Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Funcionamiento de Amazon DocumentDB
Amazon DocumentDB (compatible con MongoDB) es un servicio de base de datos totalmente gestionado. MongoDB-compatible Con Amazon DocumentDB, puede ejecutar el mismo código de aplicación y utilizar los mismos controladores y herramientas que utiliza con MongoDB. Amazon DocumentDB es compatible con MongoDB 3.6, 4.0, 5.0 y 8.0.
Temas
Versiones de Amazon DocumentDB
nota
La numeración de las versiones secundarias se aplica a Amazon DocumentDB 5.0 y versiones posteriores. Amazon DocumentDB 3.6 y 4.0 utilizan únicamente las versiones principales con parches de motor.
A partir de Amazon DocumentDB 5.0, la versión del motor utiliza un esquema de numeración de cuatro niveles: major.major.minor.patch.
-
Versión principal: se identifica con los dos primeros números de la versión (por ejemplo, 5.0). La versión principal representa el nivel de compatibilidad de MongoDB. Las versiones principales incluyen nuevas funciones, mejoras de rendimiento y actualizaciones de compatibilidad con MongoDB. La actualización entre las versiones principales (por ejemplo, de la 4.0 a la 5.0) requiere una actualización de la versión principal (MVU). Para obtener más información, consulte Actualización local de la versión principal Amazon DocumentDB.
-
Versión secundaria: se identifica con el tercer número de la versión (por ejemplo, el de la
1versión 5.0.1). Las versiones secundarias incluyen mejoras, como nuevas funciones, correcciones de seguridad y correcciones de errores en la misma versión principal. Puede actualizar manualmente a una nueva versión secundaria. Para obtener más información, consulte Actualización de la versión secundaria de Amazon DocumentDB. -
Versión de parche: los parches del motor se aplican dentro de una versión secundaria y contienen correcciones de errores y correcciones de seguridad críticas. La versión del parche se rastrea mediante la versión del parche del motor (por ejemplo,
3.0.17983), que puede comprobardb.runCommand({getEngineVersion: 1})ejecutándola. Los parches se aplican durante el período de mantenimiento del clúster. Para obtener más información, consulte Mantenimiento de Amazon DocumentDB.
Al crear un clúster nuevo, puede especificar cualquier versión de motor disponible. Para obtener información sobre las versiones disponibles y las fechas de soporte, consulteFechas de soporte de la versión del motor de Amazon DocumentDB.
Cuando utilice Amazon DocumentDB, empezará creando un clúster. Un clúster se compone de cero o varias instancias y de un volumen de clúster que administra los datos de esas instancias. Un volumen de clúster de Amazon DocumentDB es un volumen de almacenamiento de base de datos virtual que abarca varias zonas de disponibilidad. Cada zona de disponibilidad tiene una copia de los datos del clúster.
Los clústeres de Amazon DocumentDB constan de dos componentes principales:
-
Volumen de clúster: utiliza un servicio de almacenamiento nativo en la nube para replicar los datos de seis maneras en tres zonas de disponibilidad, lo que proporciona un almacenamiento disponible y duradero. Un clúster de Amazon DocumentDB tiene exactamente un volumen de clúster, que puede almacenar hasta 128 TiB de datos.
-
Instancias: proporcionan la potencia de procesamiento de la base de datos al escribir y leer datos desde el volumen de almacenamiento del clúster. Un clúster de Amazon DocumentDB puede tener de 0 a 16 instancias.
Las instancias adoptan uno de estos dos roles:
-
Instancia de base de datos principal: admite operaciones de lectura y escritura y realiza todas las modificaciones de los datos en el volumen de clúster. Cada clúster de Amazon DocumentDB tiene una instancia principal.
-
Instancia de réplica: solo admite operaciones de lectura. Un clúster de Amazon DocumentDB puede tener hasta 15 réplicas, además de la instancia principal. El hecho de disponer de varias réplicas le permite distribuir las cargas de trabajo de lectura. Además, al colocar las réplicas en distintas zonas de disponibilidad, también puede aumentar la disponibilidad del clúster.
