Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cargando archivos por primera vez
Puede utilizar la función de AWS Supply Chain asociación automática para cargar sus datos sin procesar y asociarlos automáticamente con el modelo de AWS Supply Chain datos. También puede ver las columnas y tablas necesarias para cada AWS Supply Chain módulo en la aplicación AWS Supply Chain web.
Para ver una breve demostración de cómo funciona la asociación automática, vea el siguiente vídeo:
nota
Solo puede cargar CSV archivos en Amazon S3 cuando utilice la asociación automática.
Una vez que las columnas de origen de su conjunto de datos se asocien a las columnas de destino, AWS Supply Chain generará automáticamente la SQL receta.
nota
AWS Supply Chain utiliza Amazon Bedrock para la asociación automática, que no es compatible en todas las AWS regiones & en las que AWS Supply Chain está disponible. Por lo tanto, AWS Supply Chain llamará al punto de conexión Amazon Bedrock desde la región disponible más cercana, a la región de Europa (Irlanda), a Europa (Fráncfort), y a la región de Asia Pacífico (Sídney), a la región de EE. UU., oeste (Oregón).
nota
La asociación automática mediante modelos de lenguaje grandes (LLM) solo se admite cuando los datos se ingieren a través de Amazon S3.
-
En el AWS Supply Chain panel de control, en el panel de navegación izquierdo, elija Data Lake y, a continuación, elija la pestaña Ingestión de datos.
Aparece la página de ingesta de datos.
Seleccione Añadir nueva fuente.
Aparece la página Seleccione su fuente de datos.
En la página Seleccione su fuente de datos, elija Cargar archivos.
Elija Continuar.
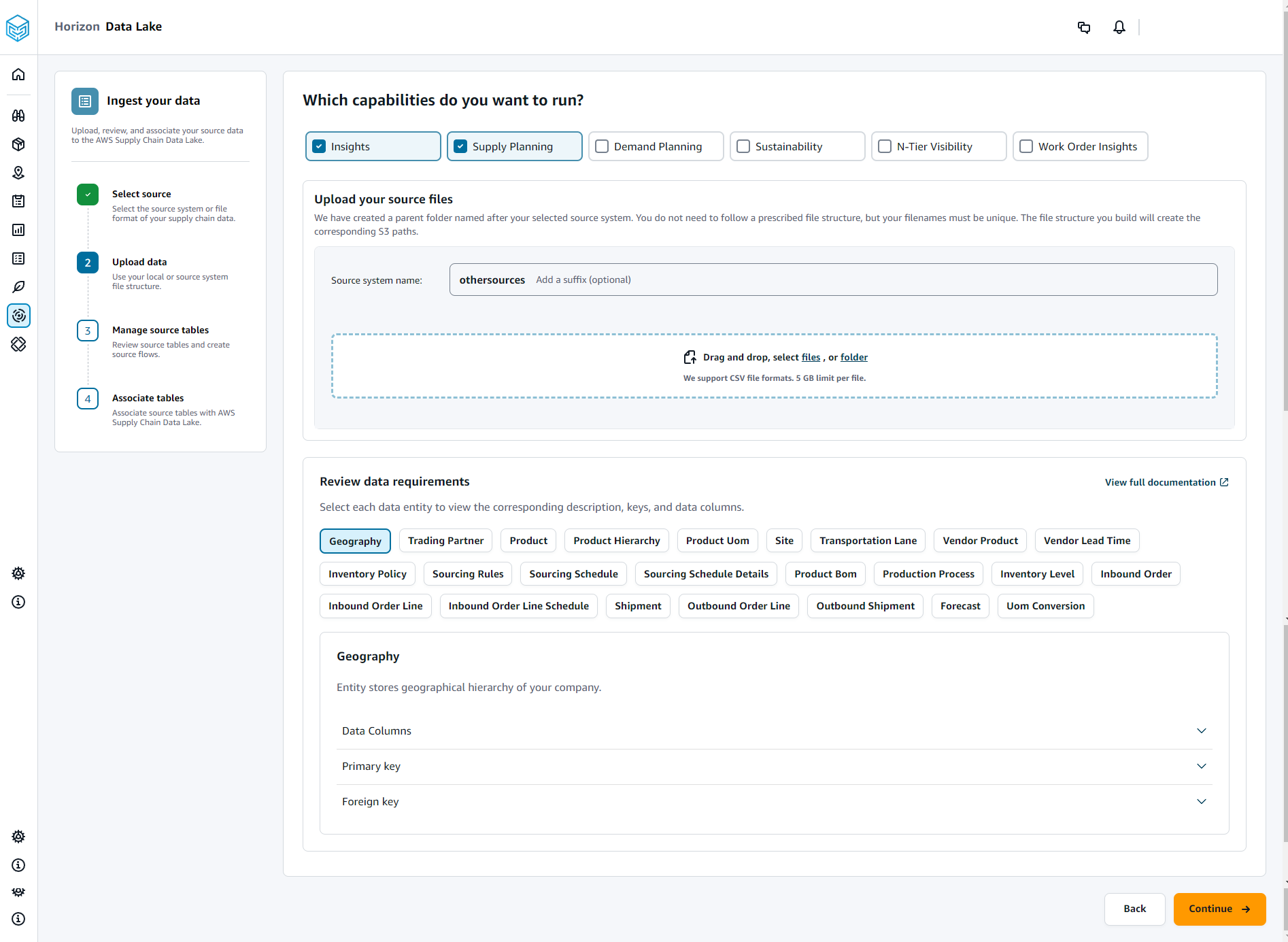
En la página Qué capacidades desea ejecutar, elija los AWS Supply Chain módulos que desee usar. Puede elegir más de un módulo.
