Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Orígenes de datos
En la sección anterior, hemos aprendido que un esquema define la forma de los datos. Sin embargo, no llegamos a explicar de dónde procedían esos datos. En proyectos reales, el esquema es como una puerta de enlace que gestiona todas las solicitudes realizadas al servidor. Cuando se realiza una solicitud, el esquema actúa como el único punto de conexión que interactúa con el cliente. El esquema accederá a los datos del origen de datos, los procesará y los retransmitirá al cliente. Vea la infografía siguiente:
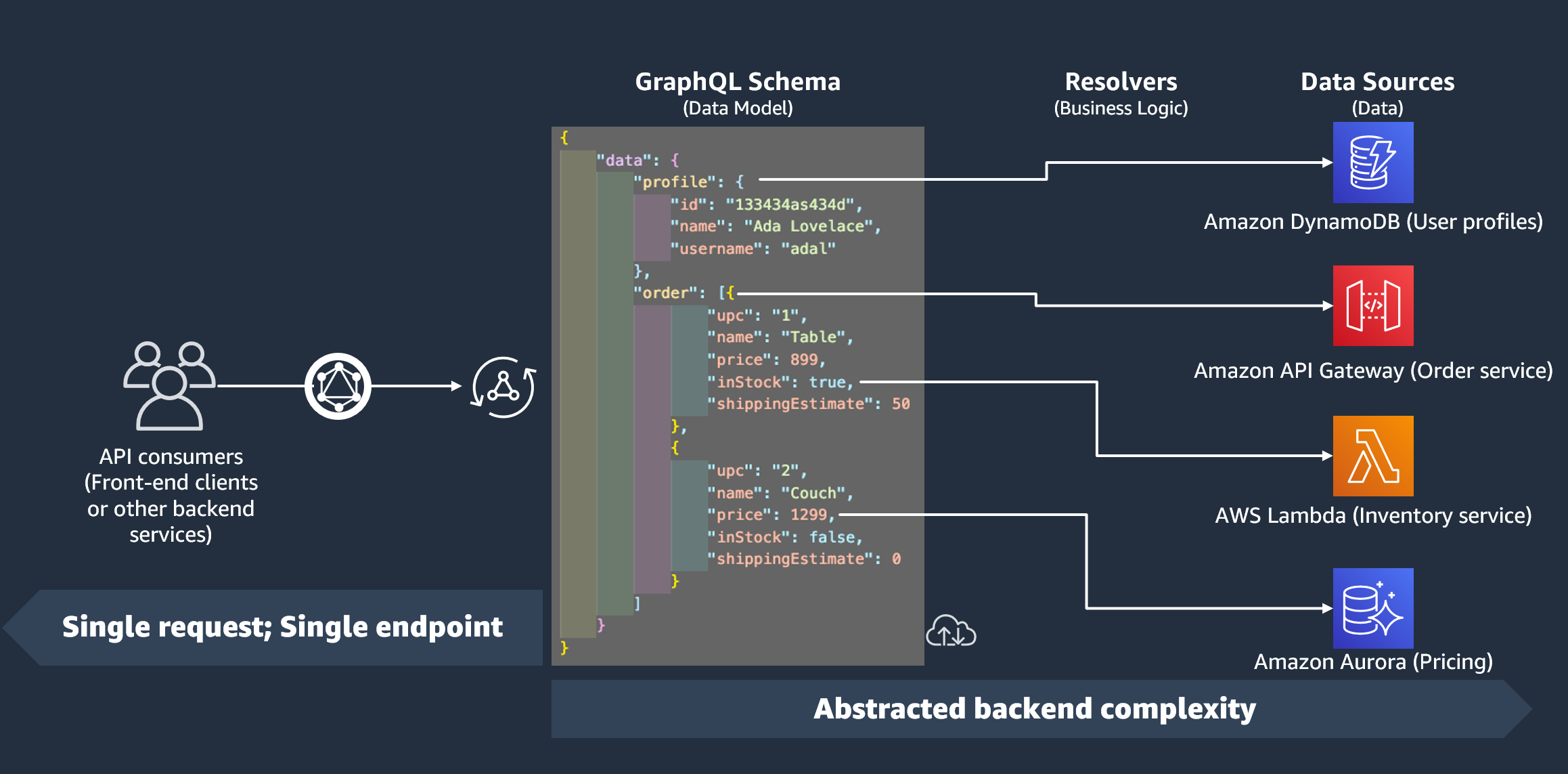
AWS AppSync y GraphQL implementan magníficamente las soluciones Backend For Frontend (BFF). Funcionan en grupo para reducir la complejidad a gran escala al abstraer el backend. Si su servicio utiliza orígenes de datos o microservicios diferentes, para abstraer de manera básica parte de la complejidad, puede definir la forma de los datos de cada origen (subgráfico) en un único esquema (supergráfico). Esto significa que su API de GraphQL no se limita a usar un origen de datos. Puede asociar cualquier número de orígenes de datos a su API de GraphQL y especificar en su código cómo van a interactuar con el servicio.
