Migración desde una base de datos relacional a DynamoDB
La migración de una base de datos relacional a DynamoDB requiere una planificación cuidadosa para garantizar un resultado satisfactorio. Esta guía lo ayudará a entender cómo funciona este proceso, qué herramientas tiene disponibles y a evaluar las posibles estrategias de migración para elegir la que mejor se adapte a sus necesidades.
Temas
Razones para migrar a DynamoDB
La migración a Amazon DynamoDB presenta una serie de ventajas muy interesantes para las empresas y las organizaciones. Estas son algunas de las principales ventajas que convierten a DynamoDB en una opción atractiva para migrar las bases de datos:
-
Escalabilidad: DynamoDB se ha diseñado para gestionar cargas de trabajo masivas y escalar sin complicaciones para adaptarse al crecimiento de los volúmenes de datos y del tráfico. DynamoDB le permite ampliar o reducir fácilmente su base de datos en función de la demanda, lo que garantiza que sus aplicaciones puedan gestionar picos repentinos de tráfico sin que afecte al rendimiento.
-
Rendimiento: DynamoDB ofrece acceso a datos de baja latencia, lo que permite a las aplicaciones recuperar y procesar datos con una velocidad excepcional. Su arquitectura distribuida garantiza que las operaciones de lectura y escritura se distribuyan en varios nodos, lo que ofrece tiempos de respuesta uniformes en milisegundos de un solo dígito, incluso con altas tasas de solicitudes.
-
Totalmente administrado: DynamoDB es un servicio totalmente administrado por AWS. Esto significa que AWS gestiona los aspectos operativos de la administración de bases de datos, incluidos el aprovisionamiento, la configuración, la aplicación de parches, las copias de seguridad y el escalado. Esto le permite centrarse más en el desarrollo de sus aplicaciones y menos en las tareas de administración de bases de datos.
-
Arquitectura sin servidor: DynamoDB admite un modelo sin servidor, conocido como DynamoDB bajo demanda, en el que solo se paga por las solicitudes de lectura y escritura reales que realice la aplicación sin que sea necesario aprovisionar capacidad por adelantado. Este modelo de pago por solicitud ofrece rentabilidad y unos gastos operativos mínimos, ya que solo paga por los recursos que consume sin que sea necesario aprovisionar ni monitorear la capacidad.
-
Flexibilidad NoSQL: a diferencia de las bases de datos relacionales tradicionales, DynamoDB sigue un modelo de datos NoSQL, lo que proporciona flexibilidad en el diseño de esquemas. DynamoDB permite almacenar datos estructurados, semiestructurados y sin estructurar, lo que los hace adecuados para gestionar tipos de datos diversos y en constante evolución. Esta flexibilidad permite ciclos de desarrollo más rápidos y una adaptación más sencilla a los requisitos empresariales en constante cambio.
-
Alta disponibilidad y durabilidad: DynamoDB replica los datos en varias zonas de disponibilidad dentro de una región, lo que garantiza una alta disponibilidad y durabilidad de los datos. Además, gestiona automáticamente la replicación, la conmutación por error y la recuperación, lo que minimiza el riesgo de pérdida de datos o interrupciones en el servicio. DynamoDB ofrece un SLA de disponibilidad de hasta el 99,999 %.
-
Seguridad y conformidad: DynamoDB se integra con AWS Identity and Access Management para controlar el acceso de forma precisa. Proporciona cifrado en reposo y en tránsito, lo que garantiza la seguridad de sus datos. DynamoDB también aplica varios estándares de conformidad, como HIPAA, PCI DSS y RGPD, lo que le permite cumplir con los requisitos normativos.
-
Integración con el ecosistema de AWS: al formar parte del ecosistema de AWS, DynamoDB se integra perfectamente con otros servicios de AWS, como AWS Lambda, CloudFormation y AWS AppSync. Esta integración le permite crear arquitecturas sin servidor, aprovechar la infraestructura como código y crear aplicaciones basadas en datos en tiempo real.