En la sección Cargue los archivos fuente, añada un sufijo al nombre del sistema fuente. Por ejemplo, oracle_test.
Para cargar el conjunto de datos de origen, elija archivos o arrastre y suelte los archivos.
Se muestran las tablas de origen con el nombre y el estado.
Elija Cargar a S3. El estado de carga cambiará para mostrar el estado.
En Revisar los requisitos de datos, revisa todas las entidades y columnas de datos necesarias para la AWS Supply Chain función seleccionada. Se muestran todas las claves principales y externas requeridas.
Elija Continuar.
En Administre sus tablas de origen, las siguientes tablas de origen y las columnas de la lista se asociarán automáticamente y se importarán al lago de datos.
Elija Eliminar tabla para eliminar cualquiera de las tablas de origen antes de importarlas al lago de datos.
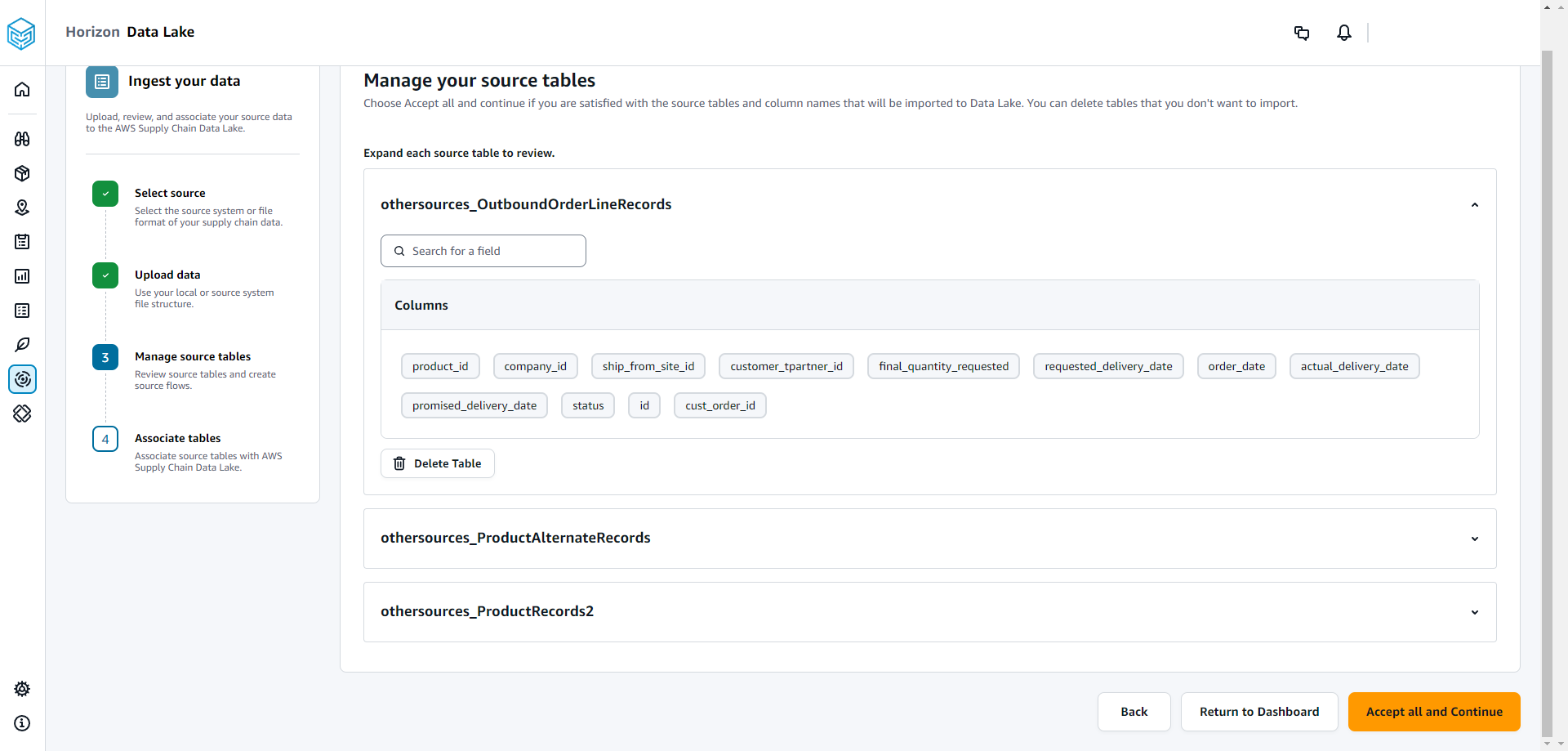
Selecciona Aceptar todo y continuar.