En el siguiente diagrama se ilustra la relación entre el volumen de clúster, la instancia principal y las réplicas de un clúster de Amazon DocumentDB:
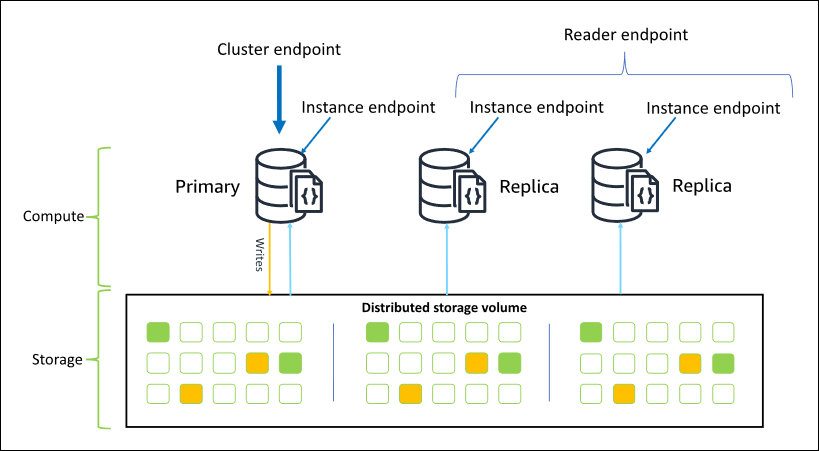
Las instancias del clúster no tienen por qué ser de la misma clase, y se pueden aprovisionar y terminar según sea necesario. Esta arquitectura le permite escalar la capacidad de cómputo de su clúster de forma independiente de su almacenamiento.
Cuando la aplicación escribe datos en la instancia principal, la instancia principal ejecuta una operación de escritura duradera en el volumen del clúster. A continuación, replica el estado de esa escritura (no los datos) en cada réplica activa. Las réplicas de Amazon DocumentDB no participan en el procesamiento de escrituras y, por lo tanto, las réplicas de Amazon DocumentDB son ventajosas para el escalado de lectura. Las lecturas de réplicas de Amazon DocumentDB son, en última instancia, consistentes con un retardo de réplica mínimo, normalmente menos de 100 milisegundos una vez que la instancia principal escribe los datos. Se garantiza que las operaciones de lectura de las réplicas se realizan en el orden en que fueron escritas en la instancia principal. El retardo de la réplica varía en función de la frecuencia de cambio de datos, y los periodos con mucha actividad de escritura pueden aumentar el retardo de la réplica. Para obtener más información, consulte las métricas ReplicationLag en Métricas de Amazon DocumentDB.
Puntos de conexión de Amazon DocumentDB
Amazon DocumentDB ofrece varias opciones de conexión para proporcionar una amplia variedad de casos de uso. Para conectarse a una instancia de un clúster de Amazon DocumentDB, debe especificar el punto de conexión de la instancia. Un punto de conexión es una dirección y un número de puerto de host, separados por dos puntos.
Le recomendamos que se conecte al clúster mediante el punto de conexión de clúster y en el modo de conjunto de réplicas (consulte Conexión a Amazon DocumentDB como conjunto de réplicas), a no ser que tenga un caso de uso específico para conectarse al punto de conexión del lector o a un punto de conexión de instancia. Para dirigir solicitudes a las réplicas, elija una configuración de preferencia de lectura de controlador que maximice el escalado de lectura mientras cumple con los requisitos de coherencia de lectura de su aplicación. Las preferencias de lectura secondaryPreferred permiten las lecturas de réplica y libera la instancia principal para hacer más trabajo.
Los siguientes puntos de conexión están disponibles en un clúster de Amazon DocumentDB.
Punto de conexión de clúster
El punto de conexión del clúster le conecta a la instancia principal del clúster. El punto de conexión del clúster se puede utilizar para operaciones de lectura y escritura. Un clúster de Amazon DocumentDB tiene exactamente un punto de conexión de clúster.
El punto de conexión del clúster proporciona conmutación por error para conexiones de lectura y escritura con el clúster. Si la instancia principal actual del clúster produce un error y el clúster tiene al menos una réplica de lectura activa, el punto de conexión del clúster redirige automáticamente las solicitudes de conexión a una nueva instancia principal. Cuando se conecte al clúster de Amazon DocumentDB, le recomendamos que se conecte al clúster mediante el punto de conexión de clúster y en el modo de conjunto de réplicas (consulte Conexión a Amazon DocumentDB como conjunto de réplicas).
A continuación, se muestra un punto de conexión de un clúster de Amazon DocumentDB de ejemplo:
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
A continuación, se muestra una cadena de conexión de ejemplo que usa este punto de conexión de clúster:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Para obtener información acerca de cómo encontrar los puntos de conexión de un clúster, consulte Búsqueda de puntos de conexión de un clúster.