Consideraciones al migrar una base de datos relacional a DynamoDB
Los sistemas de bases de datos relacionales y las bases de datos NoSQL tienen diferentes ventajas y desventajas. Estas diferencias hacen que el diseño de las bases de datos sea muy distinto entre los dos sistemas.
| Tipo de tarea | Base de datos relacional | Base de datos NoSQL |
|---|---|---|
| Consultar la base de datos | En las bases de datos relacionales, los datos se pueden consultar de manera flexible, pero las consultas son relativamente caras y no escalan bien cuando hay mucho tráfico (consulte Primeros pasos para modelar datos relacionales en DynamoDB). Una aplicación de base de datos relacional puede implementar la lógica empresarial en los procedimientos almacenados, las subconsultas de SQL, las consultas de actualización masiva y las consultas de agregación. | En una base de datos NoSQL como DynamoDB, existe un número limitado de métodos para consultar los datos; si se utiliza cualquier otro método diferente a estos, resultará más costoso y lento realizar las consultas. Las escrituras en DynamoDB son simples. La lógica empresarial de la aplicación que antes se ejecutaba en procedimientos almacenados debe refactorizarse para que se ejecute fuera de DynamoDB en un código personalizado que se ejecute en un host como Amazon EC2 o AWS Lambda. |
| Diseño de la base de datos | El diseño busca la flexibilidad sin preocuparse por los detalles o el rendimiento de la implementación. Por lo general, la optimización de consultas no afecta al diseño del esquema, pero la normalización es importante. | El esquema se diseña específicamente para que las consultas más habituales y más importantes resulten lo más rápidas y económicas que sea posible. Las estructuras de datos se ajustan a los requisitos específicos de los casos de uso de la organización. |
Diseñar para una base de datos NoSQL requiere un cambio de mentalidad respecto al diseño de un sistema de administración de bases de datos relacionales (RDBMS). En un sistema RDBMS, puede crear un modelo de datos normalizados sin pensar en los patrones de acceso. Posteriormente, podrá ampliar este modelo cuando surjan nuevos requisitos sobre preguntas y consultas. Puede organizar cada tipo de datos en su propia tabla.
Sin un diseño NoSQL, puede diseñar el esquema para DynamoDB cuando sepa las preguntas a las que tendrá que responder. Es esencial comprender los problemas empresariales y los patrones de lectura y escritura de la aplicación. También debería mantener el menor número de tablas posible en una aplicación de DynamoDB. Tener menos tablas hace que las cosas sean más escalables, requiere menos administración de permisos y reduce la sobrecarga de la aplicación de DynamoDB. También puede ayudar a mantener los costos de las copias de seguridad generalmente más bajos.
La tarea de modelar datos relacionales para DynamoDB y crear una nueva versión de la aplicación front-end se tratan en otro tema. En esta guía se da por sentado que tiene una nueva versión de la aplicación creada para usar DynamoDB, pero que aún debe determinar la mejor manera de migrar y sincronizar los datos históricos durante la transición.
Consideraciones sobre el tamaño
El tamaño máximo de cada elemento (fila) que se almacena en una tabla de DynamoDB es de 400 KB. Para obtener más información, consulte Cuotas en Amazon DynamoDB. El tamaño del elemento viene determinado por el tamaño total de todos los nombres y valores de los atributos de un elemento. Para obtener más información, consulte Tamaños y formatos de elementos de DynamoDB.
