Ayude a mejorar esta página
Para contribuir a esta guía del usuario, elija el enlace Edit this page on GitHub que se encuentra en el panel derecho de cada página.
Conceptos de Kubernetes
Amazon Elastic Kubernetes Service (Amazon EKS) es un servicio administrado de AWS basado en un proyecto de código abierto de Kubernetes
Esta página divide los conceptos de Kubernetes en tres secciones: ¿Por qué debería elegir Kubernetes?, Clústeres y Cargas de trabajo. La primera sección describe el valor de ejecutar un servicio de Kubernetes, en particular como un servicio administrado como Amazon EKS. La sección Cargas de trabajo describe cómo se crean, almacenan, ejecutan y administran las aplicaciones de Kubernetes. La sección Clústeres describe los diferentes componentes que componen los clústeres de Kubernetes y cuáles son sus responsabilidades a la hora de crear y mantener los clústeres de Kubernetes.
A medida que vaya leyendo este contenido, los enlaces le llevarán a descripciones más detalladas de los conceptos de Kubernetes, tanto en Amazon EKS como en la documentación de Kubernetes, por si quiere profundizar en alguno de los temas aquí tratados. Para obtener más información sobre cómo Amazon EKS implementa las características de computación y del plano de control de Kubernetes, consulte Arquitectura de Amazon EKS.
¿Por qué debería elegir Kubernetes?
Kubernetes se diseñó para mejorar la disponibilidad y la escalabilidad al ejecutar aplicaciones en contenedores esenciales y con calidad de producción. En lugar de ejecutar Kubernetes en una sola máquina (aunque eso es posible), Kubernetes logra esos objetivos al permitir ejecutar aplicaciones en conjuntos de computadoras que pueden expandirse o contraerse para satisfacer la demanda. Kubernetes incluye características que le facilitan lo siguiente:
-
Implementar aplicaciones en varios equipos (mediante contenedores implementados en pods)
-
Supervisar el estado de los contenedores y reiniciar los que estén defectuosos
-
Escalar los contenedores hacia arriba y hacia abajo en función de la carga
-
Actualizar los contenedores con nuevas versiones
-
Mover recursos entre contenedores
-
Equilibrar el tráfico entre las máquinas
Permitir que Kubernetes automatice este tipo de tareas complejas permite a los desarrolladores de aplicaciones concentrarse en la creación y mejora de sus cargas de trabajo, en lugar de preocuparse por la infraestructura. El desarrollador suele crear archivos de configuración, formateados como archivos YAML, que describen el estado deseado de la aplicación. Esto podría incluir qué contenedores ejecutar, los límites de recursos, el número de réplicas del pod, la asignación de CPU o memoria, las reglas de afinidad, etc.
Atributos de Kubernetes
Para lograr sus objetivos, Kubernetes cuenta con los siguientes atributos:
-
En contenedores: Kubernetes es una herramienta de orquestación de contenedores. Para usar Kubernetes, antes debe tener sus aplicaciones en contenedores. Según el tipo de aplicación, puede ser un conjunto de microservicios, trabajos por lotes o de otras formas. De este modo, sus aplicaciones pueden aprovechar un flujo de trabajo de Kubernetes que abarca un enorme ecosistema de herramientas, en el que los contenedores pueden almacenarse como imágenes en un registro de contenedores
, implementarse en un clúster de Kubernetes y ejecutarse en un nodo disponible. Puede crear y probar contenedores individuales en su equipo local con Docker u otro tiempo de ejecución de contenedores , antes de implementarlos en su clúster de Kubernetes. -
Escalable: si la demanda de sus aplicaciones supera la capacidad de las instancias en ejecución de esas aplicaciones, Kubernetes podrá escalar verticalmente. Según sea necesario, Kubernetes puede determinar si las aplicaciones requieren más CPU o memoria y responder mediante la ampliación automática de la capacidad disponible o con una mayor capacidad existente. El escalado se puede llevar a cabo en el pod, si hay suficiente computación disponible para ejecutar más instancias de la aplicación (escalado automático horizontal del pod
), o en el nodo, si es necesario instalar más nodos para gestionar el aumento de la capacidad (Escalador automático de clústeres o Karpenter ). Como la capacidad ya no es necesaria, estos servicios pueden eliminar los pods innecesarios y cerrar los nodos innecesarios. -
Disponible: si una aplicación o un nodo deja de funcionar o no está disponible, Kubernetes puede mover las cargas de trabajo en ejecución a otro nodo disponible. Para forzar el problema, basta con eliminar una instancia en ejecución de una carga de trabajo o un nodo en el que se estén ejecutando sus cargas de trabajo. La conclusión es que las cargas de trabajo se pueden almacenar en otras ubicaciones si ya no se pueden ejecutar donde están.