Punto de conexión del lector
El punto de conexión del lector balancea la carga de las conexiones de solo lectura entre todas las réplicas disponibles del clúster. Un punto de conexión de lector de clúster funcionará como punto de conexión del clúster si se conecta a través del modo replicaSet, es decir, en la cadena de conexión, el parámetro del conjunto de réplicas es &replicaSet=rs0. En este caso, podrá llevar a cabo operaciones de escritura en el principal. Sin embargo, si se conecta al clúster que especifica directConnection=true y se intenta llevar a cabo una operación de escritura a través de una conexión con el punto de conexión de lector, se produce un error. Un clúster de Amazon DocumentDB tiene exactamente un punto de conexión de lector.
Si el clúster contiene solo una instancia principal, el punto de conexión del lector se conecta a la instancia principal. Cuando se añade una instancia de réplica al clúster de Amazon DocumentDB, el punto de conexión del lector abre las conexiones de solo lectura con la nueva réplica una vez que esté activo.
A continuación, se muestra un punto de conexión del lector de ejemplo de un clúster de Amazon DocumentDB:
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
A continuación, se muestra una cadena de conexión de ejemplo que usa un punto de conexión de lector:
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
El punto de conexión del lector balancea la carga de las conexiones de solo lectura, no de las solicitudes de lectura. Si algunas de las conexiones del punto de conexión del lector se utilizan más que otras, es posible que las solicitudes de lectura no se puedan equilibrar uniformemente entre las instancias del clúster. Se recomienda distribuir solicitudes mediante la conexión al punto de conexión de clúster como un conjunto de réplicas y mediante la opción de preferencia de lectura secondaryPreferred.
Para obtener información acerca de cómo encontrar los puntos de conexión de un clúster, consulte Búsqueda de puntos de conexión de un clúster.
Punto de conexión de instancia
Un punto de conexión de una instancia se conecta a una instancia específica del clúster. El punto de conexión de instancia de la instancia principal actual se puede utilizar para realizar operaciones de lectura y escritura. Sin embargo, si se intentan realizar operaciones de escritura en un punto de conexión de instancia de una réplica de lectura, se produce un error. Un clúster de Amazon DocumentDB tiene un punto de conexión de instancia para cada instancia activa.
Un punto de conexión de instancia proporciona un control directo sobre las conexiones con una instancia específica en los casos en los que el uso del punto de conexión del clúster o del lector puede no ser adecuado. Un ejemplo de caso de uso es el aprovisionamiento de una carga de trabajo de análisis diarios de solo lectura. Puede aprovisionar una instancia de réplica mayor de lo normal, conectarse directamente a la nueva instancia más grande con su punto de conexión de instancia, ejecutar las consultas de análisis y después terminar la instancia. El uso del punto de conexión de instancia impide que el tráfico de los análisis afecte a otras instancias del clúster.
A continuación, se muestra un punto de conexión de instancia de ejemplo para una sola instancia de un clúster de Amazon DocumentDB:
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
A continuación, se muestra una cadena de conexión de ejemplo que usa este punto de conexión de instancia:
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
nota
El rol de instancia principal o réplica de una instancia puede cambiar debido a un evento de conmutación por error. Las aplicaciones no deben presuponer en ningún momento que un determinado punto de conexión de instancia es la instancia principal. No se recomienda conectarse a puntos de conexión de instancia para aplicaciones de producción. En su lugar, se recomienda que se conecte al clúster mediante el punto de conexión de clúster y en el modo de conjunto de réplicas (consulte Conexión a Amazon DocumentDB como conjunto de réplicas). Para obtener información sobre el control avanzado de la prioridad de conmutación por error de las instancias, consulte Información general de la tolerancia a errores de clúster de Amazon DocumentDB.
Para obtener información acerca de cómo encontrar los puntos de conexión de un clúster, consulte Búsqueda del punto de conexión de una instancia.
Modo de conjunto de réplicas
Puede conectarse al punto de conexión de su clúster de Amazon DocumentDB en modo de conjunto de réplicas especificando el nombre del conjunto de réplicas rs0. La conexión en el modo de conjunto de réplicas proporciona la capacidad de especificar las opciones Read Concern, Write Concern y Read Preference. Para obtener más información, consulte Coherencia de lectura.
