Conector para Neptune de Amazon Athena
Amazon Neptune es un servicio de base de datos de gráficos rápido, fiable y completamente administrado que le permite crear y ejecutar fácilmente aplicaciones que funcionen con conjuntos de datos altamente conectados. El motor de base de datos de gráficos de alto rendimiento diseñado específicamente de Neptune almacena de manera óptima miles de millones de relaciones y consulta gráficos con una latencia de milisegundos. Para obtener más información, consulte la Guía del usuario de Neptune.
El conector Amazon Athena Neptune permite a Athena comunicarse con la instancia de base de datos de gráficos de Neptune, lo que hace que sus datos de gráficos de Neptune sean accesibles mediante consultas SQL.
Si Lake Formation está habilitado en la cuenta, el rol de IAM del conector de Lambda federado de Athena que haya implementado en AWS Serverless Application Repository debe tener acceso de lectura en Lake Formation para AWS Glue Data Catalog.
Requisitos previos
El uso del conector de Neptune requiere los tres pasos siguientes.
-
Configuración de un clúster de Neptune
-
Configuración de un AWS Glue Data Catalog
-
Implementación del conector en su Cuenta de AWS. Para obtener más información, consulte Implementación de un conector de origen de datos o Uso de AWS Serverless Application Repository para implementar un conector de origen de datos. Para obtener más información específica sobre la implementación del conector de Neptune, consulte Implementación del conector de Neptune de Amazon Athena
en GitHub.com.
Limitaciones
Actualmente, el conector de Neptune tiene la siguiente limitación.
-
No se admite la proyección de columnas, ni siquiera la clave principal (ID).
Configuración de un clúster de Neptune
Si no tiene un clúster existente de Amazon Neptune y un conjunto de datos de gráficos de propiedades que le gustaría usar, debe configurar uno.
Asegúrese de tener una puerta de enlace de Internet y una puerta de enlace NAT en la VPC que aloja el clúster de Neptune. Las subredes privadas que utiliza la función de Lambda del conector de Neptune deben tener una ruta a Internet a través de esta puerta de enlace NAT. La función de Lambda del conector de Neptune utiliza la puerta de enlace NAT para comunicarse con AWS Glue.
Para obtener instrucciones sobre cómo configurar un nuevo clúster de Neptune y cargarlo con un conjunto de datos de ejemplo, consulte Configuración del clúster de Neptune de ejemplo
Configuración de un AWS Glue Data Catalog
A diferencia de los almacenes de datos relacionales tradicionales, los nodos y periferias de la base de datos de gráficos Neptune no utilizan ningún esquema establecido. Cada entrada puede tener diferentes campos y tipos de datos. Sin embargo, dado que el conector de Neptune recupera los metadatos de AWS Glue Data Catalog, debe crear una base de datos de AWS Glue que tenga tablas con el esquema requerido. Después de crear la base de datos y tablas de AWS Glue, el conector puede rellenar la lista de tablas disponibles para consultarla desde Athena.
Habilitación de la coincidencia de columnas sin distinción entre mayúsculas y minúsculas
Si desea resolver los nombres de las columnas de la tabla de Neptune con las mayúsculas y minúsculas correctas, incluso cuando todos los nombres de columnas aparezcan en minúsculas en AWS Glue, puede configurar el conector Neptune para que no distinga entre mayúsculas y minúsculas.
Para habilitar esta característica, establezca la variable de entorno enable_caseinsensitivematch como true en la función de Lambda del conector Neptune.
Especificación del parámetro de tabla glabel de AWS Glue para los nombres de las tablas en mayúsculas
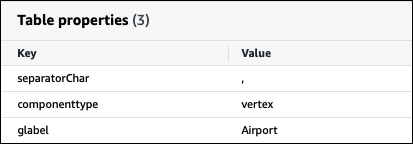
Dado que AWS Glue solo admite nombres de tablas en minúsculas, es importante especificar el parámetro de tabla glabel de AWS Glue si se crea una tabla de AWS Glue para Neptune y el nombre de la tabla de Neptune incluye mayúsculas.
En la definición de la tabla de AWS Glue, incluya el parámetro glabel y establezca su valor en el nombre de la tabla con las mayúsculas originales. Esto garantiza que se conserven las mayúsculas correctas cuando AWS Glue interactúe con la tabla de Neptune. En el siguiente ejemplo, se establece el valor de glabel como el nombre de la tabla Airport.
glabel = Airport
Para obtener más información sobre cómo configurar AWS Glue Data Catalog para utilizarlo con Neptune, consulte Configurar un catálogo de AWS Glue
Rendimiento
El conector Neptune de Athena inserta predicados para reducir los datos analizados en la consulta. Sin embargo, los predicados que usan la clave principal provocan un error en la consulta. Las cláusulas LIMIT reducen la cantidad de datos analizados; sin embargo, si no proporciona un predicado, es probable que las consultas SELECT con una cláusula LIMIT analicen al menos 16 MB de datos. El conector para Neptune resiste las limitaciones debidas a la simultaneidad.
Consultas de acceso directo
El conector de Neptune admite consultas de acceso directo. Puede utilizar esta característica para ejecutar consultas Gremlin en gráficos de propiedades y para ejecutar consultas SPARQL en datos RDF.
Para crear consultas de acceso directo con Neptune, puede utilizar la siguiente sintaxis:
SELECT * FROM TABLE( system.query( DATABASE => 'database_name', COLLECTION => 'collection_name', QUERY => 'query_string' ))
En el siguiente ejemplo, se filtra la consulta de acceso directo de Neptune para los aeropuertos con el código ATL. Las comillas simples dobles son para escapar.
SELECT * FROM TABLE( system.query( DATABASE => 'graph-database', COLLECTION => 'airport', QUERY => 'g.V().has(''airport'', ''code'', ''ATL'').valueMap()' ))
Recursos adicionales de
Para obtener más información acerca de este conector, consulte el sitio correspondiente