-
Declarativo: Kubernetes utiliza la conciliación activa para verificar constantemente que el estado que se declara para el clúster coincida con el estado real. Al aplicar objetos de Kubernetes
a un clúster, normalmente a través de archivos de configuración con formato YAML, puede, por ejemplo, solicitar que se inicien las cargas de trabajo que desea ejecutar en su clúster. Puede cambiar las configuraciones más adelante para llevar a cabo otras acciones, como usar una versión posterior de un contenedor o asignar más memoria. Kubernetes hará lo necesario para establecer el estado deseado. Esto puede incluir activar o desactivar los nodos, detener y reiniciar las cargas de trabajo o extraer contenedores actualizados. -
Compatible con la composición: dado que una aplicación suele constar de varios componentes, es recomendable poder administrar un conjunto de estos componentes (que suelen estar representados por varios contenedores) de forma conjunta. Si bien Docker Compose ofrece una forma de hacerlo directamente con Docker, el comando Kompose
de Kubernetes puede ayudarlo a hacerlo con Kubernetes. Consulte Traducir un archivo de Docker Compose a recursos de Kubernetes para ver un ejemplo de cómo hacerlo. -
Extensible: a diferencia del software propietario, el proyecto de Kubernetes de código abierto está diseñado para que pueda ampliar Kubernetes como desee para satisfacer sus necesidades. Las API y los archivos de configuración están abiertos a modificaciones directas. Se recomienda a terceros desarrollar sus propios controladores
para ampliar tanto las características de infraestructura como las características de Kubernetes orientadas al usuario final. Los webhooks le permiten configurar reglas de clúster para hacer cumplir las políticas y adaptarlas a las condiciones cambiantes. Para obtener más ideas sobre cómo ampliar los clústeres de Kubernetes, consulte Extending Kubernetes . -
Portátil: muchas organizaciones han estandarizado sus operaciones en Kubernetes porque les permite administrar todas las necesidades de sus aplicaciones de la misma manera. Los desarrolladores pueden usar las mismas canalizaciones para crear y almacenar aplicaciones en contenedores. A continuación, esas aplicaciones se pueden implementar en clústeres de Kubernetes que se ejecutan en las instalaciones, en nubes, en terminales de puntos de venta de restaurantes o en dispositivos de IoT dispersos por los sitios remotos de la empresa. Su naturaleza de código abierto permite a las personas desarrollar estas distribuciones de Kubernetes especiales, junto con las herramientas necesarias para administrarlas.
Administración de Kubernetes
El código fuente de Kubernetes está disponible de forma gratuita, por lo que puede instalarlo con su propio equipo y administrar Kubernetes por su cuenta. Sin embargo, autoadministrar Kubernetes requiere una profunda experiencia operativa, y su mantenimiento requiere tiempo y esfuerzo. Por estas razones, la mayoría de las personas que implementan cargas de trabajo de producción eligen un proveedor de nube (como Amazon EKS) o en las instalaciones (como Amazon EKS Anywhere) con su propia distribución de Kubernetes probada y el apoyo de expertos de Kubernetes. Esto le permite librarse de gran parte del trabajo pesado e indiferenciado necesario para el mantenimiento de sus clústeres, que incluye:
-
Hardware: si no tiene hardware disponible para ejecutar Kubernetes según sus necesidades, un proveedor de servicios en la nube como AWS Amazon EKS puede ahorrarle costos iniciales. Con Amazon EKS, esto significa que puede consumir los mejores recursos de nube que ofrece AWS, incluidas las instancias de computación (Amazon Elastic Compute Cloud), su propio entorno privado (Amazon VPC), la administración central de identidades y permisos (IAM) y el almacenamiento (Amazon EBS). AWS administra las computadoras, las redes, los centros de datos y todos los demás componentes físicos necesarios para ejecutar Kubernetes. Del mismo modo, no tiene que planificar su centro de datos para gestionar la máxima capacidad en los días de mayor demanda. En el caso de Amazon EKS Anywhere u otros clústeres en las instalaciones de Kubernetes, es responsable de administrar la infraestructura utilizada en sus implementaciones de Kubernetes, pero puede confiar en que AWS le ayudará a mantener Kubernetes actualizado.
-
Administración del plano de control: Amazon EKS administra la seguridad y la disponibilidad del plano de control de Kubernetes alojado en AWS, que se encarga de programar contenedores, administrar la disponibilidad de las aplicaciones y otras tareas clave, para que pueda centrarse en las cargas de trabajo de sus aplicaciones. Si el clúster se interrumpe, AWS debería disponer de los medios necesarios para restaurarlo a un estado de ejecución. En el caso de Amazon EKS Anywhere, administraría el plano de control.
-
Actualizaciones probadas: cuando actualiza sus clústeres, puede confiar en Amazon EKS o Amazon EKS Anywhere para proporcionarle versiones probadas de sus distribuciones de Kubernetes.
-
Complementos: hay cientos de proyectos diseñados para ampliar la funcionalidad y trabajar con Kubernetes que puede agregar a la infraestructura de su clúster o utilizarlos para facilitar la ejecución de sus cargas de trabajo. De modo que no tenga que crear y administrar esos complementos por su cuenta, AWS proporciona Complementos de Amazon EKS que se pueden usar con los clústeres. Amazon EKS Anywhere ofrece paquetes seleccionados
que incluyen compilaciones de muchos proyectos populares de código abierto. Por lo tanto, no tiene que crear el software ni administrar parches de seguridad, correcciones de errores o actualizaciones críticas. Del mismo modo, si los valores predeterminados se ajustan a sus necesidades, es habitual que se necesite muy poca configuración de esos complementos. Consulte Extensión de clústeres para obtener más información sobre cómo ampliar su clúster con complementos.