A continuación, se muestra una cadena de conexión de ejemplo que se conecta en el modo de conjunto de réplicas:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
Cuando se conecta en modo de conjunto de réplicas, el clúster de Amazon DocumentDB se muestra ante los controladores y clientes como un conjunto de réplicas. Las instancias añadidas y eliminadas del clúster de Amazon DocumentDB se reflejan automáticamente en la configuración del conjunto de réplicas.
Cada clúster de Amazon DocumentDB consta de un único conjunto de réplicas con el nombre predeterminado rs0. El nombre del conjunto de réplicas no se puede modificar.
La conexión al punto de conexión del clúster en el modo de conjunto de réplicas es el método recomendado para uso general.
nota
Todas las instancias de un clúster de Amazon DocumentDB atienden las conexiones en el mismo puerto TCP.
Compatibilidad con TLS
Para obtener más información sobre cómo conectarse a Amazon DocumentDB mediante seguridad de la capa de transporte (TLS), consulte Cifrado de datos en tránsito.
Almacenamiento de Amazon DocumentDB
Los datos de Amazon DocumentDB se almacenan en el volumen del clúster, que es un volumen único y virtual que usa unidades de estado sólido (SSD). Un volumen de clúster se compone de seis copias de los datos, que se replican automáticamente en varias zonas de disponibilidad de una sola Región de AWS. Esta replicación ayuda a garantizar que los datos se conserven durante mucho tiempo, con menos riesgo de que se pierdan los datos. También ayuda a garantizar que el clúster esté más disponible durante una conmutación por error, porque ya existen copias de sus datos en otras zonas de disponibilidad. Estas copias pueden seguir enviando solicitudes de datos a las instancias del clúster de Amazon DocumentDB.
Cómo se factura el almacenamiento de datos de
Amazon DocumentDB aumenta automáticamente el tamaño del volumen del clúster cuando aumenta la cantidad de datos. Un volumen de clúster de Amazon DocumentDB puede crecer hasta un tamaño máximo de 128 TiB; sin embargo, solo se le cobrará por el espacio que utilice en un volumen de clúster de Amazon DocumentDB. A partir de Amazon DocumentDB 4.0, cuando se eliminan datos, por ejemplo, al eliminar una colección o un índice, el espacio asignado general disminuye en una cantidad comparable. Por lo tanto, puede reducir los cargos de almacenamiento eliminando tablas, índices y bases de datos que ya no necesite. En la versión 3.6 de Amazon DocumentDB, el volumen del clúster puede reutilizar el espacio liberado al eliminar datos, pero el volumen en sí nunca disminuye de tamaño. Como resultado, en la versión 3.6, es posible que no vea ningún cambio en el almacenamiento cuando elimine una colección o un índice, aunque el espacio liberado se vuelva a utilizar.
nota
Con Amazon DocumentDB 3.6, los costos de almacenamiento se basan en el “límite máximo” de almacenamiento (la cantidad máxima que se asignó al clúster de Amazon DocumentDB en cualquier momento). Puede administrar los costos evitando las prácticas de ETL que crean grandes volúmenes de información temporal o que cargan grandes volúmenes de datos nuevos antes de eliminar datos antiguos innecesarios. Si la eliminación de datos de un clúster de Amazon DocumentDB produce una cantidad sustancial de espacio asignado pero que no se utiliza, el restablecimiento del nivel máximo de crecimiento exige realizar el volcado de datos lógicos y restablecerlo a un clúster nuevo, con una herramienta como mongodump o mongorestore. La creación y restauración de una instantánea no reduce el almacenamiento asignado debido a que la distribución física del almacenamiento subyacente no se verá modificada en la instantánea restaurada.
nota
El uso de mongodump utilidades mongorestore como esta I/O conlleva cargos en función del tamaño de los datos que se leen y escriben en el volumen de almacenamiento.
Para obtener información sobre el almacenamiento de datos y los precios de Amazon DocumentDB, consulte I/O los precios de Amazon DocumentDB (compatible con MongoDB
Replicación de Amazon DocumentDB
En un clúster de Amazon DocumentDB, cada instancia de réplica expone un punto de conexión independiente. Los puntos de conexión de estas réplicas proporcionan acceso de solo lectura a los datos del volumen de clúster. Le permiten escalar la carga de trabajo de lectura de los datos entre varias instancias replicadas. También ayudan a mejorar el rendimiento de las lecturas de datos y a aumentar la disponibilidad de los datos en el clúster de Amazon DocumentDB. Las réplicas de Amazon DocumentDB también son objetivos de conmutación por error y se promocionan rápidamente si se produce un error en la instancia principal del clúster de Amazon DocumentDB.