Si la aplicación necesita almacenar más datos en un elemento de lo que permite el límite de tamaño de DynamoDB, divida el elemento en una colección de elementos, comprima los datos del elemento o almacene el elemento como un objeto de Amazon Simple Storage Service (Amazon S3) y almacene el identificador de objetos de Amazon S3 en el elemento de DynamoDB. Consulte Prácticas recomendadas para almacenar elementos y atributos grandes en DynamoDB. El costo de actualizar un elemento se basa en el tamaño total del elemento. En el caso de las cargas de trabajo que requieren actualizaciones frecuentes de los elementos existentes, actualizar elementos pequeños de uno o dos KB costará menos que los elementos más grandes. Para obtener más información sobre las colecciones de elementos, consulte Colecciones de elementos: cómo modelar relaciones de uno a varios en DynamoDB.
Al elegir los atributos de clave de clasificación y partición, otros ajustes de la tabla, el tamaño y la estructura de los elementos y si se van a crear índices secundarios, asegúrese de revisar la documentación de modelado de DynamoDB y la guía correspondiente para Optimización de los costos en las tablas de DynamoDB. Asegúrese de probar su plan de migración para que la solución de DynamoDB sea rentable y se ajuste a las características y limitaciones de DynamoDB.
Comprensión del funcionamiento de la migración a DynamoDB
Antes de revisar las herramientas de migración disponibles, piense en cómo procesa DynamoDB las escrituras.
La operación de escritura predeterminada y más común es una operación de API PutItem única. Puede realizar una operación PutItem en bucle para procesar conjuntos de datos. DynamoDB admite conexiones simultáneas prácticamente ilimitadas, por lo que, si puede configurar y ejecutar una rutina de carga masiva con varios subprocesos, como MapReduce o Spark, la velocidad de escritura solo está limitada por la capacidad de la tabla de destino (que también suele ser ilimitada).
Al cargar datos en DynamoDB, es importante comprender la velocidad de escritura del cargador. Si los elementos (filas) que está cargando tienen un tamaño de 1 KB o menos, esta velocidad es simplemente el número de elementos por segundo. A continuación, se puede aprovisionar la tabla de destino con suficientes WCU (unidades de capacidad de escritura) para gestionar esta velocidad. Si el cargador supera la capacidad aprovisionada por algún segundo, es posible que las solicitudes adicionales se limiten o se rechacen por completo. Puede comprobar si hay limitaciones en los gráficos de CloudWatch que se encuentran en la pestaña de monitoreo de la consola de DynamoDB.
La segunda operación que se puede realizar es con una API relacionada llamada BatchWriteItem. BatchWriteItem permite combinar hasta 25 solicitudes de escritura en una llamada a la API. El servicio las recibe y las procesa como solicitudes PutItem independientes en la tabla. Actualmente, al elegir BatchWriteItem, no disfrutará de las ventajas de los reintentos automáticos que se incluyen en el SDK de AWS para realizar llamadas individuales con PutItem. Por lo tanto, si hay algún error (por ejemplo, excepciones de limitación), tendrá que buscar en la lista de escrituras con errores en la llamada de respuesta a BatchWriteItem. Para obtener más información sobre cómo gestionar las advertencias de limitación en caso de que se detecten en los gráficos de limitación de CloudWatch, consulte Solución de problemas de limitación en Amazon DynamoDB.
El tercer tipo de importación de datos es posible gracias a la característica Importación de DynamoDB desde S3PutItem, requiere un proceso previo y escribe los datos en el formato elegido en un bucket de Amazon S3.
Herramientas que ayudan a migrar a DynamoDB
Existen varias herramientas comunes de migración y ETL que puede utilizar para migrar datos a DynamoDB.
Amazon ofrece un host de herramientas de datos que se puede usar en migración, como AWS Database Migration Service (DMS), AWS Glue, Amazon EMR y Amazon Managed Streaming for Apache Kafka. Todas estas herramientas se pueden utilizar para realizar una migración durante el tiempo de inactividad y pueden aprovechar las características de la captura de datos de cambios (CDC) de la base de datos relacional para admitir las migraciones en línea. Al elegir una herramienta, será útil tener en cuenta el conjunto de destrezas y la experiencia que la organización tiene con cada herramienta, junto con las características, el rendimiento y el costo de cada una de ellas.