Kubernetes en acción
En el siguiente diagrama se muestran las actividades clave que llevaría a cabo como administrador de Kubernetes o desarrollador de aplicaciones para crear y usar un clúster de Kubernetes. En el proceso, ilustra cómo los componentes de Kubernetes interactúan entre sí, con la nube de AWS como ejemplo del proveedor de nube subyacente.
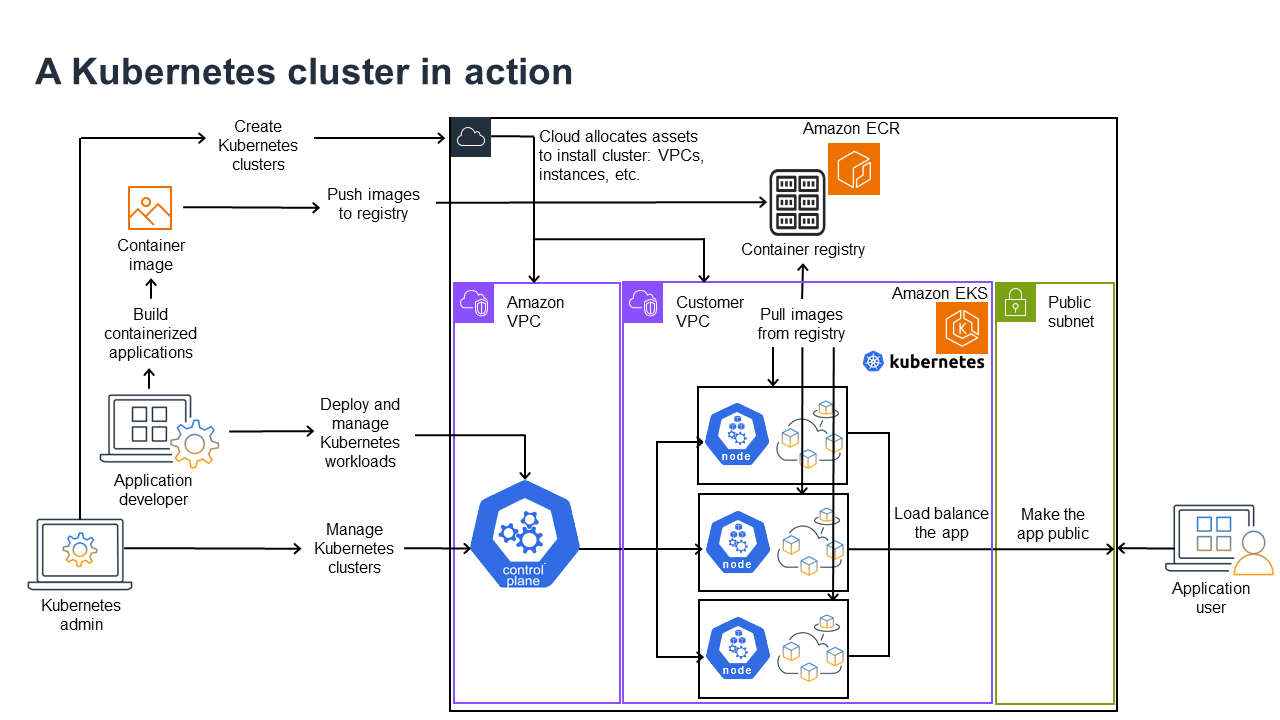
Un administrador de Kubernetes crea el clúster de Kubernetes mediante una herramienta específica para el tipo de proveedor en el que se creará el clúster. En este ejemplo, se utiliza la nube de AWS como proveedor, que ofrece el servicio administrado de Kubernetes denominado Amazon EKS. El servicio administrado asigna automáticamente los recursos necesarios para crear el clúster, lo que incluye la creación de dos nuevas nubes privadas virtuales (Amazon VPC) para el clúster, la configuración de la red y la asignación de permisos de Kubernetes directamente en las nuevas VPC para la administración de activos en la nube. Además, el servicio administrado garantiza que los servicios del plano de control tengan dónde ejecutarse y asigna cero o más instancias de Amazon EC2 como nodos de Kubernetes para ejecutar cargas de trabajo. AWS administra una Amazon VPC para el plano de control, mientras que la otra Amazon VPC contiene los nodos del cliente que ejecutan las cargas de trabajo.
En el futuro, muchas de las tareas del administrador de Kubernetes se harán mediante herramientas de Kubernetes como kubectl. Esa herramienta envía las solicitudes de servicios directamente al plano de control del clúster. Por lo tanto, las formas en que se hacen las consultas y los cambios en el clúster son muy similares a las formas en que se harían en cualquier clúster de Kubernetes.
Un desarrollador de aplicaciones que desee implementar cargas de trabajo en este clúster puede llevar a cabo varias tareas. El desarrollador debe crear la aplicación en una o más imágenes de contenedor y, a continuación, enviarlas a un registro de contenedores al que pueda acceder el clúster de Kubernetes. AWS ofrece Amazon Elastic Container Registry (Amazon ECR) para ese fin.