Fiabilidad de Amazon DocumentDB
Amazon DocumentDB está diseñado para ofrecer fiabilidad, durabilidad y tolerancia a errores. (Para mejorar la disponibilidad, debe configurar el clúster de Amazon DocumentDB de modo que tenga varias instancias de réplica en distintas zonas de disponibilidad). Amazon DocumentDB también incluye varias características automáticas que la convierten en una solución de base de datos de confianza.
Reparación automática del almacenamiento
Amazon DocumentDB mantiene varias copias de los datos en tres zonas de disponibilidad, lo que reduce considerablemente la posibilidad de pérdida de datos debido a un error de almacenamiento. Amazon DocumentDB también detecta automáticamente los errores del volumen de clúster. Cuando se produce un error en un segmento de un volumen del clúster, Amazon DocumentDB lo repara inmediatamente. Utiliza los datos de los demás volúmenes que conforman el volumen del clúster para ayudar a garantizar que los datos del segmento reparado estén actualizados. Por consiguiente, Amazon DocumentDB evita la pérdida de datos y reduce la necesidad de realizar una restauración a un momento dado para recuperarse del error de una instancia.
Calentamiento de caché que puede sobrevivir
Amazon DocumentDB administra su caché de páginas en un proceso independiente de la base de datos para que pueda sobrevivir independientemente de la base de datos. En el improbable caso de que se produzca un error de la base de datos, la caché de páginas permanece en la memoria. De este modo, se garantiza que el grupo del búfer contiene datos con el estado más actualizado al reiniciar la base de datos.
Recuperación de bloqueos
Amazon DocumentDB se ha diseñado para recuperarse de un bloqueo casi instantáneamente y continuar sirviendo sus datos de aplicación sin el registro binario. Amazon DocumentDB realiza las recuperaciones de bloqueos de forma asíncrona en subprocesos paralelos, de forma que su base de datos permanece abierta y disponible inmediatamente después de un bloqueo.
Administración de recursos
Amazon DocumentDB protege los recursos necesarios para ejecutar los procesos críticos del servicio, como las comprobaciones de estado. Para ello, y cuando una instancia experimente una presión de memoria elevada, Amazon DocumentDB limitará las solicitudes. Como resultado, es posible que algunas operaciones se pongan en cola para esperar a que disminuya la presión sobre la memoria. Si la presión de la memoria continúa, es posible que se agote el tiempo de espera de las operaciones en cola. Puede controlar si el servicio limita o no sus operaciones debido a la falta de memoria con las siguientes CloudWatch métricas:,,,. LowMemThrottleQueueDepth LowMemThrottleMaxQueueDepth LowMemNumOperationsThrottled LowMemNumOperationsTimedOut Para obtener más información, consulte Supervisión de Amazon DocumentDB con. CloudWatch Si observa una presión de memoria constante en su instancia como resultado de las LowMem CloudWatch métricas, le recomendamos que amplíe la instancia para proporcionar memoria adicional para su carga de trabajo.
Opciones de preferencia de lectura
Amazon DocumentDB utiliza un servicio de almacenamiento compartido nativo en la nube que replica los datos seis veces en tres zonas de disponibilidad para ofrecer altos niveles de durabilidad. Amazon DocumentDB no se basa en la replicación de datos en varias instancias para lograr durabilidad. Los datos del clúster serán duraderos tanto si este contiene una sola instancia como si tiene 15.
Temas
Durabilidad de escritura
Amazon DocumentDB utiliza un sistema de almacenamiento único, distribuido, tolerante a errores y de recuperación automática. Este sistema replica seis copias (V=6) de sus datos en tres zonas de disponibilidad para ofrecer una AWS alta disponibilidad y durabilidad. Al escribir datos, Amazon DocumentDB garantiza que todas las escrituras se registren de forma duradera en la gran mayoría de los nodos antes de confirmar la escritura al cliente. Si ejecuta un conjunto de réplicas de MongoDB de tres nodos y utiliza la opción Write Concern de {w:3, j:true}, obtendría la mejor configuración posible en comparación con Amazon DocumentDB.
Las operaciones de escritura en el clúster de Amazon DocumentDB debe procesarlas la instancia principal del clúster. Si se intenta escribir a una réplica, se producirá un error. Una operación de escritura confirmada desde una instancia principal de Amazon DocumentDB es duradera y no se puede revertir. Amazon DocumentDB es muy duradero de forma predeterminada y no admite una opción de escritura no duradera. No se puede modificar el nivel de durabilidad (es decir, Write Concern). Amazon DocumentDB ignora w=anything y, de hecho, es w: 3 y j: true. No puede reducirlo.