Muchos clientes optan por escribir sus propios scripts y trabajos de migración para crear transformaciones de datos personalizadas para el proceso de migración. Si tiene previsto operar una tabla de DynamoDB de gran volumen con mucho tráfico de escritura o con trabajos normales de gran carga masiva, puede que quiera escribir código de migración usted mismo para ganar confianza con el comportamiento de DynamoDB con un tráfico de escritura intenso. Al realizar una migración de práctica, se puede experimentar con situaciones como la gestión de la aceleración y el aprovisionamiento eficiente de tablas al principio del proyecto.
Elección de la estrategia adecuada para migrar a DynamoDB
Una aplicación de base de datos relacional grande puede abarcar cien o más tablas y admitir varias funciones de aplicación diferentes. Al realizar una migración grande, considere la posibilidad de dividir la aplicación en componentes o microservicios más pequeños y migrar un conjunto pequeño de tablas a la vez. A continuación, puede migrar componentes adicionales a DynamoDB en oleadas.
Al seleccionar una estrategia de migración, varios factores pueden orientarlo hacia una solución u otra. Podemos presentar estas opciones en un árbol de decisiones para simplificar las opciones disponibles en función de los requisitos y recursos disponibles. Los conceptos se mencionan brevemente aquí (pero se tratarán con más detalle más adelante en la guía):
-
Migración sin conexión: si la aplicación puede tolerar algún tiempo de inactividad durante la migración, se simplificará el proceso de migración.
-
Migración híbrida: este enfoque permite un tiempo de actividad parcial durante una migración, como permitir lecturas pero no escrituras, o permitir lecturas e inserciones, pero no actualizaciones ni eliminaciones.
-
Migración en línea: las aplicaciones que no requieren ningún tiempo de inactividad durante la migración son más difíciles de migrar y pueden requerir una planificación significativa y un desarrollo personalizado. Una decisión clave es estimar y sopesar los costos de crear un proceso de migración personalizado frente al costo que supone para la empresa disponer de un periodo de inactividad durante la transición.
| Si | Y | Entonces |
|---|---|---|
| Le parece bien cerrar la aplicación algún tiempo durante un periodo de mantenimiento para realizar la migración de datos. Esta migración se denomina migración sin conexión. |
Utilice AWS DMS y realice una migración sin conexión con una tarea de carga completa. Si lo desea, dé forma previamente a los datos de origen con un SQL |
|
| Le parece bien ejecutar la aplicación en modo de solo lectura durante la migración. Entonces la denominamos migración híbrida. | Desactive las escrituras en la aplicación o en la base de datos de origen. Utilice AWS DMS y realice una migración sin conexión con una tarea de carga completa. | |
| Le parece bien ejecutar la aplicación con lecturas e inserciones de nuevos registros, pero sin actualizarla ni eliminarla, durante la migración. Entonces la denominamos migración híbrida. | Tiene conocimientos de desarrollo de aplicaciones y puede actualizar la aplicación relacional existente para realizar escrituras duales, incluso en DynamoDB, para todos los registros nuevos | Utilice AWS DMS y realice una migración sin conexión con una tarea de carga completa. Al mismo tiempo, despliegue una versión de la aplicación existente que permita leer y realizar escrituras duales. |
| Necesita una migración con un tiempo de inactividad mínimo, Esta migración se denomina migración en línea. |
|
Utilice AWS DMS para realizar una migración de datos en línea. Ejecute una tarea de carga masiva seguida de una tarea de sincronización de CDC. |
| Necesita una migración con un tiempo de inactividad mínimo, Esta migración se denomina migración en línea. |
|
Cree la tabla lista para NoSQL en la base de datos SQL. Rellénela y sincronícela con elementos JOIN, UNION, VIEW, desencadenadores y procedimientos almacenados. |
| Necesita una migración con un tiempo de inactividad mínimo, Esta migración se denomina migración en línea. |
|
Tenga en cuenta los enfoques de migración híbrida o sin conexión. |
| Necesita una migración con un tiempo de inactividad mínimo, Esta migración se denomina migración en línea. | Le parece bien omitir la migración de los datos históricos de transacciones o puede archivarlos en Amazon S3 en lugar de migrarlos. Solo tiene que migrar unas cuantas tablas estáticas pequeñas. | Escriba un script o utilice cualquier herramienta ETL para migrar las tablas. Si lo desea, dé forma previamente a los datos de origen con un SQL VIEW. |
Migración sin conexión a DynamoDB
Las migraciones sin conexión son adecuadas cuando se puede permitir un período de inactividad para realizar la migración. Las bases de datos relacionales suelen tener un tiempo de inactividad cada mes para realizar trabajos de mantenimiento y de aplicación de parches, o incluso tiempos de inactividad más largos en caso de actualizaciones de hardware o versiones importantes.