Para ejecutar la aplicación, el desarrollador puede crear archivos de configuración con formato YAML que indiquen al clúster cómo ejecutar la aplicación, incluidos los contenedores que deben extraerse del registro y cómo empaquetarlos en pods. El plano de control (programador) programa los contenedores en uno o más nodos y el tiempo de ejecución del contenedor en cada nodo extrae y ejecuta los contenedores necesarios. El desarrollador también puede configurar un equilibrador de carga de aplicaciones para equilibrar el tráfico hacia los contenedores disponibles que se ejecutan en cada nodo y exponer la aplicación al mundo exterior para que esté disponible en una red pública. Una vez hecho esto, cualquier persona que desee utilizar la aplicación puede conectarse al punto de conexión de la aplicación para acceder a ella.
En las siguientes secciones se abordan los detalles de cada una de estas características desde la perspectiva de los clústeres y las cargas de trabajo de Kubernetes.
Clústeres
Si su trabajo consiste en iniciar y administrar clústeres de Kubernetes, debe saber cómo se crean, mejoran, administran y eliminan los clústeres de Kubernetes. También debe saber cuáles son los componentes que componen un clúster y qué debe hacer para mantenerlos.
Las herramientas para administrar los clústeres gestionan la superposición entre los servicios de Kubernetes y el proveedor de hardware subyacente. Por esa razón, la automatización de estas tareas la suele llevar a cabo el proveedor de Kubernetes (como Amazon EKS o Amazon EKS Anywhere) mediante herramientas específicas del proveedor. Por ejemplo, para iniciar un clúster de Amazon EKS puede utilizar eksctl create cluster, mientras que para Amazon EKS Anywhere puede usar eksctl anywhere create cluster. Tenga en cuenta que, si bien estos comandos crean un clúster de Kubernetes, son específicos del proveedor y no forman parte del proyecto de Kubernetes en sí.
Herramientas de creación y administración de clústeres
El proyecto de Kubernetes ofrece herramientas para crear un clúster de Kubernetes manualmente. Por lo tanto, si desea instalar Kubernetes en una sola máquina o ejecutar el plano de control en una máquina y agregar nodos manualmente, puede usar herramientas de la CLI, como kind
En la nube de AWS, puede crear clústeres de Amazon EKS mediante herramientas de la CLI, como eksctl
-
Plano de control administrado: AWS garantiza que el clúster de Amazon EKS esté disponible y sea escalable, ya que administra el plano de control y hace que esté disponible en todas las zonas de disponibilidad de AWS.
-
Administración de nodos: en lugar de agregar nodos manualmente, puede hacer que Amazon EKS cree nodos automáticamente según sea necesario mediante grupos de nodos administrados (consulte Simplificación del ciclo de vida de los nodos con grupos de nodos administrados) o Karpenter
. Los grupos de nodos administrados tienen integraciones con el Escalado automático de clústeres de Kubernetes. Con las herramientas de administración de nodos, puede aprovechar los ahorros de costos, como las instancias de spot y la consolidación de nodos, y la disponibilidad, con las funciones de programación para establecer cómo se implementan las cargas de trabajo y cómo se seleccionan los nodos. -
Redes de clústeres: mediante plantillas de CloudFormation,
eksctlconfigura las redes entre los componentes del plano de control y del plano de datos (nodo) del clúster de Kubernetes. También configura puntos de conexión a través de los cuales se pueden llevar a cabo las comunicaciones internas y externas. Consulte De-mystifying cluster networking for Amazon EKS worker nodespara obtener más información. Las comunicaciones entre pods en Amazon EKS se llevan a cabo mediante Pod Identities de Amazon EKS (consulte Más información sobre cómo Pod Identity de EKS concede a los pods acceso a los servicios de AWS), lo que permite a los pods aprovechar los métodos de administración de credenciales y permisos en la nube de AWS. -
Complementos: Amazon EKS le ahorra tener que crear y agregar componentes de software que se utilizan habitualmente para admitir clústeres de Kubernetes. Por ejemplo, cuando crea un clúster de Amazon EKS desde la AWS Management Console, se agregan automáticamente el kube-proxy de Amazon EKS (Administración de kube-proxy en clústeres de Amazon EKS), el complemento CNI de Amazon VPC para Kubernetes (Asignación de direcciones IP a pods con CNI de Amazon VPC) y los complementos de CoreDNS (Administración de CoredNS para DNS en clústeres de Amazon EKS). Consulte Complementos de Amazon EKS para obtener más información sobre estos complementos, incluida una lista de los que están disponibles.
Para ejecutar sus clústeres en sus propias computadoras y redes en las instalaciones, Amazon ofrece Amazon EKS Anywhere
Amazon EKS Anywhere se basa en el mismo software de Amazon EKS Distroetcd más adelante en este documento).