Debido a que en la arquitectura de Amazon DocumentDB la computación y el almacenamiento están separados, un clúster con una sola instancia es de larga duración. La durabilidad se gestiona en la capa de almacenamiento. Como resultado, un clúster de Amazon DocumentDB con una sola instancia y uno con tres instancias consiguen el mismo nivel de durabilidad. Puede configurar el clúster para que se adapte a su caso de uso específico a la vez que proporciona un alto nivel de durabilidad para sus datos.
Las operaciones de escritura en un clúster de Amazon DocumentDB son atómicas dentro del mismo documento.
Amazon DocumentDB no admite la opción wtimeout y no devolverá un error si se especifica un valor. Las operaciones de escritura en la instancia principal de Amazon DocumentDB están aseguradas contra el bloqueo indefinido.
Aislamiento de lectura
Las operaciones de lectura de una instancia de Amazon DocumentDB solo devuelven datos que se conservan antes de que se inicie la consulta. Las operaciones de lectura nunca devuelven datos modificados una vez que se inicia la ejecución de la consulta, y las lecturas sucias no son posibles en ninguna circunstancia.
Coherencia de lectura
Los datos leídos de un clúster de Amazon DocumentDB son duraderos y no se pueden revertir. Puede modificar la lectura consistente para las operaciones de lectura de Amazon DocumentDB especificando la preferencia de lectura de la solicitud o conexión. Amazon DocumentDB no admite una opción de lectura no duradera.
Las lecturas desde una instancia principal del clúster de Amazon DocumentDB tienen una consistencia alta en condiciones funcionamiento normales y tienen consistencia de lectura tras la escritura. Si se produce un evento de conmutación por error entre la escritura y la lectura posterior, el sistema puede devolver brevemente una lectura que no tiene una consistencia alta. Todas las lecturas que se realizan desde una réplica de lectura tienen consistencia final y devuelven los datos en el mismo orden, a menudo con un retardo de réplica inferior a los 100 ms.
Preferencias de lectura de Amazon DocumentDB
Amazon DocumentDB permite configurar una opción de preferencia de lectura únicamente cuando los datos se leen del punto de conexión del clúster en modo de conjunto de réplicas. La configuración de una opción de preferencia de lectura afecta al modo en que el cliente o el controlador de MongoDB lee las solicitudes enviadas a las instancias del clúster de Amazon DocumentDB. Puede definir opciones de preferencia de lectura para una consulta específica o como una opción general en el controlador de MongoDB. (Consulte la documentación del cliente o controlador para obtener instrucciones sobre cómo definir una opción de preferencia de lectura).
Si el cliente o controlador no se conecta a un punto de conexión del clúster de Amazon DocumentDB en modo de conjunto de réplicas, el resultado de especificar una preferencia de lectura es incierto.
Amazon DocumentDB no admite la configuración de conjuntos de etiquetas como preferencia de lectura.
