Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso de EMR Serverless con AWS Lake Formation para un control de acceso detallado
Descripción general de
Con Amazon EMR, versión 7.2.0 y versiones posteriores, aproveche AWS Lake Formation para aplicar controles de acceso detallados en las tablas del catálogo de datos respaldadas por S3. Esta capacidad le permite configurar controles de acceso a nivel de tabla, fila, columna y celda para consultas deread dentro de sus trabajos de Spark de Amazon EMR sin servidor. Para configurar un control de acceso detallado para los trabajos por lotes y las sesiones interactivas de Apache Spark, utilice EMR Studio. Consulte las siguientes secciones para obtener más información sobre Lake Formation y cómo usarlo con EMR sin servidor.
El uso de Amazon EMR Serverless AWS Lake Formation conlleva cargos adicionales. Para obtener más información, consulte Precios de Amazon EMR
Cómo funciona EMR Serverless con AWS Lake Formation
El uso de EMR sin servidor con Lake Formation le permite implementar una capa de permisos en cada trabajo de Spark para aplicar el control de permisos de Lake Formation cuando EMR sin servidor ejecuta trabajos. EMR sin servidor utiliza los perfiles de recursos de Spark
Cuando utilice la capacidad preinicializada con Lake Formation, le sugerimos que tenga un mínimo de dos controladores de Spark. Cada Formation-enabled trabajo de Lake utiliza dos controladores Spark, uno para el perfil de usuario y otro para el perfil del sistema. Para obtener el mejor rendimiento, utilice el doble de conductores para los Formation-enabled trabajos en Lake en comparación con los que utilizaría si no utilizara Lake Formation.
Cuando ejecute trabajos de Spark en EMR sin servidor, también debe tener en cuenta el impacto de la asignación dinámica en la administración de recursos y el rendimiento del clúster. La configuración de spark.dynamicAllocation.maxExecutors del número máximo de ejecutores por perfil de recursos se aplica a los ejecutores de usuario y a los ejecutores del sistema. Si configura ese número para que sea igual al número máximo permitido de ejecutores, es posible que la ejecución del trabajo se bloquee debido a que un tipo de ejecutor utiliza todos los recursos disponibles, lo que impide que el otro ejecutor ejecute los trabajos.
Para no quedarse sin recursos, EMR sin servidor establece el número máximo predeterminado de ejecutores por perfil de recursos en el 90 % del valor spark.dynamicAllocation.maxExecutors. Puede anular esta configuración al especificar spark.dynamicAllocation.maxExecutorsRatio con un valor entre 0 y 1. Además, también puede configurar las siguientes propiedades para optimizar la asignación de recursos y el rendimiento general:
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
A continuación, se ofrece una descripción general de alto nivel sobre cómo EMR sin servidor obtiene acceso a los datos protegidos por las políticas de seguridad de Lake Formation.
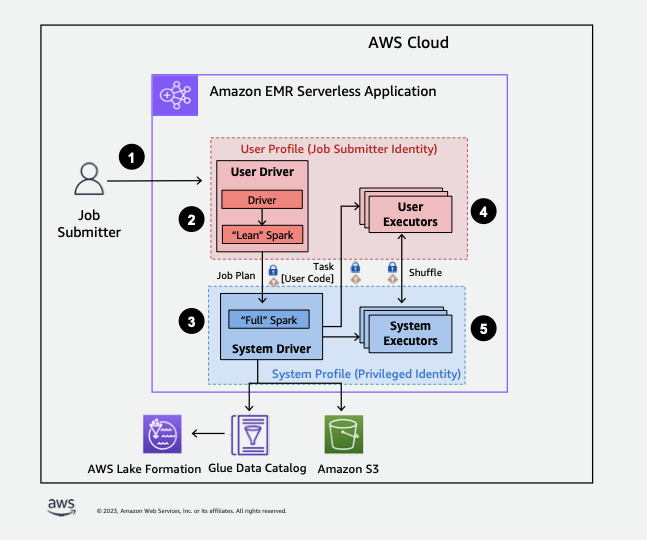
-
Un usuario envía un trabajo de Spark a una aplicación AWS Lake Formation EMR Serverless habilitada.
-
EMR sin servidor envía el trabajo a un controlador de usuario y lo ejecuta en el perfil de usuario. El controlador de usuario ejecuta una versión sencilla de Spark que no permite lanzar tareas, solicitar ejecutores ni acceder a S3 ni al catálogo de Glue. Crea un plan de trabajo.
-
EMR sin servidor configura un segundo controlador denominado controlador del sistema y lo ejecuta en el perfil del sistema (con una identidad privilegiada). EMR sin servidor configura un canal TLS cifrado entre los dos controladores para la comunicación. El controlador de usuario utiliza el canal para enviar los planes de trabajo al controlador del sistema. El controlador del sistema no ejecuta el código enviado por el usuario. Ejecuta Spark a pleno rendimiento y se comunica con S3 y con el catálogo de datos para acceder a los datos. Solicita ejecutores y compila el plan de trabajo en una secuencia de etapas de ejecución.
-
Luego, EMR sin servidor ejecuta las etapas en los ejecutores con el controlador de usuario o el controlador del sistema. En cualquier etapa, el código de usuario se ejecuta exclusivamente en los ejecutores de perfiles de usuario.
-
Las etapas que leen los datos de las tablas del catálogo de datos protegidas por filtros de seguridad AWS Lake Formation o las que los aplican se delegan a los ejecutores del sistema.
Habilitación de Lake Formation en Amazon EMR
Para habilitar Lake Formation, debe establecer spark.emr-serverless.lakeformation.enabled en true según la clasificación de spark-defaults para el parámetro de configuración de tiempo de ejecución al crear una aplicación EMR sin servidor.