Componentes del clúster
Los componentes del clúster de Kubernetes se dividen en dos áreas principales: el plano de control y los nodos de trabajo. Los componentes del plano de control
Plano de control
El plano de control consiste en un conjunto de servicios que administran el clúster. Es posible que todos estos servicios se ejecuten en un solo equipo o que estén repartidos en varios equipos. Internamente, se denominan instancias del plano de control (CPI). La forma en que se ejecutan las CPI depende del tamaño del clúster y de los requisitos de alta disponibilidad. A medida que aumenta la demanda en el clúster, un servicio de plano de control puede escalarse para ofrecer más instancias de ese servicio y equilibrar la carga de las solicitudes entre las instancias.
Entre las tareas que llevan a cabo los componentes del plano de control de Kubernetes se incluyen las siguientes:
-
Comunicación con los componentes del clúster (servidor de API): el servidor de API (kube-apiserver
) expone la API de Kubernetes para que las solicitudes al clúster se puedan efectuar tanto desde dentro como desde fuera del clúster. En otras palabras, las solicitudes para agregar o cambiar los objetos de un clúster (pods, servicios, nodos, etc.) pueden provenir de comandos externos, como las solicitudes de kubectlpara ejecutar un pod. Del mismo modo, se pueden hacer solicitudes desde el servidor de API a los componentes del clúster, por ejemplo, una consulta al serviciokubeletpara conocer el estado de un pod. -
Almacenamiento de datos sobre el clúster (almacén de pares de clave y valor de
etcd): el servicio deetcddesempeña la función fundamental de hacer un seguimiento del estado actual del clúster. Si el servicioetcddejara de ser accesible, no podría actualizar ni consultar el estado del clúster, aunque las cargas de trabajo seguirían ejecutándose durante un tiempo. Por ese motivo, los clústeres críticos suelen tener varias instancias del servicioetcdcon equilibrio de carga que se ejecutan a la vez y hacen copias de seguridad periódicas del almacén de pares de clave-valor deetcden caso de pérdida o corrupción de los datos. Tenga en cuenta que, en Amazon EKS, todo esto se gestiona automáticamente de forma predeterminada. Amazon EKS Anywhere proporciona instrucciones para la copia de seguridad y restauración de etcd. Consulte el Modelo de datos de etcd para aprender cómo etcdadministra los datos. -
Programación de los pods por nodos (Programador): las solicitudes para iniciar o detener un pod en Kubernetes se dirigen al Programador de Kubernetes
(kube-scheduler ). Como un clúster puede tener varios nodos capaces de ejecutar el pod, es el programador quien decide en qué nodo (o nodos, en el caso de las réplicas) debe ejecutarse el pod. Si no hay suficiente capacidad disponible para ejecutar el pod solicitado en un nodo existente, la solicitud fallará, a menos que haya tomado otras medidas. Estas disposiciones podrían incluir la habilitación de servicios, como los grupos de nodos administrados (Simplificación del ciclo de vida de los nodos con grupos de nodos administrados) o Karpenter , que puedan iniciar automáticamente nuevos nodos para gestionar las cargas de trabajo. -
Mantenimiento de los componentes en el estado deseado (Administrador de controladores): el Administrador de controladores de Kubernetes se ejecuta como un proceso daemon (kube-controller-manager
) para observar el estado del clúster y hacer cambios en él para restablecer los estados esperados. En concreto, hay varios controladores que vigilan diferentes objetos de Kubernetes, entre los que se incluyen statefulset-controller,endpoint-controller,cronjob-controllerynode-controller, entre otros. -
Administración de los recursos de la nube (Administrador de controladores de la nube): el Administrador de controladores de la nube
(cloud-controller-manager ) gestiona las interacciones entre Kubernetes y el proveedor de servicios en la nube que hace las solicitudes de los recursos del centro de datos subyacente. Los controladores administrados por el administrador de controladores de la nube pueden incluir un controlador de rutas (para establecer rutas de red en la nube), un controlador de servicios (para utilizar servicios de equilibrador de carga en la nube) y un controlador del ciclo de vida de nodos (para mantener los nodos sincronizados con Kubernetes a lo largo de sus ciclos de vida).
Nodos de trabajo (plano de datos)
En el caso de un clúster de Kubernetes de un solo nodo, las cargas de trabajo se ejecutan en la misma máquina que el plano de control. Sin embargo, una configuración más estándar consiste en tener uno o más sistemas de computación independientes (nodos
Al crear un clúster de Kubernetes por primera vez, algunas herramientas de creación de clústeres permiten configurar un número determinado de nodos para agregarlos al clúster (ya sea al identificar sistemas de computación existentes o hacer que el proveedor cree otros nuevos). Antes de agregar cargas de trabajo a esos sistemas, se agregan servicios a cada nodo para implementar estas características:
-
Administración de cada nodo (
kubelet): el servidor de API se comunica con el servicio kubeletque se ejecuta en cada nodo para asegurarse de que el nodo esté registrado correctamente y de que los pods solicitados por el Programador estén en ejecución. El kubelet puede leer los manifiestos de los pods y configurar los volúmenes de almacenamiento u otras características que necesiten los pods del sistema local. También puede comprobar el estado de los contenedores que se ejecutan localmente. -
Ejecución de contenedores en un nodo (tiempo de ejecución de contenedores): el tiempo de ejecución de contenedores
de cada nodo administra los contenedores solicitados para cada pod asignado al nodo. Esto significa que puede extraer imágenes de contenedores del registro correspondiente, ejecutar el contenedor, detenerlo y responder a las consultas sobre el contenedor. El tiempo de ejecución del contenedor predeterminado es containerd . A partir de la versión 1.24 de Kubernetes, se eliminó la integración especial de Docker ( dockershim), que podía usarse como tiempo de ejecución del contenedor de Kubernetes. Si bien puede seguir usando Docker para probar y ejecutar contenedores en su sistema local, para usar Docker con Kubernetes tendrá que instalar el motor de Dockeren cada nodo para usarlo con Kubernetes. -
Administración de la red entre contenedores (
kube-proxy): para permitir la comunicación entre pods, Kubernetes utiliza una característica denominada serviciopara configurar redes de pods que rastrean las direcciones IP y los puertos asociados a dichos pods. El servicio kube-proxy se ejecuta en todos los nodos para permitir que se produzca la comunicación entre los pods.