Aparece un mensaje sobre la asociación automática de las tablas al lago AWS Supply Chain de datos.
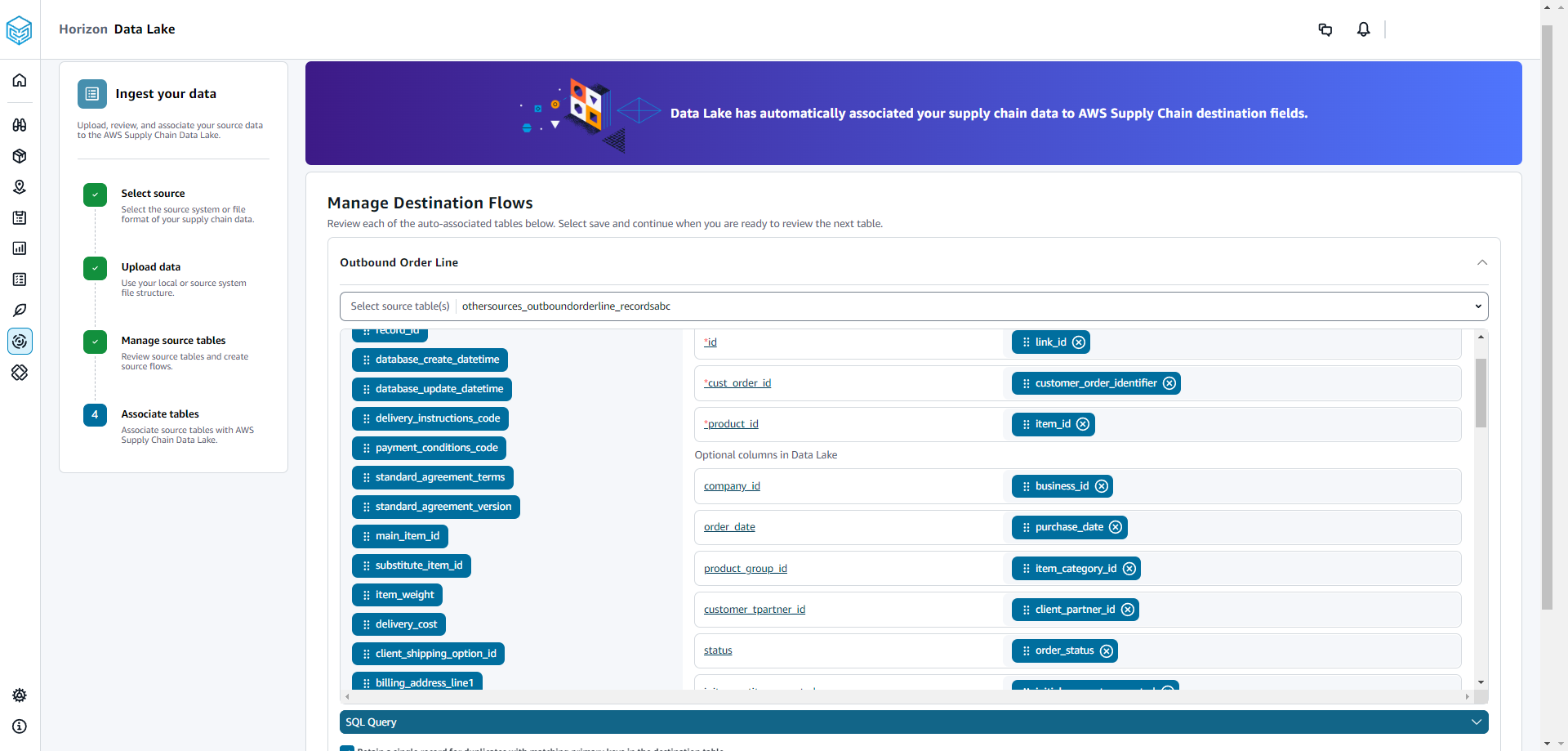
En Administrar flujos de destino, puede revisar cada tabla asociada automáticamente.
De forma predeterminada, la asociación automática está habilitada y las columnas de origen se asocian automáticamente a las columnas de destino. Para actualizar las columnas asociadas automáticamente, puedes actualizar la SQL receta para crear tu receta personalizada.
En Columnas de origen, se muestran todas las columnas de origen no asociadas. Arrastre y suelte las columnas no asociadas a las columnas de destino de la derecha.
Siga el paso anterior para cada tabla asociada automáticamente.
Elija Enviar.
Seleccione Salir y revisar los flujos de destino.