Amazon S3 se puede utilizar como área provisional durante una migración. Los datos almacenados en formato CSV (valores separados por comas) o JSON de DynamoDB se pueden importar automáticamente a una nueva tabla de DynamoDB con la característica Importación de DynamoDB desde S3.
Es posible que quiera combinar tablas para aprovechar patrones de acceso NoSQL únicos (por ejemplo, transformar cuatro tablas heredadas en una sola tabla de DynamoDB). Por lo general, una solicitud de documento con un único valor clave o una consulta de una recopilación de elementos agrupados previamente tiene una mejor latencia que una base de datos SQL que realiza una unión de varias tablas. Sin embargo, esto hace más difícil la tarea de migración. Una vista SQL podría hacer el trabajo dentro de la base de datos de origen para preparar un único conjunto de datos que represente las cuatro tablas de un conjunto.

Esta vista puede crear tablas JOIN en una forma desnormalizada o podría mantener las entidades normalizadas y apilar las tablas mediante un SQL UNION. En este vídeo
Plan
Realización de una migración sin conexión con Amazon S3
Herramientas
-
Un trabajo ETL para extraer y transformar datos SQL y almacenarlos en un bucket de S3, como:
-
AWS Database Migration Service, un servicio que puede cargar datos históricos de forma masiva y también puede procesar registros de captura de datos de cambio (CDC) para sincronizar las tablas de origen y destino.
-
AWS Glue
-
Amazon EMR
-
Su propio código personalizado
-
-
Característica Importación de DynamoDB desde S3
Pasos de la migración sin conexión:
-
Cree un trabajo ETL que pueda consultar la base de datos SQL, transformar los datos de las tablas en formato JSON o CSV de DynamoDB y guardarlos en un bucket de S3.

-
La característica Importación de DynamoDB desde S3 se invoca para crear una tabla nueva y cargar automáticamente los datos desde el bucket de S3.
La migración total sin conexión es sencilla y directa, pero puede que no sea muy popular entre los propietarios y los usuarios de las aplicaciones. Los usuarios se beneficiarían si la aplicación pudiera ofrecer niveles de servicio reducidos durante la migración, en lugar de no ofrecer ningún servicio.
Podría añadir una funcionalidad para desactivar las escrituras durante la migración sin conexión y, al mismo tiempo, permitir que las lecturas continuaran con normalidad. Los usuarios de la aplicación podrían seguir navegando y consultando los datos existentes de forma segura mientras se migran los datos relacionales. Si esto es lo que busca, siga leyendo para obtener más información sobre las migraciones híbridas.
Migración híbrida a DynamoDB
Si bien todas las aplicaciones de bases de datos realizan operaciones de lectura y escritura, se deben tener en cuenta los tipos de operaciones de escritura que se realizan al planificar una migración híbrida o en línea. Las escrituras en bases de datos se pueden clasificar en tres grupos: inserciones, actualizaciones y eliminaciones. Es posible que algunas aplicaciones no requieran el procesamiento inmediato de las eliminaciones. Estas aplicaciones pueden aplazar eliminaciones en un proceso de limpieza masiva a final de mes, por ejemplo. Estos tipos de aplicaciones pueden ser más fáciles de migrar y, al mismo tiempo, requieren un tiempo de actividad parcial.