Extensión de clústeres
Hay algunos servicios que puede agregar a Kubernetes para que sean compatibles con el clúster, pero no se ejecutan en el plano de control. Estos servicios suelen ejecutarse directamente en los nodos del espacio de nombres kube-system o en su propio espacio de nombres (como suele ocurrir con los proveedores de servicios de terceros). Un ejemplo común es el servicio CoreDNS, que proporciona servicios DNS al clúster. Consulte Discovering built in services
Hay diferentes tipos de complementos que puede considerar agregar a sus clústeres. Para mantener los clústeres en buen estado, puede agregar características de observabilidad (consulte Supervisión del rendimiento de un clúster y visualización de registros) capaces de efectuar tareas como el registro, la auditoría y las métricas. Con esta información, puede solucionar los problemas que se producen, a menudo a través de las mismas interfaces de observabilidad. Algunos ejemplos de estos tipos de servicios son Amazon GuardDuty, CloudWatch (consulte Supervisión de datos de clústeres con Amazon CloudWatch), AWS Distro para OpenTelemetry
Para obtener una lista más completa de los complementos disponibles de Amazon EKS, consulte Complementos de Amazon EKS.
Cargas de trabajo
Kubernetes define una carga de trabajo
Contenedores
El elemento más básico de la carga de trabajo de una aplicación que se implementa y administra en Kubernetes es un pod
Como el pod es la unidad implementable más pequeña, normalmente contiene un contenedor. Sin embargo, en el caso de que los contenedores estén bien acoplados, puede haber varios contenedores en un mismo pod. Por ejemplo, un contenedor de servidor web puede estar empaquetado en un pod con un contenedor tipo sidecar
Las especificaciones del pod (PodSpec
Mientras que un pod es la unidad más pequeña que se implemente, un contenedor es la unidad más pequeña que se crea y administra.
Creación de contenedores
En realidad, el pod no es más que una estructura alrededor de uno o más contenedores, en la que cada contenedor contiene el sistema de archivos, los ejecutables, los archivos de configuración, las bibliotecas y otros componentes necesarios para ejecutar realmente la aplicación. Debido a que una empresa llamada Docker Inc. fue la primera en popularizar los contenedores, algunas personas se refieren a los contenedores como contenedores de Docker. Sin embargo, desde entonces, la Open Container Initiative
Cuando crea un contenedor, normalmente comienza con un Dockerfile (literalmente llamado así). Dentro de ese Dockerfile, puede identificar lo siguiente:
-
Una imagen base: una imagen de contenedor base es un contenedor que normalmente se crea a partir de una versión mínima del sistema de archivos de un sistema operativo (como Red Hat Enterprise Linux
o Ubuntu ) o de un sistema mínimo que se mejora para proporcionar software que ejecute tipos específicos de aplicaciones (como aplicaciones nodejs o python ). -
Software de aplicaciones: puede agregar el software de su aplicación a su contenedor de la misma manera que lo agregaría a un sistema Linux. Por ejemplo, en su Dockerfile puede ejecutar
npmyyarnpara instalar una aplicación Java oyumydnfpara instalar paquetes RPM. En otras palabras, si utiliza el comando RUN en un Dockerfile, puede ejecutar cualquier comando que esté disponible en el sistema de archivos de la imagen base para instalar software o configurar software dentro de la imagen contenedora resultante. -
Instrucciones: en la referencia de Dockerfile
se describen las instrucciones que puede agregar a un Dockerfile al configurarlo. Estas incluyen instrucciones que se utilizan para crear lo que hay en el propio contenedor (archivos ADDoCOPYdel sistema local), identificar los comandos que se van a ejecutar cuando se ejecuta el contenedor (CMDoENTRYPOINT) y conectar el contenedor al sistema en el que se ejecuta (identificando elUSERque se va a ejecutar, elVOLUMElocal que se va a montar o los puertos aEXPOSE).