Opciones de preferencia de lectura admitidas
-
primary. especificar una preferencia deprimarylectura ayuda a garantizar que todas las lecturas se dirijan a la instancia principal del clúster. Si la instancia principal no está disponible, se produce un error en la operación de lectura. Una preferencia de lecturaprimaryproporciona coherencia de lectura tras escritura y es adecuada para aquellos casos de uso en los que la coherencia de lectura tras escritura tiene prioridad sobre la alta disponibilidad y el escalado de lectura.En el siguiente ejemplo se especifica una preferencia de lectura
primary:db.example.find().readPref('primary') -
primaryPreferred: si se especifica una preferencia deprimaryPreferredlectura, las lecturas se redirigen a la instancia principal en condiciones normales de funcionamiento. Si se produce una conmutación por error de la instancia principal, el cliente envía las solicitudes a una réplica. Una preferencia de lecturaprimaryPreferredproporciona coherencia de lectura tras escritura en condiciones normales y una lectura consistente final durante un evento de conmutación por error. Una preferencia de lecturaprimaryPreferredes adecuada en aquellos casos de uso en los que la coherencia de lectura tras escritura tiene prioridad sobre el escalado de lectura, pero aún se requiere una alta disponibilidad.En el siguiente ejemplo se especifica una preferencia de lectura
primaryPreferred:db.example.find().readPref('primaryPreferred') -
secondary: la especificación de una preferencia desecondarylectura garantiza que las lecturas solo se enruten a una réplica, nunca a la instancia principal. Si no hay instancias de réplica en el clúster, la solicitud de lectura produce un error. Una preferencia de lecturasecondaryproporciona lecturas consistentes finales y es adecuada en aquellos casos de uso en los que el rendimiento de escritura de la instancia principal tiene prioridad sobre la alta disponibilidad y la coherencia de lectura tras escritura.En el siguiente ejemplo se especifica una preferencia de lectura
secondary:db.example.find().readPref('secondary') -
secondaryPreferred: la especificación de una preferencia desecondaryPreferredlectura garantiza que las lecturas se enruten a una réplica de lectura cuando hay una o más réplicas activas. Si no hay instancias de réplica activas en el clúster, la solicitud de lectura se envía a la instancia principal. Una preferencia de lecturasecondaryPreferredproporciona operaciones de lectura consistente final cuando una réplica de lectura atiende la operación de lectura. Presenta lectura consistente tras escritura cuando es la instancia principal la que atiende la solicitud de lectura (salvo en los casos de conmutación por error). Una preferencia de lecturasecondaryPreferredes adecuada para aquellos casos de uso en los que el escalado de lectura y la alta disponibilidad tienen prioridad sobre la coherencia de lectura tras escritura.En el siguiente ejemplo se especifica una preferencia de lectura
secondaryPreferred:db.example.find().readPref('secondaryPreferred') -
nearest: al especificar una preferencia denearestlectura, las lecturas se distribuyen únicamente en función de la latencia medida entre el cliente y todas las instancias del clúster de Amazon DocumentDB. Una preferencia de lecturanearestproporciona operaciones de lectura consistente final cuando una réplica de lectura atiende la operación de lectura. Presenta lectura consistente tras escritura cuando es la instancia principal la que atiende la solicitud de lectura (salvo en los casos de conmutación por error). Una preferencia de lecturanearestes adecuada en aquellos casos de uso en los que conseguir la menor latencia de lectura posible y una alta disponibilidad tienen prioridad sobre la coherencia de lectura tras escritura y el escalado de lectura.En el siguiente ejemplo se especifica una preferencia de lectura
nearest:db.example.find().readPref('nearest')
Alta disponibilidad
Amazon DocumentDB admite configuraciones de clúster altamente disponibles mediante el uso de réplicas como destinos de la conmutación por error de la instancia principal. Si la instancia principal produce un error, una réplica de Amazon DocumentDB pasará a ser la nueva instancia principal, con una breve interrupción durante la cual las solicitudes de lectura y escritura realizadas a la instancia principal producen una excepción.
Si el clúster de Amazon DocumentDB no contiene réplicas, se vuelve a crear la instancia principal cuando se produce un error. Sin embargo, promover una réplica de Amazon DocumentDB es mucho más rápido que volver a crear la instancia principal. Por lo tanto, le recomendamos que cree una o varias réplicas de Amazon DocumentDB como destinos de conmutación por error.
Las réplicas que se han diseñado para utilizarlas como destinos de conmutación por error deben ser de la misma clase de instancia que la instancia principal. Deberían aprovisionarse en zonas de disponibilidad distintas de la principal. Puede controlar las réplicas que deben usarse como destinos de la conmutación por error. Para obtener instrucciones sobre cómo configurar Amazon DocumentDB para una alta disponibilidad, consulte Información general de la tolerancia a errores de clúster de Amazon DocumentDB.
Escalado de operaciones de lectura
Las réplicas de Amazon DocumentDB son ideales para el escalado de lectura. Están totalmente dedicadas a las operaciones de lectura en el volumen del clúster, es decir, las réplicas no procesan operaciones de escritura. La replicación de datos se produce en el volumen del clúster y no entre las instancias. Por lo tanto, los recursos de cada réplica se dedican a procesar las consultas, y no a replicar y escribir datos.
Si su aplicación necesita más capacidad de lectura, puede añadir una réplica al clúster rápidamente (normalmente en menos de 10 minutos). Si los requisitos de capacidad de lectura disminuyen, puede eliminar las réplicas que no necesite. Con las réplicas de Amazon DocumentDB, solo paga por la capacidad de lectura que necesite.
Amazon DocumentDB permite el escalado de lectura en el cliente mediante el uso de opciones de preferencia de lectura. Para obtener más información, consulte Preferencias de lectura de Amazon DocumentDB.
