Uso de cuadernos Jupyter autoalojados
Puede alojar y administrar cuadernos de Jupyter o JupyterLab en una instancia de Amazon EC2 o en su propio clúster de Amazon EKS como un cuaderno de Jupyter autoalojado. A continuación, puede ejecutar cargas de trabajo interactivas con sus cuadernos de Jupyter autoalojados. En las siguientes secciones se explica el proceso de configuración e implementación de un cuaderno de Jupyter autoalojado en un clúster de Amazon EKS.
Creación de un cuaderno de Jupyter autoalojado en un clúster de EKS
- Creación de un grupo de seguridad
- Crear un punto de conexión interactivo de Amazon EMR en EKS
- Recuperar la URL del servidor de puerta de enlace de su punto de conexión interactivo
- Recuperar un token de autenticación para conectarse al punto de conexión interactivo
- Ejemplo: implementar un cuaderno de JupyterLab
- Eliminar un cuaderno de Jupyter autoalojado
Creación de un grupo de seguridad
Antes de poder crear un punto de conexión interactivo y ejecutar un cuaderno de Jupyter o JupyterLab autoalojado, debe crear un grupo de seguridad para controlar el tráfico entre el cuaderno y el punto de conexión interactivo. Para usar la consola de Amazon EC2 o el SDK de Amazon EC2 para crear el grupo de seguridad, consulte los pasos en Crear un grupo de seguridad en la Guía del usuario de Amazon EC2. Debe crear el grupo de seguridad en la VPC en la que desee implementar el servidor de su cuaderno.
Para seguir el ejemplo de esta guía, utilice la misma VPC que su clúster de Amazon EKS. Si desea alojar el cuaderno en una VPC diferente de la VPC de su clúster de Amazon EKS, es posible que tenga que crear una conexión de emparejamiento entre esas dos VPC. Para ver los pasos para crear una conexión de emparejamiento entre dos VPC, consulte Creación de una conexión de emparejamiento de VPC en la Guía de introducción a Amazon VPC.
En el siguiente paso, necesitará el ID del grupo de seguridad para crear un punto de conexión interactivo de Amazon EMR en EKS.
Crear un punto de conexión interactivo de Amazon EMR en EKS
Después de crear el grupo de seguridad de su cuaderno, siga los pasos que se indican en Creación de un punto de conexión interactivo para su clúster virtual para crear un punto de conexión interactivo. Debe proporcionar el ID del grupo de seguridad que creó para su cuaderno en Creación de un grupo de seguridad.
Introduzca el ID de seguridad en lugar de your-notebook-security-group-id en las siguientes opciones de anulación de la configuración:
--configuration-overrides '{ "applicationConfiguration": [ { "classification": "endpoint-configuration", "properties": { "notebook-security-group-id": "your-notebook-security-group-id" } } ], "monitoringConfiguration": { ...'
Recuperar la URL del servidor de puerta de enlace de su punto de conexión interactivo
Tras crear un punto de conexión interactivo, recupere la URL del servidor de puerta de enlace con el comando describe-managed-endpoint incluido en la AWS CLI. Necesita esta URL para conectar su cuaderno al punto de conexión. La URL del servidor de puerta de enlace es un punto de conexión privado.
aws emr-containers describe-managed-endpoint \ --regionregion\ --virtual-cluster-idvirtualClusterId\ --idendpointId
Al principio, el estado del punto de conexión es CREATING. Pasados unos minutos, pasa al estado ACTIVE. Cuando el estado del punto de conexión sea ACTIVE, estará listo para usarse.
Tome nota del atributo serverUrl que el comando aws emr-containers
describe-managed-endpoint devuelve desde el punto de conexión activo. Necesita esta URL para conectar su cuaderno al punto de conexión cuando implemente su cuaderno de Jupyter o JupyterLab autoalojado.
Recuperar un token de autenticación para conectarse al punto de conexión interactivo
Para conectarse a un punto de conexión interactivo desde un cuaderno de Jupyter o JupyterLab, debe generar un token de sesión con la API GetManagedEndpointSessionCredentials. El token actúa como prueba de autenticación para conectarse al servidor del punto de conexión interactivo.
El siguiente comando se explica con más detalle con un ejemplo de resultado.
aws emr-containers get-managed-endpoint-session-credentials \ --endpoint-identifierendpointArn\ --virtual-cluster-identifiervirtualClusterArn\ --execution-role-arnexecutionRoleArn\ --credential-type "TOKEN" \ --duration-in-secondsdurationInSeconds\ --regionregion
endpointArn-
El ARN de su punto de conexión. Puede encontrar el ARN en el resultado de una llamada
describe-managed-endpoint. virtualClusterArn-
El ARN del clúster virtual.
executionRoleArn-
El ARN del rol de ejecución.
durationInSeconds-
La duración en segundos durante la cual el token es válido. La duración predeterminada es de 15 minutos (
900) y la máxima, de 12 horas (43200). region-
La misma región que el punto de conexión.
El resultado debería parecerse al siguiente ejemplo. Tome nota del valor session-token
{
"id": "credentialsId",
"credentials": {
"token": "session-token"
},
"expiresAt": "2022-07-05T17:49:38Z"
}Ejemplo: implementar un cuaderno de JupyterLab
Una vez que haya completado los pasos anteriores, puede probar este procedimiento de ejemplo para implementar un cuaderno de JupyterLab en el clúster de Amazon EKS con su punto de conexión interactivo.
-
Cree un espacio de nombres para ejecutar el servidor de cuadernos.
-
Cree un archivo localmente denominado
notebook.yamly con el siguiente contenido. El contenido del archivo se describe a continuación.apiVersion: v1 kind: Pod metadata: name: jupyter-notebook namespace:namespacespec: containers: - name: minimal-notebook image: jupyter/all-spark-notebook:lab-3.1.4 # open source image ports: - containerPort: 8888 command: ["start-notebook.sh"] args: ["--LabApp.token=''"] env: - name: JUPYTER_ENABLE_LAB value: "yes" - name: KERNEL_LAUNCH_TIMEOUT value: "400" - name: JUPYTER_GATEWAY_URL value: "serverUrl" - name: JUPYTER_GATEWAY_VALIDATE_CERT value: "false" - name: JUPYTER_GATEWAY_AUTH_TOKEN value: "session-token"Si va a implementar el cuaderno de Jupyter en un clúster exclusivo de Fargate, etiquete el pod de Jupyter con una etiqueta de
role, tal como se muestra en el siguiente ejemplo:... metadata: name: jupyter-notebook namespace: default labels: role:example-role-name-labelspec: ...namespace-
El espacio de nombres de Kubernetes en el que se implementa el cuaderno.
serverUrl-
El atributo
serverUrlque el comandodescribe-managed-endpointdevolvió en Recuperar la URL del servidor de puerta de enlace de su punto de conexión interactivo . session-token-
El atributo
session-tokenque el comandoget-managed-endpoint-session-credentialsdevolvió en Recuperar un token de autenticación para conectarse al punto de conexión interactivo. KERNEL_LAUNCH_TIMEOUT-
La cantidad de tiempo en segundos que el punto de conexión interactivo espera a que el kernel entre en estado RUNNING. Asegúrese de que haya tiempo suficiente para que se complete el inicio del kernel configurando el tiempo de espera de inicio del kernel en un valor adecuado (máximo 400 segundos).
KERNEL_EXTRA_SPARK_OPTS-
Si lo desea, puede transferir configuraciones de Spark adicionales a los kernels de Spark. Establezca esta variable de entorno con los valores como propiedad de configuración de Spark, tal como se muestra en el siguiente ejemplo:
- name: KERNEL_EXTRA_SPARK_OPTS value: "--conf spark.driver.cores=2 --conf spark.driver.memory=2G --conf spark.executor.instances=2 --conf spark.executor.cores=2 --conf spark.executor.memory=2G --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.shuffleTracking.enabled=true --conf spark.dynamicAllocation.minExecutors=1 --conf spark.dynamicAllocation.maxExecutors=5 --conf spark.dynamicAllocation.initialExecutors=1 "
-
Implemente la especificación del pod en su clúster de Amazon EKS:
kubectl apply -f notebook.yaml -nnamespaceEsto pondrá en marcha un cuaderno mínimo de JupyterLab conectado a su punto de conexión interactivo de Amazon EMR en EKS. Espere a que el estado del pod sea RUNNING. Puede comprobarlo con el siguiente comando:
kubectl get pod jupyter-notebook -nnamespaceCuando el pod esté listo, el comando
get poddevuelve un resultado similar al siguiente:NAME READY STATUS RESTARTS AGE jupyter-notebook 1/1 Running 0 46s -
Adjunte el grupo de seguridad del cuaderno al nodo en el que está programado el cuaderno.
-
En primer lugar, identifique el nodo en el que está programado el pod de
jupyter-notebookcon el comandodescribe pod.kubectl describe pod jupyter-notebook -nnamespace Abra la consola de Amazon EKS en https://console.aws.amazon.com/eks/home#/clusters
. -
Vaya a la pestaña Computación de su clúster de Amazon EKS y seleccione el nodo identificado por el comando
describe pod. Seleccione el ID de la instancia para el nodo. -
En el menú Acciones, seleccione Seguridad > Cambiar grupos de seguridad para adjuntar el grupo de seguridad que creó en Creación de un grupo de seguridad.
-
Si está implementando el pod de cuaderno de Jupyter en AWS Fargate, cree un
SecurityGroupPolicypara aplicarlo al pod de cuaderno de Jupyter con la etiqueta de rol:cat >my-security-group-policy.yaml <<EOF apiVersion: vpcresources.k8s.aws/v1beta1 kind: SecurityGroupPolicy metadata: name:example-security-group-policy-namenamespace: default spec: podSelector: matchLabels: role:example-role-name-labelsecurityGroups: groupIds: -your-notebook-security-group-idEOF
-
-
Ahora, redireccione los puertos para que pueda acceder localmente a la interfaz de JupyterLab:
kubectl port-forward jupyter-notebook 8888:8888 -nnamespaceUna vez que se esté ejecutando, vaya a su navegador local y visite
localhost:8888para ver la interfaz de JupyterLab: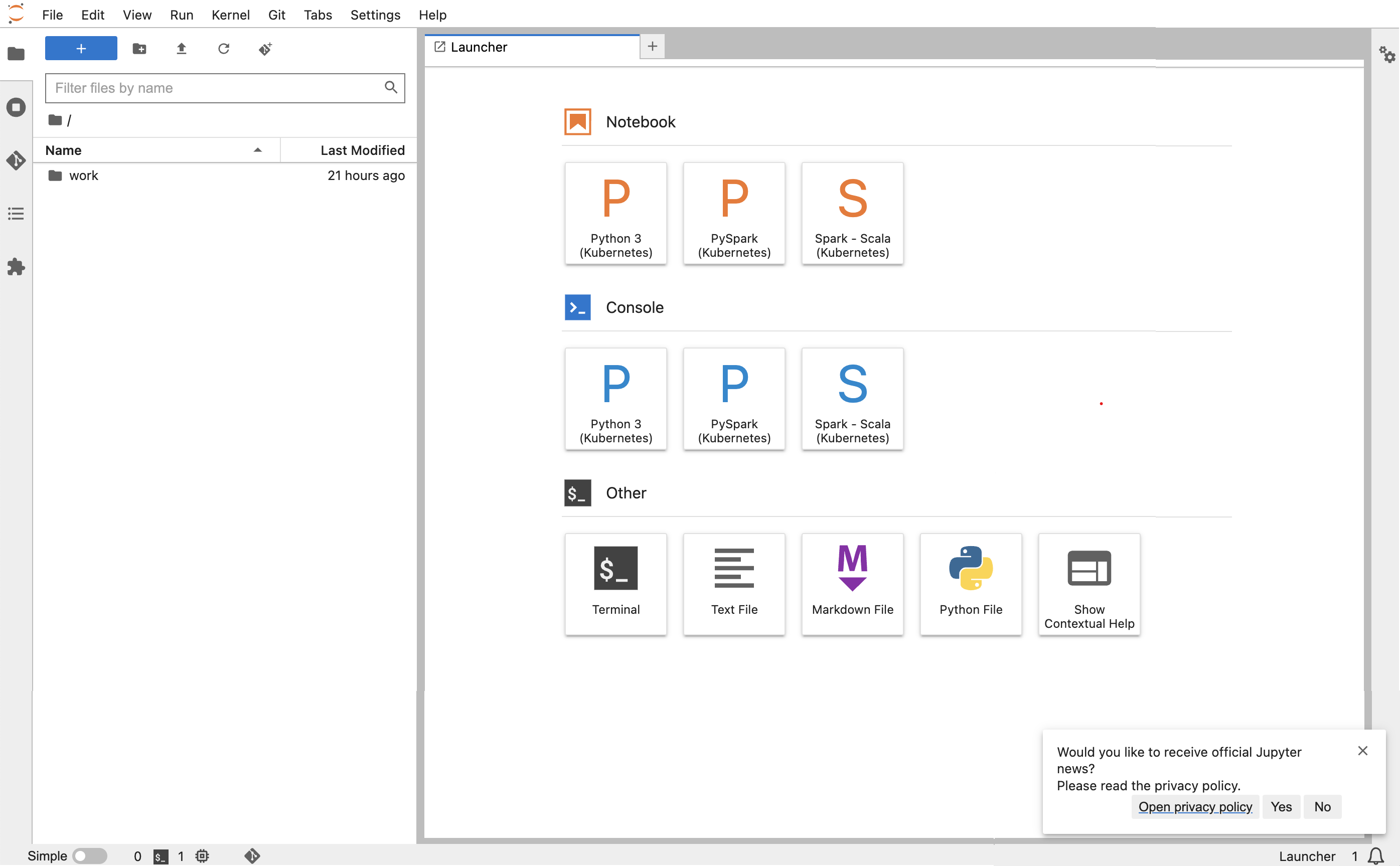
-
Desde JupyterLab, cree un nuevo cuaderno de Scala. Aquí tiene un ejemplo de fragmento de código que puede ejecutar para aproximar el valor de Pi:
import scala.math.random import org.apache.spark.sql.SparkSession /** Computes an approximation to pi */ val session = SparkSession .builder .appName("Spark Pi") .getOrCreate() val slices = 2 // avoid overflow val n = math.min(100000L * slices, Int.MaxValue).toInt val count = session.sparkContext .parallelize(1 until n, slices) .map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y <= 1) 1 else 0 }.reduce(_ + _) println(s"Pi is roughly ${4.0 * count / (n - 1)}") session.stop()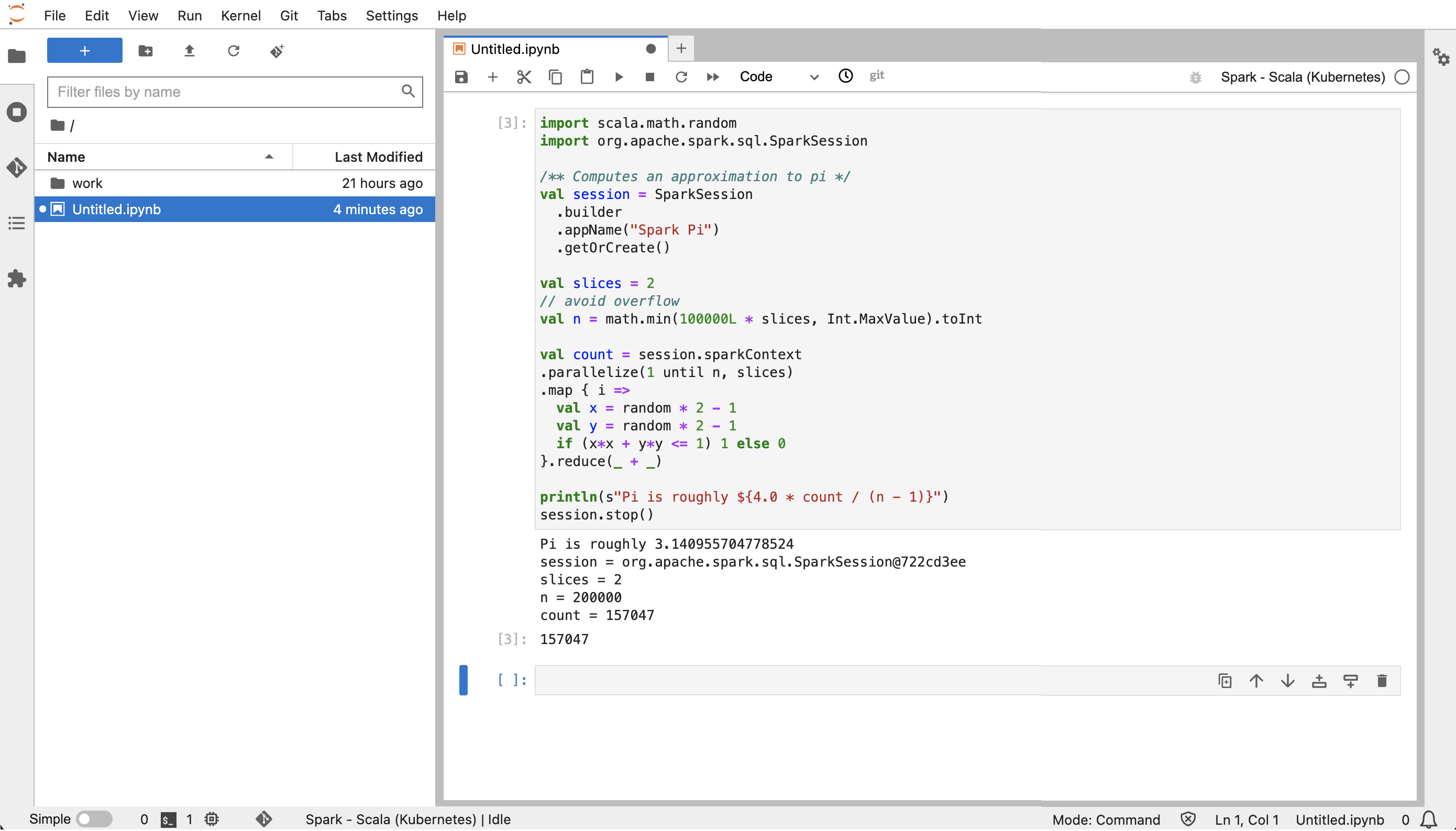
Eliminar un cuaderno de Jupyter autoalojado
Cuando lo tenga todo listo para eliminar su cuaderno autoalojado, también puede eliminar el punto de conexión interactivo y el grupo de seguridad. Lleve a cabo las acciones en el siguiente orden:
-
Utilice el siguiente comando para eliminar el pod de
jupyter-notebook:kubectl delete pod jupyter-notebook -nnamespace -
A continuación, elimine el punto de conexión interactivo con el comando
delete-managed-endpoint. Para ver los pasos para eliminar un punto de conexión interactivo, consulte Eliminar un punto de conexión interactivo. Inicialmente, el estado del punto de conexión será TERMINATING. Una vez que se hayan depurado todos los recursos, pasará al estado TERMINATED. -
Si no piensa utilizar el grupo de seguridad de cuadernos que creó en Creación de un grupo de seguridad para otras implementaciones de cuaderno de Jupyter, puede eliminarlo. Para obtener más información, consulte Eliminar un grupo de seguridad en la Guía del usuario de Amazon EC2.
