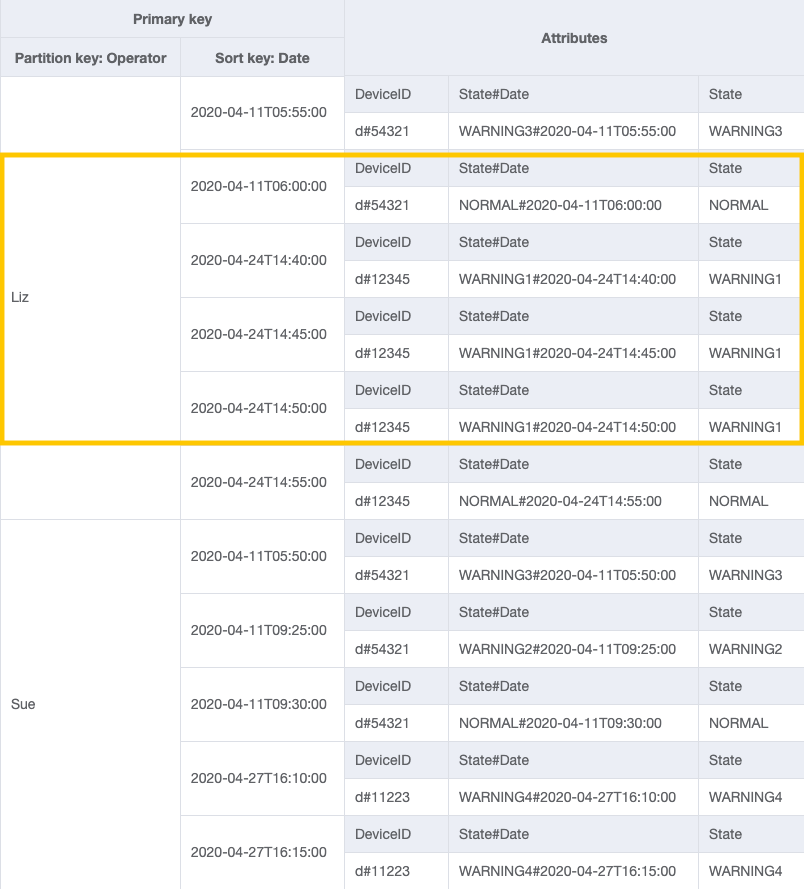
Paso 4: Abordar patrones de acceso 5 (getEscalatedLogsForSupervisor), 6 (getEscalatedLogsWithSpecificStatusForSupervisor) y 7 (getEscalatedLogsWithSpecificStatusForSupervisorForDate)
Utilizaremos un índice disperso para abordar estos patrones de acceso.
Los índices secundarios globales son dispersos de forma predeterminada, por lo que solo aparecerán en el índice los elementos de la tabla base que contengan atributos de clave principal del índice. Esta es otra forma de excluir elementos que no son relevantes para el patrón de acceso que se está modelando.
Puede importar DeviceStateLog_6.jsonEscalatedTo a la tabla DeviceStateLog con datos de ejemplo. Como ya se ha mencionado, no todos los registros se escalan a un supervisor.
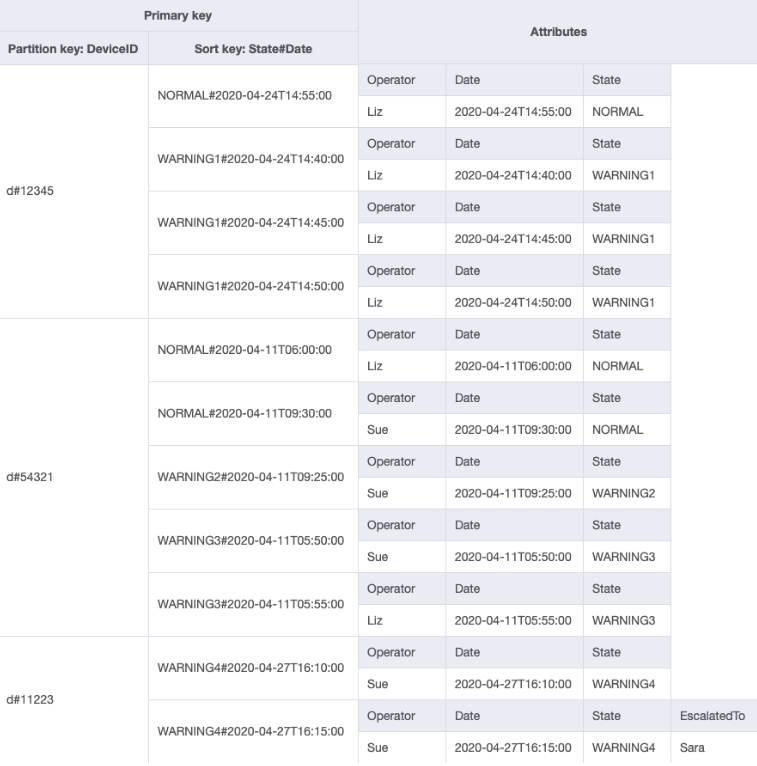
Ahora puede crear un nuevo GSI en el que EscalatedTo es la clave de partición y State#Date es la clave de clasificación. Observe que solo aparecen en el índice los elementos que tienen los atributos EscalatedTo y State#Date.

El resto de los patrones de acceso se resumen como sigue:
En la tabla siguiente se resumen todos los patrones de acceso y cómo los aborda el diseño del esquema:
| Patrón de acceso | Tabla base/GSI/LSI | Operación | Valor de clave de partición | Valor de la clave de clasificación | Otras condiciones/filtros |
|---|---|---|---|---|---|
| createLogEntryForSpecificDevice | Tabla de base | PutItem | DeviceID=deviceId | State#Date=state#date | |
| getLogsForSpecificDevice | Tabla de base | Consultar | DeviceID=deviceId | State#Date begins_with “state1#” | ScanIndexForward = False |
| getWarningLogsForSpecificDevice | Tabla de base | Consultar | DeviceID=deviceId | State#Date begins_with “WARNING” | |
| getLogsForOperatorBetweenTwoDates | GSI-1 | Consultar | Operator=operatorName | Date between date1 and date2 | |
| getEscalatedLogsForSupervisor | GSI-2 | Consultar | EscalatedTo=supervisorName | ||
| getEscalatedLogsWithSpecificStatusForSupervisor | GSI-2 | Consultar | EscalatedTo=supervisorName | State#Date begins_with “state1#” | |
| getEscalatedLogsWithSpecificStatusForSupervisorForDate | GSI-2 | Consultar | EscalatedTo=supervisorName | State#Date begins_with “state1#date1” |
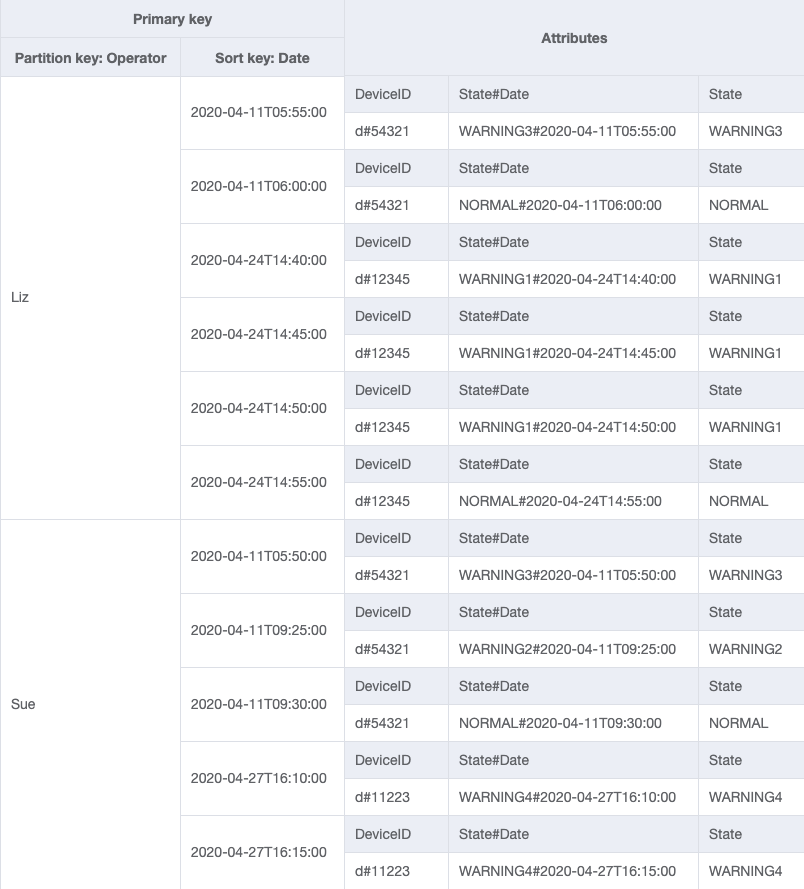
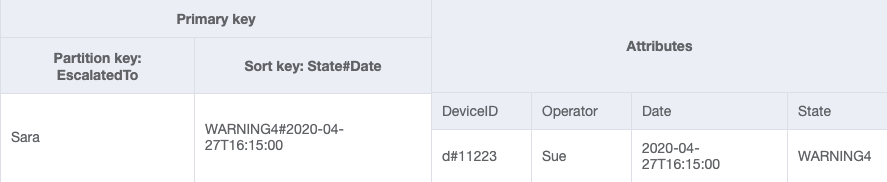
Esquema final
Estos son los diseños finales del esquema. Para descargar este diseño de esquema como un archivo JSON, consulte los ejemplos de DynamoDB
Tabla base
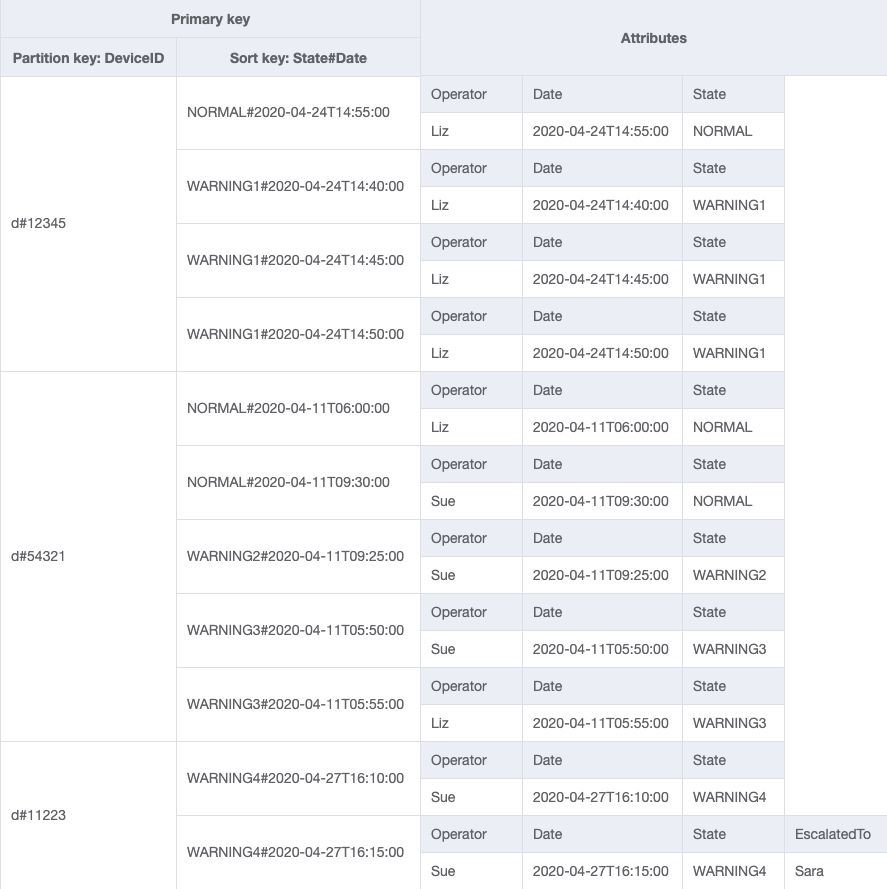
GSI-1
GSI-2
Uso de NoSQL Workbench con este diseño de esquema
Puede importar este esquema final en NoSQL Workbench, una herramienta visual que proporciona características de modelado de datos, visualización de datos y desarrollo de consultas para DynamoDB, a fin de explorar y editar más a fondo el nuevo proyecto. Para comenzar, siga estos pasos:
-
Descargue NoSQL Workbench. Para obtener más información, consulte Descargar NoSQL Workbench para DynamoDB.
-
Descargue el archivo de esquema JSON que se muestra anteriormente, que ya está en el formato de modelo NoSQL Workbench.
-
Importe el archivo de esquema JSON en NoSQL Workbench. Para obtener más información, consulte Importación de un modelo de datos existente.
-
Una vez que haya importado en NOSQL Workbench, podrá editar el modelo de datos. Para obtener más información, consulte Edición de un modelo de datos existente.