Eliminaciones de TTL
Las eliminaciones de un área de índice TTL logradas a través de un proceso en segundo plano son el mejor esfuerzo y no están garantizadas dentro de un período de tiempo específico. Factores como el tamaño de instancia, la utilización de recursos de instancia, el tamaño del documento y el rendimiento general pueden afectar la temporización de una eliminación de TTL.
Cuando el monitor TTL elimina sus documentos, cada eliminación incurre en costos de E/S, lo que aumentará su factura. Si el rendimiento y las tasas de eliminación de TTL aumentan, debería esperar un aumento en su factura debido al aumento del uso de E/S.
Al crear un índice TTL en una colección existente, debe eliminar todos los documentos caducados antes de crear el índice. La implementación actual del TTL está optimizada para eliminar una pequeña fracción de los documentos de la colección, lo que suele ocurrir si el TTL estaba activado en la colección desde el principio, y puede resultar en un aumento de las IOPS de lo necesario si es necesario eliminar un gran número de documentos de una sola vez.
En lugar de utilizar un índice TTL para eliminar documentos, puede segmentar documentos en colecciones según el tiempo y simplemente eliminar esas colecciones cuando los documentos ya no sean necesarios. Por ejemplo: puede crear una colección por semana y eliminarla sin incurrir en costos de E/S. Esto puede resultar considerablemente más rentable que utilizar un índice TTL.
Recursos facturables
Identificación de los recursos facturables de Amazon DocumentDB
Como servicio de base de datos totalmente gestionado, Amazon DocumentDB cobra por las instancias, el almacenamiento I/Os, las copias de seguridad y la transferencia de datos. Para obtener más información, consulte Amazon DocumentDB (with MongoDB compatibility) Pricing
Para descubrir los recursos facturables de su cuenta y, si es posible, eliminarlos, puede utilizar la Consola de administración de AWS opción o. AWS CLI
Uso de Consola de administración de AWS
Con el Consola de administración de AWS, puede descubrir los clústeres, instancias e instantáneas de Amazon DocumentDB que ha aprovisionado para un determinado número. Región de AWS
Para detectar clústeres, instancias e instantáneas
Inicie sesión en y abra la Consola de administración de AWS consola de Amazon DocumentDB en. https://console.aws.amazon.com/docdb
-
Para descubrir los recursos facturables en una región que no sea la región predeterminada, en la esquina superior derecha de la pantalla, elija la Región de AWS que desee buscar.
-
En el panel de navegación, seleccione el tipo de recurso facturable que le interesa: Clusters (Clústeres), Instances (Instancias) o Snapshots (Instantáneas).
-
Todos los clústeres, instancias o instantáneas aprovisionados para la región se indican en el panel de la derecha. Se le cobrará por los clústeres, las instancias y las instantáneas.
Uso de AWS CLI
Con el AWS CLI, puede descubrir los clústeres, instancias e instantáneas de Amazon DocumentDB que ha aprovisionado para un determinado número. Región de AWS
Para detectar clústeres e instancias
El código siguiente muestra todos los clústeres e instancias para la región especificada. Si desea buscar clústeres e instancias en la región predeterminada, puede omitir el parámetro --region.
ejemplo
Para Linux, macOS o Unix:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Para Windows:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
La salida de esta operación será similar a lo que se indica a continuación.
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",Para detectar instantáneas
El código siguiente muestra todas las instantáneas para la región especificada. Si desea buscar instantáneas en la región predeterminada, puede omitir el parámetro --region.
Para Linux, macOS o Unix:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Para Windows:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
La salida de esta operación será similar a lo que se indica a continuación.
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]Solo tiene que eliminar las instantáneas manual. Las instantáneas Automated se eliminan cuando elimina el clúster.
Eliminación de recursos facturables no deseados
Para eliminar un clúster, antes debe eliminar todas las instancias de ese clúster.
-
Para eliminar las instancias, consulte Eliminación de una instancia de Amazon DocumentDB.
importante
Aunque elimine las instancias de un clúster, se le seguirá facturando por el uso del almacenamiento y las copias de seguridad asociadas a ese clúster. Para evitar todos los cargos, también debe eliminar el clúster y las instantáneas manuales.
-
Para eliminar clústeres, consulte Eliminación de un clúster de Amazon DocumentDB.
-
Para eliminar instantáneas manuales, consulte Eliminación de una instantánea del clúster.