Si bien el comando docker y el servicio se han utilizado tradicionalmente para crear contenedores (docker build), otras herramientas disponibles para crear imágenes de contenedores incluyen podman
Almacenamiento de contenedores
Una vez que haya creado la imagen del contenedor, puede almacenarla en un registro de distribución
Para almacenar las imágenes de los contenedores de una forma más pública, puede enviarlas a un registro de contenedores público. Los registros públicos de contenedores proporcionan una ubicación central para almacenar y distribuir las imágenes de los contenedores. Algunos ejemplos de registros de contenedores públicos son Amazon Elastic Container Registry
Al ejecutar cargas de trabajo en contenedores en Amazon Elastic Kubernetes Service (Amazon EKS), recomendamos que extraiga copias de las imágenes oficiales de Docker que se almacenan en Amazon Elastic Container Registry. Amazon ECR ha estado almacenando estas imágenes desde 2021. Puede buscar imágenes de contenedores populares en la Galería pública de Amazon ECR
Ejecución de contenedores
Como los contenedores se crean en un formato estándar, un contenedor puede ejecutarse en cualquier máquina que pueda ejecutar un contenedor en tiempo de ejecución (por ejemplo, Docker) y cuyo contenido coincida con la arquitectura de la máquina local (por ejemplo, x86_64 o arm). Para probar un contenedor o simplemente ejecutarlo en el escritorio local, puede usar los comandos docker run o podman run para iniciar un contenedor en el servidor local. Sin embargo, en Kubernetes, cada nodo de trabajo tiene implementado un tiempo de ejecución del contenedor y depende de Kubernetes que se solicite que un nodo ejecute un contenedor.
Una vez que se ha asignado un contenedor para que se ejecute en un nodo, este comprueba si la versión solicitada de la imagen del contenedor ya existe en el nodo. Si no es así, Kubernetes indica al tiempo de ejecución del contenedor que extraiga ese contenedor del registro de contenedores correspondiente y, a continuación, lo ejecute localmente. Tenga en cuenta que la imagen de un contenedor hace referencia al paquete de software que se mueve entre su portátil, el registro del contenedor y los nodos de Kubernetes. Un contenedor hace referencia a una instancia en ejecución de esa imagen.
Pods
Una vez que los contenedores estén listos, trabajar con los pods incluye configurar, implementar y hacer que estos sean accesibles.
Configuración de pods
Cuando define un pod, le asigna un conjunto de atributos. Esos atributos deben incluir al menos el nombre del pod y la imagen del contenedor para que se ejecuten. Sin embargo, hay muchas otras cosas que también querrá configurar con las definiciones de su pod (consulte la página PodSpec
-
Almacenamiento: cuando un contenedor en ejecución se detiene y se elimina, el almacenamiento de datos en ese contenedor desaparecerá, a menos que configure un almacenamiento más permanente. Kubernetes admite muchos tipos de almacenamiento diferentes y los abstrae bajo el nombre de volúmenes
. Los tipos de almacenamiento incluyen CephFS , NFS , iSCSI , etc. Incluso puede usar un dispositivo de bloques local desde la computadora local. Con uno de esos tipos de almacenamiento disponibles en su clúster, puede montar el volumen de almacenamiento en un punto de montaje seleccionado del sistema de archivos del contenedor. Un volumen persistente es aquel que sigue existiendo después de eliminar el pod, mientras que un volumen efímero se elimina cuando se elimina el pod. Si el administrador del clúster creó diferentes clases de almacenamiento para el clúster, es posible que tenga la opción de elegir los atributos del almacenamiento que va a utilizar, por ejemplo, si el volumen se elimina o se recupera después de su uso, si se ampliará si se necesita más espacio e incluso si cumple con ciertos requisitos de rendimiento. -
Secretos: al poner los secretos
a disposición de los contenedores en las especificaciones del pod, puede proporcionar los permisos que esos contenedores necesitan para acceder a los sistemas de archivos, las bases de datos u otros activos protegidos. Las claves, las contraseñas y los tokens son algunos de los elementos que se pueden almacenar como secretos. El uso de secretos elimina la necesidad de almacenar esta información en las imágenes de contenedores, ya que únicamente es necesario que los secretos estén disponibles para los contenedores en ejecución. Los ConfigMaps son similares a los secretos. ConfigMaptiende a contener información menos crítica, como pares de clave-valor para configurar un servicio. -
Recursos de contenedores: los objetos para seguir configurando los contenedores pueden adoptar la forma de configuración de recursos. Para cada contenedor, puede solicitar la cantidad de memoria y CPU que puede usar, así como establecer límites a la cantidad total de esos recursos que puede usar el contenedor. Consulte Resource Management for Pods and Containers
para ver ejemplos. -
Interrupciones: los pods se pueden interrumpir de forma involuntaria (un nodo deja de funcionar) o de forma voluntaria (se desea una actualización). Al configurar un presupuesto de interrupciones para los pods
, puede controlar en cierta medida la disponibilidad de su aplicación en caso de que se produzcan interrupciones. Para ver ejemplos, consulte Specifying a Disruption Budget for your application . -
Espacios de nombres: Kubernetes proporciona diferentes formas de aislar las cargas de trabajo y los componentes de Kubernetes entre sí. Ejecutar todos los pods de una aplicación concreta en el mismo espacio de nombres
es una forma habitual de proteger y administrar esos pods juntos. Puede crear sus propios espacios de nombres para usarlos o elegir no indicar ninguno (lo que hace que Kubernetes utilice el espacio de nombres default). Los componentes del plano de control de Kubernetes normalmente se ejecutan en el espacio de nombres kube-system.