Plan
Realizar una migración híbrida en línea y sin conexión con escrituras duales de aplicaciones
Herramientas
-
Un trabajo ETL para extraer y transformar datos SQL y almacenarlos en un bucket de S3, como:
-
AWS DMS
-
AWS Glue
-
Amazon EMR
-
Su propio código personalizado
-
Pasos de la migración híbrida:
-
Cree una tabla de DynamoDB de destino. Esta tabla recibirá tanto datos masivos históricos como datos nuevos y activos.
-
Cree una versión de la aplicación heredada que tenga desactivadas las eliminaciones y actualizaciones y, al mismo tiempo, realice todas las inserciones como escrituras duales tanto en la base de datos SQL como en DynamoDB.
-
Comience el trabajo ETL o la tarea de AWS DMS para reponer los datos existentes e implementar la nueva versión de la aplicación al mismo tiempo.
-
Cuando se complete el trabajo de reposición, DynamoDB dispondrá de todos los registros nuevos y existentes y estará listo para la transición de la aplicación.

nota
El trabajo de reposición escribe directamente desde SQL a DynamoDB. No podemos utilizar la característica de importación de S3 como en el ejemplo de migración sin conexión, ya que esa característica crea una tabla nueva que no se ejecutará en un entorno real hasta después de que DynamoDB cargue los datos.
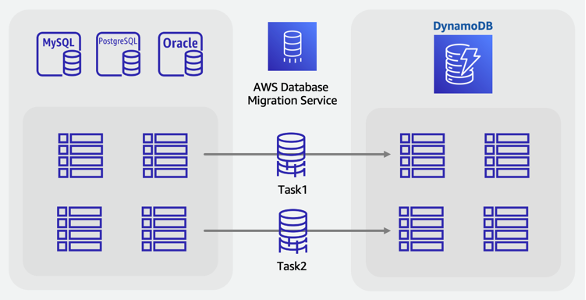
Migración en línea a DynamoDB mediante la migración de cada tabla de forma individual
Muchas bases de datos relacionales tienen una característica llamada Captura de datos de cambios (CDC), que permite a los usuarios solicitar una lista de los cambios realizados en una tabla y que se han realizado antes o después de un momento específico. La CDC utiliza registros internos para activar esta característica y no requiere que la tabla tenga ninguna columna con marca temporal para que funcione.
Al migrar un esquema de tablas SQL a una base de datos NoSQL, es posible que desee combinar y cambiar la forma de los datos en menos tablas. Esto le permitirá recopilar datos en un solo lugar y evitar tener que unir manualmente los datos relacionados en operaciones de lectura de varios pasos. Sin embargo, no siempre es necesario dar forma a los datos de una sola tabla y, a veces, las tablas se migran una por una a DynamoDB. Estas migraciones de tablas individuales una por una son menos complicadas, ya que se puede aprovechar la característica CDC de la base de datos de origen con las herramientas ETL habituales que admiten este tipo de migración. Es posible que los datos de cada fila se sigan transformando en nuevos formatos, pero el alcance de cada tabla sigue siendo el mismo.
Considere la posibilidad de migrar tablas SQL una por una a DynamoDB, con la salvedad de que DynamoDB no admite uniones del servidor. Tendrá que agregar lógica a la aplicación para combinar los datos de varias tablas.
Plan
Realizar una migración en línea de cada tabla a DynamoDB con AWS DMS
Herramientas
Pasos de la migración en línea:
-
Identifique las tablas del esquema de origen que se van a migrar.
-
Cree el mismo número de tablas en DynamoDB con la misma estructura de claves que en el origen.