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
También puede habilitar Lake Formation al crear una nueva aplicación en EMR Studio. Elija Uso de Lake Formation para un control de acceso detallado, disponible en Configuraciones adicionales.
Inter-worker el cifrado está habilitado de forma predeterminada cuando se utiliza Lake Formation con EMR Serverless, por lo que no es necesario volver a habilitar explícitamente el cifrado entre trabajadores.
Habilitación de Lake Formation para trabajos de Spark
Para habilitar Lake Formation para trabajos individuales de Spark, establezca spark.emr-serverless.lakeformation.enabled en “verdadero” cuando utilice spark-submit.
--conf spark.emr-serverless.lakeformation.enabled=true
Permisos de IAM del rol de tiempo de ejecución de trabajos
Los permisos de Lake Formation controlan el acceso a los recursos del catálogo de datos de AWS Glue, a las ubicaciones de Amazon S3 y a los datos subyacentes en esas ubicaciones. Los permisos de IAM controlan el acceso a las API y los recursos de Lake Formation y AWS Glue. Aunque es posible que tenga el permiso de Lake Formation para acceder a una tabla del catálogo de datos (SELECT), la operación fallará si no tiene el permiso de IAM en la operativa de la API glue:Get*.
El siguiente es un ejemplo de política sobre cómo proporcionar permisos de IAM para acceder a un script en S3, cargar registros en S3, permisos de la API de Glue de AWS y permiso para acceder a Lake Formation.
Configuración de permisos de Lake Formation para roles de tiempo de ejecución de trabajos
Primero, registre la ubicación de su tabla de Hive con Lake Formation. A continuación, cree los permisos para el rol de tiempo de ejecución de su trabajo en la tabla que desee. Para obtener más información sobre Lake Formation, consulte ¿Qué es AWS Lake Formation? en la Guía para AWS Lake Formation desarrolladores.
Después de configurar los permisos de Lake Formation, envíe trabajos de Spark en Amazon EMR sin servidor. Para obtener más información acerca de trabajos de Spark, consulte ejemplos de Spark.
Envío de la ejecución de un trabajo
Cuando termine de configurar los permisos de Lake Formation, podrá enviar trabajos a Spark en EMR sin servidor. En la siguiente sección, se muestran ejemplos de cómo configurar y enviar las propiedades de la ejecución del trabajo.
Requisitos del permiso
Tablas no registradas en AWS Lake Formation
En el caso de las tablas no registradas AWS Lake Formation, el rol de tiempo de ejecución del trabajo accede tanto al catálogo de datos de AWS Glue como a los datos de la tabla subyacente en Amazon S3. Esto requiere que el rol de tiempo de ejecución del trabajo tenga los permisos de IAM adecuados para las operaciones de AWS Glue y Amazon S3.
Tablas registradas en AWS Lake Formation
En el caso de las tablas registradas con AWS Lake Formation, el rol de ejecución del trabajo accede a los metadatos del catálogo de datos de AWS Glue, mientras que las credenciales temporales que vende Lake Formation acceden a los datos de la tabla subyacente en Amazon S3. Los permisos de Lake Formation necesarios para ejecutar una operación dependen del catálogo de datos de AWS Glue y de las llamadas a la API de Amazon S3 que inicie el trabajo de Spark y se pueden resumir de la siguiente manera:
-
El permiso DESCRIBE permite al rol de ejecución leer los metadatos de una tabla o base de datos en el catálogo de datos
-
El permiso ALTER permite al rol de ejecución modificar los metadatos de una tabla o base de datos en el catálogo de datos
-
El permiso DROP permite al rol de ejecución eliminar metadatos de tablas o bases de datos del catálogo de datos
-
El permiso SELECT permite al rol de ejecución leer datos de tablas de Amazon S3
-
El permiso INSERT permite al rol de ejecución escribir datos de tablas en Amazon S3
-
El permiso DELETE permite al rol de ejecución eliminar los datos de la tabla de Amazon S3
nota
Lake Formation evalúa los permisos de forma perezosa cuando un trabajo de Spark llama a AWS Glue para recuperar los metadatos de la tabla y a Amazon S3 para recuperar los datos de la tabla. Los trabajos que utilizan un rol en tiempo de ejecución con permisos insuficientes no fallarán hasta que Spark realice una llamada a AWS Glue o Amazon S3 que requiera el permiso faltante.
nota
En la siguiente matriz de tablas compatibles:
-
Las operaciones marcadas como compatibles utilizan exclusivamente las credenciales de Lake Formation para acceder a los datos de las tablas registradas en Lake Formation. Si los permisos de Lake Formation son insuficientes, la operación no recurrirá a las credenciales del rol en tiempo de ejecución. En el caso de las tablas no registradas en Lake Formation, las credenciales del rol de ejecución del trabajo acceden a los datos de la tabla.
-
Las operaciones marcadas como compatibles con los permisos de IAM en la ubicación de Amazon S3 no utilizan las credenciales de Lake Formation para acceder a los datos de las tablas subyacentes en Amazon S3. Para ejecutar estas operaciones, el rol de ejecución del trabajo debe tener los permisos de IAM de Amazon S3 necesarios para acceder a los datos de la tabla, independientemente de si la tabla está registrada en Lake Formation.
nota
A partir de Amazon EMR 7.12, las operaciones de DML y DDL que modifican los datos de las tablas utilizan las credenciales de Lake Formation. En Amazon EMR 7.11 y versiones anteriores, estas operaciones (excepto DELETE, UPDATE y MERGE) utilizan las credenciales del rol de ejecución de tareas para modificar los datos de la tabla. Amazon EMR 7.11 y las versiones anteriores no admiten las operaciones DELETE, UPDATE y MERGE.