La configuración que acabamos de describir normalmente se recopila en un archivo YAML para aplicarla al clúster de Kubernetes. En el caso de los clústeres de Kubernetes personales, puede almacenar estos archivos YAML en el sistema local. Sin embargo, dado que los clústeres y las cargas de trabajo son más importantes, GitOps
Los objetos que se utilizan para recopilar e implementar la información del pod se definen mediante uno de los siguientes métodos de implementación.
Implementación de pods
El método que elija para implementar los pods depende del tipo de aplicación que planee ejecutar con ellos. Aquí tiene algunas opciones:
-
Aplicaciones sin estado: una aplicación sin estado no guarda los datos de la sesión de un cliente, por lo que no es necesario volver a hacer referencia a lo que ocurrió en una sesión anterior. Esto facilita la sustitución de los pods por otros nuevos en caso de que no funcionen correctamente, o bien el traslado de un sitio a otro sin guardar su estado. Si ejecuta una aplicación sin estado (como un servidor web), puede usar una Implementación
para implementar Pods y ReplicaSets . Un ReplicaSet define cuántas instancias de un pod desea que se ejecuten simultáneamente. Aunque puede ejecutar un ReplicaSet directamente, es habitual ejecutar réplicas directamente dentro de una implementación, para definir cuántas réplicas de un pod deben ejecutarse a la vez. -
Aplicaciones con estado: una aplicación con estado es aquella en la que la identidad del pod y el orden en que se lanzan los pods son importantes. Estas aplicaciones necesitan un almacenamiento persistente que sea estable y deben implementarse y escalarse de manera coherente. Para implementar una aplicación con estado en Kubernetes, puede usar StatefulSets
. Un ejemplo de una aplicación que normalmente se ejecuta como StatefulSet es una base de datos. Dentro de un StatefulSet, puede definir las réplicas, el pod y sus contenedores, los volúmenes de almacenamiento que se van a montar y las ubicaciones del contenedor donde se almacenan los datos. Consulte Run a Replicated Stateful Application para ver un ejemplo de una base de datos que se implementa como ReplicaSet. -
Aplicaciones por nodo: hay ocasiones en las que desea ejecutar una aplicación en cada nodo del clúster de Kubernetes. Por ejemplo, su centro de datos puede requerir que todos los equipos ejecuten una aplicación de monitoreo o un servicio de acceso remoto concreto. Para Kubernetes, puede utilizar un DaemonSet
para garantizar que la aplicación seleccionada se ejecute en todos los nodos del clúster. -
Las aplicaciones se ejecutan hasta completarse: hay algunas aplicaciones que desea ejecutar para completar una tarea concreta. Esto podría incluir uno que publique informes de estado mensuales o que elimine datos antiguos. Se puede usar un objeto Job
para configurar una aplicación para que se inicie y ejecute y, a continuación, se cierre cuando finalice la tarea. Un objeto CronJob permite configurar una aplicación para que se ejecute a una hora, minuto, día del mes, mes o día de la semana específicos, mediante una estructura definida por el formato crontab de Linux.
Hacer que las aplicaciones sean accesibles desde la red
Dado que las aplicaciones solían implementarse como un conjunto de microservicios que se desplazan a diferentes lugares, Kubernetes necesitaba una forma de que esos microservicios pudieran encontrarse entre sí. Además, para que otras personas pudieran acceder a una aplicación fuera del clúster de Kubernetes, este necesitaba una forma de exponer esa aplicación en direcciones y puertos externos. Estas características relacionadas con las redes se llevan a cabo con los objetos Servicio y Entrada, respectivamente:
-
Servicios: dado que un pod puede moverse a diferentes nodos y direcciones, otro pod que necesite comunicarse con el primer pod podría tener dificultades para localizar dónde está. Para resolver este problema, Kubernetes le permite representar una aplicación como un servicio
. Con un servicio, puede identificar un pod o un conjunto de pods con un nombre concreto y, a continuación, indicar qué puerto expone el servicio de esa aplicación desde el pod y qué puertos podría utilizar otra aplicación para contactar con ese servicio. Otro pod de un clúster puede simplemente solicitar un servicio por su nombre y Kubernetes dirigirá esa solicitud al puerto adecuado de una instancia del pod que ejecute ese servicio. -
Entrada: una entrada
es lo que permite que las aplicaciones representadas por los servicios de Kubernetes estén disponibles para los clientes que se encuentran fuera del clúster. Las características básicas de entrada incluyen un equilibrador de carga (administrado por la entrada), el controlador de entrada y reglas para dirigir las solicitudes desde el controlador al servicio. Hay varios controladores de entrada que puede elegir con Kubernetes.
Siguientes pasos
Comprender los conceptos básicos de Kubernetes y su relación con Amazon EKS lo ayudará a navegar por la documentación de Amazon EKS y la documentación de Kubernetes