Como puede ver en la infografía, el esquema de GraphQL contiene toda la información que los clientes necesitan para solicitar datos. Esto significa que todo se puede procesar en una sola solicitud en lugar de en varias, como es el caso con REST. Estas solicitudes pasan por el esquema, que es el único punto de conexión del servicio. Cuando se procesan las solicitudes, un solucionador (elemento que se explica en la sección siguiente) ejecuta su código para procesar los datos del origen de datos correspondiente. Cuando se devuelva la respuesta, el subgráfico vinculado al origen de datos se rellenará con los datos del esquema.
AWS AppSync admite muchos tipos de fuentes de datos diferentes. En la siguiente tabla, describiremos cada tipo, enumeraremos algunas de las ventajas de cada uno y proporcionaremos enlaces útiles para obtener más contexto.
| Origen de datos | Description (Descripción) | Ventajas | Información complementaria |
|---|---|---|---|
| Amazon DynamoDB | “Amazon DynamoDB es un servicio de base de datos NoSQL totalmente administrado que ofrece un rendimiento rápido y predecible, así como una perfecta escalabilidad. DynamoDB le permite delegar las cargas administrativas que supone tener que utilizar y escalar bases de datos distribuidas, para que no tenga que preocuparse del aprovisionamiento, la instalación ni la configuración del hardware, ni tampoco de las tareas de replicación, aplicación de parches de software o escalado de clústeres. DynamoDB también ofrece el cifrado en reposo, que elimina la carga y la complejidad operativa que conlleva la protección de información confidencial.” |
|
|
| AWS Lambda | «AWS Lambda es un servicio informático que permite ejecutar código sin aprovisionar ni administrar servidores. Lambda ejecuta el código en una infraestructura de computación de alta disponibilidad y realiza todas las tareas de administración de los recursos de computación, incluido el mantenimiento del servidor y del sistema operativo, el aprovisionamiento de capacidad y el escalado automático, así como las funciones de registro. Con Lambda, lo único que tiene que hacer es suministrar el código en uno de los tiempos de ejecución de lenguaje compatibles con Lambda.” |
|
|
| OpenSearch | «Amazon OpenSearch Service es un servicio gestionado que facilita la implementación, el funcionamiento y el escalado de OpenSearch clústeres en la AWS nube. Amazon OpenSearch Service es compatible con OpenSearch Elasticsearch OSS heredado (hasta la 7.10, la versión final de código abierto del software). Al crear un clúster, tiene la opción de elegir qué motor de búsqueda utilizar. OpenSearches un motor de búsqueda y análisis totalmente de código abierto para casos de uso como el análisis de registros, la supervisión de aplicaciones en tiempo real y el análisis del flujo de clics. Para obtener más información, consulte la Documentación de OpenSearch Amazon OpenSearch Service aprovisiona todos los recursos OpenSearch del clúster y lo lanza. También detecta y reemplaza automáticamente los nodos de OpenSearch servicio defectuosos, lo que reduce la sobrecarga asociada a las infraestructuras autogestionadas. Puede escalar el clúster con una única llamada a la API o con algunos clics en la consola.” |
|
|
| Puntos de conexión HTTP | Puedes usar puntos finales HTTP como fuentes de datos. AWS AppSync puede enviar solicitudes a los puntos finales con la información relevante, como los parámetros y la carga útil. La respuesta HTTP estará expuesta al solucionador, que devolverá la respuesta final cuando finalice sus operaciones. |
|
|
| Amazon EventBridge | «EventBridge es un servicio sin servidor que utiliza eventos para conectar los componentes de la aplicación, lo que facilita la creación de aplicaciones escalables basadas en eventos. Úselo para redirigir eventos desde fuentes como aplicaciones propias, AWS servicios y software de terceros a aplicaciones de consumo de toda la organización. EventBridge proporciona una forma sencilla y coherente de incorporar, filtrar, transformar y distribuir eventos para que pueda crear nuevas aplicaciones rápidamente». |
|
|
| Bases de datos relacionales | «Amazon Relational Database Service (Amazon RDS) es un servicio web que facilita la configuración, el funcionamiento y el escalado de una base de datos relacional en la nube. AWS Proporciona una capacidad rentable y de tamaño ajustable para una base de datos relacional estándar y se ocupa de las tareas de administración de bases de datos comunes.” |
|
|
| Origen de datos none | Si no planea usar un servicio de origen de datos, puede configurarlo en none. Un origen de datos none, aunque se siga considerando explícitamente un origen de datos, no es un medio de almacenamiento. A pesar de ello, sigue siendo útil en algunos casos para la manipulación y transferencia de datos. |
|
sugerencia
Para obtener más información sobre cómo interactúan las fuentes de datos AWS AppSync, consulta Cómo adjuntar una fuente de datos.