-
Cree un servidor de replicación en AWS DMS y configure los puntos de conexión de origen y destino.
-
Defina cualquier transformación por fila que sea necesaria (como columnas concatenadas o la conversión de fechas al formato de cadena ISO-8601).
-
Cree una tarea de migración para cada tabla para la carga completa y la captura de datos de cambios.
-
Supervise estas tareas hasta que comience la fase de replicación en curso.
-
Llegados a este punto, puede realizar cualquier auditoría de validación y, a continuación, cambiar los usuarios a la aplicación que lee y escribe en DynamoDB.
Migración en línea a DynamoDB con una tabla provisional personalizada
Como en el escenario de migración sin conexión anterior, tiene la opción de elegir combinar tablas para aprovechar patrones de acceso NoSQL únicos (por ejemplo, transformar cuatro tablas heredadas en una sola tabla de DynamoDB). Un SQL VIEW podría hacer el trabajo dentro de la base de datos de origen para preparar un único conjunto de datos que represente las cuatro tablas de un conjunto.
Sin embargo, para las migraciones en línea con datos cambiantes y activos, no podrá aprovechar las características de CDC, ya que no se admiten para VIEW. Si sus tablas incluyen una columna de marca de tiempo actualizada por última vez y estas se incorporan a la VIEW, puede crear un trabajo ETL personalizado que las utilice para lograr una carga masiva con la sincronización.
Un enfoque novedoso para este desafío es utilizar características SQL estándar, como vistas, procedimientos almacenados y desencadenadores para crear una nueva tabla SQL con el formato final NoSQL de DynamoDB deseado.
Si el servidor de base de datos tiene la capacidad sobrante, es posible crear esta tabla provisional única antes de que comience la migración. Haría esto mediante la escritura de un procedimiento almacenado que lea las tablas existentes, transforme los datos según sea necesario y escriba en la nueva tabla provisional. Puede agregar un conjunto de desencadenadores para replicar los cambios de las tablas en la tabla provisional en tiempo real. Si la política de la empresa no admite los desencadenadores, los cambios en los procedimientos almacenados pueden arrojar el mismo resultado. Usted añadiría unas cuantas líneas de código a cualquier procedimiento que escriba datos para, además, escribir los mismos cambios en la tabla provisional.
Disponer de esta tabla provisional, totalmente sincronizada con las tablas de aplicaciones heredadas, le proporcionará un excelente punto de partida para una migración en directo. Las herramientas que utilizan la CDC de base de datos para realizar migraciones en tiempo real, como AWS DMS, ahora se pueden utilizar en esta tabla. Una ventaja de este enfoque es que utiliza habilidades y características de SQL muy conocidas disponibles en el motor de bases de datos relacionales.
Plan
Realizar una migración en línea con una tabla provisional de SQL mediante AWS DMS
Herramientas
-
Procedimientos o desencadenadores de SQL almacenados y personalizados
Pasos de la migración en línea:
-
En el motor de base de datos relacional de origen, asegúrese de que haya espacio en disco y capacidad de procesamiento adicionales.
-
Cree una nueva tabla provisional en la base de datos SQL, con las marcas de tiempo o las características CDC activadas.
-
Escriba y ejecute un procedimiento almacenado para copiar los datos de la tabla relacional existente en la tabla provisional.
-
Implemente desencadenadores o modifique los procedimientos existentes para realizar una escritura doble en la nueva tabla provisional y, al mismo tiempo, realizar escrituras normales en las tablas existentes.
-
Ejecute AWS DMS para migrar y sincronizar esta tabla de origen con una tabla de DynamoDB de destino.

Esta guía presenta varias consideraciones y enfoques para migrar datos de bases de datos relacionales a DynamoDB, centrándose en minimizar el tiempo de inactividad y utilizar herramientas y técnicas de bases de datos comunes. Para obtener más información, consulte los siguientes temas:
