Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Mejores prácticas de confiabilidad
Esta sección proporciona orientación sobre cómo hacer que las cargas de trabajo que se ejecutan en EKS sean resilientes y estén altamente disponibles
Cómo usar esta guía
Esta guía está destinada a desarrolladores y arquitectos que desean desarrollar y operar servicios de alta disponibilidad y tolerantes a fallos en EKS. La guía está organizada en diferentes áreas temáticas para facilitar su consumo. Cada tema comienza con una breve descripción, seguida de una lista de recomendaciones y mejores prácticas para garantizar la fiabilidad de los clústeres de EKS.
Introducción
Las prácticas recomendadas de fiabilidad de EKS se han agrupado en los siguientes temas:
-
Aplicaciones
-
Plano de control
-
Plano de datos
¿Qué hace que un sistema sea fiable? Si un sistema puede funcionar de manera consistente y satisfacer las demandas a pesar de los cambios en su entorno durante un período de tiempo, se lo puede considerar confiable. Para lograrlo, el sistema debe detectar los fallos, subsanarse automáticamente y tener la capacidad de escalar en función de la demanda.
Los clientes pueden usar Kubernetes como base para operar aplicaciones y servicios de misión crítica de manera confiable. Pero además de incorporar principios de diseño de aplicaciones basadas en contenedores, ejecutar cargas de trabajo de manera confiable también requiere una infraestructura confiable. En Kubernetes, la infraestructura comprende el plano de control y el plano de datos.
EKS proporciona un plano de control de Kubernetes apto para producción que está diseñado para ofrecer una alta disponibilidad y tolerancia a los fallos.
En EKS, AWS es responsable de la fiabilidad del plano de control de Kubernetes. EKS ejecuta el plano de control de Kubernetes en tres zonas de disponibilidad de una región de AWS. Administra automáticamente la disponibilidad y la escalabilidad de los servidores API de Kubernetes y del clúster etcd.
La responsabilidad de la confiabilidad del plano de datos recae entre usted, el cliente y AWS. EKS ofrece cuatro opciones de nodos de trabajo para implementar el plano de datos de Kubernetes.
El modo automático de EKS, que es la opción más gestionada, gestiona el aprovisionamiento, el escalado y las actualizaciones del plano de datos, además de proporcionar capacidades gestionadas de computación, redes y almacenamiento. Las AMI de modo automático se publican con frecuencia y los clústeres se actualizan automáticamente a la AMI más reciente para implementar correcciones y parches de seguridad de CVE. Puede controlar cuándo ocurre esto configurando los controles de interrupción en el modo automático. NodePools
Fargate gestiona el aprovisionamiento y el escalado del plano de datos mediante la ejecución de un pod por nodo. La tercera opción, los grupos de nodos gestionados, gestiona el aprovisionamiento y las actualizaciones del plano de datos. Por último, los nodos autogestionados son la opción menos gestionada para el plano de datos. Cuanto más plano AWS-managed de datos utilice, menor será la responsabilidad que tendrá.
Los grupos de nodos gestionados automatizan el aprovisionamiento y la administración del ciclo de vida de los nodos de EC2. Puede usar la API de EKS (mediante la consola de EKS, la API de AWSCloudFormation, la CLI de AWS o Terraformeksctl) para crear, escalar y actualizar los nodos administrados. Los nodos gestionados ejecutan instancias EC2 de EKS-optimized Amazon Linux 2 en su cuenta y puede instalar paquetes de software personalizados habilitando el acceso SSH. Cuando aprovisiona nodos administrados, se ejecutan como parte de un grupo de EKS-managed Auto Scaling que puede abarcar varias zonas de disponibilidad; esto se controla a través de las subredes que proporciona al crear los nodos administrados. EKS también etiqueta automáticamente los nodos gestionados para que puedan usarse con Cluster AutoScaler.
Amazon EKS sigue el modelo de responsabilidad compartida para CVE y los parches de seguridad en grupos de nodos administrados. Dado que los nodos gestionados ejecutan las EKS-optimized AMI de Amazon, Amazon EKS se encarga de crear versiones parcheadas de estas AMI cuando se corrigen errores. Sin embargo, es responsable de implementar estas versiones de AMI parcheadas en los grupos de nodos administrados.
EKS también gestiona la actualización de los nodos, aunque usted debe iniciar el proceso de actualización. El proceso de actualización del nodo gestionado se explica en la documentación de EKS.
Si ejecuta nodos autogestionados, puede utilizar la AMI de Amazon EKS-optimized Linux para crear nodos de trabajo. Usted es responsable de parchear y actualizar la AMI y los nodos. Se recomienda utilizar o utilizar eksctl la infraestructura como herramientas de código para aprovisionar los nodos autogestionados CloudFormation, ya que esto le facilitará la actualización de los nodos autogestionados. Considere la posibilidad de migrar a nuevos nodos cuando actualice los nodos de trabajo, ya que el proceso de migración contamina el grupo de nodos anterior NoSchedule y agota los nodos una vez que una nueva pila esté lista para aceptar la carga de trabajo del módulo existente. Sin embargo, también puedes realizar una actualización local de los nodos autogestionados.
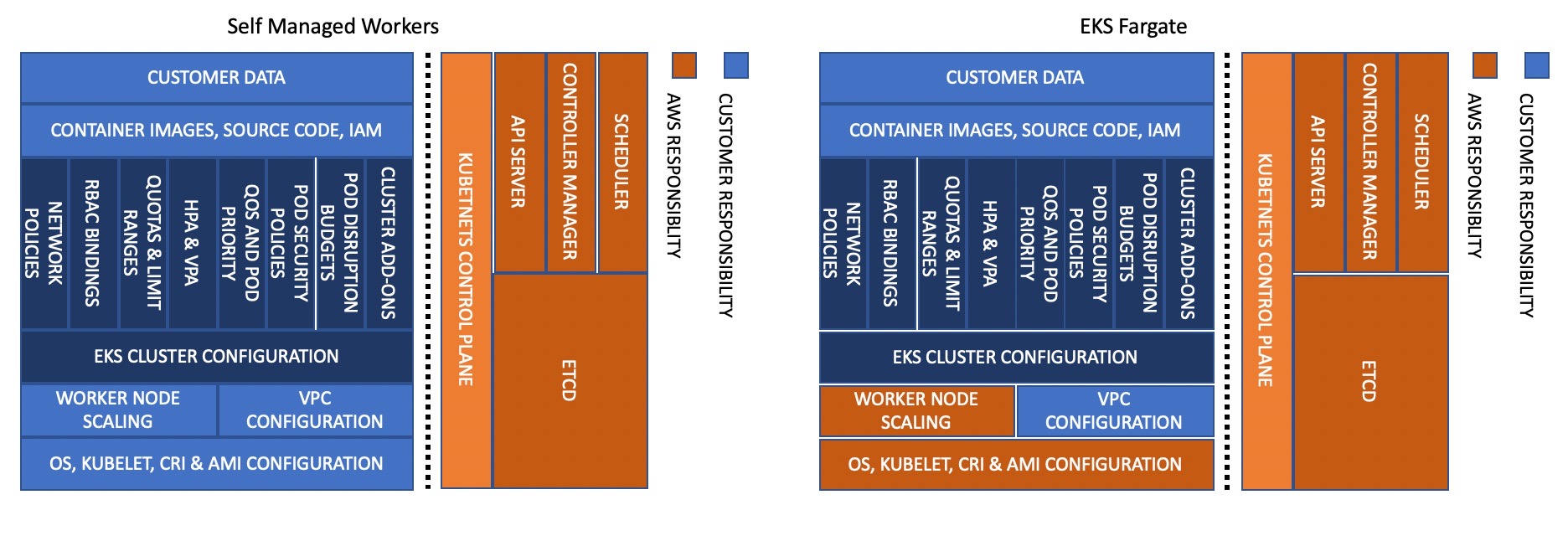
Modelo de responsabilidad compartida - Fargate
Modelo de responsabilidad compartida - MNG
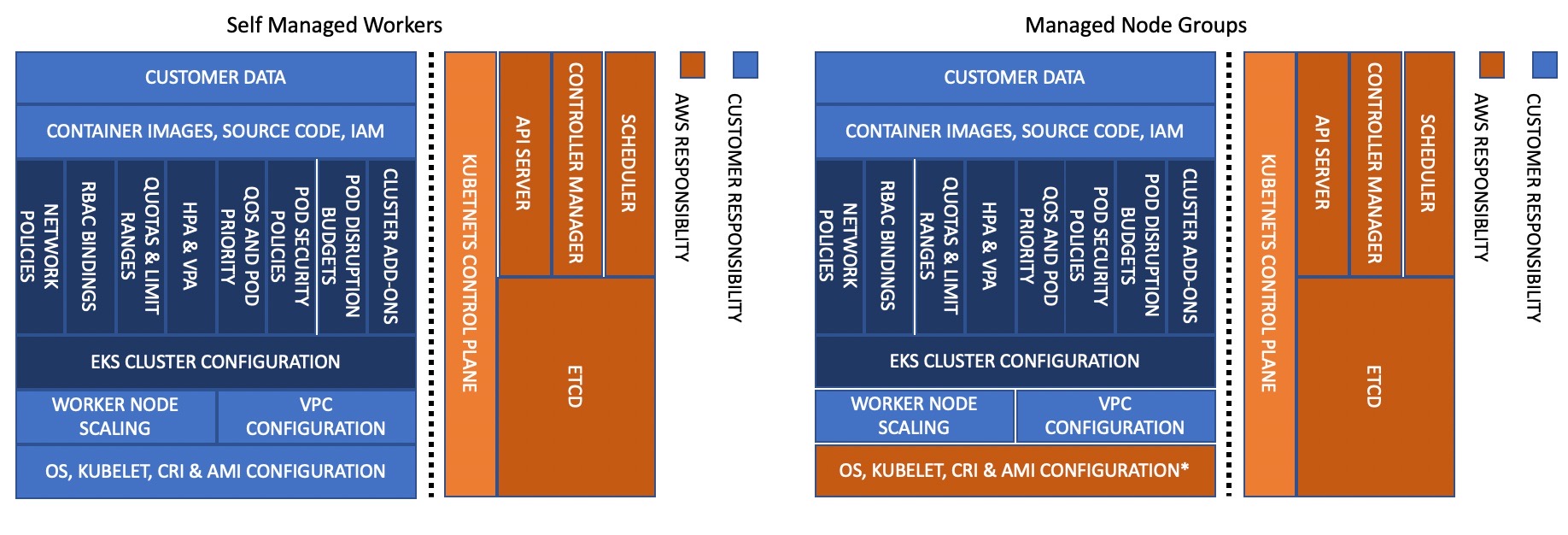
Esta guía incluye un conjunto de recomendaciones que puede utilizar para mejorar la confiabilidad de su plano de datos de EKS, los componentes principales de Kubernetes y sus aplicaciones.
Comentarios
Esta guía se publica GitHub para recopilar comentarios y sugerencias directos de la comunidad en general. EKS/Kubernetes Si tienes alguna buena práctica que consideres que deberíamos incluir en la guía, presenta un problema o envía un PR al GitHub repositorio. Tenemos la intención de actualizar la guía periódicamente a medida que se agreguen nuevas funciones al servicio o cuando surja una nueva práctica recomendada.
